Hunyuan Video | 텍스트에서 비디오로
Hunyuan Video는 Tencent가 개발한 오픈 소스 비디오 기반 모델입니다. 이 모델은 비디오 생성 성능이 선도적인 클로즈드 소스 모델과 동등하거나 더 우수합니다. 데이터 큐레이션, 이미지-비디오 공동 훈련, 최적화된 인프라와 같은 고급 기술을 활용하여 Hunyuan Video는 고품질, 대규모 비디오 생성을 가능하게 합니다.ComfyUI Hunyuan Video 워크플로우
이 워크플로우를 실행하고 싶으신가요?
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Hunyuan Video 예제
ComfyUI Hunyuan Video 설명
는 성능 면에서 상위 클로즈드 소스 모델에 견줄 수 있는 혁신적인 오픈 소스 비디오 기반 모델로, Tencent라는 선도적인 기술 회사에서 개발되었습니다. Hunyuan Video는 데이터 큐레이션, 이미지-비디오 공동 모델 훈련, 대규모 모델 훈련 및 추론을 위한 효율적인 인프라와 같은 첨단 기술을 사용하여 모델 학습을 수행합니다. Hunyuan Video는 130억 개 이상의 매개변수를 가진 가장 큰 오픈 소스 비디오 생성 모델을 자랑합니다.
Hunyuan Video의 주요 기능
- Hunyuan Video는 이미지와 비디오를 모두 생성할 수 있는 통합 아키텍처를 제공합니다. "Dual-stream to Single-stream"이라는 특별한 Transformer 모델 설계를 사용합니다. 이는 모델이 비디오와 텍스트 정보를 먼저 개별적으로 처리한 후, 최종 결과물을 생성하기 위해 이를 결합한다는 것을 의미합니다. 이를 통해 모델은 시각적 요소와 텍스트 설명 간의 관계를 더 잘 이해할 수 있습니다.
- Hunyuan Video의 텍스트 인코더는 다중 모달 대형 언어 모델(MLLM)을 기반으로 합니다. CLIP 및 T5-XXL과 같은 다른 인기 있는 텍스트 인코더와 비교하여, MLLM은 텍스트와 이미지를 더 잘 정렬할 수 있습니다. 또한 콘텐츠에 대한 보다 세부적인 설명과 추론을 제공할 수 있습니다. 이를 통해 Hunyuan Video는 입력 텍스트와 더 정확하게 일치하는 비디오를 생성할 수 있습니다.
- 고해상도 및 높은 프레임 속도의 비디오를 효율적으로 처리하기 위해, Hunyuan Video는 CausalConv3D를 사용하는 3D 변동 오토인코더(VAE)를 사용합니다. 이 구성 요소는 비디오와 이미지를 잠재 공간이라고 불리는 더 작은 표현으로 압축합니다. 이 압축된 공간에서 작업함으로써, Hunyuan Video는 과도한 계산 자원을 사용하지 않고 원래의 해상도와 프레임 속도로 비디오를 훈련하고 생성할 수 있습니다.
- Hunyuan Video에는 사용자의 입력 텍스트를 모델의 선호에 맞게 자동으로 조정할 수 있는 프롬프트 리라이트 모델이 포함되어 있습니다. Normal과 Master 두 가지 모드를 사용할 수 있습니다. Normal 모드는 사용자의 지시 사항에 대한 모델의 이해도를 향상시키는 데 중점을 두며, Master 모드는 더 높은 시각적 품질의 비디오를 만드는 데 중점을 둡니다. 그러나 Master 모드는 때때로 비디오의 시각적 품질을 향상시키기 위해 텍스트의 특정 세부 사항을 간과할 수 있습니다.
ComfyUI에서 Hunyuan Video 사용하기
이 노드와 관련 워크플로는 Kijai에 의해 개발되었습니다. 우리는 이 혁신적인 작업에 대해 Kijai에게 모든 공로를 돌립니다. RunComfy 플랫폼에서 우리는 단순히 그의 기여를 커뮤니티에 소개하고 있습니다.
