Omost | Mejora la Creación de Imágenes
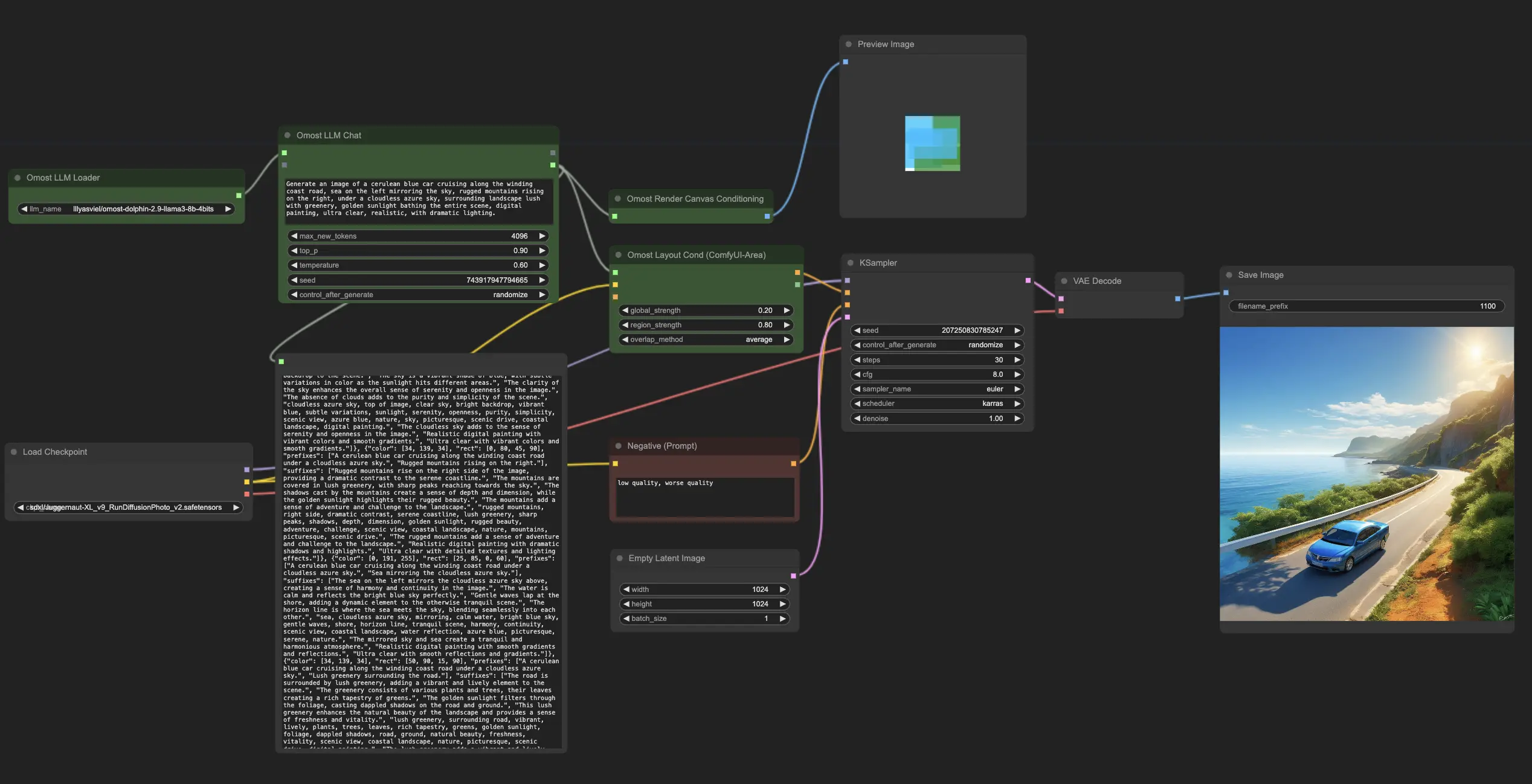
Omost aprovecha los Modelos de Lenguaje Grande para transformar la codificación en composiciones de imágenes detalladas. Al usar un Canvas estructurado y una ingeniería de prompts sofisticada, Omost garantiza una generación de imágenes precisa y eficienteComfyUI Omost Flujo de trabajo
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI Omost Ejemplos

ComfyUI Omost Descripción
1. ¿Qué es Omost?
