


Entfesseln Sie die Kraft von ComfyUI: Ein Einsteiger-Leitfaden mit praktischer Übung
Updated: 5/16/2024
Hallo, Mitstreiter der KI-Kunst! 👋 Willkommen bei unserem benutzerfreundlichen Leitfaden zu ComfyUI, einem unglaublich leistungsstarken und flexiblen Werkzeug zur Erstellung atemberaubender KI-generierter Kunst. 🎨 In diesem Leitfaden führen wir Sie durch die Grundlagen von ComfyUI, erforschen seine Funktionen und helfen Ihnen, sein Potenzial zu entfesseln, um Ihre KI-Kunst auf die nächste Stufe zu heben. 🚀
Wir werden behandeln:
1. Was ist ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. Wo fange ich mit ComfyUI an?
- 1.3. Grundlegende Steuerelemente
2. ComfyUI-Workflows: Text-zu-Bild
- 2.1. Auswahl eines Modells
- 2.2. Eingabe des positiven und negativen Prompts
- 2.3. Erzeugung eines Bildes
- 2.4. Technische Erklärung von ComfyUI
- 2.4.1 Load Checkpoint Node
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
3. ComfyUI-Workflow: Bild-zu-Bild
4. ComfyUI SDXL
5. ComfyUI Inpainting
6. ComfyUI Outpainting
7. ComfyUI-Hochskalierung
- 7.1. Hochskalierung Pixel
- 7.1.1. Hochskalierung Pixel durch Algorithmus
- 7.1.2. Hochskalierung Pixel durch Modell
- 7.2. Hochskalierung Latent
- 7.3. Hochskalierung Pixel vs. Hochskalierung Latent
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. So installieren Sie fehlende benutzerdefinierte Knoten
- 9.2. So aktualisieren Sie benutzerdefinierte Knoten
- 9.3. So laden Sie benutzerdefinierte Knoten in Ihren Workflow
10. ComfyUI Embeddings
- 10.1. Embedding mit Autovervollständigung
- 10.2. Embedding-Gewichtung
11. ComfyUI LoRA
- 11.1. Einfache LoRA-Workflows
- 11.2. Mehrere LoRAs
12. Abkürzungen und Tricks für ComfyUI
- 12.1. Kopieren und Einfügen
- 12.2. Verschieben mehrerer Knoten
- 12.3. Umgehen eines Knotens
- 12.4. Minimieren eines Knotens
- 12.5. Bild erzeugen
- 12.6. Eingebetteter Workflow
- 12.7. Seeds fixieren, um Zeit zu sparen
13. ComfyUI Online
1. Was ist ComfyUI? 🤔
ComfyUI ist wie ein Zauberstab 🪄, mit dem Sie mühelos atemberaubende, KI-generierte Kunstwerke erstellen können. Im Kern ist ComfyUI eine knotenbasierte grafische Benutzeroberfläche (GUI), die auf Stable Diffusion aufbaut, einem hochmodernen Deep-Learning-Modell, das Bilder aus Textbeschreibungen erzeugt. 🌟 Aber was ComfyUI wirklich besonders macht, ist die Art und Weise, wie es Künstler wie Sie dazu befähigt, Ihre Kreativität zu entfesseln und Ihre wildesten Ideen zum Leben zu erwecken.
Stellen Sie sich eine digitale Leinwand vor, auf der Sie Ihre eigenen einzigartigen Bildgenerierungs-Workflows erstellen können, indem Sie verschiedene Knoten miteinander verbinden, von denen jeder eine bestimmte Funktion oder Operation repräsentiert. 🧩 Es ist wie das Erstellen eines visuellen Rezepts für Ihre KI-generierten Meisterwerke!
Möchten Sie ein Bild von Grund auf mit einem Textprompt generieren? Es gibt einen Knoten dafür! Möchten Sie einen bestimmten Sampler anwenden oder den Geräuschpegel optimieren? Fügen Sie einfach die entsprechenden Knoten hinzu und lassen Sie den Zauber geschehen. ✨
Aber das Beste daran ist: ComfyUI zerlegt den Workflow in umstellbare Elemente und gibt Ihnen so die Freiheit, Ihre eigenen benutzerdefinierten Workflows zu erstellen, die auf Ihre künstlerische Vision zugeschnitten sind. 🖼️ Es ist wie ein persönliches Toolkit, das sich Ihrem kreativen Prozess anpasst.
1.1. ComfyUI vs. AUTOMATIC1111 🆚
AUTOMATIC1111 ist die Standard-GUI für Stable Diffusion. Sollten Sie also stattdessen ComfyUI verwenden? Vergleichen wir:
✅ Vorteile der Verwendung von ComfyUI:
- Leichtgewicht: Es läuft schnell und effizient.
- Flexibel: Sehr konfigurierbar, um Ihren Anforderungen gerecht zu werden.
- Transparent: Der Datenfluss ist sichtbar und leicht verständlich.
- Einfach zu teilen: Jede Datei repräsentiert einen reproduzierbaren Workflow.
- Gut für Prototyping: Erstellen Sie Prototypen mit einer grafischen Oberfläche anstelle von Code.
❌ Nachteile der Verwendung von ComfyUI:
- Inkonsistente Benutzeroberfläche: Jeder Workflow kann ein anderes Knotenlayout haben.
- Zu viele Details: Durchschnittliche Benutzer müssen möglicherweise nicht die zugrunde liegenden Verbindungen kennen.
1.2. Wo fange ich mit ComfyUI an? 🏁
Wir glauben, dass die beste Art, ComfyUI zu lernen, darin besteht, sich in Beispiele zu vertiefen und es aus erster Hand zu erleben. 🙌 Deshalb haben wir dieses einzigartige Tutorial erstellt, das sich von anderen abhebt. In diesem Tutorial finden Sie eine detaillierte, schrittweise Anleitung, der Sie folgen können.
Aber das Beste daran ist: 🌟 Wir haben ComfyUI direkt in diese Webseite integriert! Sie können mit ComfyUI-Beispielen in Echtzeit interagieren, während Sie den Leitfaden durcharbeiten.🌟 Lassen Sie uns eintauchen!
2. ComfyUI-Workflows: Text-zu-Bild 🖼️
Beginnen wir mit dem einfachsten Fall: der Erzeugung eines Bildes aus Text. Klicken Sie auf Queue Prompt, um den Workflow auszuführen. Nach einer kurzen Wartezeit sollten Sie Ihr erstes generiertes Bild sehen! Um Ihre Warteschlange zu überprüfen, klicken Sie einfach auf View Queue.
Hier ist ein standardmäßiger Text-zu-Bild-Workflow zum Ausprobieren:
Grundbausteine 🕹️
Der ComfyUI-Workflow besteht aus zwei grundlegenden Bausteinen: Knoten und Kanten.
- Knoten sind die rechteckigen Blöcke, z.B. Load Checkpoint, Clip Text Encoder usw. Jeder Knoten führt spezifischen Code aus und benötigt Eingaben, Ausgaben und Parameter.
- Kanten sind die Drähte, die die Ein- und Ausgänge zwischen den Knoten verbinden.
Grundlegende Steuerelemente 🕹️
- Zoomen Sie mit dem Mausrad oder einer Zwei-Finger-Geste.
- Ziehen und halten Sie den Eingabe- oder Ausgabepunkt, um Verbindungen zwischen Knoten zu erstellen.
- Bewegen Sie sich im Arbeitsbereich, indem Sie mit der linken Maustaste klicken, ziehen und halten.
Lassen Sie uns auf die Details dieses Workflows eingehen.
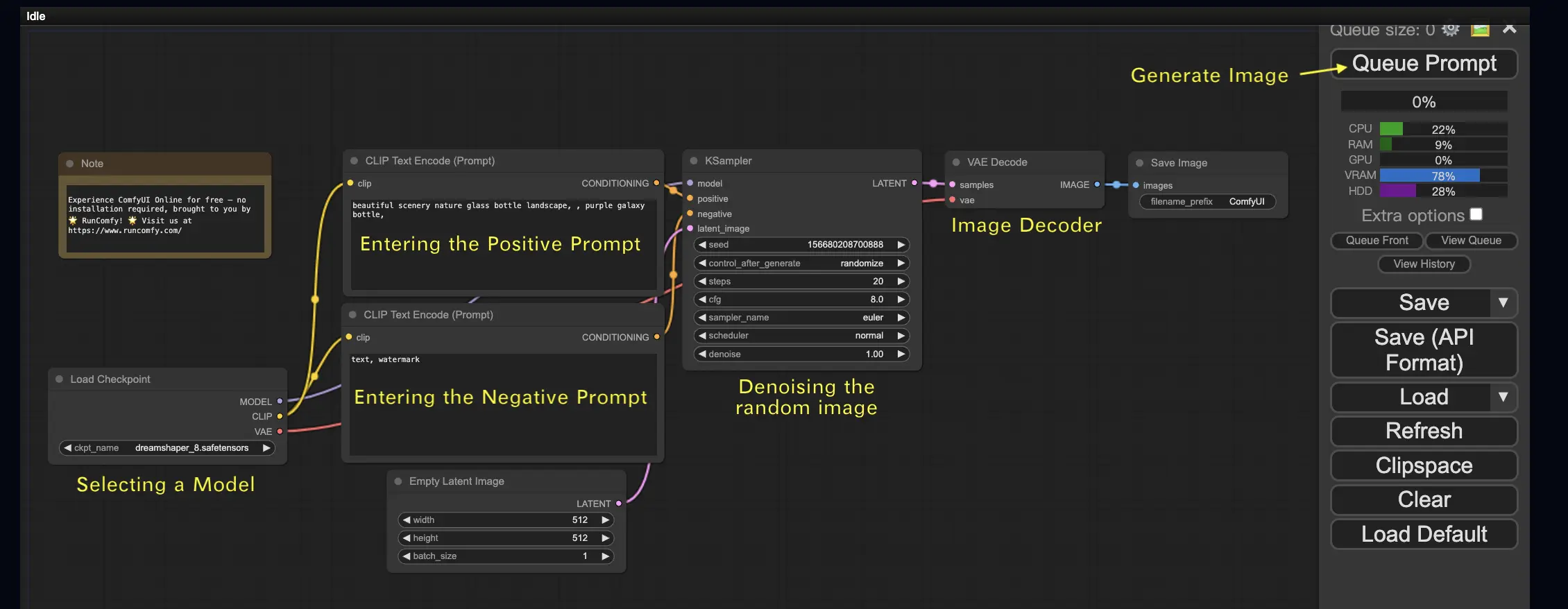
2.1. Auswahl eines Modells 🗃️
Wählen Sie zunächst im Knoten Load Checkpoint ein Stable Diffusion Checkpoint-Modell aus. Klicken Sie auf den Modellnamen, um verfügbare Modelle anzuzeigen. Wenn Sie auf den Modellnamen klicken und nichts passiert, müssen Sie möglicherweise ein benutzerdefiniertes Modell hochladen.
