AnimateDiff + IPAdapter V1 | Da immagine a video
IPAdapter è una soluzione leggera che migliora i modelli pre-addestrati con funzionalità di prompt di immagini. Utilizzando AnimateDiff insieme a IPAdapter, puoi generare facilmente animazioni più controllabili a partire da immagini di riferimento.ComfyUI AnimateDiff IPAdapter Flusso di lavoro
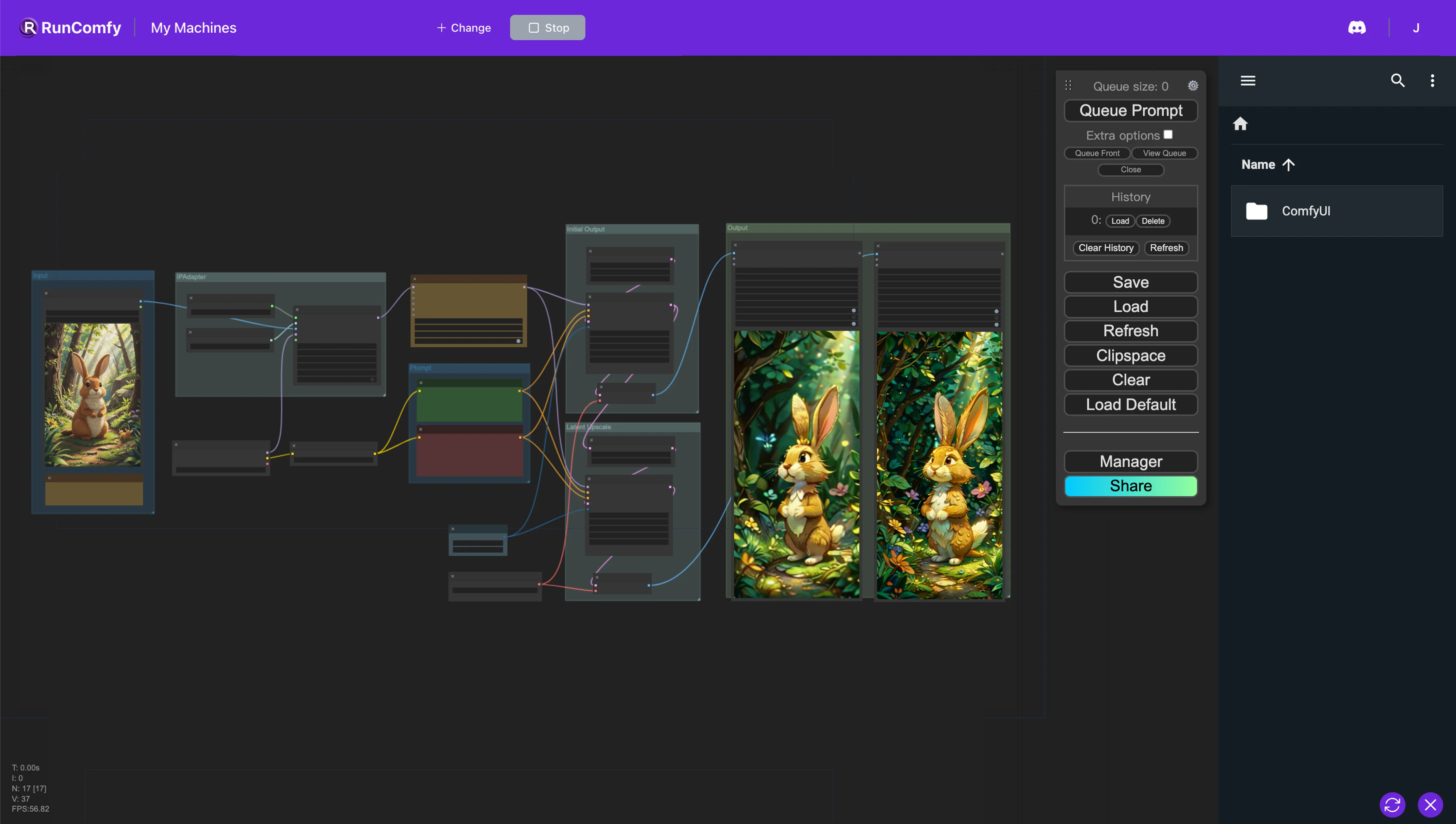
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI AnimateDiff IPAdapter Esempi
ComfyUI AnimateDiff IPAdapter Descrizione
1. Workflow ComfyUI: AnimateDiff + IPAdapter | Da immagine a video
Questo workflow ComfyUI è progettato per creare animazioni da immagini di riferimento utilizzando AnimateDiff e IP-Adapter. Il nodo AnimateDiff integra opzioni di modello e contesto per regolare la dinamica dell'animazione. Al contrario, il nodo IP-Adapter facilita l'uso di immagini come prompt in modi che possono imitare lo stile, la composizione o le caratteristiche facciali dell'immagine di riferimento, migliorando significativamente la personalizzazione e la qualità delle animazioni o immagini generate.
2. Panoramica di AnimateDiff
Per favore, consulta i dettagli su
3. Panoramica di IP-Adapter
3.1. Introduzione a IP-Adapter
IP-Adapter sta per "Image Prompt Adapter", un nuovo approccio per migliorare i modelli di diffusione da testo a immagine con la capacità di utilizzare prompt di immagini nelle attività di generazione di immagini. IP-Adapter mira a risolvere le carenze dei prompt di testo che spesso richiedono un complesso prompt engineering per generare le immagini desiderate. L'introduzione di prompt di immagini, insieme al testo, consente un modo più intuitivo ed efficace per guidare il processo di sintesi dell'immagine.