Omost, abreviatura de "¡Tu imagen está casi lista!", es un proyecto innovador que convierte las capacidades de codificación de los Modelos de Lenguaje Grande (LLM) en generación de imágenes, o más precisamente, en capacidades de composición de imágenes. El nombre "Omost" tiene un doble significado: implica que cada vez que usas Omost, tu imagen está casi completa, y también significa "omni" (multi-modal) y "most" (sacando el máximo provecho).
Omost proporciona modelos LLM preentrenados que generan código para componer contenido visual de imágenes utilizando el agente virtual Canvas de Omost. Este Canvas luego puede ser renderizado por implementaciones específicas de generadores de imágenes para crear las imágenes finales. Omost está diseñado para simplificar y mejorar el proceso de generación de imágenes, haciéndolo accesible y eficiente para los artistas de IA.
2. ¿Cómo funciona Omost?
2.1. Canvas y Descripciones
Omost utiliza un Canvas virtual donde se describen y posicionan los elementos de la imagen. El Canvas está dividido en una cuadrícula de 9x9=81 posiciones, permitiendo una colocación precisa de los elementos. Estas posiciones se refinan aún más en cuadros delimitadores, proporcionando 729 ubicaciones diferentes posibles para cada elemento. Este enfoque estructurado asegura que los elementos se coloquen de manera precisa y consistente.
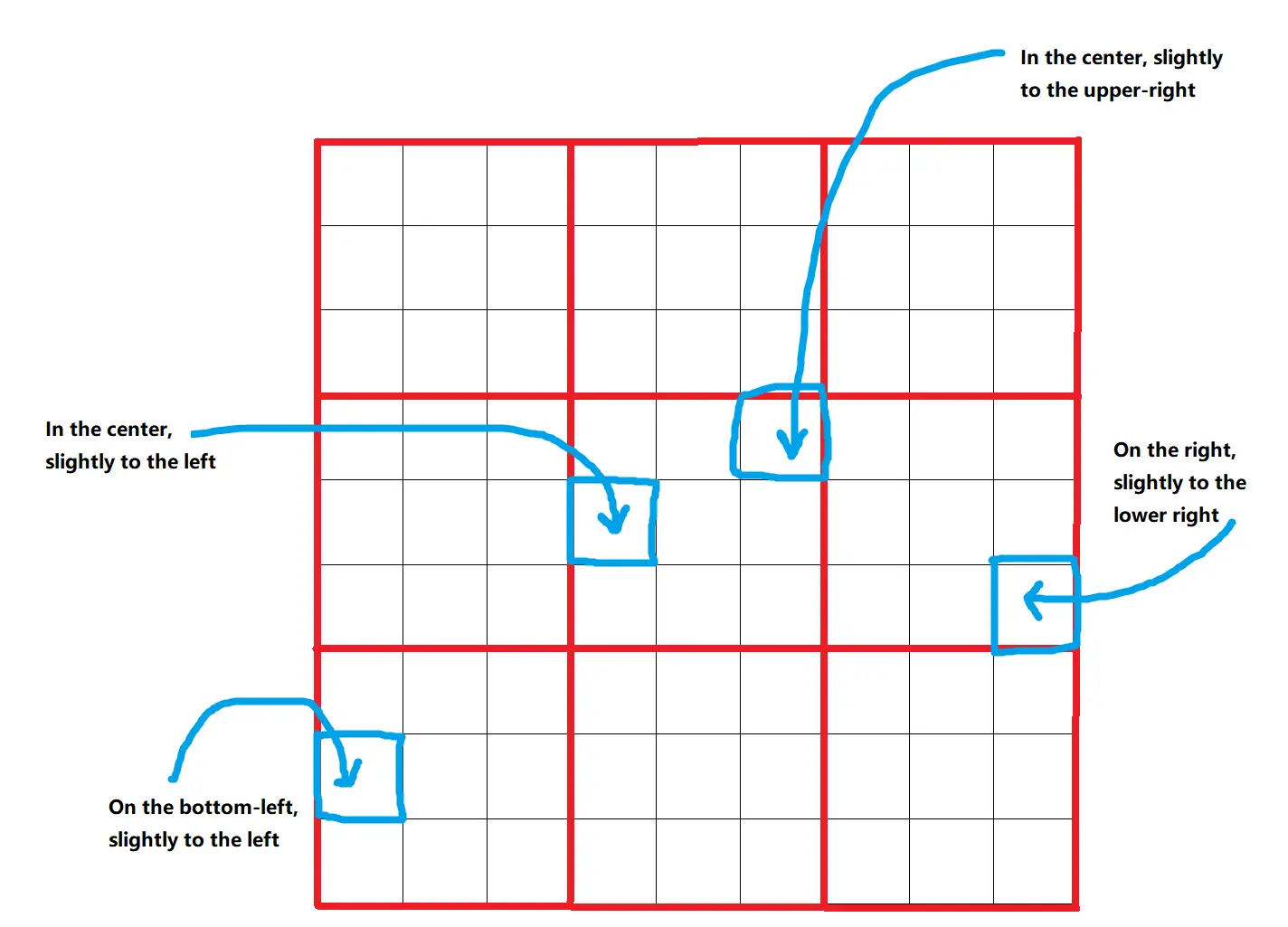
2.2. Profundidad y Color
A los elementos en el Canvas se les asigna un parámetro distance_to_viewer, que ayuda a ordenarlos en capas de fondo a primer plano. Este parámetro actúa como un indicador de profundidad relativa, asegurando que los elementos más cercanos aparezcan frente a aquellos que están más lejos. Además, el parámetro HTML_web_color_name proporciona una representación de color inicial para el renderizado, que puede ser refinada utilizando modelos de difusión. Este color inicial ayuda a visualizar la composición antes de afinarla.