2.2. Eingabe des positiven und negativen Prompts 📝
Sie sehen zwei Knoten mit der Bezeichnung CLIP Text Encode (Prompt). Der obere Prompt ist mit dem positive-Eingang des KSampler-Knotens verbunden, während der untere Prompt mit dem negative-Eingang verbunden ist. Geben Sie also Ihren positiven Prompt oben und Ihren negativen Prompt unten ein.
Der Knoten CLIP Text Encode konvertiert den Prompt in Tokens und kodiert sie mit dem Textencoder in Embeddings.
💡 Tipp: Verwenden Sie die Syntax (keyword:weight), um das Gewicht eines Schlüsselworts zu steuern, z.B. (keyword:1.2), um seinen Effekt zu erhöhen, oder (keyword:0.8), um ihn zu verringern.
2.3. Erzeugung eines Bildes 🎨
Klicken Sie auf Queue Prompt, um den Workflow auszuführen. Nach einer kurzen Wartezeit wird Ihr erstes Bild generiert!
2.4. Technische Erklärung von ComfyUI 🤓
Die Stärke von ComfyUI liegt in seiner Konfigurierbarkeit. Das Verständnis der Funktionsweise jedes Knotens ermöglicht es Ihnen, sie an Ihre Bedürfnisse anzupassen. Bevor wir jedoch auf die Details eingehen, werfen wir einen Blick auf den Stable Diffusion-Prozess, um besser zu verstehen, wie ComfyUI funktioniert.
Der Stable Diffusion-Prozess lässt sich in drei Hauptschritte zusammenfassen:
- Textcodierung: Der vom Benutzer eingegebene Prompt wird von einer Komponente namens Text Encoder in einzelne Wortmerkmalsvektoren kompiliert. Dieser Schritt wandelt den Text in ein Format um, das das Modell verstehen und mit dem es arbeiten kann.
- Latent Space Transformation: Die Merkmalsvektoren aus dem Text Encoder und ein zufälliges Rauschbild werden in einen latenten Raum transformiert. In diesem Raum durchläuft das zufällige Bild basierend auf den Merkmalsvektoren einen Entrauschungsprozess, was zu einem Zwischenprodukt führt. In diesem Schritt geschieht der Zauber, da das Modell lernt, die Textmerkmale mit visuellen Darstellungen zu assoziieren.
- Bilddekodierung: Schließlich wird das Zwischenprodukt aus dem latenten Raum vom Bilddecoder dekodiert und in ein tatsächliches Bild umgewandelt, das wir sehen und schätzen können.
Jetzt, da wir ein allgemeines Verständnis des Stable Diffusion-Prozesses haben, tauchen wir in die Schlüsselkomponenten und -knoten in ComfyUI ein, die diesen Prozess ermöglichen.
2.4.1 Load Checkpoint-Knoten 🗃️
Der Load Checkpoint-Knoten in ComfyUI ist entscheidend für die Auswahl eines Stable Diffusion-Modells. Ein Stable Diffusion-Modell besteht aus drei Hauptkomponenten: MODEL, CLIP und VAE. Lassen Sie uns jede Komponente und ihre Beziehung zu den entsprechenden Knoten in ComfyUI untersuchen.
- MODEL: Die Komponente MODEL ist das Rauschvorhersagemodell, das im latenten Raum arbeitet. Sie ist für den Kernprozess der Bilderzeugung aus der latenten Repräsentation verantwortlich. In ComfyUI verbindet sich der MODEL-Ausgang des Load Checkpoint-Knotens mit dem KSampler-Knoten, wo der umgekehrte Diffusionsprozess stattfindet. Der KSampler-Knoten verwendet das MODEL, um die latente Repräsentation iterativ zu entrauschen und das Bild schrittweise zu verfeinern, bis es mit dem gewünschten Prompt übereinstimmt.
- CLIP: CLIP (Contrastive Language-Image Pre-training) ist ein Sprachmodell, das die positiven und negativen Prompts des Benutzers vorverarbeitet. Es wandelt die Textprompts in ein Format um, das das MODEL verstehen und zur Steuerung des Bilderzeugungsprozesses verwenden kann. In ComfyUI verbindet sich der CLIP-Ausgang des Load Checkpoint-Knotens mit dem CLIP Text Encode-Knoten. Der CLIP Text Encode-Knoten nimmt die vom Benutzer bereitgestellten Prompts entgegen und speist sie in das CLIP-Sprachmodell ein, wobei jedes Wort in Embeddings umgewandelt wird. Diese Embeddings erfassen die semantische Bedeutung der Wörter und ermöglichen es dem MODEL, Bilder zu generieren, die mit den gegebenen Prompts übereinstimmen.
- VAE: VAE (Variational AutoEncoder) ist für die Umwandlung des Bildes zwischen dem Pixelraum und dem latenten Raum verantwortlich. Es besteht aus einem Encoder, der das Bild in eine niedrigdimensionale latente Repräsentation komprimiert, und einem Decoder, der das Bild aus der latenten Repräsentation rekonstruiert. Im Text-zu-Bild-Prozess wird der VAE nur im letzten Schritt verwendet, um das generierte Bild vom latenten Raum zurück in den Pixelraum zu konvertieren. Der VAE Decode-Knoten in ComfyUI nimmt die Ausgabe des KSampler-Knotens (der im latenten Raum arbeitet) und verwendet den Decoder-Teil des VAE, um die latente Repräsentation in das endgültige Bild im Pixelraum umzuwandeln.
Es ist wichtig zu beachten, dass der VAE eine separate Komponente vom CLIP-Sprachmodell ist. Während CLIP sich auf die Verarbeitung von Textprompts konzentriert, beschäftigt sich der VAE mit der Umwandlung zwischen Pixel- und latentem Raum.
2.4.2. CLIP Text Encode 📝
Der CLIP Text Encode-Knoten in ComfyUI ist dafür verantwortlich, die vom Benutzer bereitgestellten Prompts zu übernehmen und sie in das CLIP-Sprachmodell einzuspeisen. CLIP ist ein leistungsstarkes Sprachmodell, das die semantische Bedeutung von Wörtern versteht und sie mit visuellen Konzepten assoziieren kann. Wenn ein Prompt in den CLIP Text Encode-Knoten eingegeben wird, durchläuft er einen Transformationsprozess, bei dem jedes Wort in Embeddings umgewandelt wird. Diese Embeddings sind hochdimensionale Vektoren, die die semantischen Informationen der Wörter erfassen. Durch die Umwandlung der Prompts in Embeddings ermöglicht CLIP dem MODEL, Bilder zu generieren, die die Bedeutung und Absicht der gegebenen Prompts genau widerspiegeln.
2.4.3. Empty Latent Image 🌌
Beim Text-zu-Bild-Prozess beginnt die Generierung mit einem zufälligen Bild im latenten Raum. Dieses zufällige Bild dient als Ausgangszustand für das MODEL. Die Größe des latenten Bildes ist proportional zur tatsächlichen Bildgröße im Pixelraum. In ComfyUI können Sie die Höhe und Breite des latenten Bildes anpassen, um die Größe des generierten Bildes zu steuern. Zusätzlich können Sie die Batch-Größe festlegen, um die Anzahl der Bilder zu bestimmen, die bei jedem Durchlauf erzeugt werden.
Die optimalen Größen für latente Bilder hängen vom jeweiligen verwendeten Stable Diffusion-Modell ab. Für SD v1.5-Modelle sind die empfohlenen Größen 512x512 oder 768x768, während für SDXL-Modelle die optimale Größe 1024x1024 beträgt. ComfyUI bietet eine Reihe gängiger Seitenverhältnisse zur Auswahl, wie z.B. 1:1 (quadratisch), 3:2 (Querformat), 2:3 (Hochformat), 4:3 (Querformat), 3:4 (Hochformat), 16:9 (Breitbild) und 9:16 (vertikal). Es ist wichtig zu beachten, dass die Breite und Höhe des latenten Bildes durch 8 teilbar sein müssen, um die Kompatibilität mit der Architektur des Modells zu gewährleisten.
2.4.4. VAE 🔍
Der VAE (Variational AutoEncoder) ist eine entscheidende Komponente im Stable Diffusion-Modell, die die Umwandlung von Bildern zwischen dem Pixelraum und dem latenten Raum übernimmt. Er besteht aus zwei Hauptteilen: einem Bildencoder und einem Bilddecoder.
Der Bildencoder nimmt ein Bild im Pixelraum und komprimiert es in eine niedrigdimensionale latente Repräsentation. Dieser Kompressionsprozess reduziert die Datenmenge erheblich und ermöglicht eine effizientere Verarbeitung und Speicherung. So kann beispielsweise ein Bild der Größe 512x512 Pixel auf eine latente Repräsentation der Größe 64x64 komprimiert werden.
