


Раскройте возможности ComfyUI: руководство для начинающих с практическими занятиями
Updated: 5/21/2024
Привет, коллеги AI-художники! 👋 Добро пожаловать в наше дружественное для начинающих руководство по ComfyUI, невероятно мощному и гибкому инструменту для создания потрясающих произведений искусства, созданных ИИ. 🎨 В этом руководстве мы проведем вас через основы ComfyUI, изучим его функции и поможем вам раскрыть его потенциал, чтобы вывести ваше искусство на новый уровень. 🚀
Мы рассмотрим:
1. Что такое ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. С чего начать с ComfyUI?
- 1.3. Основные элементы управления
2. Рабочие процессы ComfyUI: Текст в изображение
- 2.1. Выбор модели
- 2.2. Ввод положительного и отрицательного запроса
- 2.3. Генерация изображения
- 2.4. Техническое объяснение ComfyUI
- 2.4.1 Загрузка узла Checkpoint
- 2.4.2. Кодирование текста CLIP
- 2.4.3. Пустое латентное изображение
- 2.4.4. VAE
- 2.4.5. KSampler
3. Рабочий процесс ComfyUI: Изображение в изображение
4. ComfyUI SDXL
5. ComfyUI Inpainting
6. ComfyUI Outpainting
7. ComfyUI Upscale
- 7.1. Масштабирование пикселей
- 7.1.1. Масштабирование пикселей по алгоритму
- 7.1.2. Масштабирование пикселей по модели
- 7.2. Масштабирование латентного изображения
- 7.3. Масштабирование пикселей vs. Масштабирование латентного изображения
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. Как установить отсутствующие пользовательские узлы
- 9.2. Как обновить пользовательские узлы
- 9.3. Как загрузить пользовательские узлы в ваш рабочий процесс
10. Встраивание ComfyUI
- 10.1. Встраивание с автозаполнением
- 10.2. Вес встраивания
11. ComfyUI LoRA
- 11.1. Простые рабочие процессы LoRA
- 11.2. Несколько LoRA
12. Сокращения и трюки для ComfyUI
- 12.1. Копирование и вставка
- 12.2. Перемещение нескольких узлов
- 12.3. Обход узла
- 12.4. Минимизация узла
- 12.5. Генерация изображения
- 12.6. Встроенный рабочий процесс
- 12.7. Фиксация семян для экономии времени
13. ComfyUI Online
1. Что такое ComfyUI? 🤔
ComfyUI — это как волшебная палочка 🪄 для легкого создания потрясающих произведений искусства, созданных ИИ. В основе ComfyUI лежит графический интерфейс пользователя (GUI) на основе узлов, построенный на основе Stable Diffusion, передовой модели глубокого обучения, которая генерирует изображения из текстовых описаний. 🌟 Но что делает ComfyUI действительно особенным, так это то, как он позволяет художникам, таким как вы, раскрыть свою креативность и воплотить в жизнь свои самые смелые идеи.
Представьте себе цифровое полотно, на котором вы можете создавать свои уникальные рабочие процессы генерации изображений, соединяя различные узлы, каждый из которых представляет собой определенную функцию или операцию. 🧩 Это как создание визуального рецепта для ваших шедевров, созданных ИИ!
Хотите создать изображение с нуля, используя текстовый запрос? Для этого есть узел! Нужно применить определенный семплер или настроить уровень шума? Просто добавьте соответствующие узлы и наблюдайте за магией. ✨
Но вот что самое лучшее: ComfyUI разбивает рабочий процесс на перестраиваемые элементы, давая вам свободу создавать свои собственные рабочие процессы, адаптированные к вашему художественному видению. 🖼️ Это как иметь персонализированный набор инструментов, который адаптируется к вашему творческому процессу.
1.1. ComfyUI vs. AUTOMATIC1111 🆚
AUTOMATIC1111 — это стандартный GUI для Stable Diffusion. Так стоит ли использовать ComfyUI вместо него? Давайте сравним:
✅ Преимущества использования ComfyUI:
- Легкий: Работает быстро и эффективно.
- Гибкий: Высококонфигурируемый для удовлетворения ваших потребностей.
- Прозрачный: Поток данных виден и легко понимается.
- Легко делиться: Каждый файл представляет собой воспроизводимый рабочий процесс.
- Хорош для прототипирования: Создавайте прототипы с графическим интерфейсом вместо кодирования.
❌ Недостатки использования ComfyUI:
- Непоследовательный интерфейс: Каждый рабочий процесс может иметь разную компоновку узлов.
- Слишком много деталей: Среднему пользователю может не понадобиться знать внутренние соединения.
1.2. С чего начать с ComfyUI? 🏁
Мы считаем, что лучший способ изучить ComfyUI — это погрузиться в примеры и испытать его на практике. 🙌 Именно поэтому мы создали это уникальное руководство, которое выделяется среди других. В этом руководстве вы найдете подробное пошаговое руководство, которое вы можете следовать.
Но вот что самое лучшее: 🌟 Мы интегрировали ComfyUI прямо в эту веб-страницу! Вы сможете взаимодействовать с примерами ComfyUI в реальном времени по мере прохождения руководства.🌟 Давайте начнем!
2. Рабочие процессы ComfyUI: Текст в изображение 🖼️
Начнем с самого простого случая: генерация изображения из текста. Нажмите Queue Prompt, чтобы запустить рабочий процесс. После короткого ожидания вы увидите свое первое сгенерированное изображение! Чтобы проверить свою очередь, просто нажмите View Queue.
Вот стандартный рабочий процесс текст-в-изображение, который вы можете попробовать:
Основные строительные блоки 🕹️
Рабочий процесс ComfyUI состоит из двух основных строительных блоков: Узлы и Края.
- Узлы — это прямоугольные блоки, например, Load Checkpoint, Clip Text Encoder и т. д. Каждый узел выполняет определенный код и требует входных данных, выходных данных и параметров.
- Края — это провода, соединяющие выходы и входы между узлами.
