IPAdapter V1 FaceID Plus | Konsistente Charaktere
Entfesseln Sie das volle Potenzial Ihrer Charakterdesigns mit dem IPAdapter Face Plus V2-Modell. Dieser Arbeitsablauf ermöglicht es Erstellern, konsistente Charaktermerkmale über verschiedene Stile hinweg beizubehalten. Experimentieren Sie gerne mit verschiedenen Checkpoints oder LoRA-Modellen, um eine Vielzahl von Stilen zu erkundenComfyUI Consistent Characters Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
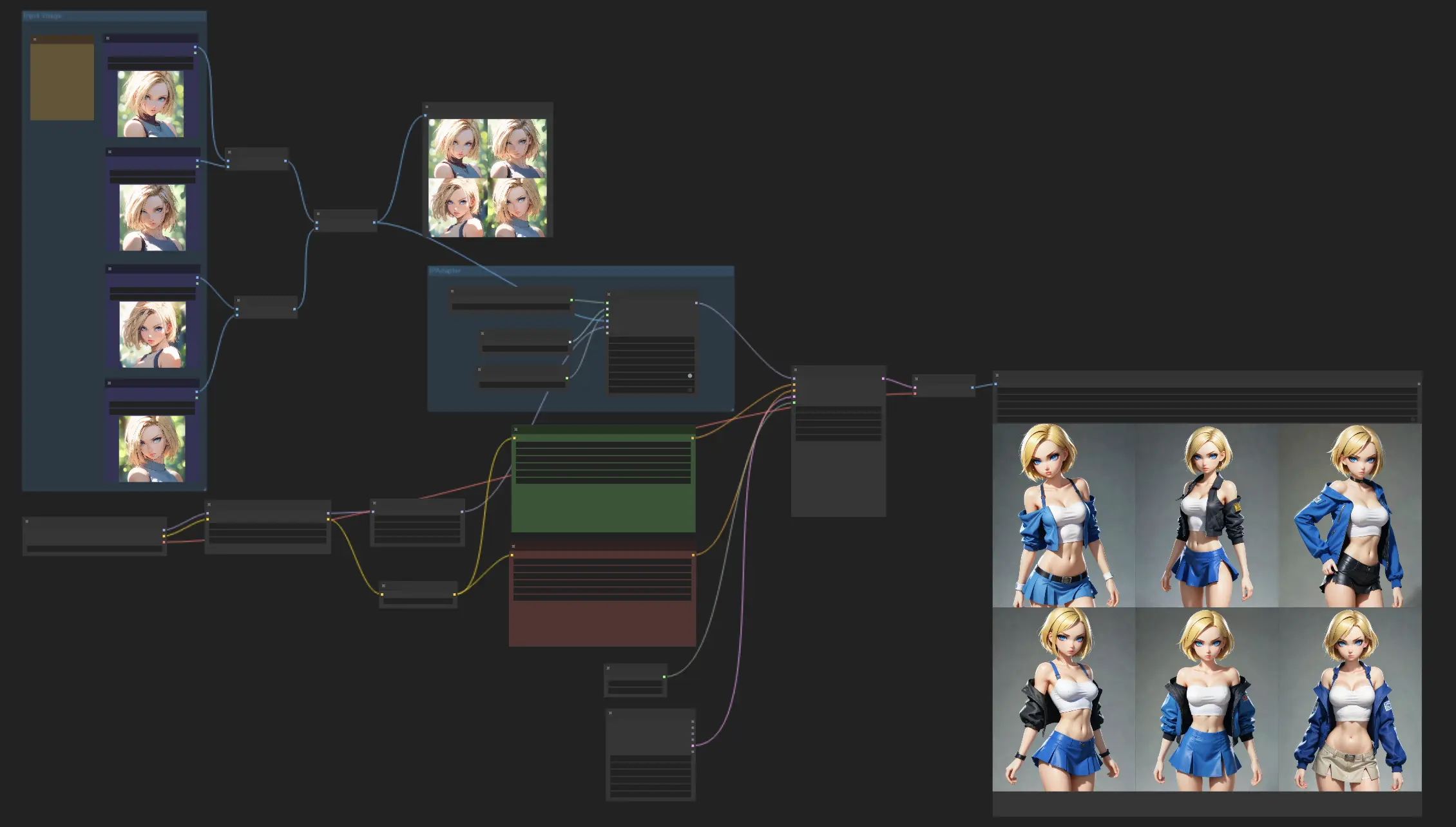
ComfyUI Consistent Characters Beispiele

ComfyUI Consistent Characters Beschreibung
1. Konsistenter Charakter-Arbeitsablauf
Bei diesem Arbeitsablauf geht es darum, Charaktere mit einem konsistenten Aussehen zu gestalten, wobei das IPAdapter Face Plus V2-Modell genutzt wird. Beginnen Sie einfach damit, einige Referenzbilder hochzuladen, und lassen Sie dann das Face Plus V2-Modell seine Magie wirken, indem es eine Reihe von Bildern erstellt, die die gleichen Gesichtszüge beibehalten. Experimentieren Sie gerne mit verschiedenen Checkpoints oder LoRA-Modellen, um eine Vielzahl von Stilen zu erkunden, während Sie das Aussehen Ihres Charakters konsistent halten.