Der Bilddecoder, auch VAE Decoder genannt, ist hingegen für die Rekonstruktion des Bildes aus der latenten Repräsentation zurück in den Pixelraum verantwortlich. Er nimmt die komprimierte latente Repräsentation und expandiert sie, um das endgültige Bild zu erzeugen.
Die Verwendung eines VAE bietet mehrere Vorteile:
- Effizienz: Durch die Komprimierung des Bildes in einen niedrigdimensionalen latenten Raum ermöglicht der VAE eine schnellere Generierung und kürzere Trainingszeiten. Die reduzierte Datengröße ermöglicht eine effizientere Verarbeitung und Speichernutzung.
- Latente Raummanipulation: Der latente Raum bietet eine kompaktere und aussagekräftigere Darstellung des Bildes. Dies ermöglicht eine präzisere Kontrolle und Bearbeitung von Bilddetails und -stil. Durch die Manipulation der latenten Repräsentation wird es möglich, bestimmte Aspekte des generierten Bildes zu modifizieren.
Es gibt jedoch auch einige Nachteile zu beachten:
- Datenverlust: Während des Kodierungs- und Dekodierungsprozesses können einige Details des Originalbildes verloren gehen. Die Kompressions- und Rekonstruktionsschritte können Artefakte oder leichte Abweichungen im endgültigen Bild im Vergleich zum Original einführen.
- Begrenzte Erfassung der Originaldaten: Der niedrigdimensionale latente Raum ist möglicherweise nicht in der Lage, alle komplexen Merkmale und Details des Originalbildes vollständig zu erfassen. Einige Informationen können während des Kompressionsprozesses verloren gehen, was zu einer etwas weniger genauen Darstellung der Originaldaten führt.
Trotz dieser Einschränkungen spielt der VAE im Stable Diffusion-Modell eine entscheidende Rolle, indem er eine effiziente Umwandlung zwischen dem Pixelraum und dem latenten Raum ermöglicht und so eine schnellere Generierung und eine präzisere Kontrolle über die generierten Bilder ermöglicht.
2.4.5. KSampler ⚙️
Der KSampler-Knoten in ComfyUI ist das Herzstück des Bilderzeugungsprozesses in Stable Diffusion. Er ist für die Entrauschung des Zufallsbildes im latenten Raum zuständig, um es an den vom Benutzer vorgegebenen Prompt anzupassen. Der KSampler verwendet eine Technik namens "Reverse Diffusion", bei der die latente Repräsentation iterativ verfeinert wird, indem Rauschen entfernt und sinnvolle Details basierend auf der Anleitung durch die CLIP-Embeddings hinzugefügt werden.
Der KSampler-Knoten bietet mehrere Parameter, mit denen Benutzer den Bilderzeugungsprozess optimieren können:
Seed: Der Seed-Wert steuert das anfängliche Rauschen und die Komposition des endgültigen Bildes. Durch die Festlegung eines bestimmten Seeds können Benutzer reproduzierbare Ergebnisse erzielen und die Konsistenz über mehrere Generationen hinweg wahren.
Control_after_generation: Dieser Parameter bestimmt, wie sich der Seed-Wert nach jeder Generation ändert. Er kann auf Randomize (bei jedem Durchlauf einen neuen Zufallsseed erzeugen), Increment (den Seed-Wert um 1 erhöhen), Decrement (den Seed-Wert um 1 verringern) oder Fixed (den Seed-Wert konstant halten) eingestellt werden.
Step: Die Anzahl der Sampling-Schritte bestimmt die Intensität des Verfeinerungsprozesses. Höhere Werte führen zu weniger Artefakten und detaillierteren Bildern, erhöhen aber auch die Generierungszeit.
Sampler_name: Mit diesem Parameter können Benutzer den spezifischen Sampling-Algorithmus auswählen, der vom KSampler verwendet wird. Verschiedene Sampling-Algorithmen können leicht unterschiedliche Ergebnisse liefern und unterschiedliche Generierungsgeschwindigkeiten aufweisen.
Scheduler: Der Scheduler steuert, wie sich der Rauschpegel bei jedem Schritt des Entrauschungsprozesses ändert. Er bestimmt die Geschwindigkeit, mit der das Rauschen aus der latenten Repräsentation entfernt wird.
Denoise: Der Denoise-Parameter legt fest, wie viel des anfänglichen Rauschens durch den Entrauschungsprozess entfernt werden soll. Ein Wert von 1 bedeutet, dass das gesamte Rauschen entfernt wird, was zu einem sauberen und detaillierten Bild führt.
Durch Anpassung dieser Parameter können Sie den Bilderzeugungsprozess optimieren, um die gewünschten Ergebnisse zu erzielen.
Sind Sie jetzt bereit, Ihre ComfyUI-Reise anzutreten?
Bei RunComfy haben wir das ultimative ComfyUI-Online-Erlebnis speziell für Sie geschaffen. Verabschieden Sie sich von komplizierten Installationen!
🎉 Probieren Sie ComfyUI Online jetzt aus und entfesseln Sie Ihr künstlerisches Potenzial wie nie zuvor! 🎉
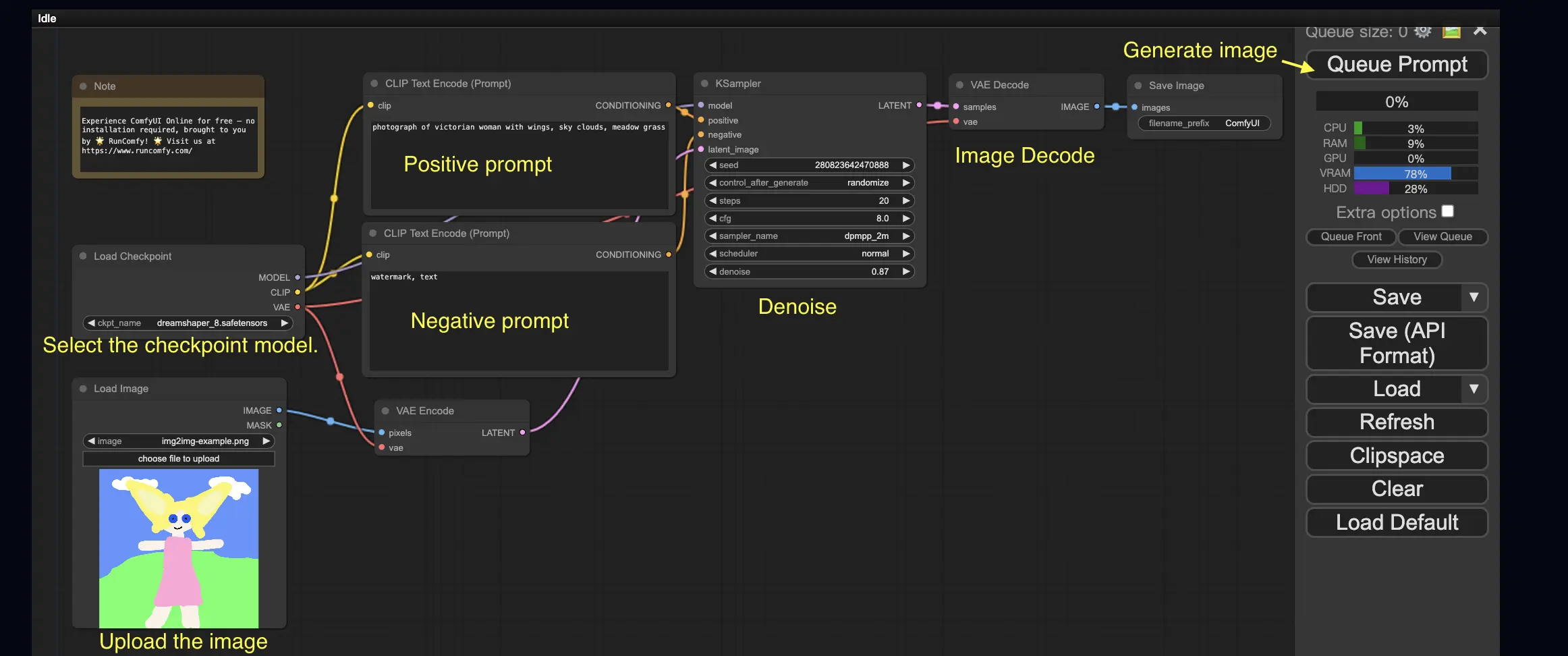
3. ComfyUI-Workflow: Bild-zu-Bild 🖼️
Der Bild-zu-Bild-Workflow erzeugt ein Bild basierend auf einem Prompt und einem Eingabebild. Probieren Sie es selbst aus!
So verwenden Sie den Bild-zu-Bild-Workflow:
- Wählen Sie das Checkpoint-Modell aus.
- Laden Sie das Bild als Bildprompt hoch.
- Überarbeiten Sie die positiven und negativen Prompts.
- Passen Sie optional die Entrauschung (Entrauschungsstärke) im KSampler-Knoten an.
- Drücken Sie Queue Prompt, um die Generierung zu starten.
Für weitere Premium-ComfyUI-Workflows besuchen Sie unsere 🌟ComfyUI-Workflow-Liste🌟
4. ComfyUI SDXL 🚀
Dank seiner extremen Konfigurierbarkeit ist ComfyUI eine der ersten GUIs, die das Stable Diffusion XL-Modell unterstützt. Lassen Sie es uns ausprobieren!
So verwenden Sie den ComfyUI SDXL-Workflow:
- Überarbeiten Sie die positiven und negativen Prompts.
- Drücken Sie Queue Prompt, um die Generierung zu starten.
