EchoMimic | 오디오 기반 초상화 애니메이션
EchoMimic은 제공된 오디오와 완벽하게 동기화되는 현실적인 말하는 머리와 신체 제스처를 만들 수 있게 해주는 도구입니다. 고급 AI 기술을 활용하여 EchoMimic은 오디오 입력을 분석하고 말하는 단어와 감정에 완벽히 맞는 실제와 같은 얼굴 표정, 입술 움직임, 신체 언어를 생성합니다. EchoMimic을 통해 캐릭터에 생명을 불어넣고 청중을 매료시키는 애니메이션 콘텐츠를 만들 수 있습니다.ComfyUI EchoMimic 워크플로우
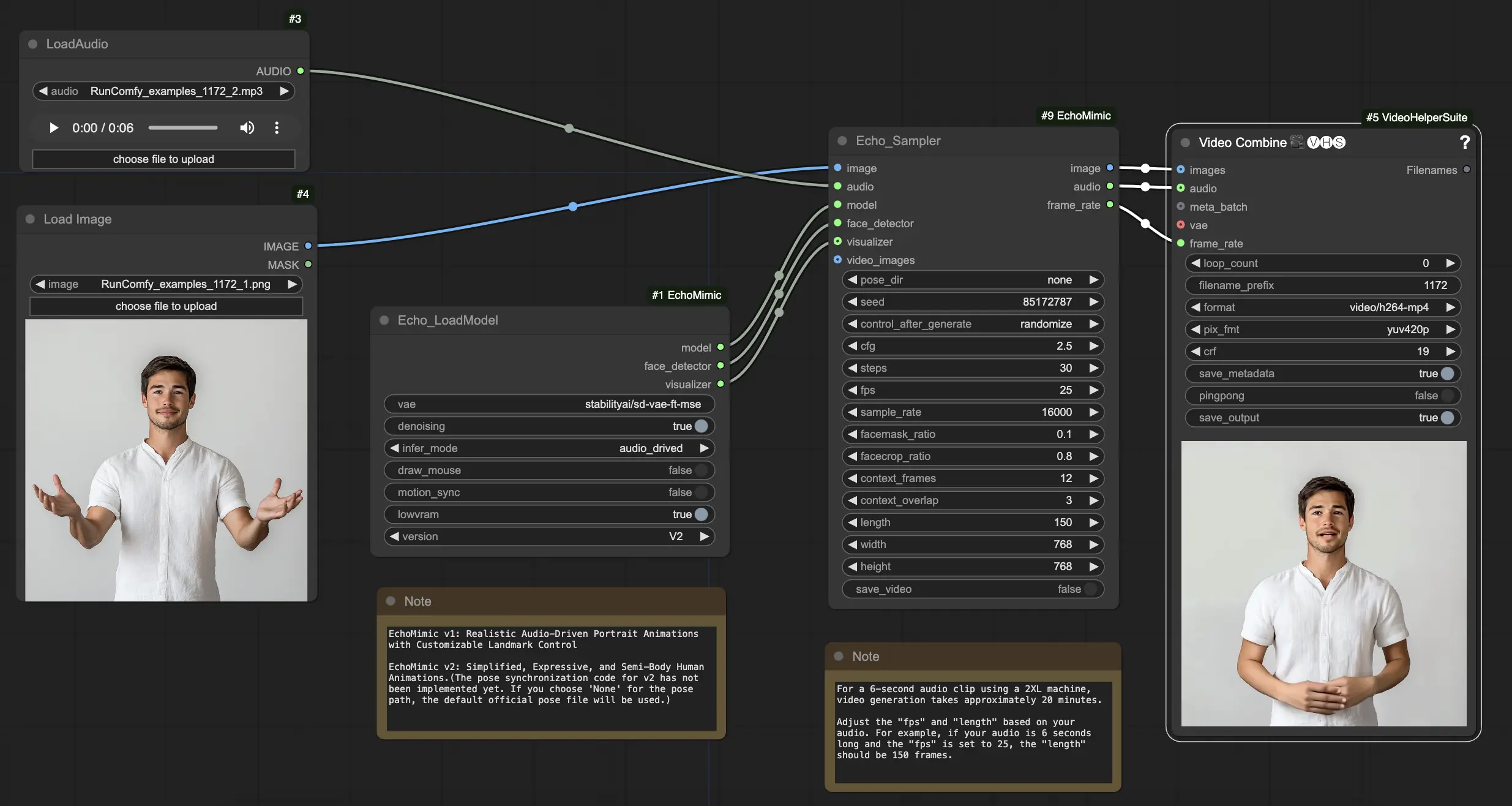
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI EchoMimic 예제
ComfyUI EchoMimic 설명
EchoMimic은 실제와 같은 오디오 기반 초상화 애니메이션을 생성하는 도구입니다. 이는 딥러닝 기술을 활용하여 입력된 오디오를 분석하고, 음성의 감정적 및 음운적 내용을 밀접하게 일치시키는 얼굴 표정, 입술 움직임, 머리 제스처를 생성합니다.