Основные элементы управления 🕹️
- Увеличивайте и уменьшайте масштаб с помощью колесика мыши или двухпальцевого жеста.
- Перетаскивайте и удерживайте точку ввода или вывода, чтобы создавать соединения между узлами.
- Перемещайтесь по рабочей области, удерживая и перетаскивая левую кнопку мыши.
Давайте разберем детали этого рабочего процесса.
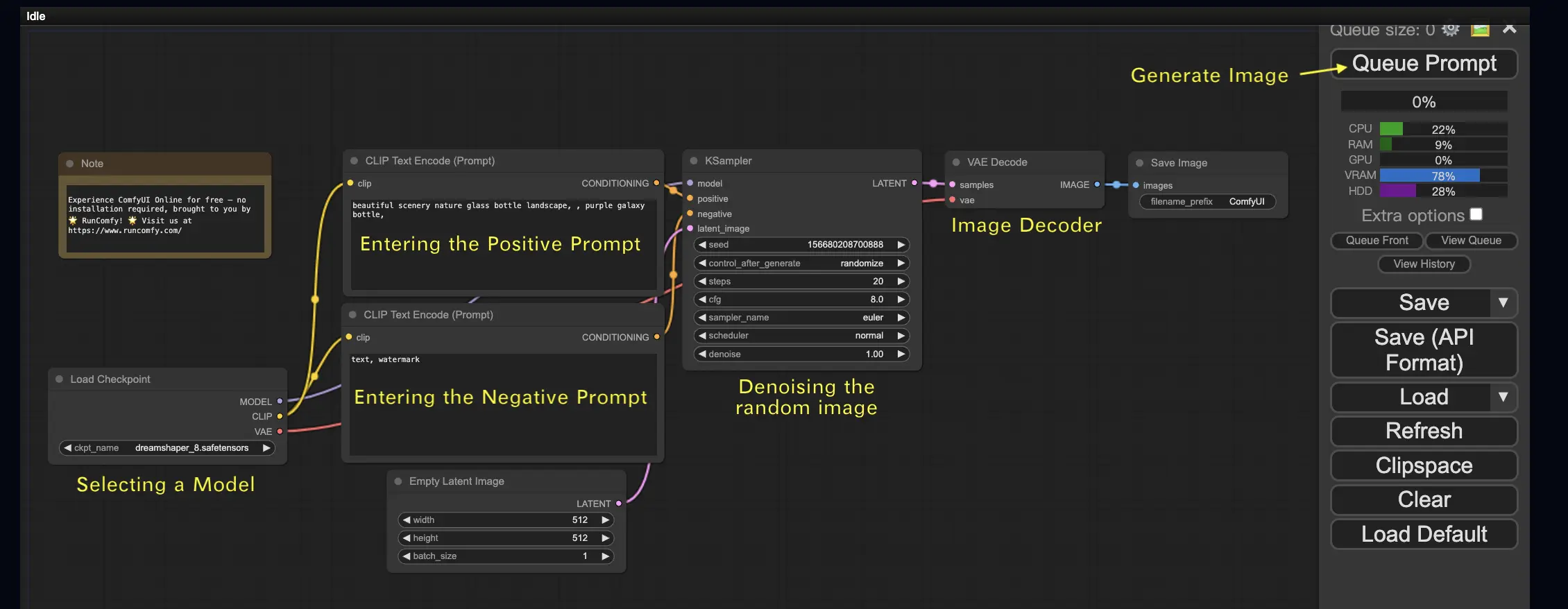
2.1. Выбор модели 🗃️
Сначала выберите модель Stable Diffusion Checkpoint в узле Load Checkpoint. Нажмите на имя модели, чтобы просмотреть доступные модели. Если нажатие на имя модели не приводит к результату, возможно, вам потребуется загрузить пользовательскую модель.
2.2. Ввод положительного и отрицательного запроса 📝
Вы увидите два узла с меткой CLIP Text Encode (Prompt). Верхний запрос подключен к положительному входу узла KSampler, а нижний запрос подключен к отрицательному входу. Поэтому введите свой положительный запрос в верхний узел, а отрицательный запрос в нижний.
Узел CLIP Text Encode преобразует запрос в токены и кодирует их в встраивания с помощью текстового кодировщика.
💡 Совет: Используйте синтаксис (keyword:weight), чтобы контролировать вес ключевого слова, например, (keyword:1.2), чтобы увеличить его эффект, или (keyword:0.8), чтобы уменьшить его.
2.3. Генерация изображения 🎨
Нажмите Queue Prompt, чтобы запустить рабочий процесс. После короткого ожидания ваше первое изображение будет сгенерировано!
2.4. Техническое объяснение ComfyUI 🤓
Сила ComfyUI заключается в его настраиваемости. Понимание того, что делает каждый узел, позволяет адаптировать их к вашим потребностям. Но прежде чем углубляться в детали, давайте рассмотрим процесс Stable Diffusion, чтобы лучше понять, как работает ComfyUI.
Процесс Stable Diffusion можно резюмировать в трех основных шагах:
- Кодирование текста: Запрос, введенный пользователем, компилируется в отдельные векторные признаки слов компонентом, называемым Text Encoder. Этот шаг преобразует текст в формат, который модель может понять и использовать.
- Преобразование латентного пространства: Векторные признаки от Text Encoder и случайное шумовое изображение преобразуются в латентное пространство. В этом пространстве случайное изображение проходит процесс удаления шума на основе векторных признаков, что приводит к промежуточному продукту. Этот шаг — это место, где происходит магия, так как модель учится связывать текстовые признаки с визуальными представлениями.
- Декодирование изображения: Наконец, промежуточный продукт из латентного пространства декодируется Image Decoder, преобразуя его в реальное изображение, которое мы можем видеть и оценить.
Теперь, когда у нас есть общее представление о процессе Stable Diffusion, давайте углубимся в ключевые компоненты и узлы в ComfyUI, которые делают этот процесс возможным.