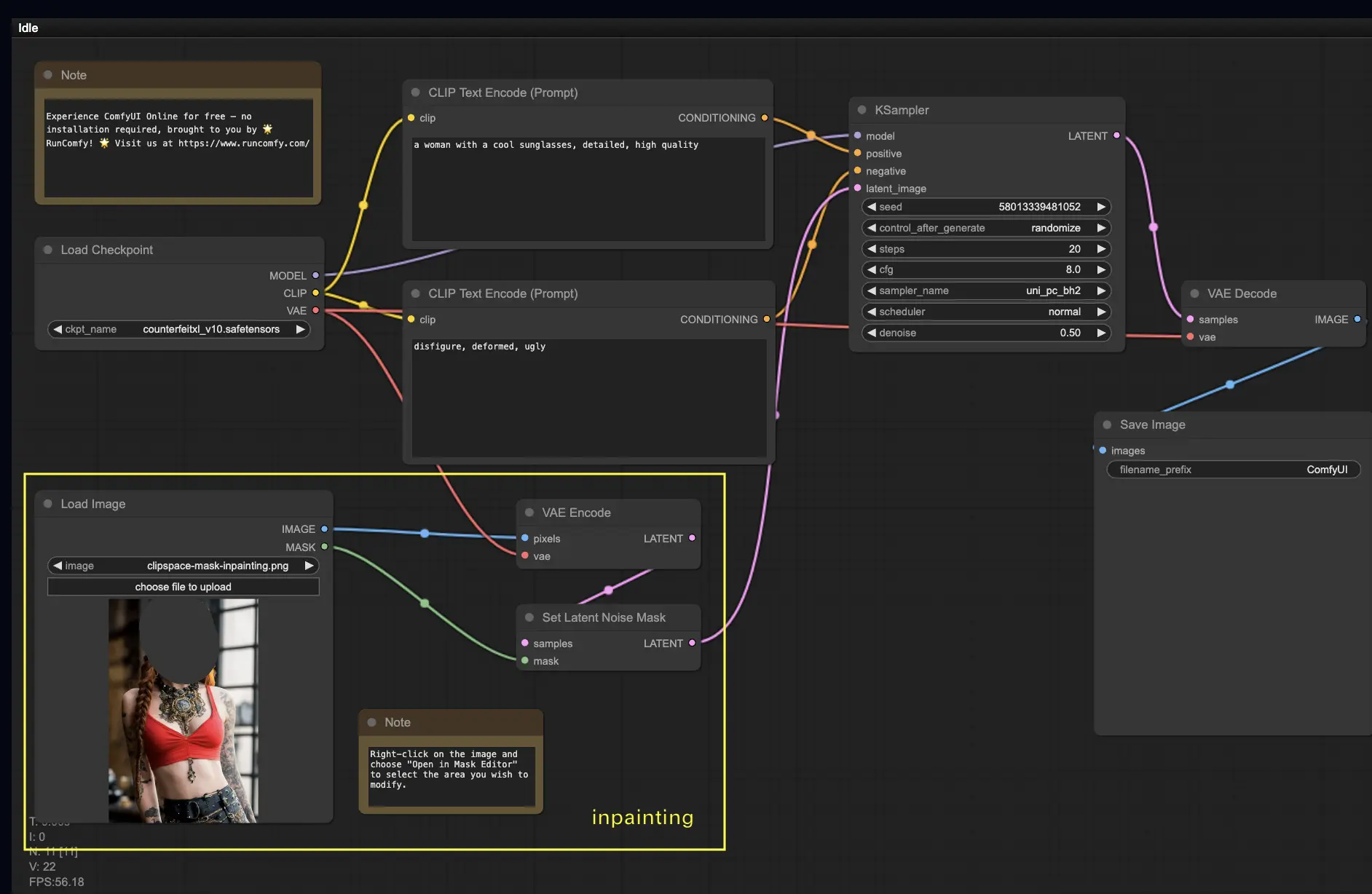
5. ComfyUI Inpainting 🎨
Tauchen wir in etwas Komplexeres ein: Inpainting! Wenn Sie ein tolles Bild haben, aber bestimmte Teile modifizieren möchten, ist Inpainting die beste Methode. Probieren Sie es hier aus!
So verwenden Sie den Inpainting-Workflow:
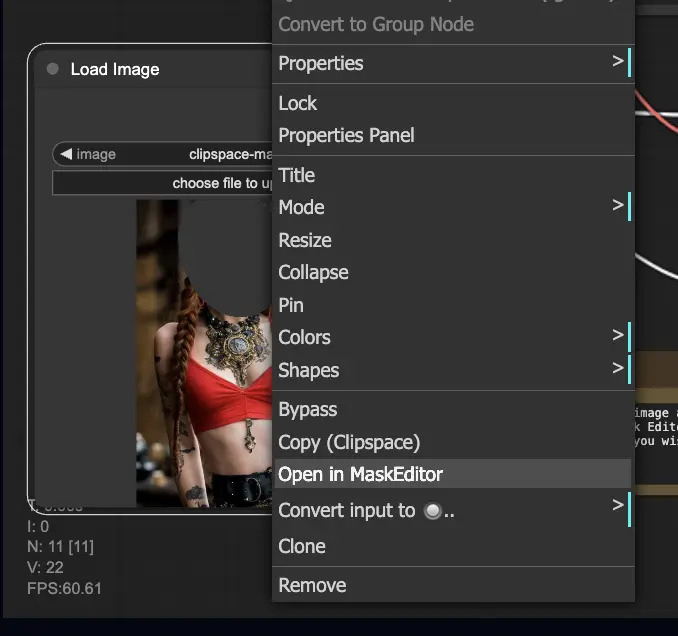
- Laden Sie ein Bild hoch, das Sie inpainting möchten.
- Klicken Sie mit der rechten Maustaste auf das Bild und wählen Sie "Open in MaskEditor". Maskieren Sie den zu regenerierenden Bereich und klicken Sie dann auf "Save to node".
- Wählen Sie ein Checkpoint-Modell aus:
- Dieser Workflow funktioniert nur mit einem Standard-Stable-Diffusion-Modell, nicht mit einem Inpainting-Modell.
- Wenn Sie ein Inpainting-Modell verwenden möchten, wechseln Sie bitte die Knoten "VAE Encode" und "Set Noise Latent Mask" zum Knoten "VAE Encode (Inpaint)", der speziell für Inpainting-Modelle entwickelt wurde.
- Passen Sie den Inpainting-Prozess an:
- Im Knoten CLIP Text Encode (Prompt) können Sie zusätzliche Informationen eingeben, um das Inpainting zu steuern. Beispielsweise können Sie den Stil, das Thema oder die Elemente angeben, die Sie in den Inpainting-Bereich einbeziehen möchten.
- Stellen Sie die ursprüngliche Entrauschungsstärke (Entrauschung) ein, z.B. 0,6.
- Drücken Sie Queue Prompt, um das Inpainting durchzuführen.
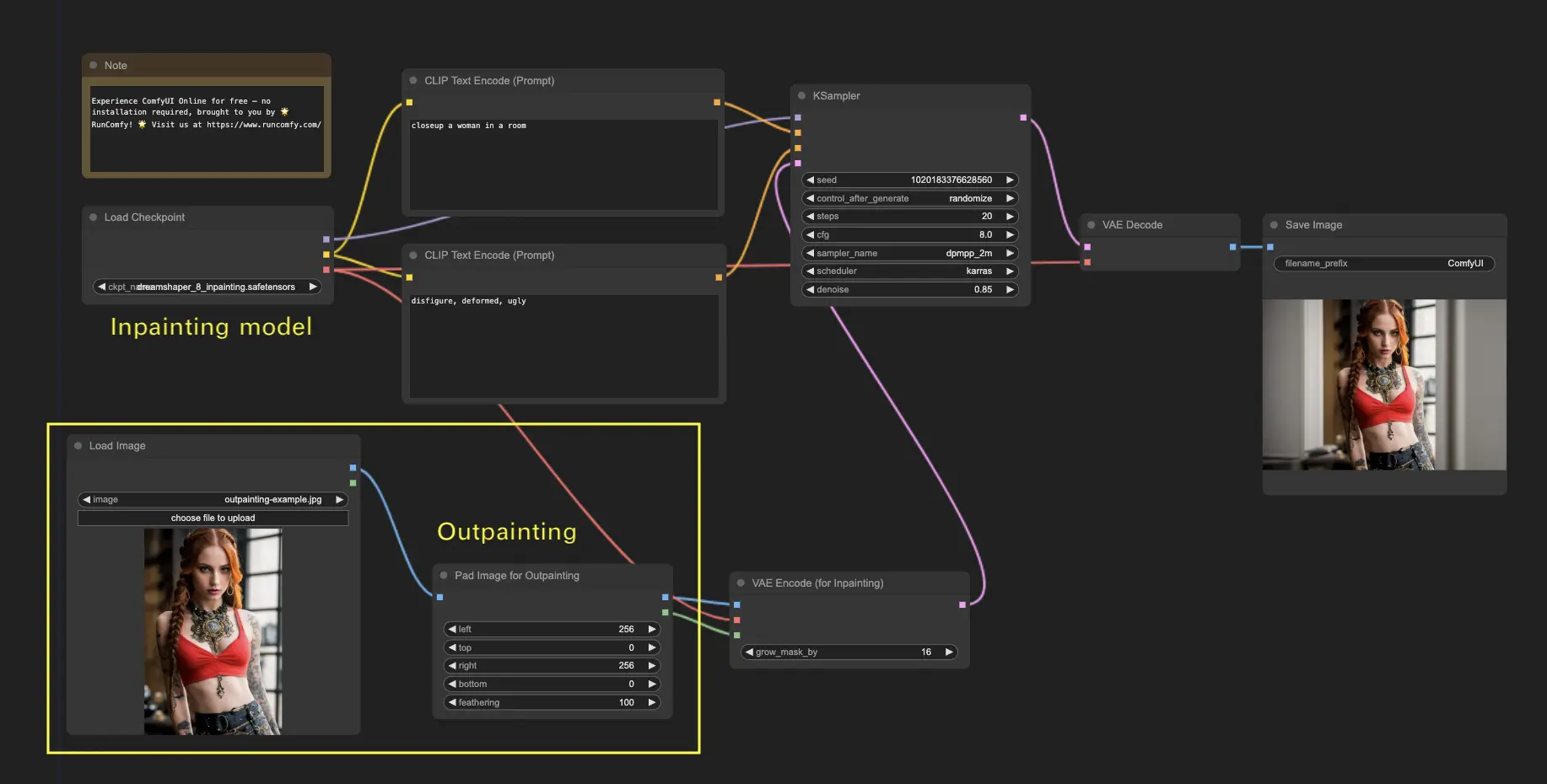
6. ComfyUI Outpainting 🖌️
Outpainting ist eine weitere spannende Technik, mit der Sie Ihre Bilder über die ursprünglichen Grenzen hinaus erweitern können. 🌆 Es ist, als hätten Sie eine unendliche Leinwand zum Arbeiten!
