SVD (Stable Video Diffusion) + SD | テキストからビデオへ
このComfyUIワークフローでは、Stable Diffusionのテキスト画像変換とStable Video Diffusionの画像動画変換のプロセスを統合しています。これにより、テキストを入力して画像を生成し、その画像をシームレスにビデオに変換することができます。ComfyUI SVD ワークフロー
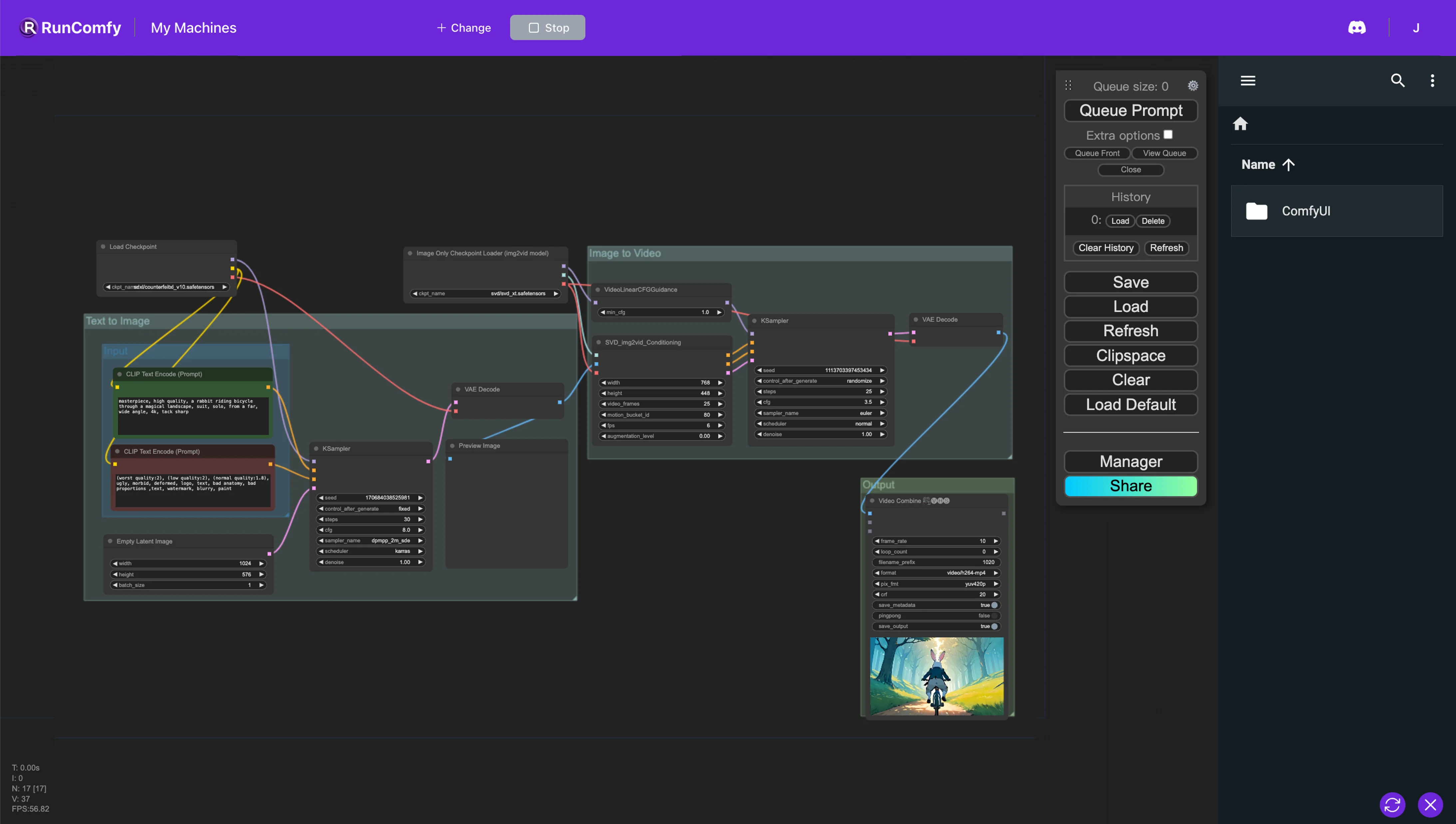
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI SVD 例
ComfyUI SVD 説明
1. ComfyUI Stable Video Diffusion (SVD) ワークフロー
ComfyUIワークフローは、テキスト画像変換(Stable Diffusion)と画像動画変換(Stable Video Diffusion)のテクノロジーをシームレスに統合し、効率的なテキスト動画変換を実現します。このワークフローでは、テキストの説明から直接ビデオを生成することができ、ベース画像から始まり、ダイナミックなビデオシーケンスへと進化します。このワークフローは、テキスト動画アニメーションやビデオの実現を促進します。
2. Stable Video Diffusion (SVD) の概要
2.1. Stable Video Diffusion (SVD) の紹介
Stable Video Diffusion (SVD) は、静止画を動的なビデオコンテンツに変換するために開発された最先端のテクノロジーです。SVDは、Stable Diffusionの画像モデルを基盤として、静止画にモーションを導入し、短いビデオクリップの作成を可能にします。当初は画像合成用に考案されたlatent diffusionモデルの進化により、静止画にテンポラルな次元を組み込むことで、通常は2〜5秒程度のビデオを生成できるようになりました。
Stable Video Diffusionには2つのバリエーションがあります。標準のSVDは、14フレームで576×1024ピクセルのビデオを生成でき、拡張版のSVD-XTは最大25フレームまで生成できます。どちらのバリエーションも、3〜30フレーム/秒の調整可能なフレームレートをサポートしており、多様なデジタルコンテンツ制作のニーズに対応しています。
SVDモデルのトレーニングは、3段階のプロセスを経ています。画像モデルから始まり、大規模なビデオデータセットで事前学習したビデオモデルへと移行し、高品質のビデオクリップを選択して微調整します。このプロセスは、モデルのビデオ制作能力を最適化するためのデータセット品質の重要性を示しています。
