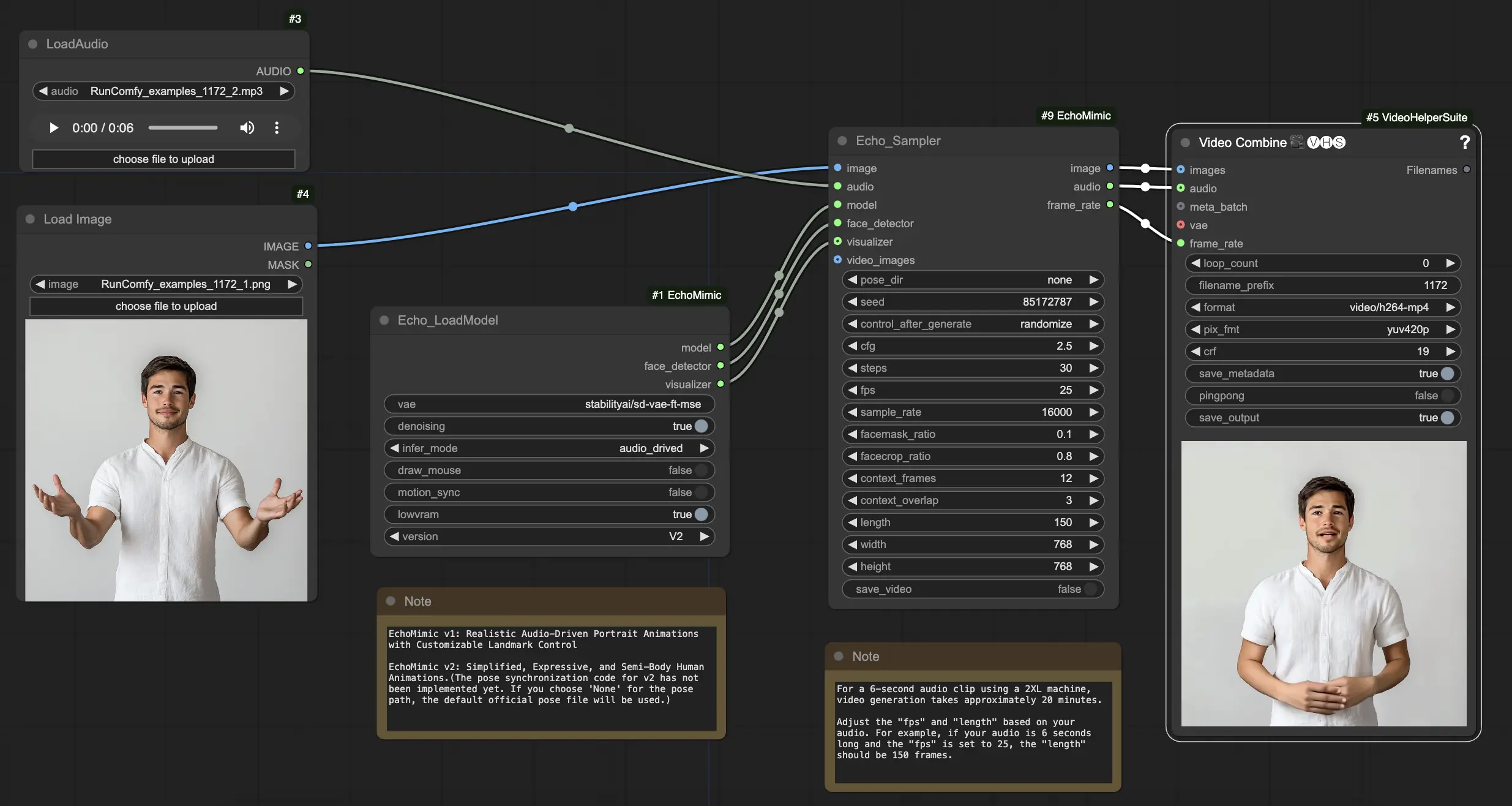
EchoMimic | Animaciones de Retratos Impulsadas por Audio
EchoMimic es una herramienta que te permite crear cabezas parlantes y gestos corporales realistas que se sincronizan perfectamente con el audio proporcionado. Al aprovechar técnicas avanzadas de IA, EchoMimic analiza la entrada de audio y genera expresiones faciales realistas, movimientos de labios y lenguaje corporal que coinciden perfectamente con las palabras y emociones habladas. Con EchoMimic, puedes dar vida a tus personajes y crear contenido animado que cautive a tu audiencia.ComfyUI EchoMimic Flujo de trabajo
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI EchoMimic Ejemplos
ComfyUI EchoMimic Descripción
EchoMimic es una herramienta para generar animaciones de retratos impulsadas por audio realistas. Utiliza técnicas de aprendizaje profundo para analizar el audio de entrada y generar expresiones faciales, movimientos de labios y gestos de cabeza correspondientes que coinciden estrechamente con el contenido emocional y fonético del discurso.