So verwenden Sie den ComfyUI Outpainting-Workflow:
- Beginnen Sie mit einem Bild, das Sie erweitern möchten.
- Fügen Sie den Knoten Pad Image for Outpainting zu Ihrem Workflow hinzu.
- Konfigurieren Sie die Outpainting-Einstellungen:
- left, top, right, bottom: Geben Sie die Anzahl der Pixel an, die in jede Richtung erweitert werden sollen.
- feathering: Passen Sie die Weichheit des Übergangs zwischen dem Originalbild und dem outgemalten Bereich an. Höhere Werte erzeugen einen weicheren Übergang, können aber einen Schmiereffekt hervorrufen.
- Passen Sie den Outpainting-Prozess an:
- Im Knoten CLIP Text Encode (Prompt) können Sie zusätzliche Informationen eingeben, um das Outpainting zu steuern. Beispielsweise können Sie den Stil, das Thema oder die Elemente angeben, die Sie in den erweiterten Bereich einbeziehen möchten.
- Experimentieren Sie mit verschiedenen Prompts, um die gewünschten Ergebnisse zu erzielen.
- Optimieren Sie den Knoten VAE Encode (for Inpainting):
- Passen Sie den Parameter grow_mask_by an, um die Größe der Outpainting-Maske zu steuern. Ein Wert größer als 10 wird für optimale Ergebnisse empfohlen.
- Drücken Sie Queue Prompt, um den Outpainting-Prozess zu starten.
Für weitere Premium-Inpainting-/Outpainting-Workflows besuchen Sie unsere 🌟ComfyUI-Workflow-Liste🌟
7. ComfyUI-Hochskalierung ⬆️
Als Nächstes werden wir die ComfyUI-Hochskalierung erkunden. Wir stellen drei grundlegende Workflows vor, mit denen Sie effizient hochskalieren können.
Es gibt zwei Hauptmethoden zur Hochskalierung:
- Hochskalierung Pixel: Direkte Hochskalierung des sichtbaren Bildes.
- Eingabe: Bild, Ausgabe: hochskaliertes Bild
- Hochskalierung Latent: Hochskalierung des unsichtbaren latenten Raumbildes.
- Eingabe: latent, Ausgabe: hochskalierter Latent (erfordert Dekodierung, um ein sichtbares Bild zu werden)
7.1. Hochskalierung Pixel 🖼️
Zwei Möglichkeiten, dies zu erreichen:
- Verwendung von Algorithmen: Schnellste Generierungsgeschwindigkeit, aber geringfügig schlechtere Ergebnisse im Vergleich zu Modellen.
- Verwendung von Modellen: Bessere Ergebnisse, aber langsamere Generierungszeit.
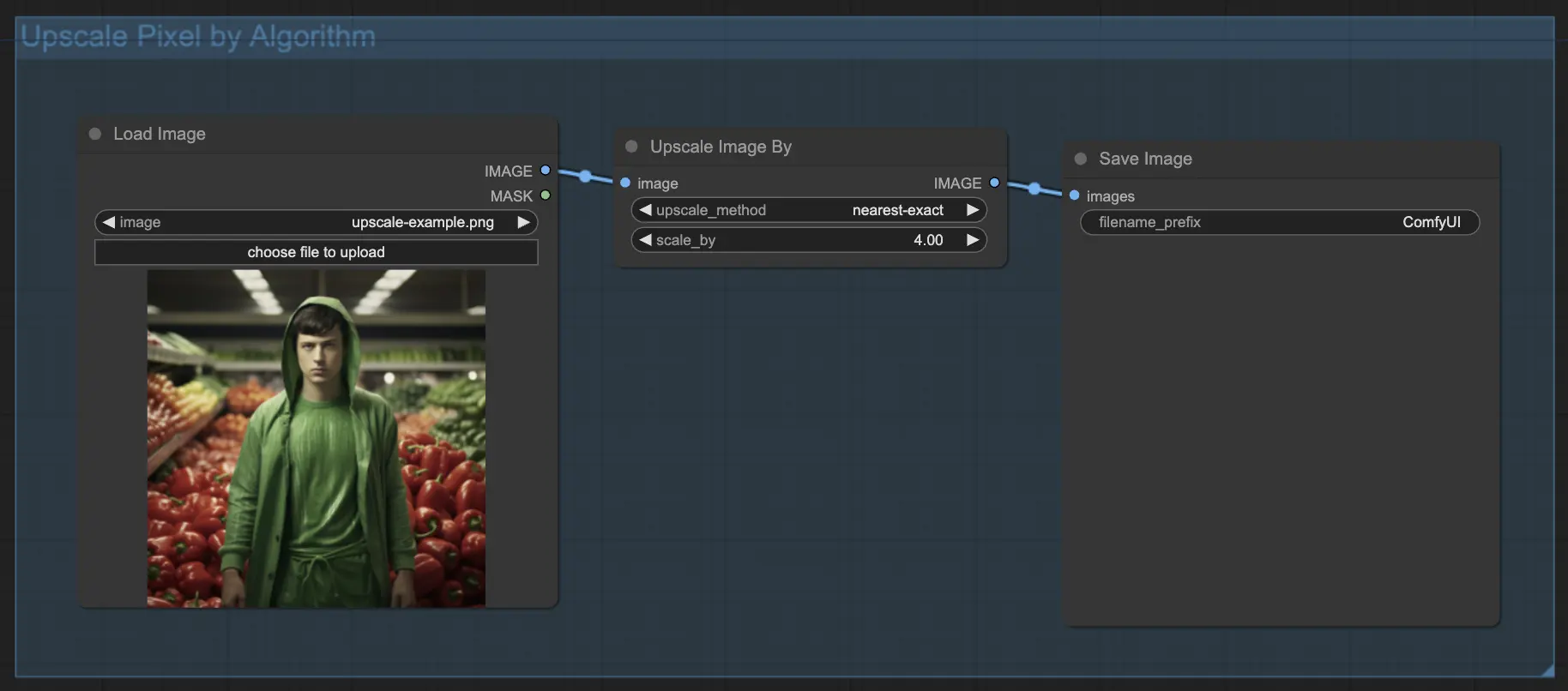
7.1.1. Hochskalierung Pixel durch Algorithmus 🧮
- Fügen Sie den Knoten Upscale Image by hinzu.
- Methodenparameter: Wählen Sie den Hochskalierungsalgorithmus aus (bicubic, bilinear, nearest-exact).
- Skalierungsparameter: Geben Sie den Hochskalierungsfaktor an (z.B. 2 für 2x).
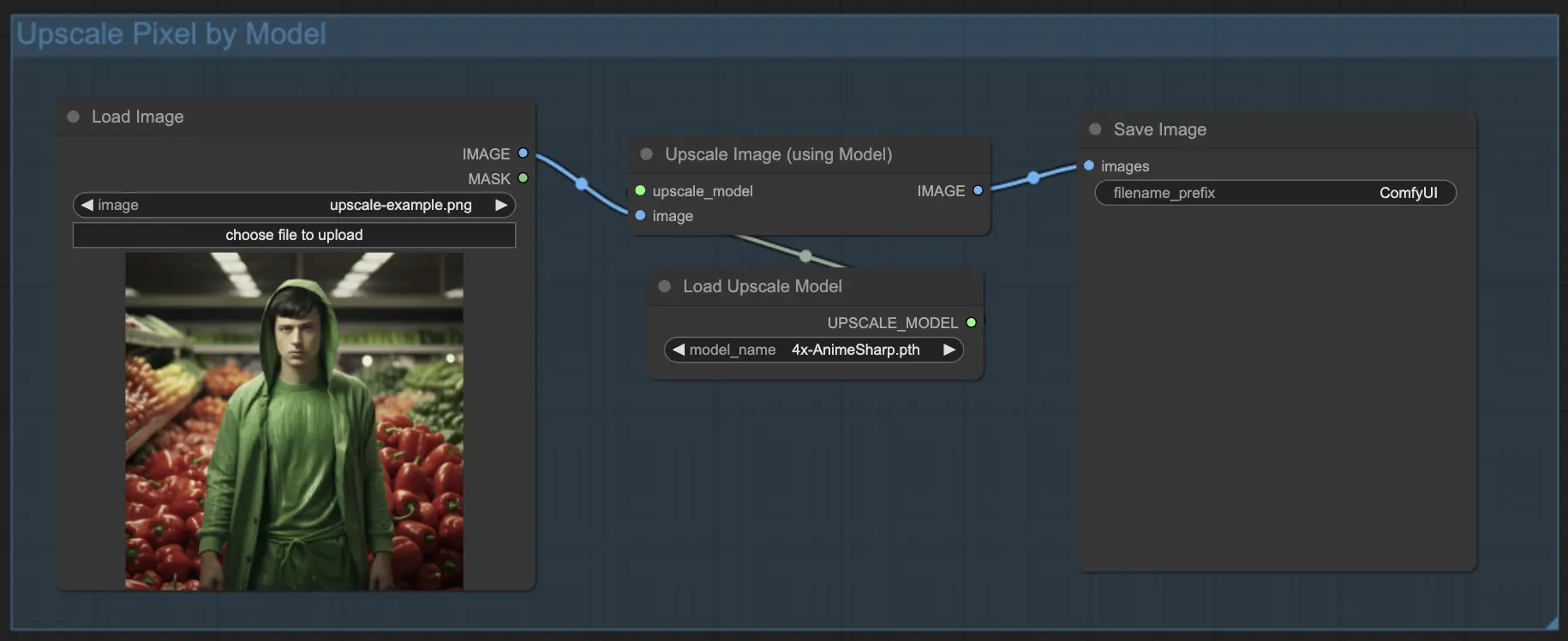
7.1.2. Hochskalierung Pixel durch Modell 🤖
- Fügen Sie den Knoten Upscale Image (using Model) hinzu.
