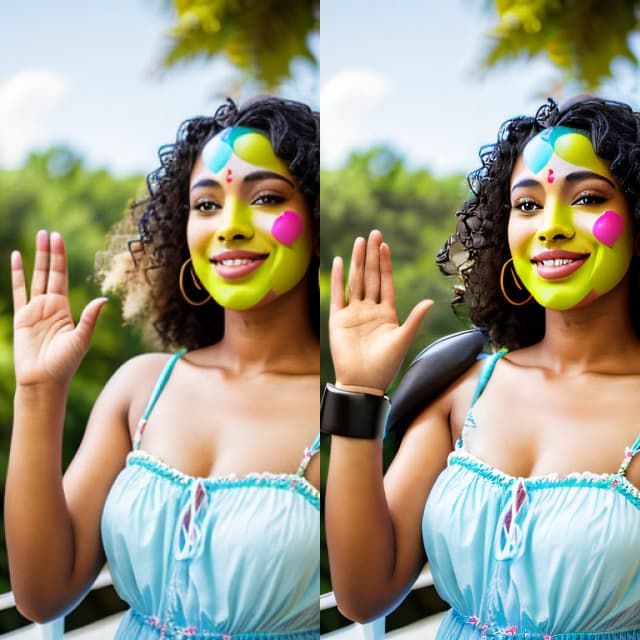CCSR | Konsistenter Bild-/Video-Upscaler
Die Integration des CCSR (Content Consistent Super-Resolution) Modells in diesen ComfyUI Upscale Workflow verbessert das Upscaling von Bildern und Videos erheblich. CCSR kombiniert Diffusionsmodelle mit GANs (Generative Adversarial Networks), um Bildstrukturen zu verfeinern und feine Details zu verbessern, wodurch die Grenzen traditioneller Upscaling-Methoden effektiv überwunden werden. Durch Priorisierung der Inhaltsbeständigkeit minimiert CCSR die Ergebnisvariabilität und bietet einen stabilen und effizienten Super-Resolution-Prozess. Zusätzlich beinhaltet der ComfyUI Upscale Workflow einen optionalen Schritt nach der CCSR-Anwendung, der weiteres Upscaling durch Hinzufügen von Rauschen und Verwendung des ControlNet Recolor Modells beinhaltet. Diese experimentelle Funktion steht Ihnen zum Ausprobieren zur Verfügung.ComfyUI CCSR Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI CCSR Beispiele
ComfyUI CCSR Beschreibung
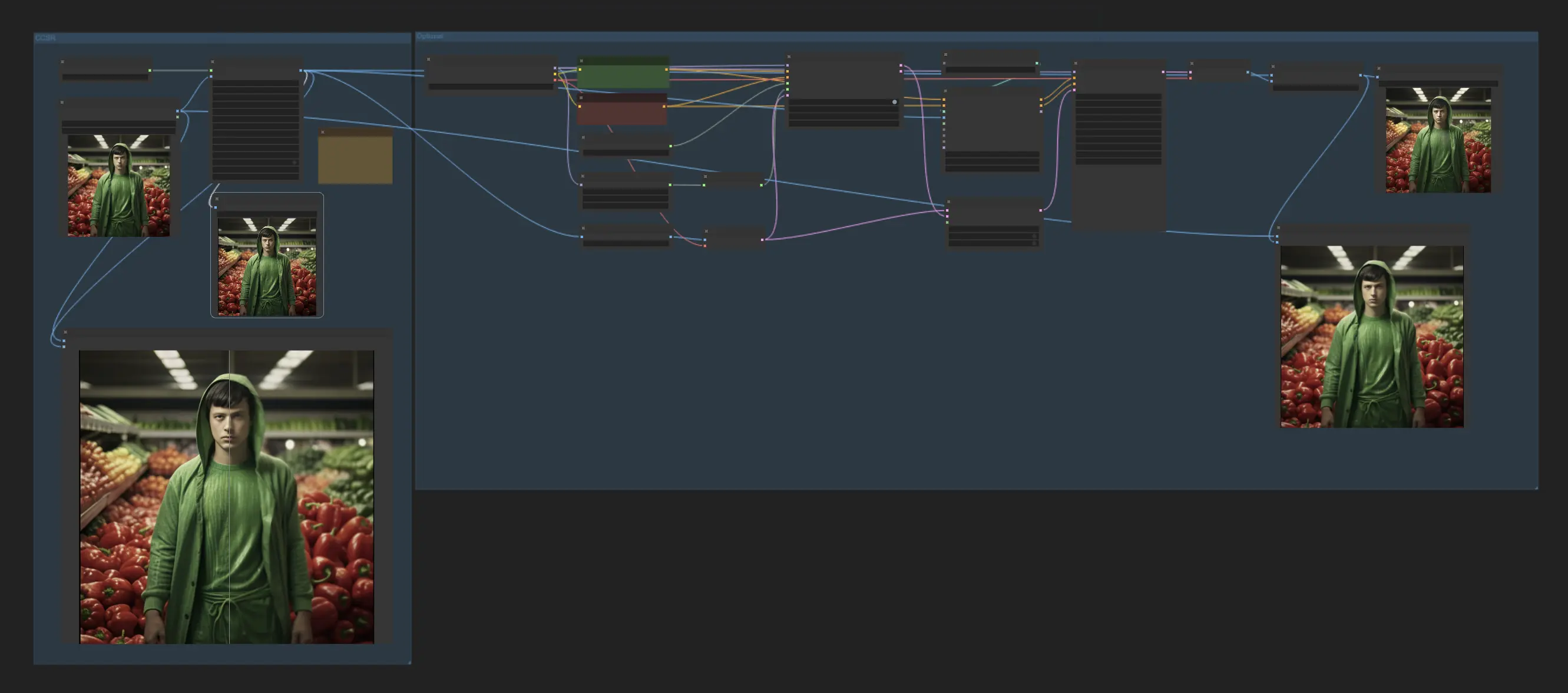
1. ComfyUI CCSR | ComfyUI Upscale Workflow
Dieser ComfyUI Workflow integriert das CCSR (Content Consistent Super-Resolution) Modell, das entwickelt wurde, um die Inhaltsbeständigkeit bei Super-Resolution-Aufgaben zu verbessern. Nach der Anwendung des CCSR-Modells gibt es einen optionalen Schritt, der erneutes Upscaling durch Hinzufügen von Rauschen und Verwendung des ControlNet Recolor Modells beinhaltet. Dies ist eine experimentelle Funktion, die Benutzer erkunden können.
Standardmäßig ist dieser Workflow für Bild-Upscaling eingerichtet. Um Videos zu skalieren, ersetzen Sie einfach "load image" durch "load video" und ändern Sie "save image" zu "combine video".