2.3. Ingeniería de Prompts
Omost utiliza sub-prompts, que son descripciones breves y autónomas de elementos, para generar composiciones de imágenes detalladas y coherentes. Cada sub-prompt tiene menos de 75 tokens y describe un elemento de manera independiente. Estos sub-prompts se combinan en prompts completos para que el LLM los procese, asegurando que las imágenes generadas sean precisas y semánticamente ricas. Este método asegura que la codificación de texto sea eficiente y evita errores de truncamiento semántico.
2.4. Prompter Regional
Omost implementa técnicas avanzadas de manipulación de atención para manejar prompts regionales, asegurando que cada parte de la imagen se genere con precisión según las descripciones dadas. Técnicas como la manipulación de puntuaciones de atención aseguran que se fomente la activación dentro de las áreas enmascaradas, mientras que se desalienta fuera de ellas. Este control preciso sobre la atención resulta en una generación de imágenes de alta calidad y específica por región.
3. Explicación Detallada de los Nodos de ComfyUI Omost
3.1. Nodo de Carga de Omost LLM
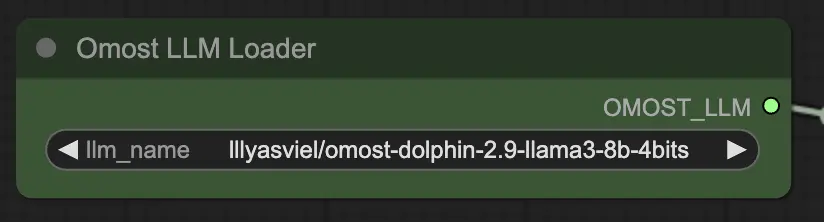
Parámetros de entrada del Nodo de Carga de Omost LLM
llm_name: El nombre del modelo LLM preentrenado a cargar. Las opciones disponibles incluyen:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
Este parámetro especifica qué modelo cargar, cada uno ofreciendo diferentes capacidades y optimizaciones.