Stable Video Diffusionモデルの中核となるのは、Stable Diffusion 2.1の画像モデルであり、基礎となる画像のバックボーンとして機能します。時間的な畳み込みとアテンション層をU-Netノイズ推定器に統合することで、これを強力なビデオモデルに進化させ、潜在テンソルをビデオシーケンスとして解釈します。このモデルは、VideoLDMモデルと同様に、すべてのフレームを同時にデノイズするためにリバースディフュージョンを採用しています。
15億のパラメータを備え、膨大なビデオデータセットで学習したこのモデルは、最高のパフォーマンスを発揮するために、高品質のビデオデータセットでさらに微調整されます。SVDモデルの重みは2セット公開されており、それぞれ14フレームと25フレームの576×1024解像度のビデオを生成するように設計されています。
2.2. Stable Video Diffusion (SVD) の主な特徴
ComfyUIワークフローでStable Video Diffusionを使用する際、ビデオ出力をカスタマイズするための主要なパラメータには、ビデオのモーション強度を制御するモーションバケットID、フレームレートを決定するフレーム/秒(fps)、初期画像のノイズレベルを調整して様々な変換の度合いを得るオーギュメンテーションレベルなどがあります。
2.2.1. モーションバケットID: この機能により、ユーザーはビデオのモーション強度を制御できます。このパラメータを調整することで、目的の視覚効果に応じて、微妙なジェスチャーからより顕著なアクションまで、ビデオ内の動きの量を指定できます。
2.2.2. フレーム/秒(fps): このパラメータは、ビデオの再生速度を決定するために重要です。フレーム/秒を調整することで、シーンの素早いダイナミクスを捉えたり、スローモーション効果を表現したりできるビデオを制作できます。これにより、ビデオコンテンツのストーリーテリング面が強化されます。この柔軟性は、高速なペースの広告から、よりゆっくりとした物語性のあるピースまで、幅広いタイプのビデオを作成するのに特に有益です。
2.2.3.オーギュメンテーションレベルパラメータ: これは、初期画像のノイズレベルを調整し、様々な変換の度合いを可能にします。このパラメータを操作することで、ビデオ作成プロセス中に元の画像がどの程度変化するかを制御できます。オーギュメンテーションレベルを調整することで、元の画像により忠実に近づけたり、より抽象的でアーティスティックな解釈に踏み込んだりできるため、創造的な可能性が広がります。