EchoMimic V2는 알리페이, Ant Group의 터미널 기술 부서 연구팀인 Rang Meng, Xingyu Zhang, Yuming Li, Chenguang Ma에 의해 개발되었습니다. 자세한 정보는 /를 방문하십시오. ComfyUI_EchoMimic 노드는 /에 의해 개발되었습니다. 모든 공로는 그들의 중요한 기여에 있습니다.
EchoMimic V1 및 V2
- EchoMimic V1: 사용자 정의 랜드마크 제어가 가능한 현실적인 오디오 기반 초상화 애니메이션
- EchoMimic V2: 간소화되고 표현력이 뛰어난 반신 인간 애니메이션
주요 차이점은 EchoMimic V2가 EchoMimic V1에 비해 불필요한 제어 조건을 단순화하면서도 인상적인 반신 인간 애니메이션을 목표로 한다는 것입니다. EchoMimic V2는 얼굴 표정과 신체 제스처를 향상시키기 위해 새로운 Audio-Pose Dynamic Harmonization 전략을 사용합니다.
EchoMimic V2의 장점과 단점
장점:
- EchoMimic V2는 오디오에 의해 구동되는 매우 현실적이고 표현력 있는 초상화 애니메이션을 생성합니다
- EchoMimic V2는 애니메이션을 머리 부분뿐만 아니라 상체까지 확장합니다
- EchoMimic V2는 EchoMimic V1에 비해 조건 복잡성을 줄이면서도 애니메이션 품질을 유지합니다
- EchoMimic V2는 얼굴 표정을 향상시키기 위해 헤드샷 데이터를 매끄럽게 통합합니다
단점:
- EchoMimic V2는 최고의 결과를 위해 초상화에 맞춘 오디오 소스를 필요로 합니다
- EchoMimic V2는 현재 포즈 동기화 코드를 제공하지 않으며, 기본 포즈 파일을 사용합니다
- EchoMimic V2로 긴 고품질 애니메이션을 생성하는 것은 계산적으로 집약적일 수 있습니다
- EchoMimic V2는 전체 신체 사진보다는 잘린 초상화 이미지에서 가장 잘 작동합니다
ComfyUI EchoMimic 워크플로우 사용 방법
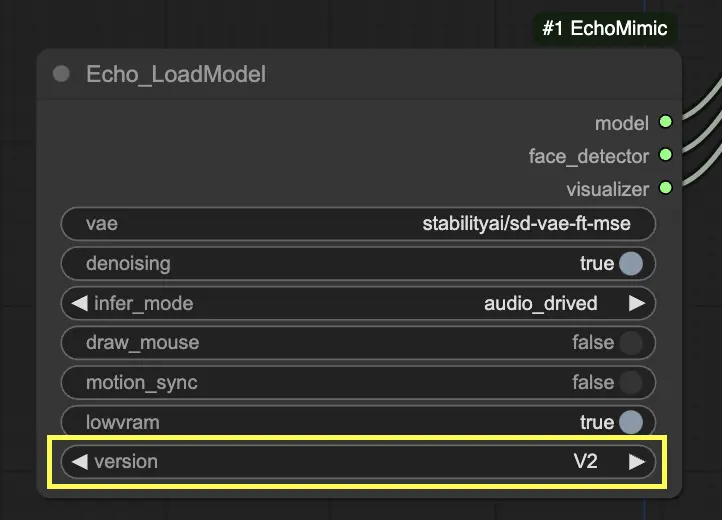
"Echo_LoadModel" 노드에서 EchoMimic v1과 EchoMimic v2 중 선택할 수 있습니다:
- EchoMimic v1: 이 버전은 랜드마크 제어를 사용자 정의할 수 있는 현실적인 오디오 기반 초상화 애니메이션 생성에 중점을 둡니다. 입력 오디오와 밀접하게 일치하는 실제 얼굴 애니메이션을 생성하는 데 적합합니다.