2. Übersicht über IPAdapter FaceID/FaceID Plus
v1.5 FaceID
Dieses Modell ist die Basisversion für die Gesichtserkennung und ermöglicht Variationen, die durch Textprompts, Control Nets und Masken erweitert werden. Es zeichnet sich durch seine durchschnittliche Stärke bei der Konditionierung aus, was es für allgemeine Gesichtskonditionierungsaufgaben geeignet macht. Das Basis-FaceID-Modell verwendet keinen CLIP-Vision-Encoder, was auf eine einfachere Einrichtung ohne komplexe Encoder-Konfigurationen hindeutet.
v1.5 FaceID Plus
Das FaceID Plus-Modell ist eine leistungsfähigere Variante, die für stärkere Bild-zu-Bild-Konditionierungseffekte entwickelt wurde. Es erfordert die Verwendung des ViT-H-Bild-Encoders, was auf die Notwendigkeit höherer Verarbeitungskapazitäten für detaillierte Gesichtsmodellierung hinweist.
v1.5 FaceID Plus v2
Eine Iteration über FaceID Plus, dieses Modell führt Verbesserungen für eine noch detailliertere Gesichtskonditionierung ein. Ähnlich wie FaceID Plus nutzt es den ViT-H-Bild-Encoder. Dieses Modell zielt darauf ab, eine erhöhte Qualität bei der Gesichtsmodellierung zu bieten und geht auf nuanciertere Anforderungen ein.
v1.5 FaceID Portrait
Dieses speziell für Porträts entwickelte Modell verwendet keinen CLIP-Vision-Encoder. Es konzentriert sich auf die Erzeugung hochwertiger Gesichtsbilder in Porträtumgebungen und bietet möglicherweise einen spezialisierten Ansatz für die Generierung von Porträtbildern.
SDXL FaceID
Die SDXL-Variante von FaceID ist auf die Verwendung mit der SDXL-Architektur zugeschnitten und verwendet keinen CLIP-Vision-Encoder. Es stellt ein Basismodell innerhalb der SDXL-Suite dar, das für skalierbare Deep-Learning-Architekturen entwickelt wurde und sich auf Gesichtserkennungsaufgaben konzentriert.
SDXL FaceID Plus v2
Dies ist eine stärkere Version des FaceID-Modells für die SDXL-Architektur, die den ViT-H-Bild-Encoder verwendet. Es wurde entwickelt, um verbesserte Gesichtskonditionierungseffekte innerhalb des SDXL-Frameworks zu bieten und zielt auf Bildgenerierungsaufgaben in hoher Qualität ab.