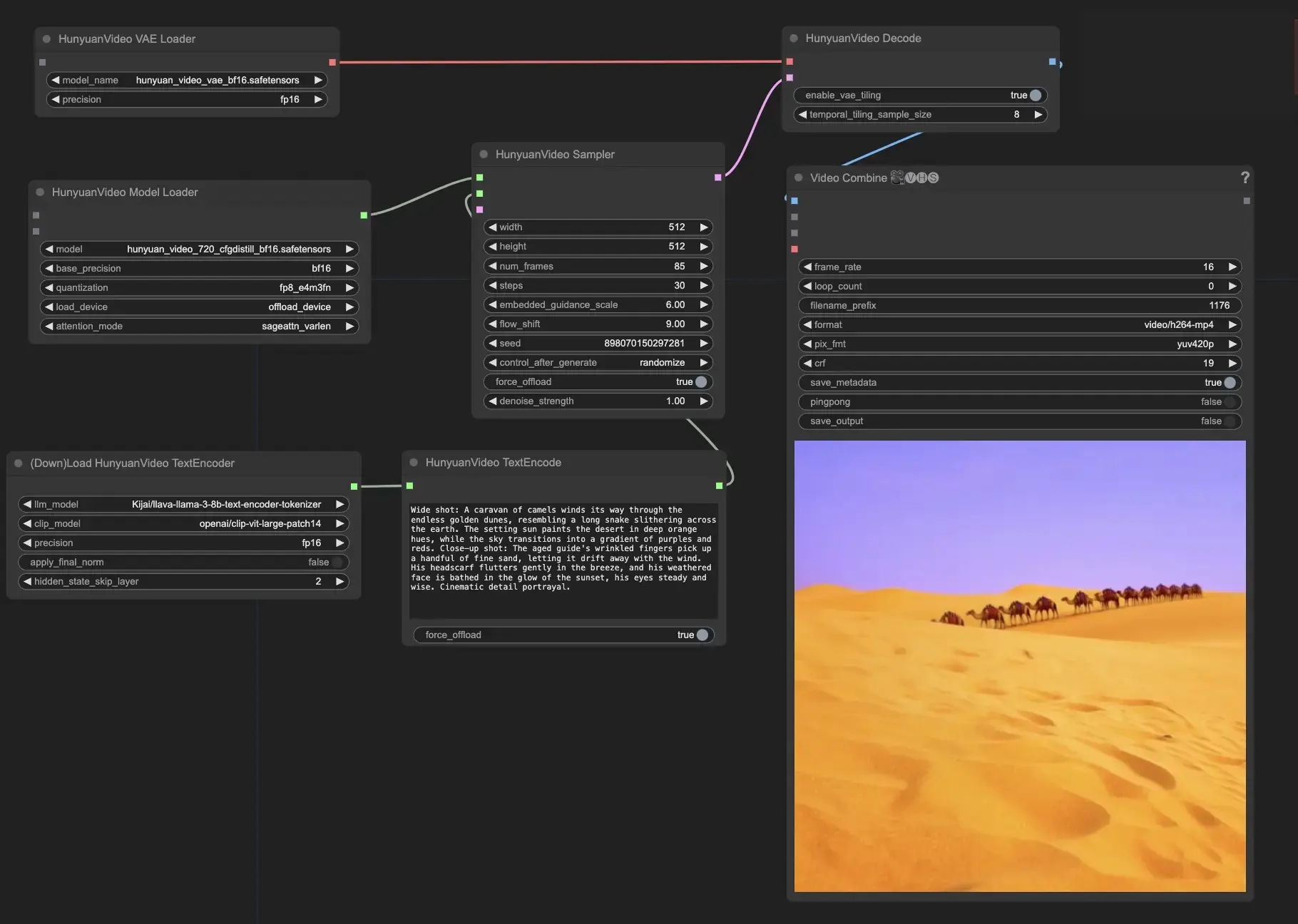
- 텍스트 프롬프트 제공: HunyuanVideoTextEncode 노드에서 "prompt" 필드에 원하는 텍스트 프롬프트를 입력합니다. 에서 참고할 수 있는 프롬프트 예제를 확인하세요.
- HunyuanVideoSampler 노드에서 출력 비디오 설정 구성:
- 원하는 해상도로 "width"와 "height"를 설정합니다
- 원하는 비디오 길이를 프레임 단위로 "num_frames"에 설정합니다
- "steps"는 디노이징/샘플링 스텝 수를 제어합니다 (기본값: 30)
- "embedded_guidance_scale"은 프롬프트 가이드의 강도를 결정합니다 (기본값: 6.0)
- "flow_shift"는 비디오 길이에 영향을 미치며 (값이 클수록 비디오가 짧아짐, 기본값: 9.0)