- EchoMimic v2: 이 버전은 애니메이션 프로세스를 간소화하면서도 표현력 있는 반신 인간 애니메이션을 제공합니다. 얼굴 영역뿐만 아니라 상체 움직임을 포함하는 애니메이션을 확장합니다. 그러나 v2의 포즈 동기화 기능은 현재 ComfyUI 워크플로우의 버전에는 구현되지 않았습니다. 'None'을 포즈 경로로 선택하면 기본 공식 포즈 파일이 대신 사용됩니다.
제공된 ComfyUI 워크플로우를 사용하는 단계별 가이드:
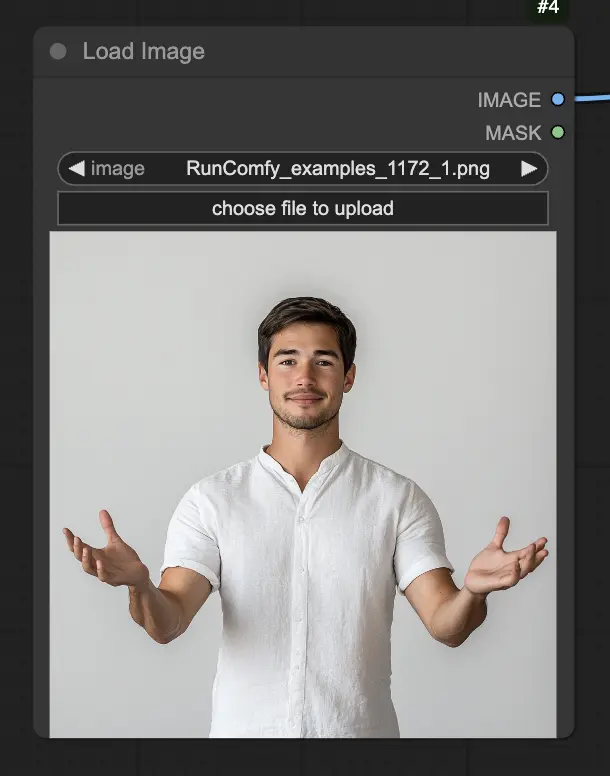
Step 1. LoadImage 노드를 사용하여 초상화 이미지를 로드합니다. 이는 주제의 머리와 어깨를 가까이 찍은 사진이어야 합니다.
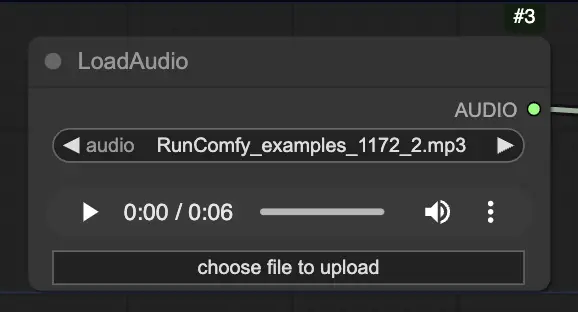
Step 2. LoadAudio 노드를 사용하여 오디오 파일을 로드합니다. 오디오의 음성은 초상화 주제의 정체성과 일치해야 합니다.
Step 3. Echo_LoadModel 노드를 사용하여 EchoMimic 모델을 로드합니다. 주요 설정:
- 버전 선택 (V1 또는 V2).
- 추론 모드 선택, 예: 오디오 기반 모드.