2. Einführung in CCSR
Vortrainierte latente Diffusionsmodelle wurden für ihr Potenzial zur Verbesserung der perzeptuellen Qualität von Bild-Super-Resolution (SR) Ergebnissen anerkannt. Diese Modelle produzieren jedoch oft variable Ergebnisse für identische niedrig aufgelöste Bilder unter verschiedenen Rauschbedingungen. Diese Variabilität, obwohl vorteilhaft für die Text-zu-Bild-Generierung, stellt eine Herausforderung für SR-Aufgaben dar, die Konsistenz bei der Inhaltsbewahrung erfordern.
Um die Zuverlässigkeit der auf Diffusions-Priors basierenden SR zu verbessern, verwendet CCSR (Content Consistent Super-Resolution) eine Strategie, die Diffusionsmodelle zur Verfeinerung von Bildstrukturen mit generativen adversarialen Netzwerken (GANs) zur Verbesserung feiner Details kombiniert. Es führt eine nicht-uniforme Zeitschrittlernstrategie ein, um ein kompaktes Diffusionsnetzwerk zu trainieren. Dieses Netzwerk rekonstruiert effizient und stabil die Hauptstrukturen eines Bildes, während der vortrainierte Decoder eines variationalen Autoencoders (VAE) durch adversariales Training für die Detailverbesserung feinabgestimmt wird. Dieser Ansatz hilft CCSR, die Stochastizität, die mit auf Diffusions-Priors basierenden SR-Methoden verbunden ist, erheblich zu reduzieren, wodurch die Inhaltsbeständigkeit in SR-Ausgaben verbessert und der Bildgenerierungsprozess beschleunigt wird.
3. Verwendung von ComfyUI CCSR für Bild-Upscaling
3.1. CCSR-Modelle
real-world_ccsr.ckpt: CCSR-Modell für die Wiederherstellung von Bildern aus der realen Welt.
bicubic_ccsr.ckpt: CCSR-Modell für die Wiederherstellung von Bildern mit bikubischer Interpolation.
