CogVideoX-5B | Продвинутая Модель Текст-Видео
CogVideoX-5B, разработанная Zhipu AI, является передовой моделью текст-видео, которая генерирует высококачественные видео из текстовых подсказок. Используя 3D Causal VAE и архитектуру Expert Transformer, эта модель обеспечивает временно согласованные и плавные видеопоследовательности, что делает её идеальной для сложных движений и детализированной семантической генерации.ComfyUI CogVideoX-5B Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI CogVideoX-5B Примеры
ComfyUI CogVideoX-5B Описание
1. О CogVideoX-5B
CogVideoX-5B — это передовая модель диффузии текст-видео, разработанная Zhipu AI в Университете Цинхуа. В рамках серии CogVideoX, эта модель создаёт видео непосредственно из текстовых подсказок, используя передовые методы ИИ, такие как 3D Вариационный Автокодировщик (VAE) и Expert Transformer. CogVideoX-5B генерирует высококачественные, временно согласованные результаты, которые захватывают сложные движения и детализированную семантику.
С CogVideoX-5B вы достигаете исключительной ясности и плавности. Модель обеспечивает бесшовный поток, захватывая сложные детали и динамические элементы с исключительной точностью. Использование CogVideoX-5B снижает несоответствия и артефакты, приводя к полированному и увлекательному представлению. Высококачественные выходы CogVideoX-5B способствуют созданию богато детализированных и согласованных сцен из текстовых подсказок, что делает её незаменимым инструментом для высочайшего качества и визуального воздействия.
2. Техника CogVideoX-5B
2.1 3D Causal Вариационный Автокодировщик (VAE) CogVideoX-5B
3D Causal VAE является ключевым компонентом CogVideoX-5B, обеспечивающим эффективную генерацию видео за счёт сжатия видеоданных как по пространственным, так и по временным осям. В отличие от традиционных моделей, использующих 2D VAE для обработки каждого кадра по отдельности — часто приводя к мерцанию между кадрами — CogVideoX-5B использует 3D свёртки для захвата как пространственной, так и временной информации одновременно. Этот подход обеспечивает плавные и согласованные переходы между кадрами.
Архитектура 3D Causal VAE включает в себя кодировщик, декодировщик и регуляризатор латентного пространства. Кодировщик сжимает видеоданные в латентное представление, которое затем используется декодировщиком для реконструкции видео. Регуляризатор Кульбака-Лейблера (KL) ограничивает латентное пространство, обеспечивая, чтобы закодированное видео оставалось в пределах Гауссовского распределения. Это помогает поддерживать высокое качество видео при реконструкции.
Ключевые особенности 3D Causal VAE
- Пространственное и временное сжатие: VAE сжимает видеоданные в 4 раза по временной оси и в 8x8 раз по пространственным осям, достигая общего коэффициента сжатия 4x8x8. Это снижает вычислительные затраты, позволяя модели обрабатывать более длинные видео с меньшими ресурсами.
- Причинная свёртка: Чтобы сохранить порядок кадров в видео, модель использует временно причинные свёртки. Это гарантирует, что будущие кадры не влияют на предсказание текущих или прошлых кадров, сохраняя целостность последовательности при генерации.
- Контекстный параллелизм: Чтобы справиться с высокой вычислительной нагрузкой при обработке длинных видео, модель использует контекстный параллелизм по временной оси, распределяя рабочую нагрузку между несколькими устройствами. Это оптимизирует процесс обучения и снижает использование памяти.
2.2 Архитектура Expert Transformer CogVideoX-5B
Архитектура Expert Transformer CogVideoX-5B разработана для эффективной обработки сложного взаимодействия между текстовыми и видеоданными. Она использует адаптивную технику LayerNorm для обработки различных пространств признаков текста и видео.
Ключевые особенности Expert Transformer
- Патчирование: После кодирования видеоданных 3D Causal VAE, они разделяются на меньшие патчи по пространственным осям. Этот процесс, называемый патчированием, преобразует видео в последовательность меньших сегментов, что облегчает обработку трансформером и выравнивание с соответствующими текстовыми данными.
- 3D Роторное Позиционное Кодирование (RoPE): Для захвата пространственных и временных отношений в видео, CogVideoX-5B расширяет традиционное 2D RoPE до 3D. Эта техника кодирования применяет позиционное кодирование к x, y и t осям видео, помогая трансформеру эффективно моделировать длинные видеопоследовательности и поддерживать согласованность между кадрами.
- Экспертная Адаптивная LayerNorm (AdaLN): Трансформер использует экспертную адаптивную LayerNorm для обработки текстовых и видеовых кодировок по отдельности. Это позволяет модели выравнивать различные пространства признаков текста и видео, обеспечивая плавное слияние этих двух модальностей.
2.3 Прогрессивные техники обучения CogVideoX-5B
CogVideoX-5B использует несколько прогрессивных техник обучения для улучшения своей производительности и стабильности при генерации видео.
Ключевые стратегии прогрессивного обучения
- Обучение на видео разной длительности: Модель обучается на видео разной длительности в пределах одного батча. Эта техника улучшает способность модели к обобщению, позволяя ей генерировать видео разной длительности при сохранении стабильного качества.