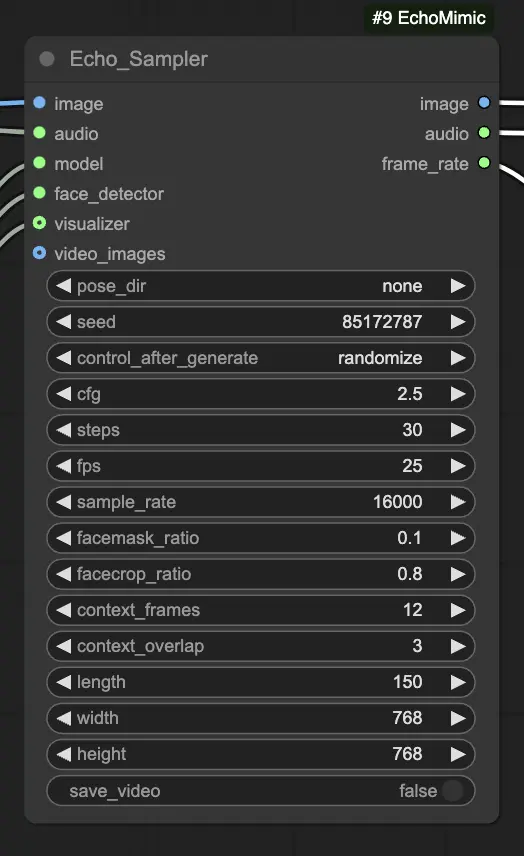
Step 4. 이미지, 오디오, 로드된 모델을 Echo_Sampler 노드에 연결합니다. 주요 설정:
- pose_dir: 포즈 기반 애니메이션 모드에서 사용되는 포즈 시퀀스 파일의 디렉토리 경로. "none"으로 설정하면 포즈 시퀀스가 사용되지 않습니다.
- seed: 실행 간 일관된 결과를 생성하기 위한 랜덤 시드입니다. 0과 MAX_SEED 사이의 정수여야 합니다.
- cfg: 오디오 조건화 강도를 제어하는 분류자 없는 가이드 스케일입니다. 더 높은 값은 더 두드러진 오디오 기반 움직임을 생성합니다. 기본 값은 2.5이며, 0.0에서 10.0까지 범위입니다.
- steps: 각 프레임을 생성하기 위한 확산 단계 수입니다. 더 높은 값은 더 부드러운 애니메이션을 생성하지만 생성 시간이 더 길어집니다. 기본값은 30이며, 1에서 100까지 범위입니다.
- fps: 초당 프레임으로 출력 비디오의 프레임 레이트입니다. 기본값은 25이며, 5에서 100까지 범위입니다.
- sample_rate: Hz로 입력 오디오의 샘플 레이트입니다. 기본값은 16000이며, 1000 단위로 8000에서 48000까지 범위입니다.
- facemask_ratio: 얼굴 마스크 영역의 비율을 전체 이미지 영역에 대한 비율로, 애니메이션 되는 얼굴 주변 영역의 크기를 제어합니다. 기본값은 0.1이며, 0.0에서 1.0까지 범위입니다.
- facecrop_ratio: 얼굴 자르기 영역의 비율을 전체 이미지 영역에 대한 비율로, 얼굴 영역에 할당되는 이미지의 양을 결정합니다. 기본값은 0.8이며, 0.0에서 1.0까지 범위입니다.
- context_frames: 각 프레임을 생성하기 위한 과거 및 미래 프레임의 수입니다. 기본값은 12이며, 0에서 50까지 범위입니다.
- context_overlap: 인접한 컨텍스트 창 사이의 겹치는 프레임 수입니다. 기본값은 3이며, 0에서 10까지 범위입니다.
- length: 출력 비디오의 길이(프레임 수)입니다. 입력 오디오의 길이와 fps 설정에 따라야 합니다. 예를 들어, 오디오가 6초 길이이고 fps가 25로 설정된 경우, 길이는 150 프레임이어야 합니다. 길이는 50에서 5000 프레임까지 범위입니다.
- width: 출력 비디오 프레임의 너비(픽셀)입니다. 기본값은 512이며, 64 단위로 128에서 1024까지 범위입니다.
- height: 출력 비디오 프레임의 높이(픽셀)입니다. 기본값은 512이며, 64 단위로 128에서 1024까지 범위입니다.
비디오 생성에는 시간이 걸릴 수 있음을 유의하십시오. 예를 들어, RunComfy에서 2XL 기계를 사용하여 6초 길이의 오디오 클립으로 비디오를 생성하는 데 약 20분이 소요됩니다.

