AnimateDiff + IPAdapter V1 | Imagen a Video
IPAdapter es una solución ligera que mejora los modelos preentrenados con capacidades de indicación de imágenes. Al usar AnimateDiff junto con IPAdapter, puede generar sin esfuerzo animaciones más controlables a partir de imágenes de referencia.ComfyUI AnimateDiff IPAdapter Flujo de trabajo
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI AnimateDiff IPAdapter Ejemplos
ComfyUI AnimateDiff IPAdapter Descripción
1. Flujo de trabajo de ComfyUI: AnimateDiff + IPAdapter | Imagen a Video
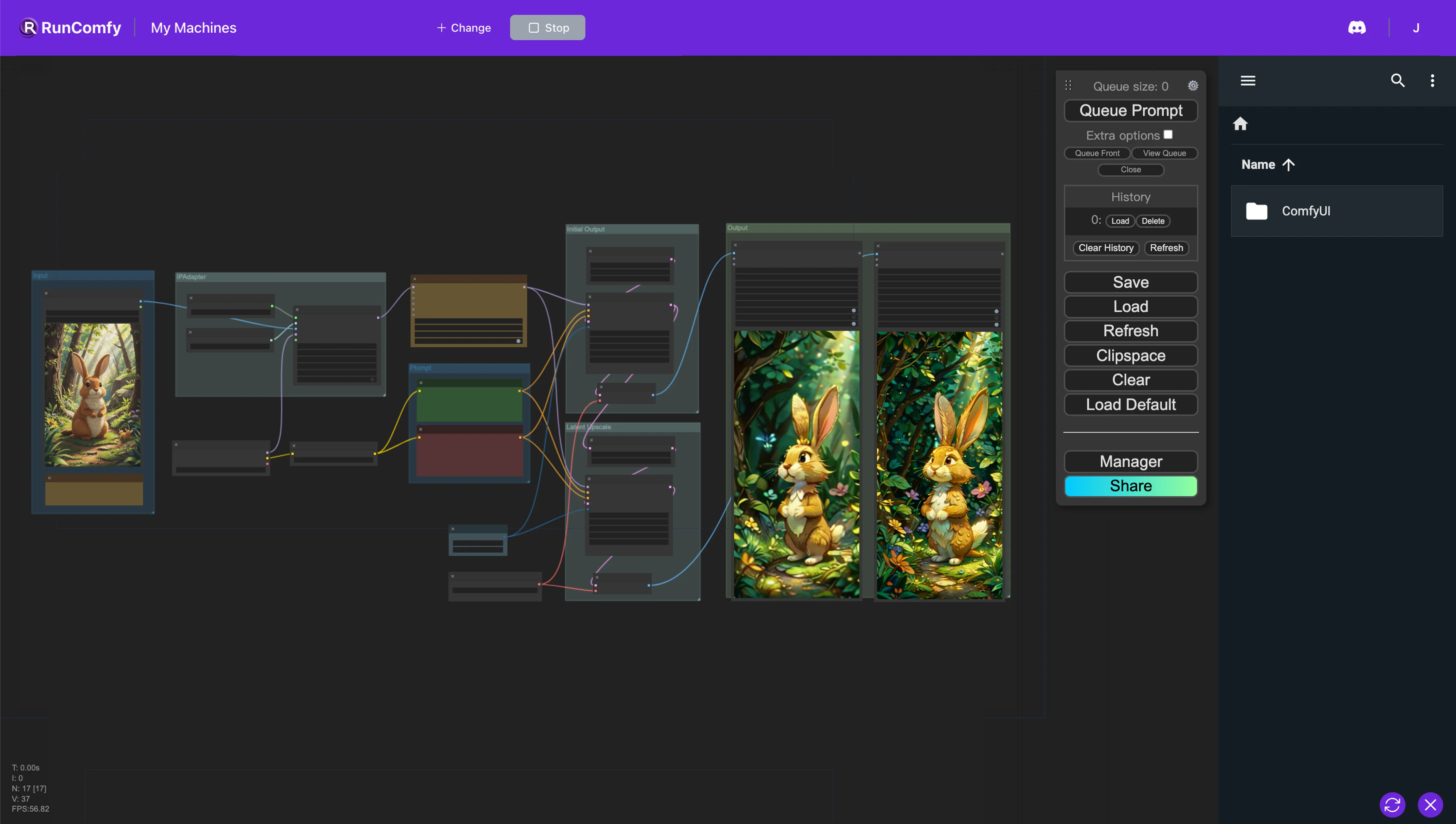
Este flujo de trabajo de ComfyUI está diseñado para crear animaciones a partir de imágenes de referencia utilizando AnimateDiff e IP-Adapter. El nodo AnimateDiff integra opciones de modelo y contexto para ajustar la dinámica de la animación. Por otro lado, el nodo IP-Adapter facilita el uso de imágenes como indicaciones de maneras que pueden imitar el estilo, la composición o las características faciales de la imagen de referencia, mejorando significativamente la personalización y la calidad de las animaciones o imágenes generadas.
2. Descripción general de AnimateDiff
Consulte los detalles sobre
3. Descripción general de IP-Adapter
3.1. Introducción a IP-Adapter
IP-Adapter significa "Image Prompt Adapter" (Adaptador de indicación de imágenes), un enfoque novedoso para mejorar los modelos de difusión de texto a imagen con la capacidad de usar indicaciones de imágenes en tareas de generación de imágenes. IP-Adapter tiene como objetivo abordar las deficiencias de las indicaciones de texto que a menudo requieren una ingeniería de indicaciones compleja para generar las imágenes deseadas. La introducción de indicaciones de imágenes, junto con el texto, permite una forma más intuitiva y efectiva de guiar el proceso de síntesis de imágenes.