Parámetros de salida del Nodo de Carga de Omost LLM
OMOST_LLM: El modelo LLM cargado.
Esta salida proporciona el LLM cargado, listo para generar descripciones y composiciones de imágenes.
3.2. Nodo de Chat de Omost LLM
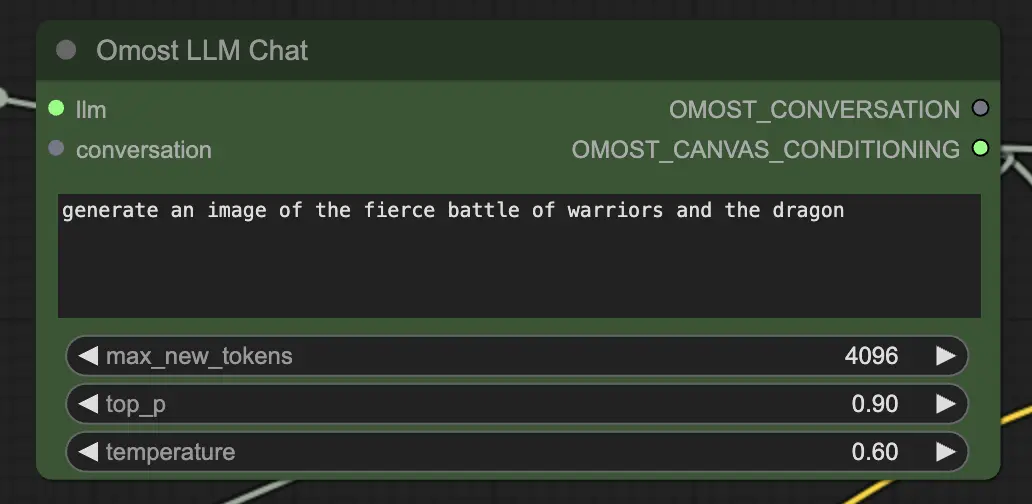
Parámetros de entrada del Nodo de Chat de Omost LLM
llm: El modelo LLM cargado por elOmostLLMLoader.text: El prompt de texto para generar una imagen. Esta es la entrada principal donde describes la escena o los elementos que deseas generar.max_new_tokens: Número máximo de nuevos tokens a generar. Esto controla la longitud del texto generado, permitiendo descripciones más detalladas con un número mayor.top_p: Controla la diversidad del resultado generado. Un valor más cercano a 1.0 incluye más posibilidades diversas, mientras que un valor menor se enfoca en los resultados más probables.temperature: Controla la aleatoriedad del resultado generado. Valores más altos resultan en resultados más aleatorios, mientras que valores más bajos hacen que el resultado sea más determinista.conversation(Opcional): Contexto de conversación anterior. Esto permite que el modelo continúe desde interacciones previas, manteniendo el contexto y la coherencia.
Parámetros de salida del Nodo de Chat de Omost LLM
OMOST_CONVERSATION: El historial de conversación, incluyendo la nueva respuesta. Esto ayuda a rastrear el diálogo y mantener el contexto a lo largo de múltiples interacciones.OMOST_CANVAS_CONDITIONING: Los parámetros de acondicionamiento del Canvas generados para el renderizado. Estos parámetros definen cómo se colocan y describen los elementos en el Canvas.
3.3. Nodo de Renderizado de Acondicionamiento del Canvas de Omost
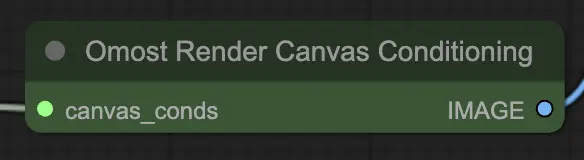
Parámetros de entrada del Nodo de Renderizado de Acondicionamiento del Canvas de Omost
canvas_conds: Los parámetros de acondicionamiento del Canvas. Estos parámetros incluyen descripciones detalladas y posiciones de elementos en el Canvas.