- Fügen Sie den Knoten Load Upscale Model hinzu.
- Wählen Sie ein für Ihren Bildtyp geeignetes Modell aus (z.B. Anime oder Realität).
- Wählen Sie den Hochskalierungsfaktor aus (X2 oder X4).
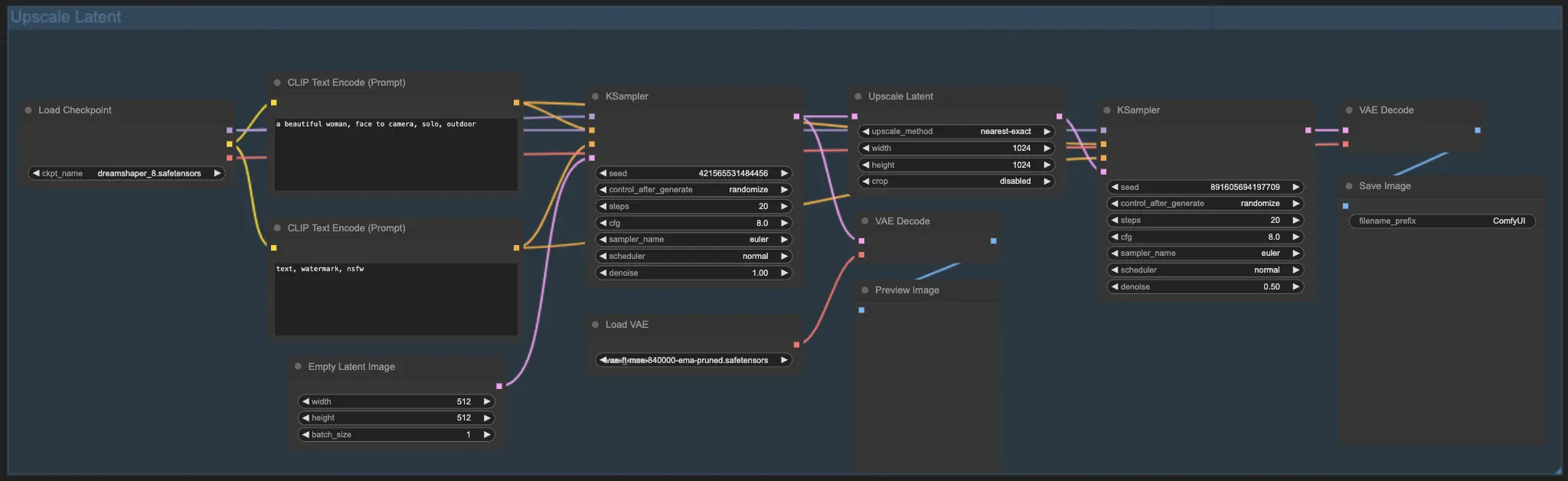
7.2. Hochskalierung Latent ⚙️
Eine weitere Hochskalierungsmethode ist die Hochskalierung Latent, auch bekannt als Hi-res Latent Fix Upscale, bei der direkt im latenten Raum hochskaliert wird.
7.3. Hochskalierung Pixel vs. Hochskalierung Latent 🆚
- Hochskalierung Pixel: Vergrößert nur das Bild, ohne neue Informationen hinzuzufügen. Schnellere Generierung, kann aber einen Schmiereffekt haben und Details fehlen.
- Hochskalierung Latent: Neben der Vergrößerung werden auch einige der ursprünglichen Bildinformationen geändert und Details angereichert. Kann vom Originalbild abweichen und hat eine langsamere Generierungsgeschwindigkeit.
Für weitere Premium-Restore-/Upscale-Workflows besuchen Sie unsere 🌟ComfyUI-Workflow-Liste🌟
8. ComfyUI ControlNet 🎮
Machen Sie sich bereit, Ihre KI-Kunst mit ControlNet, einer bahnbrechenden Technologie, die die Bildgenerierung revolutioniert, auf die nächste Stufe zu heben!
ControlNet ist wie ein Zauberstab 🪄, der Ihnen eine beispiellose Kontrolle über Ihre KI-generierten Bilder verleiht. Es arbeitet Hand in Hand mit leistungsstarken Modellen wie Stable Diffusion, erweitert deren Fähigkeiten und ermöglicht Ihnen, den Bilderstellungsprozess wie nie zuvor zu steuern!
Stellen Sie sich vor, Sie könnten die Kanten, menschlichen Posen, Tiefen oder sogar Segmentierungskarten Ihres gewünschten Bildes festlegen. 🌠 Mit ControlNet können Sie genau das tun!
Wenn Sie tiefer in die Welt von ControlNet eintauchen und sein volles Potenzial entfesseln möchten, sind Sie bei uns genau richtig. Schauen Sie sich unser detailliertes Tutorial zum Meistern von ControlNet in ComfyUI! 📚 Es ist vollgepackt mit Schritt-für-Schritt-Anleitungen und inspirierenden Beispielen, die Ihnen helfen, ein ControlNet-Profi zu werden. 🏆
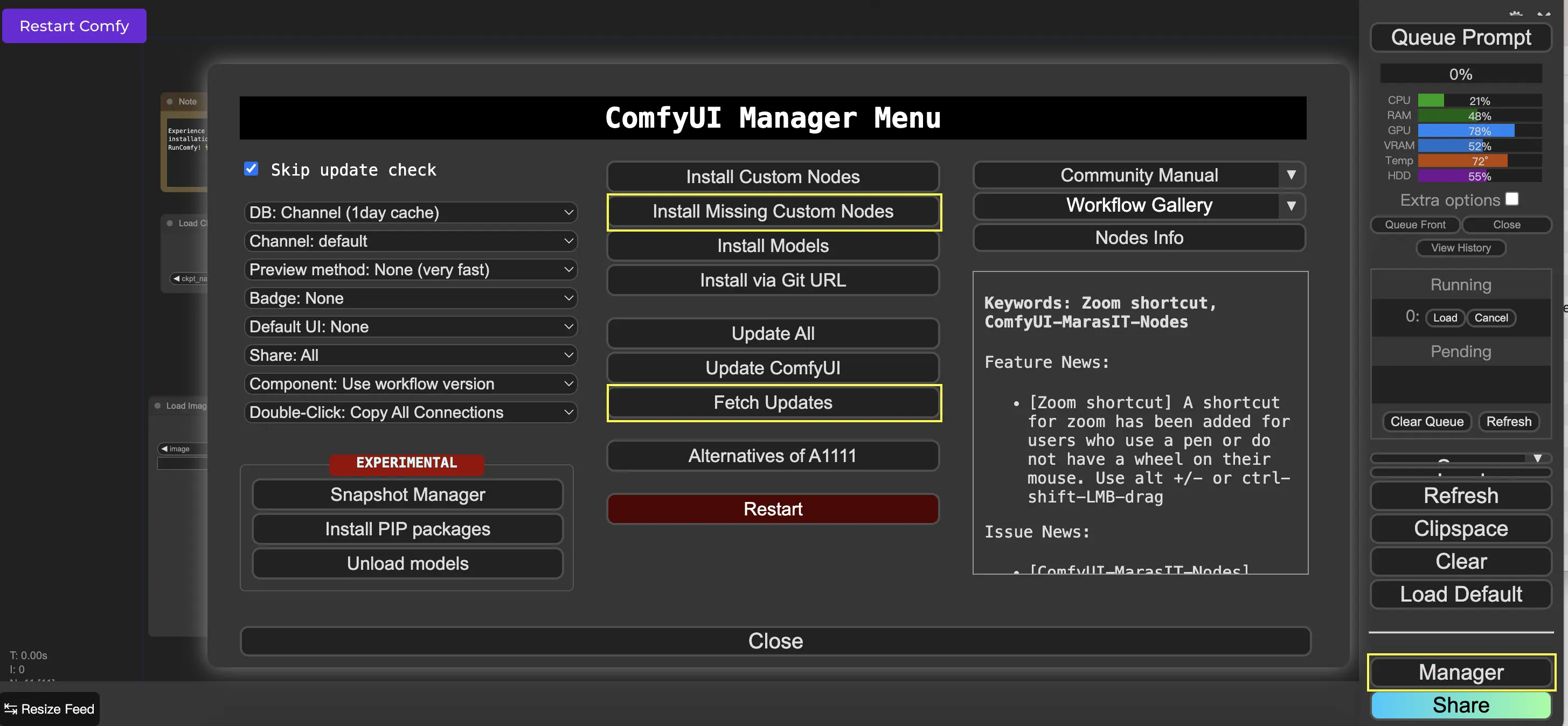
9. ComfyUI Manager 🛠️
ComfyUI Manager ist ein benutzerdefinierter Knoten, mit dem Sie andere benutzerdefinierte Knoten über die ComfyUI-Oberfläche installieren und aktualisieren können. Die Schaltfläche Manager finden Sie im Menü Queue Prompt.
9.1. So installieren Sie fehlende benutzerdefinierte Knoten 📥
Wenn ein Workflow benutzerdefinierte Knoten erfordert, die Sie nicht installiert haben, gehen Sie wie folgt vor:
- Klicken Sie im Menü auf Manager.