2.4.1 Загрузка узла Checkpoint 🗃️
Узел Load Checkpoint в ComfyUI важен для выбора модели Stable Diffusion. Модель Stable Diffusion состоит из трех основных компонентов: MODEL, CLIP и VAE. Давайте рассмотрим каждый компонент и его связь с соответствующими узлами в ComfyUI.
- MODEL: Компонент MODEL — это модель предсказания шума, которая работает в латентном пространстве. Он отвечает за основной процесс генерации изображений из латентного представления. В ComfyUI выход MODEL узла Load Checkpoint подключается к узлу KSampler, где происходит обратный процесс диффузии. Узел KSampler использует MODEL для поэтапного удаления шума из латентного представления, постепенно улучшая изображение до тех пор, пока оно не совпадет с желаемым запросом.
- CLIP: CLIP (Contrastive Language-Image Pre-training) — это языковая модель, которая предварительно обрабатывает положительные и отрицательные запросы, предоставленные пользователем. Он преобразует текстовые запросы в формат, который MODEL может понять и использовать для управления процессом генерации изображений. В ComfyUI выход CLIP узла Load Checkpoint подключается к узлу CLIP Text Encode. Узел CLIP Text Encode принимает запросы, предоставленные пользователем, и передает их в языковую модель CLIP, преобразуя каждое слово в встраивания. Эти встраивания захватывают семантическое значение слов и позволяют MODEL генерировать изображения, соответствующие данным запросам.
- VAE: VAE (Variational AutoEncoder) отвечает за преобразование изображения между пиксельным пространством и латентным пространством. Он состоит из кодировщика, который сжимает изображение в низкоразмерное латентное представление, и декодировщика, который восстанавливает изображение из латентного представления. В процессе текст-в-изображение VAE используется только на последнем шаге для преобразования сгенерированного изображения из латентного пространства обратно в пиксельное пространство. Узел VAE Decode в ComfyUI принимает выход узла KSampler (который работает в латентном пространстве) и использует декодировщик VAE для преобразования латентного представления в окончательное изображение в пиксельном пространстве.
Важно отметить, что VAE является отдельным компонентом от языковой модели CLIP. В то время как CLIP фокусируется на обработке текстовых запросов, VAE занимается преобразованием между пиксельным и латентным пространствами.
2.4.2. Кодирование текста CLIP 📝
Узел CLIP Text Encode в ComfyUI отвечает за прием запросов, предоставленных пользователем, и их передачу в языковую модель CLIP. CLIP — это мощная языковая модель, которая понимает семантическое значение слов и может связывать их с визуальными концепциями. Когда запрос вводится в узел CLIP Text Encode, он проходит процесс преобразования, в котором каждое слово преобразуется в встраивания. Эти встраивания представляют собой высокоразмерные векторы, которые захватывают семантическую информацию слов. Преобразуя запросы в встраивания, CLIP позволяет MODEL генерировать изображения, которые точно отражают значение и намерение данных запросов.
2.4.3. Пустое латентное изображение 🌌
В процессе текст-в-изображение генерация начинается с случайного изображения в латентном пространстве. Это случайное изображение служит начальным состоянием для работы MODEL. Размер латентного изображения пропорционален фактическому размеру изображения в пиксельном пространстве. В ComfyUI вы можете настроить высоту и ширину латентного изображения, чтобы контролировать размер сгенерированного изображения. Кроме того, вы можете установить размер партии, чтобы определить количество изображений, генерируемых за один запуск.
Оптимальные размеры латентных изображений зависят от используемой модели Stable Diffusion. Для моделей SD v1.5 рекомендованные размеры составляют 512x512 или 768x768, а для моделей SDXL оптимальный размер составляет 1024x1024. ComfyUI предлагает ряд общих соотношений сторон, таких как 1:1 (квадрат), 3:2 (пейзаж), 2:3 (портрет), 4:3 (пейзаж), 3:4 (портрет), 16:9 (широкий экран) и 9:16 (вертикальный). Важно отметить, что ширина и высота латентного изображения должны быть кратны 8, чтобы обеспечить совместимость с архитектурой модели.
2.4.4. VAE 🔍
VAE (Variational AutoEncoder) — это ключевой компонент модели Stable Diffusion, который отвечает за преобразование изображений между пиксельным пространством и латентным пространством. Он состоит из двух основных частей: Image Encoder и Image Decoder.
Image Encoder принимает изображение в пиксельном пространстве и сжимает его в низкоразмерное латентное представление. Этот процесс сжатия значительно уменьшает размер данных, позволяя более эффективно обрабатывать и хранить их. Например, изображение размером 512x512 пикселей может быть сжато до латентного представления размером 64x64.
С другой стороны, Image Decoder, также известный как VAE Decoder, отвечает за восстановление изображения из латентного представления обратно в пиксельное пространство. Он принимает сжатое латентное представление и расширяет его, чтобы сгенерировать окончательное изображение.
Использование VAE предлагает несколько преимуществ:
- Эффективность: Сжимая изображение в низкоразмерное латентное пространство, VAE позволяет быстрее генерировать и сократить время обучения. Уменьшенный размер данных позволяет более эффективно обрабатывать и использовать память.
- Манипуляция латентным пространством: Латентное пространство предоставляет более компактное и значимое представление изображения. Это позволяет более точно контролировать и редактировать детали и стиль изображения. Манипулируя латентным представлением, можно изменить определенные аспекты сгенерированного изображения.
Однако есть и некоторые недостатки:
- Потеря данных: Во время процесса кодирования и декодирования некоторые детали оригинального изображения могут быть утрачены. Шаги сжатия и восстановления могут ввести артефакты или небольшие вариации в окончательное изображение по сравнению с оригиналом.
- Ограниченное захватывание оригинальных данных: Низкоразмерное латентное пространство может не полностью захватить все сложные особенности и детали оригинального изображения. Некоторые данные могут быть утрачены во время процесса сжатия, что приводит к слегка менее точному представлению оригинальных данных.
Несмотря на эти ограничения, VAE играет важную роль в модели Stable Diffusion, обеспечивая эффективное преобразование между пиксельным пространством и латентным пространством, способствуя более быстрой генерации и более точному контролю над сгенерированными изображениями.