- Прогрессивное обучение разрешению: Модель сначала обучается на видео с низким разрешением, а затем постепенно дорабатывается на видео с высоким разрешением. Этот подход позволяет модели сначала изучить базовую структуру и содержание видео, а затем уточнять своё понимание на более высоких разрешениях.
- Явное равномерное выборочное обучение: Для стабилизации процесса обучения, CogVideoX-5B использует явное равномерное выборочное обучение, устанавливая различные интервалы выборки временных шагов для каждого параллельного ранга данных. Этот метод ускоряет сходимость и обеспечивает эффективное обучение модели по всей видеопоследовательности.
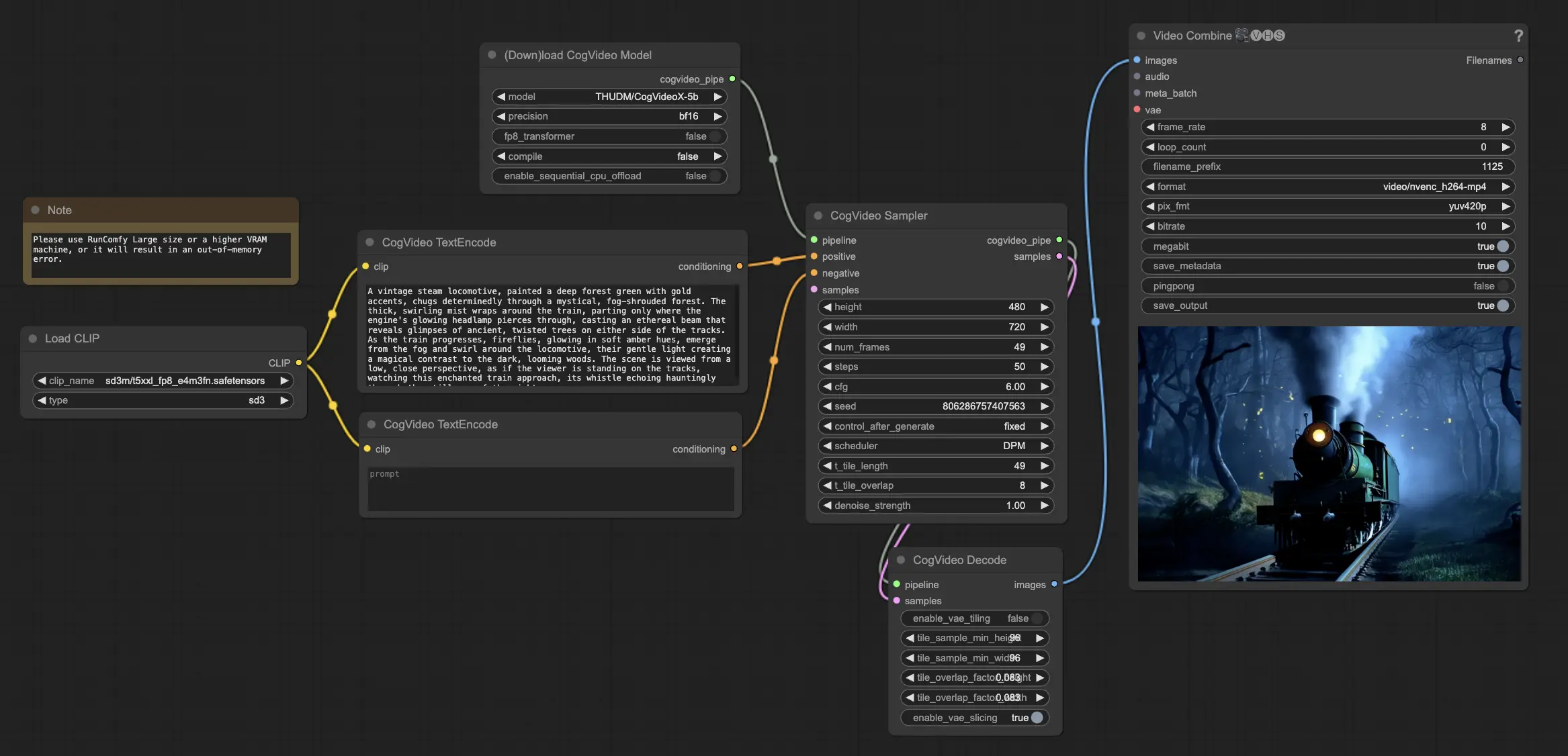
3. Как использовать рабочий процесс ComfyUI CogVideoX-5B
Шаг 1: Загрузите модель CogVideoX-5B
Начните с загрузки модели CogVideoX-5B в рабочий процесс ComfyUI. Модели CogVideoX-5B предварительно загружены на платформу RunComfy.
Шаг 2: Введите ваш текстовый запрос
Введите желаемую текстовую подсказку в назначенный узел, чтобы направить процесс генерации видео CogVideoX-5B. CogVideoX-5B отлично интерпретирует и трансформирует текстовые подсказки в динамическое видео.
4. Лицензионное соглашение
Код моделей CogVideoX выпущен под .
Модель CogVideoX-2B (включая соответствующий модуль Transformers и модуль VAE) выпущена под .
Модель CogVideoX-5B (модуль Transformers) выпущена под .