- Klicken Sie auf Install Missing Custom Nodes.
- Starten Sie ComfyUI vollständig neu.
- Aktualisieren Sie den Browser.
9.2. So aktualisieren Sie benutzerdefinierte Knoten 🔄
- Klicken Sie im Menü auf Manager.
- Klicken Sie auf Fetch Updates (kann eine Weile dauern).
- Klicken Sie auf Install Custom Nodes.
- Wenn ein Update verfügbar ist, erscheint neben dem installierten benutzerdefinierten Knoten eine Schaltfläche Update.
- Klicken Sie auf Update, um den Knoten zu aktualisieren.
- Starten Sie ComfyUI neu.
- Aktualisieren Sie den Browser.
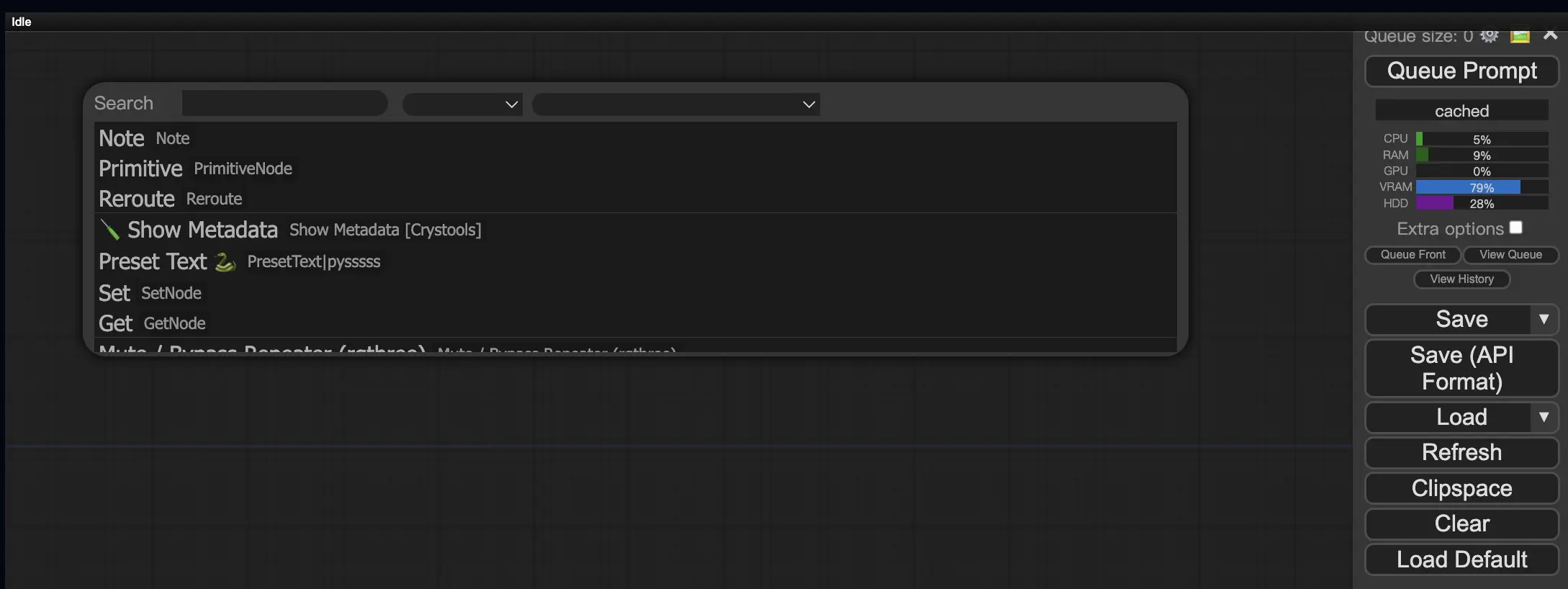
9.3. So laden Sie benutzerdefinierte Knoten in Ihren Workflow 🔍
Doppelklicken Sie auf einen leeren Bereich, um ein Menü zum Suchen nach Knoten aufzurufen.
10. ComfyUI Embeddings 📝
Embeddings, auch bekannt als textuelle Inversion, sind eine leistungsstarke Funktion in ComfyUI, mit der Sie benutzerdefinierte Konzepte oder Stile in Ihre KI-generierten Bilder einfügen können. 💡 Es ist, als würde man der KI ein neues Wort oder eine neue Phrase beibringen und es mit spezifischen visuellen Merkmalen verknüpfen.
Um Embeddings in ComfyUI zu verwenden, geben Sie einfach "embedding:" gefolgt vom Namen Ihres Embeddings in das Feld für positive oder negative Prompts ein. Zum Beispiel:
embedding: BadDream
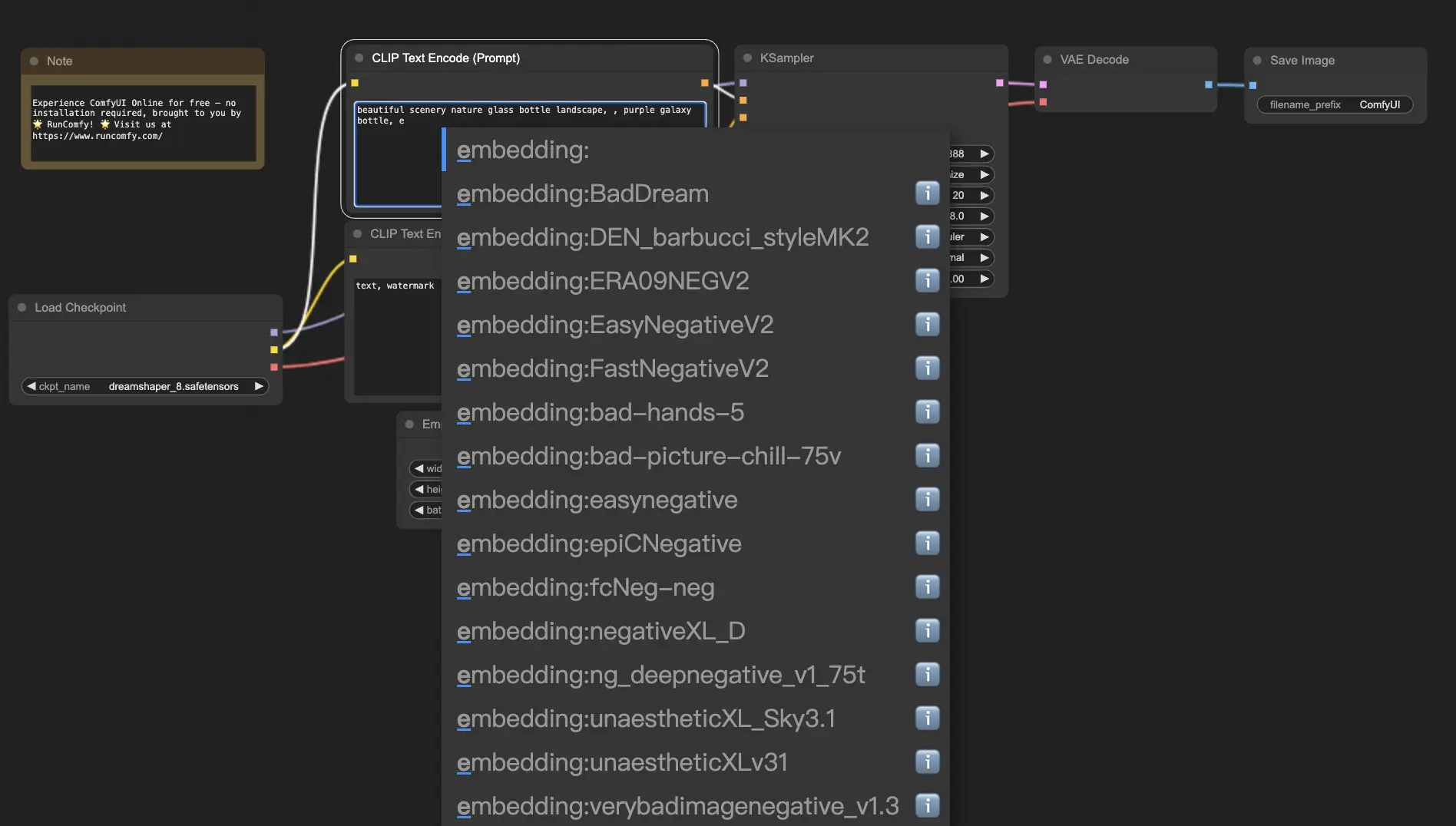
Wenn Sie diesen Prompt verwenden, sucht ComfyUI im Ordner ComfyUI > models > embeddings nach einer Embedding-Datei mit dem Namen "BadDream". 📂 Wenn es eine Übereinstimmung findet, wendet es die entsprechenden visuellen Merkmale auf Ihr generiertes Bild an.
Embeddings sind eine großartige Möglichkeit, Ihre KI-Kunst zu personalisieren und bestimmte Stile oder Ästhetiken zu erreichen. 🎨 Sie können Ihre eigenen Embeddings erstellen, indem Sie sie mit einer Reihe von Bildern trainieren, die das gewünschte Konzept oder den gewünschten Stil darstellen.
10.1. Embedding mit Autovervollständigung 🔠
Es kann mühsam sein, sich die genauen Namen Ihrer Embeddings zu merken, insbesondere wenn Sie eine große Sammlung haben. 😅 Hier kommt der benutzerdefinierte Knoten ComfyUI-Custom-Scripts zur Rettung!
So aktivieren Sie die automatische Vervollständigung von Embedding-Namen:
- Öffnen Sie den ComfyUI Manager, indem Sie im oberen Menü auf "Manager" klicken.
- Gehen Sie zu "Install Custom nodes" und suchen Sie nach "ComfyUI-Custom-Scripts".