EchoMimic V2 fue desarrollado por un equipo de investigadores del Departamento de Tecnología Terminal en Alipay, Ant Group, que incluye a Rang Meng, Xingyu Zhang, Yuming Li y Chenguang Ma. Para información detallada, por favor visita /. El nodo ComfyUI_EchoMimic fue desarrollado por /. Todo el crédito va a su significativa contribución.
EchoMimic V1 y V2
- EchoMimic V1: Animaciones de Retratos Impulsadas por Audio Realistas con Control de Puntos de Referencia Personalizables
- EchoMimic V2: Animaciones Humanas Expresivas y Semi-Corporales Simplificadas
La principal diferencia es que EchoMimic V2 busca lograr una animación humana de medio cuerpo impresionante mientras simplifica las condiciones de control innecesarias en comparación con EchoMimic V1. EchoMimic V2 utiliza una novedosa estrategia de Armonización Dinámica Audio-Postura para mejorar las expresiones faciales y los gestos corporales.
Fortalezas y Debilidades de EchoMimic V2
Fortalezas:
- EchoMimic V2 genera animaciones de retratos altamente realistas y expresivas impulsadas por audio
- EchoMimic V2 extiende la animación al cuerpo superior, no solo a la región de la cabeza
- EchoMimic V2 reduce la complejidad de las condiciones mientras mantiene la calidad de la animación en comparación con EchoMimic V1
- EchoMimic V2 incorpora sin problemas datos de primer plano para mejorar las expresiones faciales
Debilidades:
- EchoMimic V2 requiere una fuente de audio coincidente con el retrato para obtener los mejores resultados
- EchoMimic V2 actualmente carece de código de sincronización de posturas, utilizando un archivo de postura predeterminado
- Generar animaciones de alta calidad más largas con EchoMimic V2 puede ser computacionalmente intensivo
- EchoMimic V2 funciona mejor en imágenes de retratos recortadas que en tomas de cuerpo completo
Cómo Usar el Flujo de Trabajo ComfyUI EchoMimic
En el nodo "Echo_LoadModel", tienes la opción de seleccionar entre EchoMimic v1 y EchoMimic v2:
- EchoMimic v1: Esta versión se centra en generar animaciones de retratos impulsadas por audio realistas con la capacidad de personalizar el control de puntos de referencia. Es adecuada para crear animaciones faciales realistas que coinciden estrechamente con el audio de entrada.
- EchoMimic v2: Esta versión busca simplificar el proceso de animación mientras ofrece animaciones humanas expresivas y semi-corporales. Extiende la animación más allá de la región facial para incluir movimientos del cuerpo superior. Sin embargo, ten en cuenta que la función de sincronización de posturas para v2 aún no está implementada en la versión actual del flujo de trabajo de ComfyUI. Si seleccionas 'None' para la ruta de la postura, se utilizará en su lugar el archivo de postura oficial predeterminado.