3. Verwendung von IPAdapter FaceID/FaceID Plus
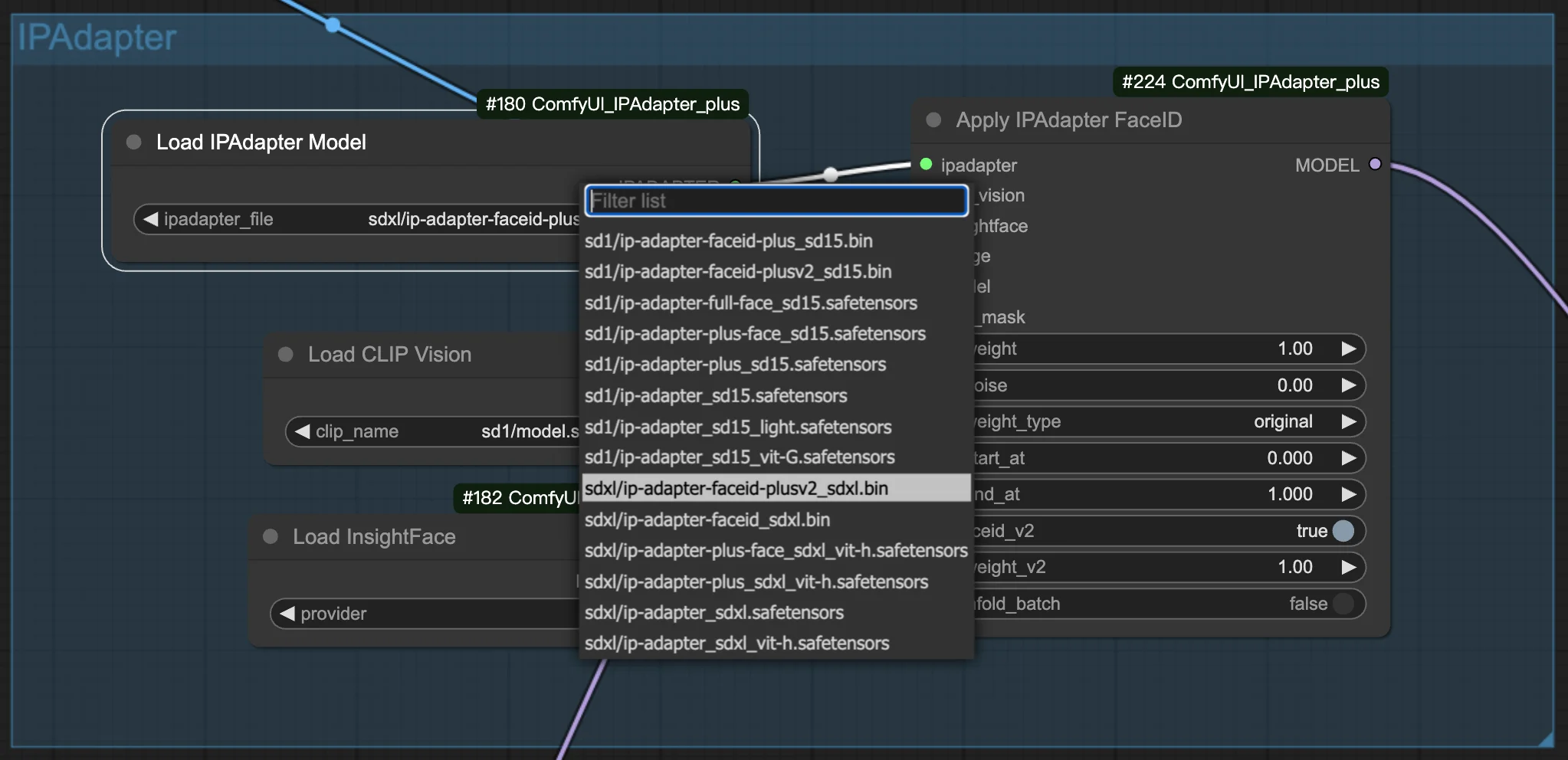
3.1. Wählen Sie das FaceID/FaceID Plus-Modell
Wählen Sie Ihr bevorzugtes FaceID- oder FaceID Plus-Modell aus, um mit der Erstellung Ihrer Bilder zu beginnen. In den Einstellungen finden Sie Optionen zum Anpassen sowohl der Gewichtungen als auch des Rauschens. Diese Anpassungen sind der Schlüssel zur Feinabstimmung des Aussehens Ihrer generierten Bilder und ermöglichen es Ihnen, den genauen Look zu erreichen, den Sie anstreben.
3.2. Vorbereiten des Referenzbildes
Bei der Verwendung von IPAdapter FaceID-Knoten verarbeitet das CLIP-Vision-Modell Ihr Referenzbild, indem es die Größe anpasst und auf eine Dimension von 224x224 Pixeln zentriert. Diese automatische Anpassung konzentriert sich auf die Mitte des Bildes, sodass es entscheidend ist, dass sich das Hauptmotiv Ihres Bildes, wie das Gesicht eines Charakters, mittig befindet. Wenn das Motiv nicht zentriert ist, insbesondere bei Hoch- oder Querformatbildern, entsprechen die Ergebnisse möglicherweise nicht Ihren Erwartungen. Für beste Ergebnisse wird dringend empfohlen, quadratische Bilder mit dem zentrierten Motiv zu verwenden.