Diversi modelli di IP-Adapter
La suite IP-Adapter include una varietà di modelli, ognuno adattato per casi d'uso specifici e livelli di complessità di sintesi dell'immagine. Ecco una panoramica dei diversi modelli disponibili:
3.1.1. Modelli v1.5
ip-adapter_sd15: Il modello standard per la versione 1.5, che utilizza la potenza di IP-Adapter per il condizionamento da immagine a immagine e l'aumento del prompt di testo.ip-adapter_sd15_light: Una versione più leggera del modello standard, ottimizzata per applicazioni meno intensive in termini di risorse, pur sfruttando la tecnologia IP-Adapter.ip-adapter-plus_sd15: Un modello avanzato che produce immagini più allineate con il riferimento originale, migliorando i dettagli più fini.ip-adapter-plus-face_sd15: Simile a IP-Adapter Plus, con un focus sulla replica più accurata delle caratteristiche facciali nelle immagini generate.ip-adapter-full-face_sd15: Un modello che enfatizza i dettagli del viso completo, probabilmente offrendo un effetto di "scambio di volti" ad alta fedeltà.ip-adapter_sd15_vit-G: Una variante del modello standard che utilizza il Vision Transformer (ViT) BigG image encoder per un'estrazione più dettagliata delle caratteristiche dell'immagine.
3.1.2. Modelli SDXL
ip-adapter_sdxl: Il modello base per SDXL, progettato per gestire prompt di immagini più grandi e complessi.ip-adapter_sdxl_vit-h: Il modello SDXL accoppiato con il ViT H image encoder, bilanciando le prestazioni con l'efficienza computazionale.ip-adapter-plus_sdxl_vit-h: Una versione avanzata del modello SDXL con dettagli e qualità del prompt di immagine migliorati.ip-adapter-plus-face_sdxl_vit-h: Una variante SDXL focalizzata sui dettagli del viso, ideale per progetti in cui la precisione facciale è fondamentale.
3.1.3. Modelli FaceID
FaceID: Un modello che utilizza InsightFace per estrarre gli embedding di Face ID, offrendo un approccio unico alla generazione di immagini correlate al viso.FaceID Plus: Una versione migliorata del modello FaceID, che combina InsightFace per le caratteristiche facciali e la codifica delle immagini CLIP per le caratteristiche facciali globali.FaceID Plus v2: Un'iterazione di FaceID Plus con un checkpoint del modello migliorato e la capacità di impostare un peso sull'embedding dell'immagine CLIP.FaceID Portrait: Un modello simile a FaceID ma progettato per accettare più immagini di volti ritagliati per un condizionamento facciale più diversificato.
3.1.4. Modelli FaceID SDXL
FaceID SDXL: La versione SDXL di FaceID, che mantiene lo stesso modello InsightFace di v1.5 ma scalato per le applicazioni SDXL.FaceID Plus v2 SDXL: Un adattamento SDXL di FaceID Plus v2 per la generazione di immagini ad alta definizione con una fedeltà migliorata.
3.2. Caratteristiche principali di IP-Adapter
3.2.1. Integrazione di prompt di testo e immagini: La capacità unica di IP-Adapter di utilizzare sia prompt di testo che di immagini consente la generazione di immagini multimodali, fornendo uno strumento versatile e potente per controllare gli output del modello di diffusione.
3.2.2. Meccanismo di cross-attention disaccoppiato: IP-Adapter utilizza una strategia di cross-attention disaccoppiata che migliora l'efficienza del modello nell'elaborazione di diverse modalità separando le caratteristiche di testo e immagini.
3.2.3. Modello leggero: Nonostante la sua funzionalità completa, IP-Adapter mantiene un numero di parametri relativamente basso (22M), offrendo prestazioni che rivaleggia o supera quella dei modelli di prompt di immagini sottoposti a fine-tuning.
3.2.4. Compatibilità e generalizzazione: IP-Adapter è progettato per una vasta compatibilità con strumenti controllabili esistenti e può essere applicato a modelli personalizzati derivati dallo stesso modello di base per una maggiore generalizzazione.
3.2.5. Controllo della struttura: IP-Adapter supporta un controllo dettagliato della struttura, consentendo ai creatori di guidare il processo di generazione delle immagini con maggiore precisione.
3.2.6. Funzionalità da immagine a immagine e di inpainting: Con il supporto per la traduzione guidata da immagine a immagine e l'inpainting, IP-Adapter amplia l'ambito delle possibili applicazioni, consentendo usi creativi e pratici in una varietà di attività di sintesi delle immagini.
3.2.7. Personalizzazione con diversi encoder: IP-Adapter consente l'uso di vari encoder, come OpenClip ViT H 14 e ViT BigG 14, per elaborare le immagini di riferimento. Questa flessibilità facilita la gestione di diverse risoluzioni e complessità delle immagini, rendendolo uno strumento versatile per i creatori che cercano di adattare il processo di generazione delle immagini a esigenze specifiche o a risultati desiderati.
L'incorporazione della tecnologia IP-Adapter nei progetti di generazione di immagini non solo semplifica la creazione di immagini complesse e dettagliate, ma migliora anche significativamente la qualità e la fedeltà delle immagini generate ai prompt originali. Colmando il divario tra i prompt di testo e di immagini, IP-Adapter fornisce un approccio potente, intuitivo ed efficiente per controllare le sfumature della sintesi delle immagini, rendendolo uno strumento indispensabile nell'arsenale degli artisti digitali, designer e creatori che lavorano all'interno del flusso di lavoro ComfyUI o in qualsiasi altro contesto che richieda una generazione di immagini di alta qualità e personalizzata.