Aquí tienes una guía paso a paso sobre cómo usar el flujo de trabajo ComfyUI proporcionado:
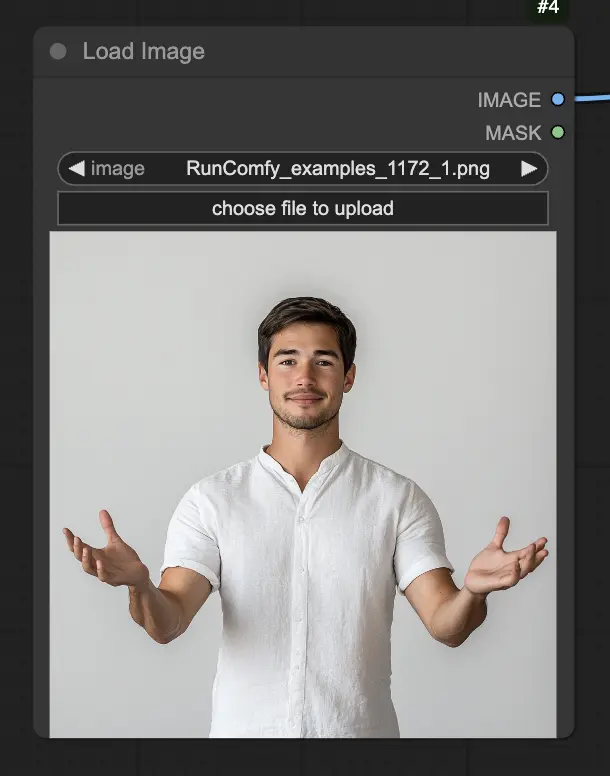
Paso 1. Carga tu imagen de retrato usando el nodo LoadImage. Esta debe ser una toma cercana de la cabeza y los hombros del sujeto.
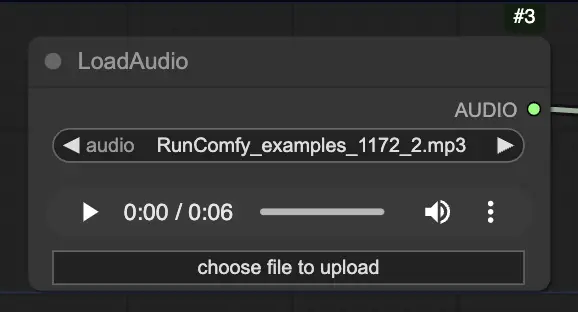
Paso 2. Carga tu archivo de audio usando el nodo LoadAudio. El discurso en el audio debe coincidir con la identidad del sujeto del retrato.
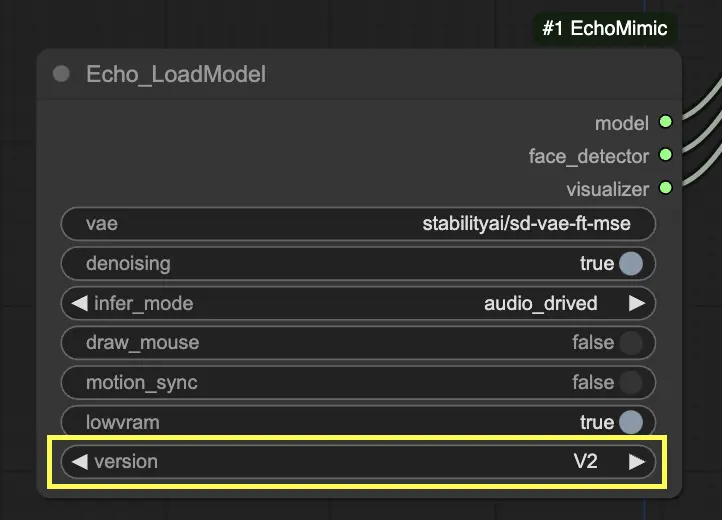
Paso 3. Usa el nodo Echo_LoadModel para cargar el modelo EchoMimic. Configuraciones clave:
- Elige la versión (V1 o V2).
- Selecciona el modo de inferencia, por ejemplo, modo impulsado por audio.