Parámetros de salida del Nodo de Renderizado de Acondicionamiento del Canvas de Omost
IMAGE: La imagen renderizada basada en el acondicionamiento del Canvas. Esta salida es la representación visual de la escena descrita, generada a partir de los parámetros de acondicionamiento.
3.4. Nodo de Condición de Diseño de Omost
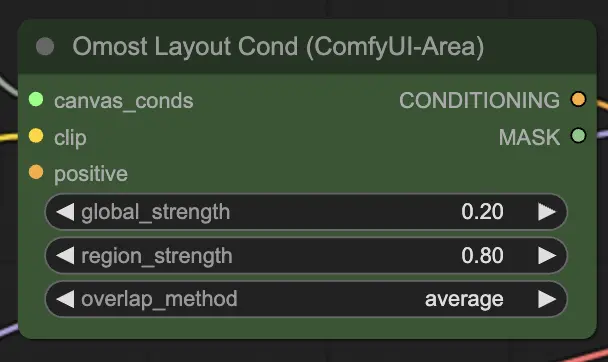
Parámetros de entrada del Nodo de Condición de Diseño de Omost
canvas_conds: Los parámetros de acondicionamiento del Canvas.clip: El modelo CLIP para la codificación de texto. Este modelo codifica las descripciones de texto en vectores que pueden ser utilizados por el generador de imágenes.global_strength: La fuerza del acondicionamiento global. Esto controla cuán fuertemente la descripción general afecta la imagen.region_strength: La fuerza del acondicionamiento regional. Esto controla cuán fuertemente las descripciones regionales específicas afectan sus respectivas áreas.overlap_method: El método para manejar áreas superpuestas (por ejemplo,overlay,average). Esto define cómo mezclar las regiones superpuestas en la imagen.positive(Opcional): Acondicionamiento positivo adicional. Esto puede incluir prompts o condiciones adicionales para mejorar aspectos específicos de la imagen.
Parámetros de salida del Nodo de Condición de Diseño de Omost
CONDITIONING: Los parámetros de acondicionamiento para la generación de imágenes. Estos parámetros guían el proceso de generación de la imagen, asegurando que el resultado coincida con la escena descrita.MASK: La máscara utilizada para el acondicionamiento. Esto ayuda en la depuración y en la aplicación de condiciones adicionales a regiones específicas.
3.5. Nodo de Carga de Acondicionamiento del Canvas de Omost
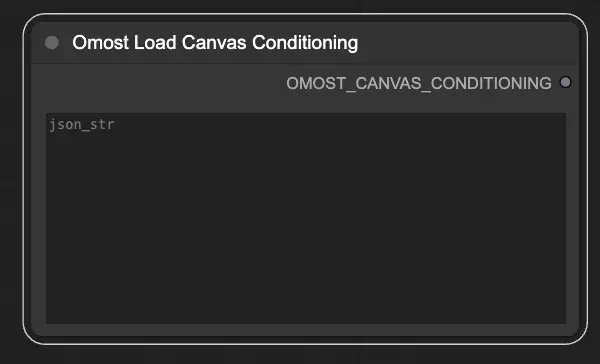
Parámetros de entrada del Nodo de Carga de Acondicionamiento del Canvas de Omost
json_str: La cadena JSON que representa los parámetros de acondicionamiento del Canvas. Esto permite cargar condiciones predefinidas desde un archivo JSON.
Parámetros de salida del Nodo de Carga de Acondicionamiento del Canvas de Omost
OMOST_CANVAS_CONDITIONING: Los parámetros de acondicionamiento del Canvas cargados. Estos parámetros inicializan el Canvas con condiciones específicas, listo para la generación de imágenes.