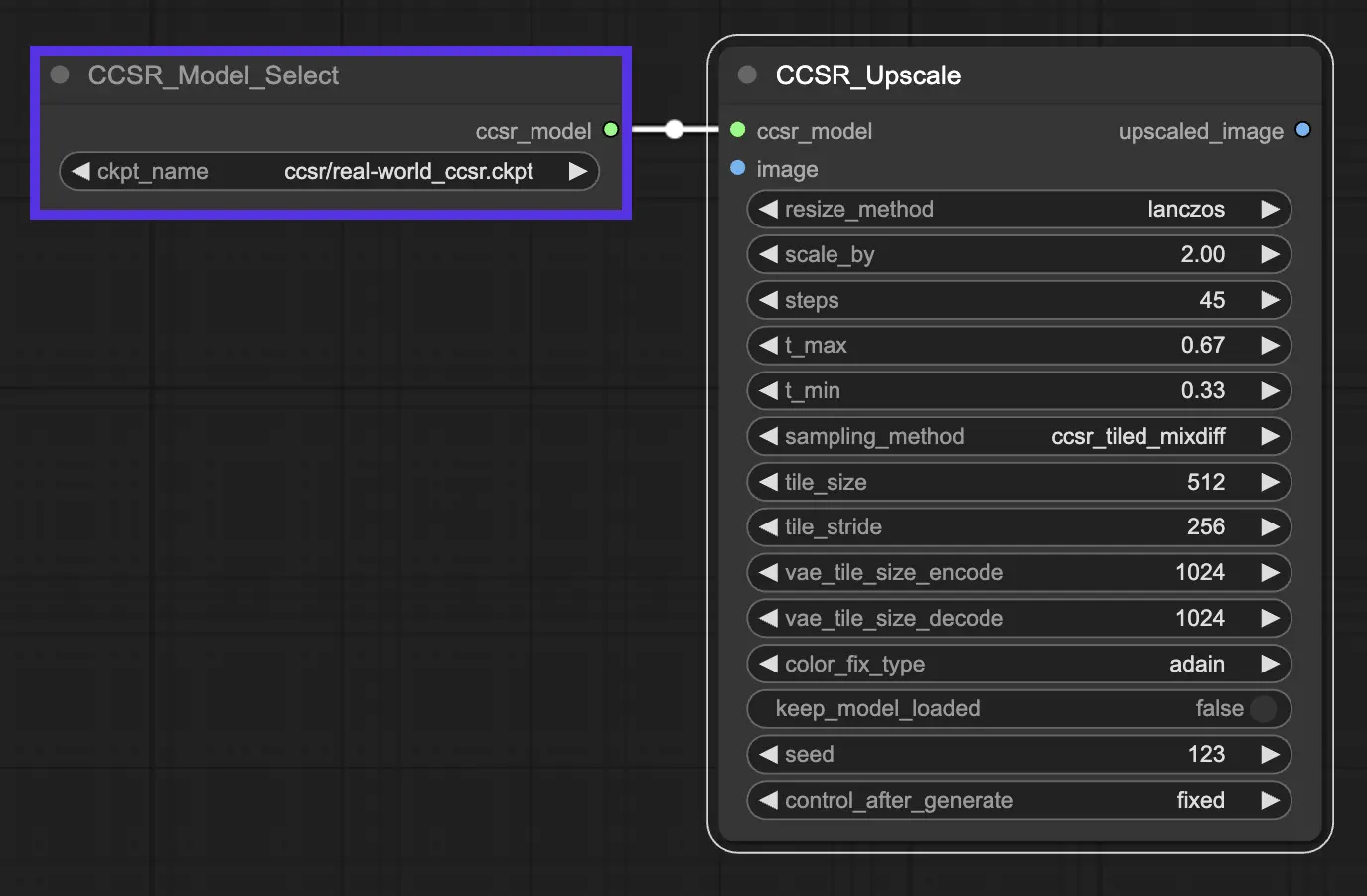
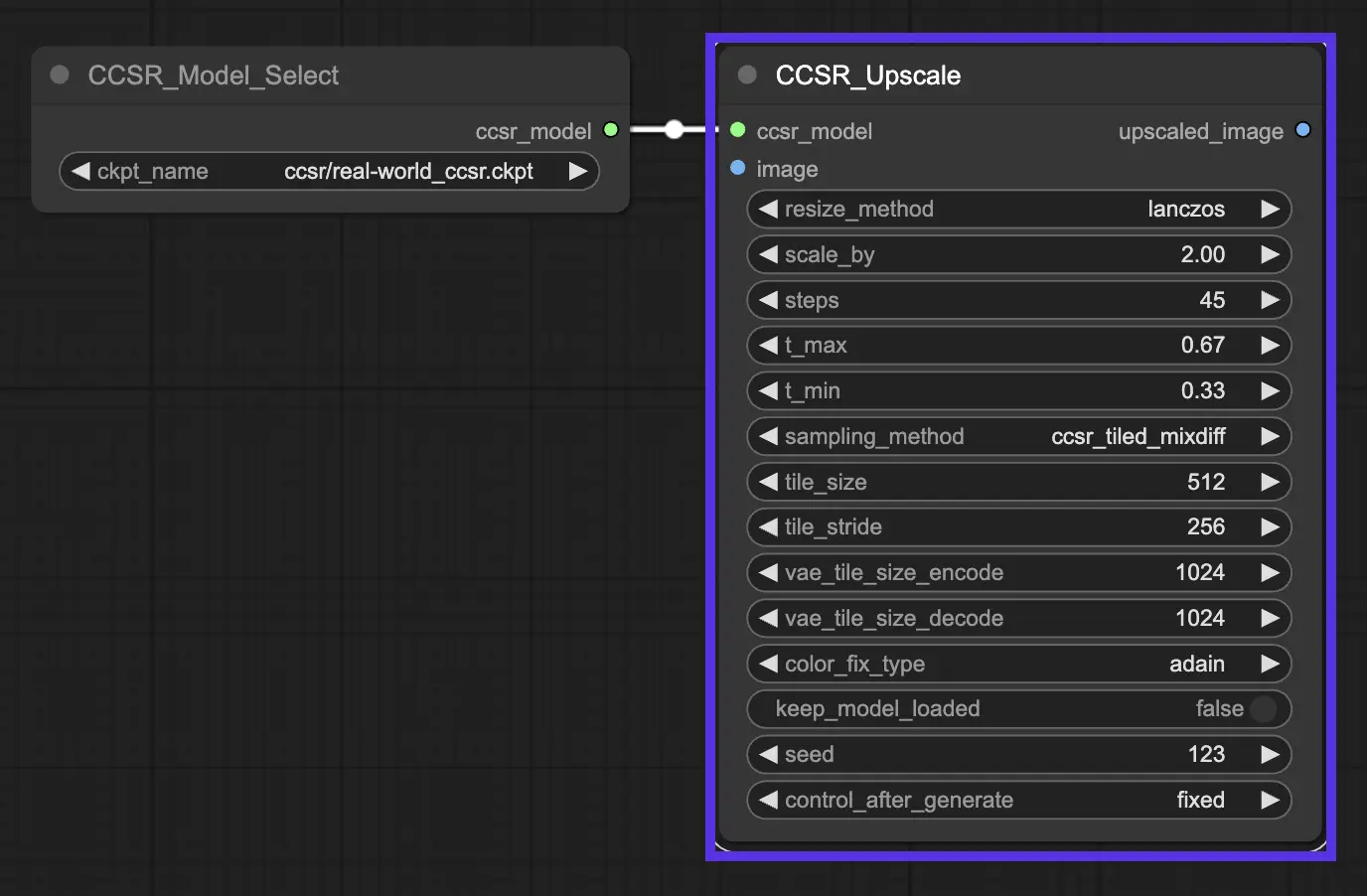
3.2. Schlüsselparameter in CCSR
-scale_by: Dieser Parameter gibt die Super-Resolution-Skalierung an und bestimmt, um wie viel die Eingabebilder oder -videos vergrößert werden.
-steps: Bezieht sich auf die Anzahl der Schritte im Diffusionsprozess. Er steuert, durch wie viele Iterationen das Modell geht, um die Bilddetails und -strukturen zu verfeinern.
-t_max und -t_min: Diese Parameter legen die oberen und unteren Schwellenwerte für die nicht-uniforme Zeitschrittlernstrategie fest, die im CCSR-Modell verwendet wird.