2.4.5. KSampler ⚙️
Узел KSampler в ComfyUI является сердцем процесса генерации изображений в Stable Diffusion. Он отвечает за удаление шума из случайного изображения в латентном пространстве, чтобы оно соответствовало запросу пользователя. KSampler использует технику, называемую обратной диффузией, где он итеративно уточняет латентное представление, удаляя шум и добавляя значимые детали на основе руководства от встраиваний CLIP.
Узел KSampler предлагает несколько параметров, которые позволяют пользователям точно настроить процесс генерации изображений:
Seed: Значение семени контролирует начальный шум и композицию окончательного изображения. Установив конкретное значение семени, пользователи могут добиться воспроизводимых результатов и поддерживать согласованность между несколькими генерациями.
Control_after_generation: Этот параметр определяет, как изменяется значение семени после каждой генерации. Он может быть установлен на случайное значение (генерировать новое случайное семя для каждого запуска), инкремент (увеличивать значение семени на 1), декремент (уменьшать значение семени на 1) или фиксированное значение (оставлять значение семени постоянным).
Step: Количество шагов выборки определяет интенсивность процесса уточнения. Более высокие значения приводят к меньшему количеству артефактов и более детализированным изображениям, но также увеличивают время генерации.
Sampler_name: Этот параметр позволяет пользователям выбрать конкретный алгоритм выборки, используемый узлом KSampler. Различные алгоритмы выборки могут давать немного разные результаты и иметь разную скорость генерации.
Scheduler: Планировщик контролирует, как изменяется уровень шума на каждом шаге процесса удаления шума. Он определяет скорость удаления шума из латентного представления.
Denoise: Параметр denoise устанавливает количество начального шума, которое должно быть удалено в процессе удаления шума. Значение 1 означает, что весь шум будет удален, что приведет к чистому и детализированному изображению.
Настраивая эти параметры, вы можете точно настроить процесс генерации изображений для достижения желаемых результатов.
Теперь вы готовы отправиться в путешествие по ComfyUI?
На RunComfy мы создали идеальный онлайн-опыт ComfyUI специально для вас. Скажите прощай сложным установкам! 🎉 Попробуйте ComfyUI Online сейчас и раскройте свой художественный потенциал как никогда раньше! 🎉
3. Рабочий процесс ComfyUI: Изображение в изображение 🖼️
Рабочий процесс Изображение в изображение генерирует изображение на основе запроса и входного изображения. Попробуйте сами!
Чтобы использовать рабочий процесс Изображение в изображение:
- Выберите модель контрольной точки.
- Загрузите изображение в качестве изображения-запроса.
- Пересмотрите положительные и отрицательные запросы.
- Опционально отрегулируйте denoise (силу удаления шума) в узле KSampler.
- Нажмите Queue Prompt, чтобы начать генерацию.
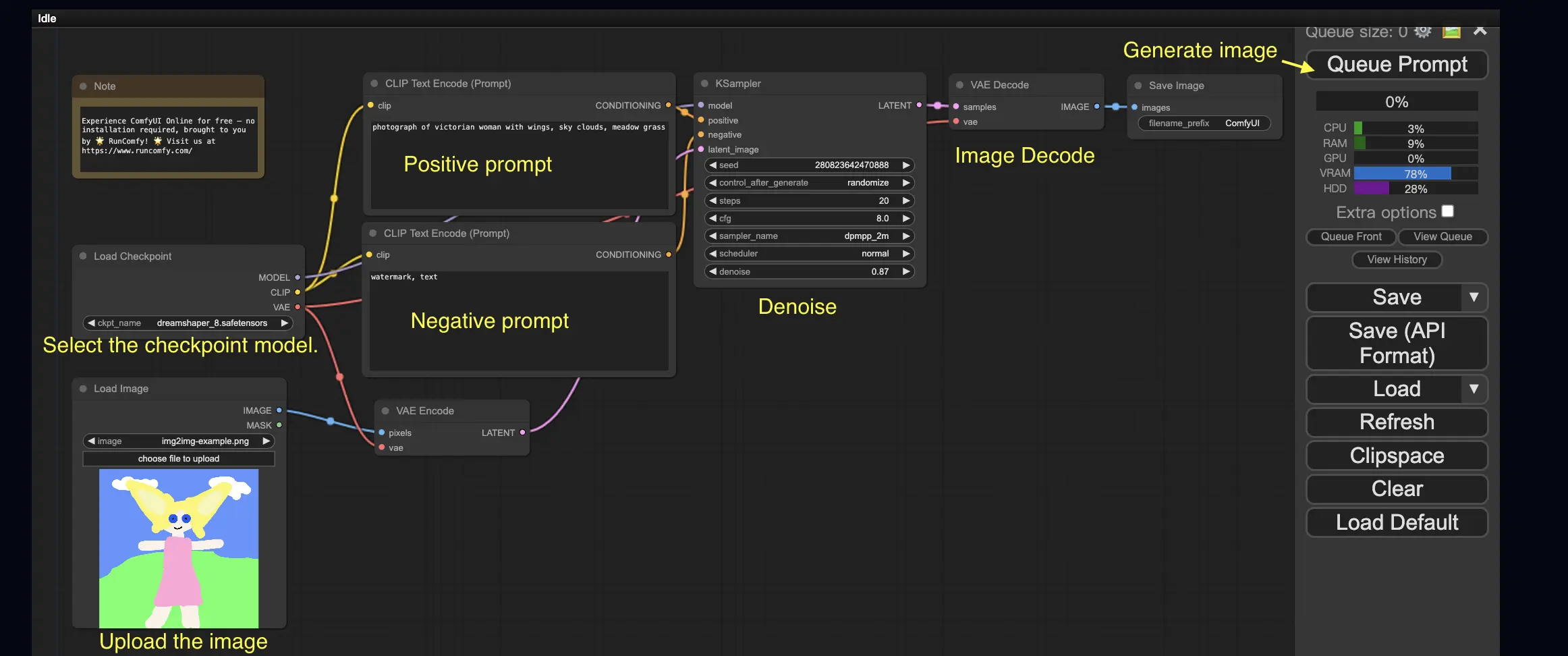
Для получения дополнительных премиум-рабочих процессов ComfyUI посетите наш 🌟Список рабочих процессов ComfyUI🌟
4. ComfyUI SDXL 🚀
Благодаря своей экстремальной настраиваемости, ComfyUI является одним из первых GUI, поддерживающих модель Stable Diffusion XL. Давайте попробуем!