- Klicken Sie auf "Install", um den benutzerdefinierten Knoten zu Ihrem ComfyUI-Setup hinzuzufügen.
- Starten Sie ComfyUI neu, um die Änderungen zu übernehmen.
Sobald Sie den Knoten ComfyUI-Custom-Scripts installiert haben, erleben Sie eine benutzerfreundlichere Art, Embeddings zu verwenden. 😊 Beginnen Sie einfach mit der Eingabe von "embedding:" in einem Prompt-Feld und es erscheint eine Liste der verfügbaren Embeddings. Sie können dann das gewünschte Embedding aus der Liste auswählen und sparen so Zeit und Mühe!
10.2. Embedding-Gewichtung ⚖️
Wussten Sie, dass Sie die Stärke Ihrer Embeddings steuern können? 💪 Da Embeddings im Wesentlichen Schlüsselwörter sind, können Sie Gewichtungen auf sie anwenden, genau wie Sie es mit regulären Schlüsselwörtern in Ihren Prompts tun würden.
Um die Gewichtung eines Embeddings anzupassen, verwenden Sie folgende Syntax:
(embedding: BadDream:1.2)
In diesem Beispiel wird die Gewichtung des Embeddings "BadDream" um 20% erhöht. Höhere Gewichtungen (z.B. 1,2) lassen das Embedding also stärker hervortreten, während niedrigere Gewichtungen (z.B. 0,8) seinen Einfluss verringern. 🎚️ So haben Sie noch mehr Kontrolle über das Endergebnis!
11. ComfyUI LoRA 🧩
LoRA, kurz für Low-rank Adaptation, ist eine weitere spannende Funktion in ComfyUI, mit der Sie Ihre Checkpoint-Modelle modifizieren und optimieren können. 🎨 Es ist, als würde man ein kleines, spezialisiertes Modell auf das Basismodell aufsetzen, um bestimmte Stile zu erreichen oder benutzerdefinierte Elemente einzubauen.
LoRA-Modelle sind kompakt und effizient, was sie einfach zu verwenden und zu teilen macht. Sie werden häufig für Aufgaben wie die Modifikation des künstlerischen Stils eines Bildes oder das Einfügen einer bestimmten Person oder eines Objekts in das generierte Ergebnis verwendet.
Wenn Sie ein LoRA-Modell auf ein Checkpoint-Modell anwenden, modifiziert es die MODEL- und CLIP-Komponenten, während der VAE (Variational Autoencoder) unverändert bleibt. Das bedeutet, dass sich das LoRA auf die Anpassung des Inhalts und des Stils des Bildes konzentriert, ohne dessen Gesamtstruktur zu verändern.
11.1. So verwenden Sie LoRA 🔧
Die Verwendung von LoRA in ComfyUI ist unkompliziert. Werfen wir einen Blick auf die einfachste Methode:
- Wählen Sie ein Checkpoint-Modell aus, das als Basis für Ihre Bildgenerierung dient.
- Wählen Sie ein LoRA-Modell aus, das Sie anwenden möchten, um den Stil zu modifizieren oder bestimmte Elemente einzufügen.
- Überarbeiten Sie die positiven und negativen Prompts, um den Bilderzeugungsprozess zu steuern.
- Klicken Sie auf "Queue Prompt", um die Generierung des Bildes mit dem angewendeten LoRA zu starten. ▶
ComfyUI kombiniert dann das Checkpoint-Modell und das LoRA-Modell, um ein Bild zu erstellen, das die angegebenen Prompts widerspiegelt und die durch das LoRA eingeführten Modifikationen enthält.
11.2. Mehrere LoRAs 🧩🧩
Aber was ist, wenn Sie mehrere LoRAs auf ein einziges Bild anwenden möchten? Kein Problem! ComfyUI ermöglicht es Ihnen, zwei oder mehr LoRAs im selben Text-zu-Bild-Workflow zu verwenden.
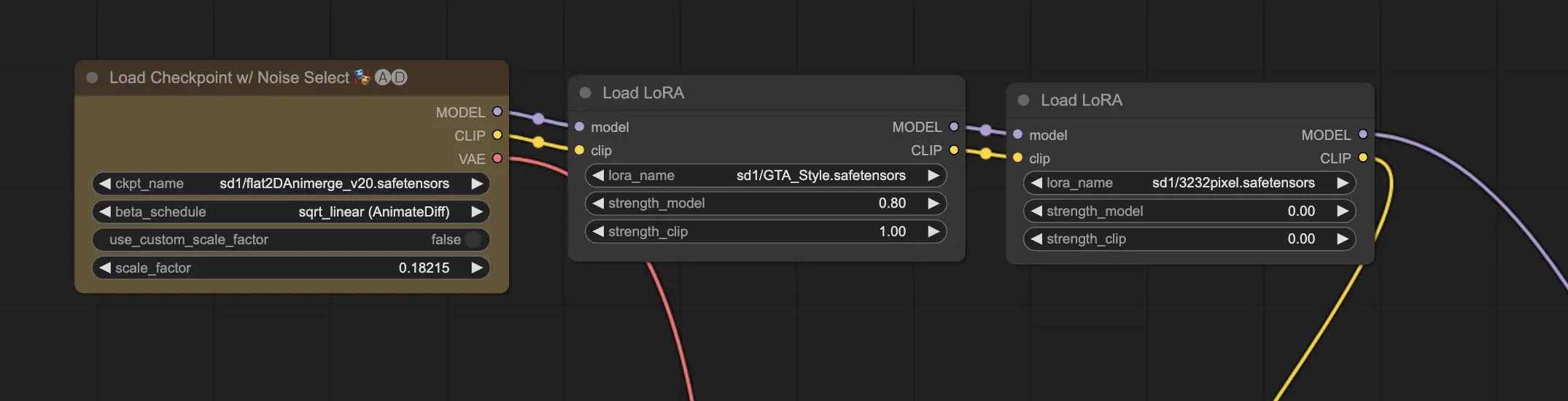
Der Prozess ähnelt der Verwendung eines einzelnen LoRA, aber Sie müssen stattdessen mehrere LoRA-Modelle auswählen. ComfyUI wendet die LoRAs nacheinander an, d.h. jedes LoRA baut auf den Modifikationen des vorherigen auf.
Dies eröffnet eine Welt von Möglichkeiten, um verschiedene Stile, Elemente und Modifikationen in Ihren KI-generierten Bildern zu kombinieren. 🌍💡 Experimentieren Sie mit verschiedenen LoRA-Kombinationen, um einzigartige und kreative Ergebnisse zu erzielen!
12. Abkürzungen und Tricks für ComfyUI ⌨️🖱️
12.1. Kopieren und Einfügen 📋
- Wählen Sie einen Knoten aus und drücken Sie Strg+C zum Kopieren.
- Drücken Sie Strg+V zum Einfügen.
- Drücken Sie Strg+Shift+V zum Einfügen mit intakten Eingangsverbindungen.
12.2. Verschieben mehrerer Knoten 🖱️
- Erstellen Sie eine Gruppe, um eine Reihe von Knoten gemeinsam zu verschieben.
- Alternativ halten Sie Strg gedrückt und ziehen Sie, um ein Feld zum Auswählen mehrerer Knoten zu erstellen, oder halten Sie Strg gedrückt, um mehrere Knoten einzeln auszuwählen.
- Um die ausgewählten Knoten zu verschieben, halten Sie Shift gedrückt und bewegen Sie die Maus.
12.3. Umgehen eines Knotens 🔇
- Deaktivieren Sie einen Knoten vorübergehend, indem Sie ihn stummschalten. Wählen Sie einen Knoten aus und drücken Sie Strg+M.
- Es gibt keine Tastenkombination zum Stummschalten einer Gruppe. Wählen Sie im Kontextmenü die Option Bypass Group Node oder schalten Sie den ersten Knoten in der Gruppe stumm, um sie zu deaktivieren.
12.4. Minimieren eines Knotens 🔍
- Klicken Sie auf den Punkt in der oberen linken Ecke des Knotens, um ihn zu minimieren.
12.5. Bild erzeugen ▶️
- Drücken Sie Strg+Enter, um den Workflow in die Warteschlange zu stellen und Bilder zu generieren.
12.6. Eingebetteter Workflow 🖼️
- ComfyUI speichert den gesamten Workflow in den Metadaten der PNG-Datei, die es generiert. Um den Workflow zu laden, ziehen Sie das Bild per Drag-and-Drop in ComfyUI.
12.7. Seeds fixieren, um Zeit zu sparen ⏰
- ComfyUI führt einen Knoten nur dann erneut aus, wenn sich die Eingabe ändert. Wenn Sie an einer langen Kette von Knoten arbeiten, sparen Sie Zeit, indem Sie den Seed fixieren, um zu vermeiden, dass vorgelagerte Ergebnisse erneut generiert werden.
13. ComfyUI Online 🚀
Herzlichen Glückwunsch zum Abschluss dieses Einsteiger-Leitfadens für ComfyUI! 🙌 Sie sind jetzt bereit, in die aufregende Welt der KI-Kunst einzutauchen. Aber warum sich mit der Installation herumschlagen, wenn man sofort loslegen kann? 🤔
Bei RunComfy haben wir es Ihnen leicht gemacht, ComfyUI online zu nutzen, ohne jegliche Einrichtung. Unser ComfyUI Online-Service ist mit über 200 beliebten Knoten und Modellen sowie mehr als 50 beeindruckenden Workflows vorgeladen, die Ihre Kreationen inspirieren.
🌟 Egal, ob Sie ein Anfänger oder ein erfahrener KI-Künstler sind, RunComfy bietet alles, was Sie brauchen, um Ihre künstlerischen Visionen zum Leben zu erwecken. 💡 Warten Sie nicht länger – probieren Sie ComfyUI Online jetzt aus und erleben Sie die Kraft der KI-Kunst-Erstellung direkt vor Ihren Fingerspitzen! 🚀