-sampling_method:
CCSR (Normal, Untiled):Dieser Ansatz verwendet eine normale, nicht gekachelte Abtastmethode. Er ist unkompliziert und teilt das Bild nicht in Kacheln zur Verarbeitung auf. Während dies effektiv sein kann, um Inhaltsbeständigkeit über das gesamte Bild zu gewährleisten, ist er auch VRAM-intensiv. Diese Methode eignet sich am besten für Szenarien, in denen viel VRAM vorhanden ist und die höchstmögliche Konsistenz über das gesamte Bild erforderlich ist.CCSR_Tiled_MixDiff:Dieser gekachelte Ansatz verarbeitet jede Kachel des Bildes separat, was hilft, die VRAM-Nutzung effizienter zu verwalten, indem nicht das gesamte Bild auf einmal im Speicher sein muss. Ein bemerkenswerter Nachteil ist jedoch die Möglichkeit sichtbarer Nähte, an denen Kacheln aufeinandertreffen, da jede Kachel unabhängig voneinander verarbeitet wird, was zu möglichen Inkonsistenzen an den Kachelgrenzen führt.CCSR_Tiled_VAE_Gaussian_Weights: Diese Methode zielt darauf ab, das Nahtproblem zu beheben, das beim CCSR_Tiled_MixDiff-Ansatz zu sehen ist, indem Gauß-Gewichte verwendet werden, um die Kacheln sanfter zu mischen. Dies kann die Sichtbarkeit von Nähten erheblich reduzieren und ein konsistenteres Erscheinungsbild über Kachelgrenzen hinweg bieten. Dieses Blending kann jedoch manchmal weniger genau sein und möglicherweise zusätzliches Rauschen in das super-aufgelöste Bild einbringen, was die Gesamtbildqualität beeinträchtigt.
-tile_size und -tile_stride: Diese Parameter sind Teil der gekachelten Diffusionsfunktion, die in CCSR integriert ist, um GPU-Speicher während der Inferenz zu sparen. Kachelung bezieht sich auf die Verarbeitung des Bildes in Patches anstelle des gesamten Bildes, was speichereffizienter sein kann. -tile_size gibt die Größe jeder Kachel an und -tile_diffusion_stride steuert die Schrittweite oder Überlappung zwischen Kacheln.
-color_fix_type: Dieser Parameter gibt die Methode an, die für die Farbkorrektur oder -anpassung im Super-Resolution-Prozess verwendet wird. adain ist eine der Methoden, die für die Farbkorrektur eingesetzt werden, um sicherzustellen, dass die Farben im super-aufgelösten Bild so genau wie möglich mit dem Originalbild übereinstimmen.
4. Weitere Details zu CCSR
Image Super-Resolution, die darauf abzielt, hochauflösende (HR) Bilder aus niedrig aufgelösten (LR) Pendants wiederherzustellen, befasst sich mit der Herausforderung der Qualitätsverschlechterung bei der Bildaufnahme. Während sich bestehende Deep-Learning-basierte SR-Techniken hauptsächlich auf die Optimierung der neuronalen Netzwerkarchitektur gegen einfache, bekannte Verschlechterungen konzentriert haben, bleiben sie hinter der Handhabung der komplexen Verschlechterungen zurück, die in realen Szenarien auftreten. Zu den jüngsten Fortschritten gehörte die Entwicklung von Datensätzen und Methoden, die komplexere Bildverschlechterungen simulieren, um diese realen Herausforderungen anzunähern.
Die Studie hebt auch die Grenzen traditioneller Verlustfunktionen wie ℓ1 und MSE hervor, die dazu neigen, übermäßig glatte Details in SR-Ausgaben zu produzieren. Obwohl SSIM-Verlust und perzeptueller Verlust dieses Problem bis zu einem gewissen Grad abmildern, bleibt das Erreichen realistischer Bilddetails eine Herausforderung. GANs haben sich als erfolgreicher Ansatz zur Verbesserung von Bilddetails herauskristallisiert, aber ihre Anwendung auf natürliche Bilder führt aufgrund der Vielfalt der natürlichen Szenen oft zu visuellen Artefakten.
Denoising Diffusion Probabilistic Models (DDPMs) und ihre Varianten haben erhebliches Potenzial gezeigt und übertreffen GANs bei der Erzeugung vielfältiger und hochwertiger Priors für die Bildwiederherstellung, einschließlich SR. Diese Modelle hatten jedoch Schwierigkeiten, sich an die komplexen und unterschiedlichen Verschlechterungen anzupassen, die in realen Anwendungen vorhanden sind.
Der CCSR-Ansatz versucht, diese Herausforderungen anzugehen, indem er stabile und konsistente Super-Resolution-Ergebnisse sicherstellt. Er nutzt Diffusions-Priors zur Erzeugung kohärenter Strukturen und setzt generatives adversariales Training zur Detail- und Texturverbesserung ein. Durch die Anwendung einer nicht-uniformen Zeitschrittabtaststrategie und die Feinabstimmung eines vortrainierten VAE-Decoders erreicht CCSR effizientere, stabile und inhaltskonsistente SR-Ergebnisse als bestehende auf Diffusions-Priors basierende SR-Methoden.
Weitere Informationen finden Sie auf oder im