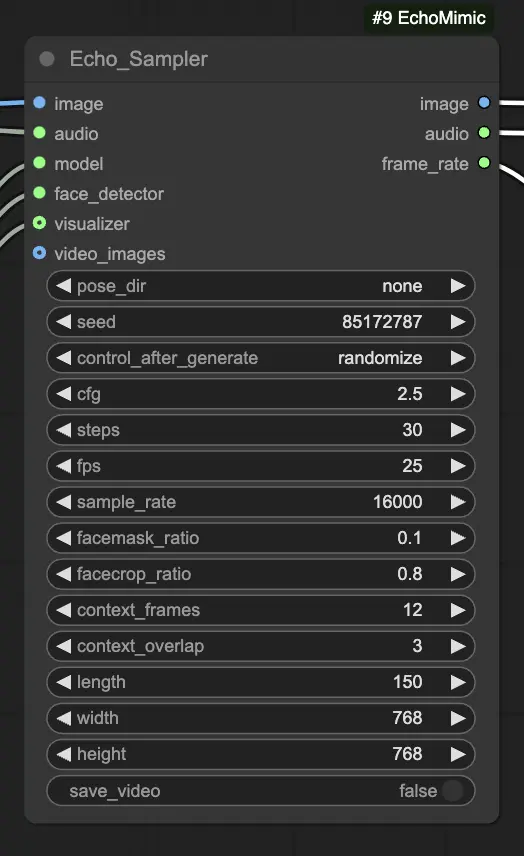
Paso 4. Conecta la imagen, el audio y el modelo cargado al nodo Echo_Sampler. Configuraciones clave:
- pose_dir: La ruta del directorio para los archivos de secuencia de postura utilizados en modos de animación impulsados por postura. Si se establece en "none", no se utilizará ninguna secuencia de postura.
- seed: La semilla aleatoria para generar resultados consistentes en ejecuciones. Debe ser un número entero entre 0 y MAX_SEED.
- cfg: La escala de guía libre de clasificador, controlando la fuerza del condicionamiento de audio. Valores más altos resultan en movimientos impulsados por audio más pronunciados. El valor predeterminado es 2.5, y puede variar de 0.0 a 10.0.
- steps: El número de pasos de difusión para generar cada cuadro. Valores más altos producen animaciones más suaves pero tardan más en generarse. El valor predeterminado es 30, y puede variar de 1 a 100.
- fps: La tasa de cuadros del video de salida en cuadros por segundo. El valor predeterminado es 25, y puede variar de 5 a 100.
- sample_rate: La tasa de muestreo del audio de entrada en Hz. El valor predeterminado es 16000, y puede variar de 8000 a 48000 en incrementos de 1000.
- facemask_ratio: La proporción del área de la máscara facial respecto al área completa de la imagen. Controla el tamaño de la región alrededor de la cara que se anima. El valor predeterminado es 0.1, y puede variar de 0.0 a 1.0.
- facecrop_ratio: La proporción del área de recorte facial respecto al área completa de la imagen. Determina cuánto de la imagen se dedica a la región facial. El valor predeterminado es 0.8, y puede variar de 0.0 a 1.0.
- context_frames: El número de cuadros pasados y futuros para usar como contexto para generar cada cuadro. El valor predeterminado es 12, y puede variar de 0 a 50.
- context_overlap: El número de cuadros superpuestos entre ventanas de contexto adyacentes. El valor predeterminado es 3, y puede variar de 0 a 10.
- length: La duración del video de salida en cuadros. Debe basarse en la duración de tu audio de entrada y la configuración de fps. Por ejemplo, si tu audio dura 6 segundos y fps está configurado en 25, la duración debe ser de 150 cuadros. La longitud puede variar de 50 a 5000 cuadros.
- width: El ancho de los cuadros del video de salida en píxeles. El valor predeterminado es 512, y puede variar de 128 a 1024 en incrementos de 64.
- height: La altura de los cuadros del video de salida en píxeles. El valor predeterminado es 512, y puede variar de 128 a 1024 en incrementos de 64.
Ten en cuenta que la generación de video puede llevar algún tiempo. Por ejemplo, crear un video a partir de un clip de audio de 6 segundos usando una máquina 2XL en RunComfy lleva aproximadamente 20 minutos.