Чтобы использовать рабочий процесс ComfyUI SDXL:
- Пересмотрите положительные и отрицательные запросы.
- Нажмите Queue Prompt, чтобы начать генерацию.
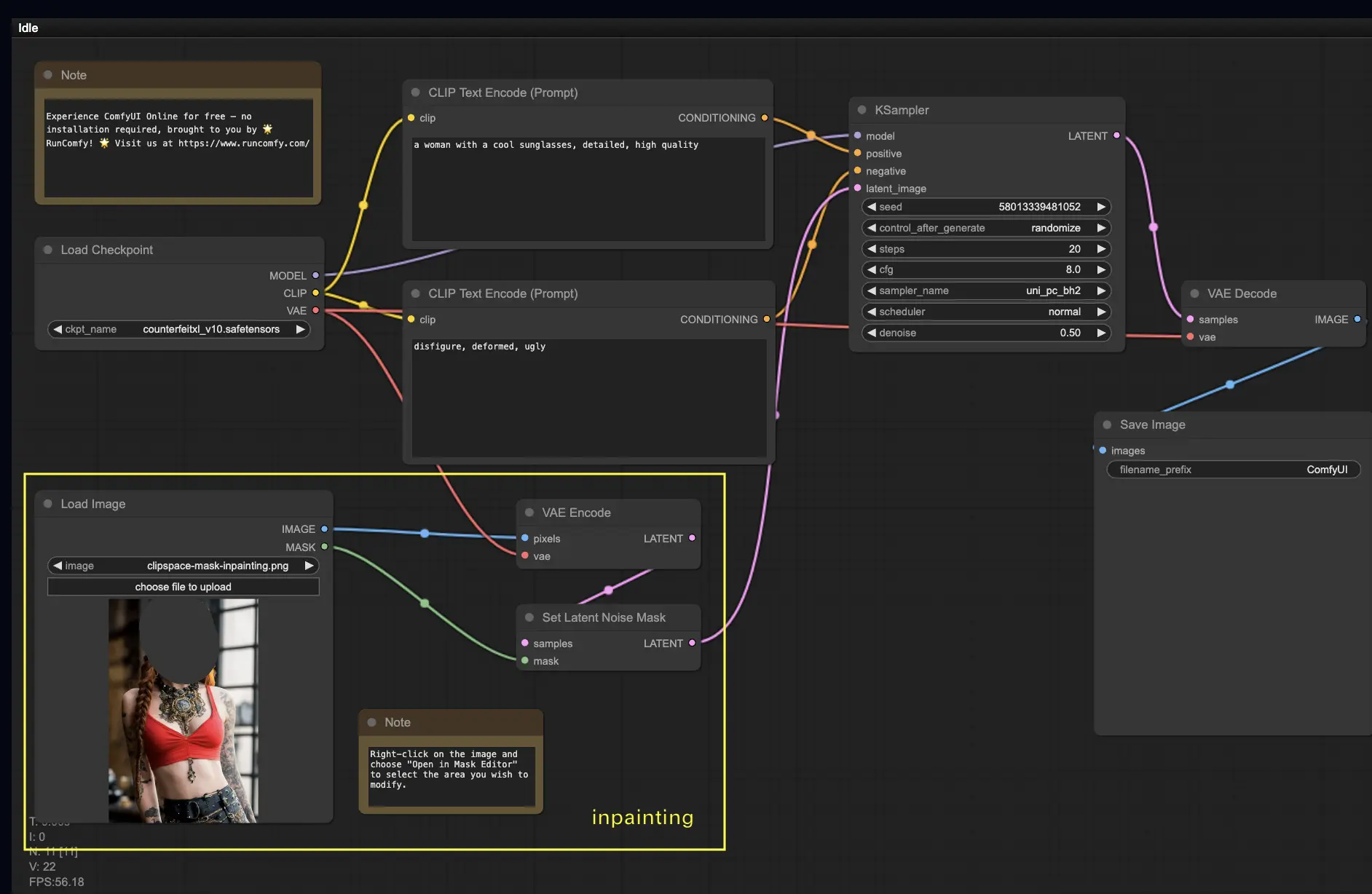
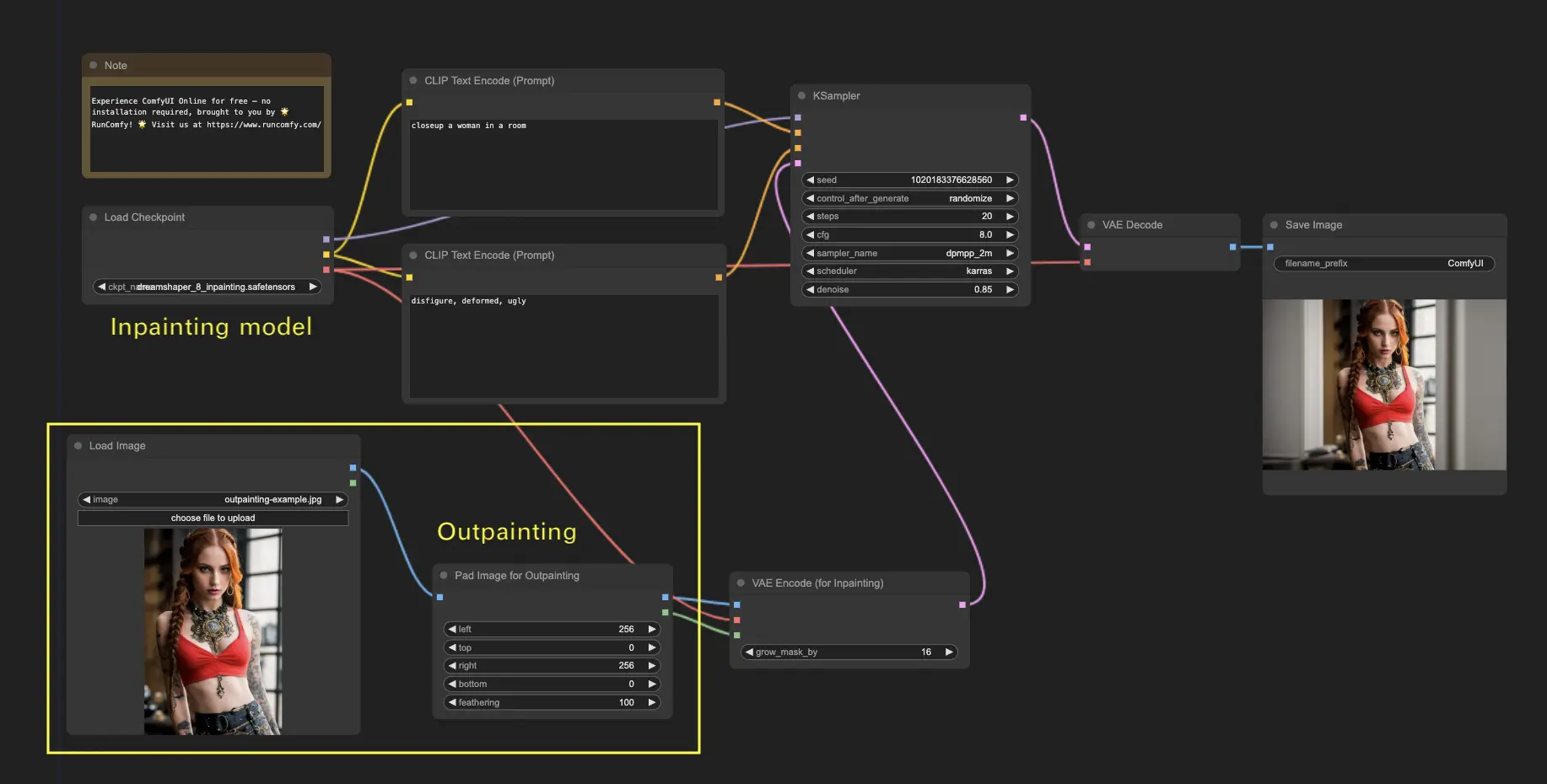
5. ComfyUI Inpainting 🎨
Давайте углубимся в более сложные вещи: inpainting! Когда у вас есть отличное изображение, но вы хотите изменить определенные части, inpainting — это лучший метод. Попробуйте здесь!
Чтобы использовать рабочий процесс inpainting:
- Загрузите изображение, которое вы хотите inpaint.
- Щелкните правой кнопкой мыши на изображении и выберите "Open in MaskEditor". Маскируйте область для регенерации, затем нажмите "Save to node".
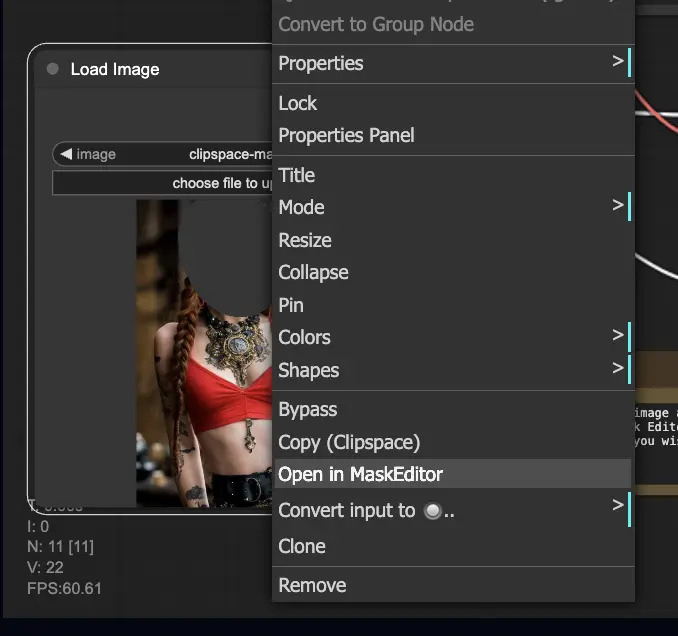
- Выберите модель контрольной точки:
- Этот рабочий процесс работает только со стандартной моделью Stable Diffusion, а не с моделью Inpainting.
- Если вы хотите использовать модель inpainting, пожалуйста, переключите узлы "VAE Encode" и "Set Noise Latent Mask" на узел "VAE Encode (Inpaint)", который специально предназначен для моделей inpainting.
- Настройте процесс inpainting:
- В узле CLIP Text Encode (Prompt) вы можете ввести дополнительную информацию, чтобы направить процесс inpainting. Например, вы можете указать стиль, тему или элементы, которые хотите включить в область inpainting.
- Установите оригинальную силу удаления шума (denoise), например, 0.6.
- Нажмите Queue Prompt, чтобы выполнить inpainting.
6. ComfyUI Outpainting 🖌️
Outpainting — это еще одна захватывающая техника, которая позволяет вам расширять изображения за пределы их исходных границ. 🌆 Это как иметь бесконечное полотно для работы!
Чтобы использовать рабочий процесс ComfyUI Outpainting:
- Начните с изображения, которое хотите расширить.
- Используйте узел Pad Image для Outpainting в вашем рабочем процессе.
- Настройте параметры outpainting:
- left, top, right, bottom: Укажите количество пикселей для расширения в каждом направлении.
- feathering: Настройте плавность перехода между оригинальным изображением и областью outpainting. Более высокие значения создают более постепенный переход, но могут ввести эффект размытия.