Diferentes modelos de IP-Adapter
La suite IP-Adapter incluye una variedad de modelos, cada uno adaptado para casos de uso específicos y niveles de complejidad de síntesis de imágenes. Aquí hay una descripción general de los diferentes modelos disponibles:
3.1.1. Modelos v1.5
ip-adapter_sd15: El modelo estándar para la versión 1.5, que utiliza el poder de IP-Adapter para el acondicionamiento de imagen a imagen y la aumentación de indicaciones de texto.ip-adapter_sd15_light: Una versión más ligera del modelo estándar, optimizada para aplicaciones menos intensivas en recursos mientras aprovecha la tecnología IP-Adapter.ip-adapter-plus_sd15: Un modelo mejorado que produce imágenes más alineadas con la referencia original, mejorando los detalles finos.ip-adapter-plus-face_sd15: Similar a IP-Adapter Plus, con un enfoque en la replicación de características faciales más precisas en las imágenes generadas.ip-adapter-full-face_sd15: Un modelo que enfatiza los detalles de la cara completa, probablemente ofreciendo un efecto de "intercambio de caras" con alta fidelidad.ip-adapter_sd15_vit-G: Una variante del modelo estándar que utiliza el codificador de imágenes Vision Transformer (ViT) BigG para una extracción de características de imagen más detallada.
3.1.2. Modelos SDXL
ip-adapter_sdxl: El modelo base para SDXL, que está diseñado para manejar indicaciones de imágenes más grandes y complejas.ip-adapter_sdxl_vit-h: El modelo SDXL emparejado con el codificador de imágenes ViT H, equilibrando el rendimiento con la eficiencia computacional.ip-adapter-plus_sdxl_vit-h: Una versión avanzada del modelo SDXL con detalles y calidad mejorados de las indicaciones de imágenes.ip-adapter-plus-face_sdxl_vit-h: Una variante SDXL centrada en los detalles de la cara, ideal para proyectos donde la precisión facial es primordial.
3.1.3. Modelos FaceID
FaceID: Un modelo que utiliza InsightFace para extraer embeddings de Face ID, ofreciendo un enfoque único para la generación de imágenes relacionadas con la cara.FaceID Plus: Una versión mejorada del modelo FaceID, que combina InsightFace para las características faciales y la codificación de imágenes CLIP para las características faciales globales.FaceID Plus v2: Una iteración en FaceID Plus con un punto de control de modelo mejorado y la capacidad de establecer un peso en el embedding de imagen CLIP.FaceID Portrait: Un modelo similar a FaceID pero diseñado para aceptar múltiples imágenes de caras recortadas para un acondicionamiento facial más diverso.
3.1.4. Modelos FaceID SDXL
FaceID SDXL: La versión SDXL de FaceID, manteniendo el mismo modelo InsightFace que la v1.5 pero escalado para aplicaciones SDXL.FaceID Plus v2 SDXL: Una adaptación SDXL de FaceID Plus v2 para la generación de imágenes de alta definición con mayor fidelidad.
3.2. Características clave de IP-Adapter
3.2.1. Integración de indicaciones de texto e imagen: La capacidad única de IP-Adapter para usar indicaciones tanto de texto como de imágenes permite la generación de imágenes multimodales, proporcionando una herramienta versátil y poderosa para controlar las salidas del modelo de difusión.
3.2.2. Mecanismo de atención cruzada desacoplada: El IP-Adapter emplea una estrategia de atención cruzada desacoplada que mejora la eficiencia del modelo en el procesamiento de diversas modalidades al separar las características de texto e imagen.
3.2.3. Modelo ligero: A pesar de su funcionalidad integral, el IP-Adapter mantiene un recuento de parámetros relativamente bajo (22M), ofreciendo un rendimiento que rivaliza o supera al de los modelos de indicación de imagen ajustados.
3.2.4. Compatibilidad y generalización: El IP-Adapter está diseñado para una amplia compatibilidad con las herramientas controlables existentes y se puede aplicar a modelos personalizados derivados del mismo modelo base para una mayor generalización.
3.2.5. Control de estructura: IP-Adapter admite un control detallado de la estructura, permitiendo a los creadores guiar el proceso de generación de imágenes con mayor precisión.
3.2.6. Capacidades de imagen a imagen y de inpainting: Con soporte para la traducción de imagen a imagen guiada por imágenes y el inpainting, el IP-Adapter amplía el alcance de las aplicaciones posibles, permitiendo usos creativos y prácticos en una variedad de tareas de síntesis de imágenes.
3.2.7. Personalización con diferentes codificadores: El IP-Adapter permite el uso de varios codificadores, como OpenClip ViT H 14 y ViT BigG 14, para procesar imágenes de referencia. Esta flexibilidad facilita el manejo de diferentes resoluciones y complejidades de imágenes, lo que lo convierte en una herramienta versátil para los creadores que buscan adaptar el proceso de generación de imágenes a necesidades específicas o resultados deseados.
La incorporación de la tecnología IP-Adapter en proyectos de generación de imágenes no solo simplifica la creación de imágenes complejas y detalladas, sino que también mejora significativamente la calidad y fidelidad de las imágenes generadas con respecto a las indicaciones originales. Al cerrar la brecha entre las indicaciones de texto y de imágenes, IP-Adapter proporciona un enfoque poderoso, intuitivo y eficiente para controlar los matices de la síntesis de imágenes, convirtiéndolo en una herramienta indispensable en el arsenal de artistas digitales, diseñadores y creadores que trabajan dentro del flujo de trabajo de ComfyUI o cualquier otro contexto que exija una generación de imágenes personalizada de alta calidad.