- Настройте процесс outpainting:
- В узле CLIP Text Encode (Prompt) вы можете ввести дополнительную информацию, чтобы направить процесс outpainting. Например, вы можете указать стиль, тему или элементы, которые хотите включить в расширенную область.
- Экспериментируйте с разными запросами, чтобы достичь желаемых результатов.
- Тонко настройте узел VAE Encode (for Inpainting):
- Настройте параметр grow_mask_by, чтобы контролировать размер маски outpainting. Для оптимальных результатов рекомендуется значение больше 10.
- Нажмите Queue Prompt, чтобы начать процесс outpainting.
Для получения дополнительных премиум-рабочих процессов inpainting/outpainting посетите наш 🌟Список рабочих процессов ComfyUI🌟
7. ComfyUI Upscale ⬆️
Теперь давайте изучим ComfyUI upscale. Мы представим три основных рабочих процесса, которые помогут вам эффективно масштабировать.
Существует два основных метода масштабирования:
- Масштабирование пикселей: Прямое масштабирование видимого изображения.
- Вход: изображение, Выход: масштабированное изображение
- Масштабирование латентного изображения: Масштабирование невидимого латентного изображения.
- Вход: латентное изображение, Выход: масштабированное латентное изображение (требуется декодирование для превращения в видимое изображение)
7.1. Масштабирование пикселей 🖼️
Два способа достижения этого:
- С использованием алгоритмов: Самая быстрая скорость генерации, но немного уступает по качеству результатам по сравнению с моделями.
- С использованием моделей: Лучшие результаты, но более длительное время генерации.
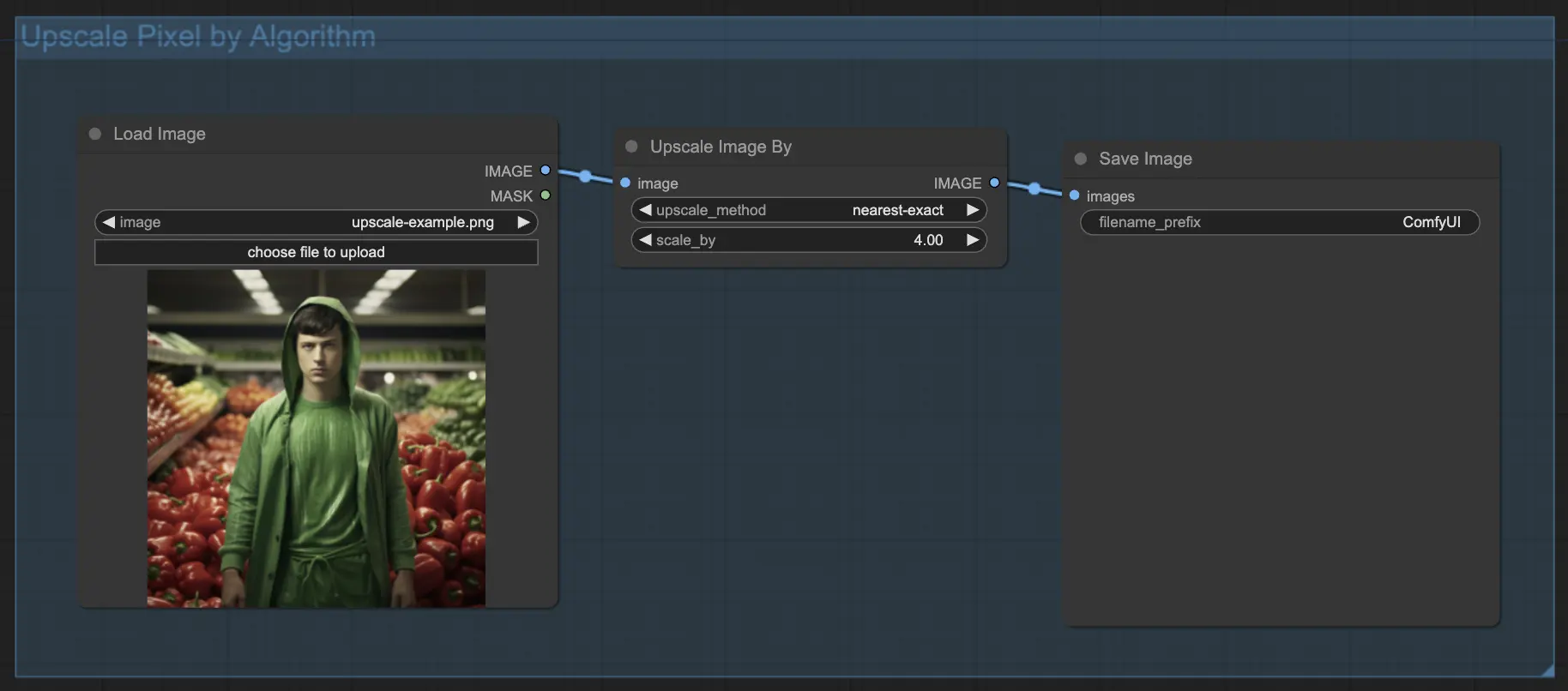
7.1.1. Масштабирование пикселей по алгоритму 🧮
- Добавьте узел Upscale Image.
- Параметр method: Выберите алгоритм масштабирования (bicubic, bilinear, nearest-exact).
- Параметр Scale: Укажите коэффициент масштабирования (например, 2 для 2x).
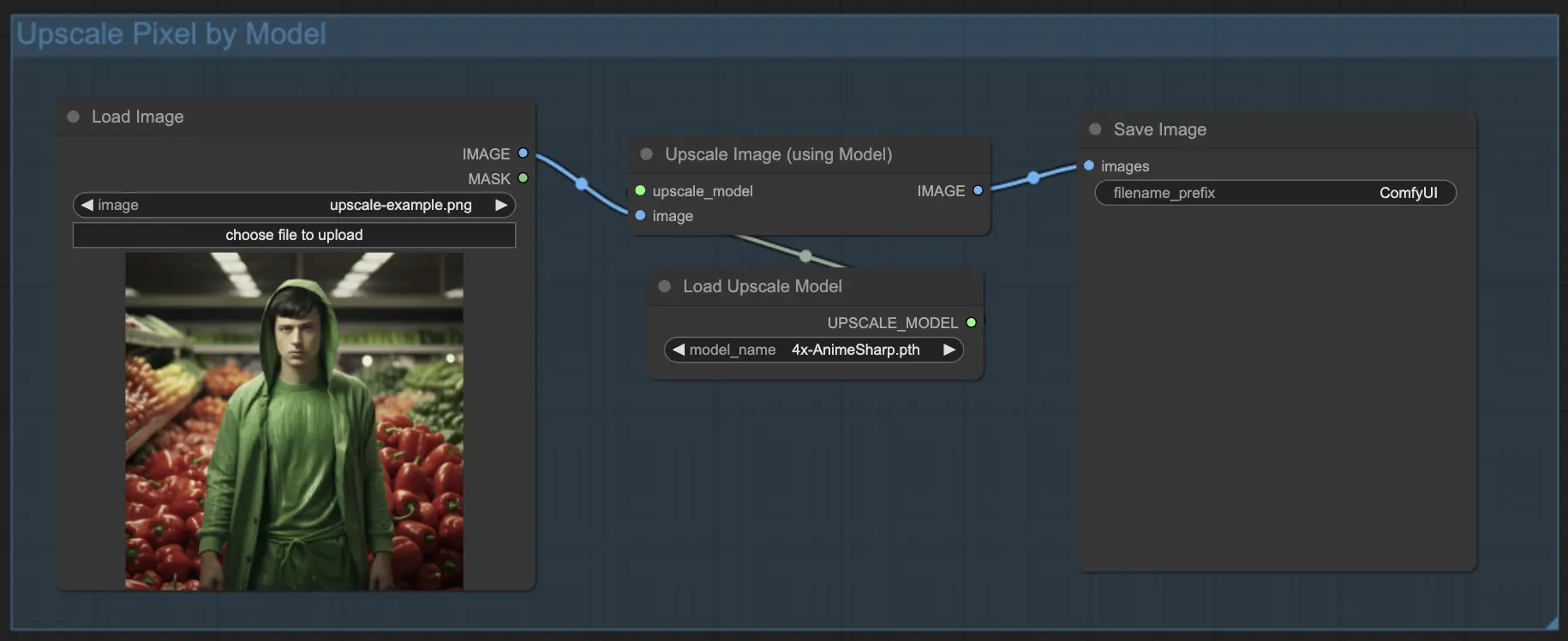
7.1.2. Масштабирование пикселей по модели 🤖
- Добавьте узел Upscale Image (using Model).
- Добавьте узел Load Upscale Model.
- Выберите модель, подходящую для вашего типа изображения (например, аниме или реальная жизнь).
- Выберите коэффициент масштабирования (X2 или X4).
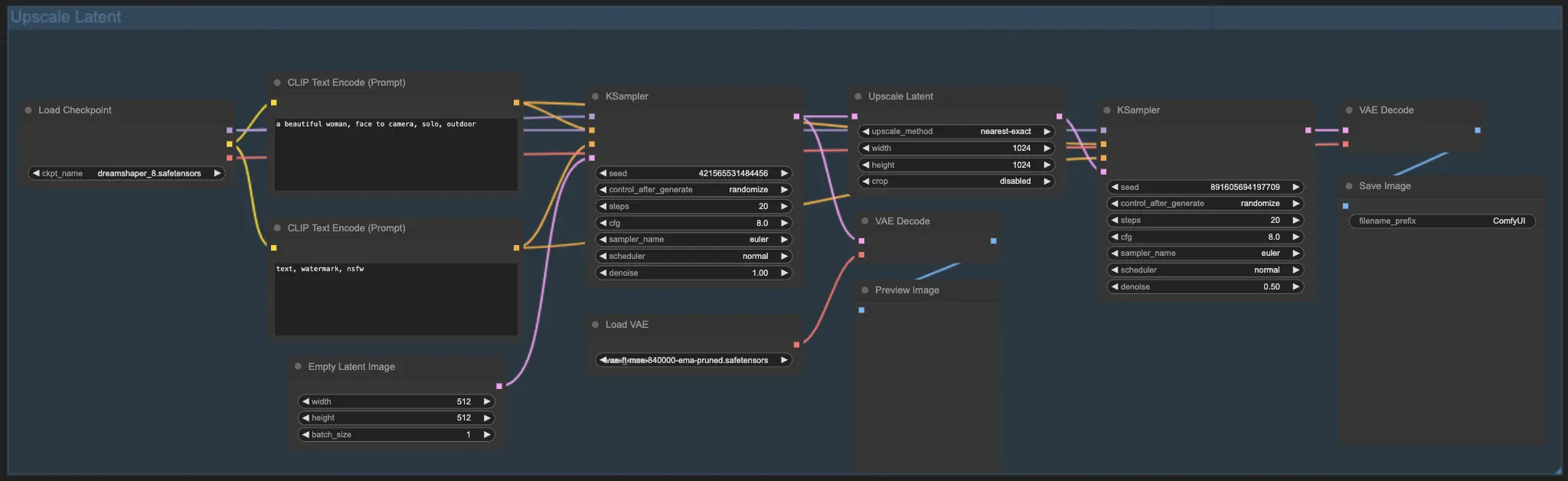
7.2. Масштабирование латентного изображения ⚙️
Другой метод масштабирования — это Масштабирование латентного изображения, также известное как Hi-res Latent Fix Upscale, которое напрямую масштабирует в латентном пространстве.
7.3. Масштабирование пикселей vs. Масштабирование латентного изображения 🆚
- Масштабирование пикселей: Только увеличивает изображение без добавления новой информации. Быстрая генерация, но может иметь эффект размытия и недостаток деталей.
- Масштабирование латентного изображения: В дополнение к увеличению, изменяет некоторые исходные данные изображения, обогащая детали. Может отклоняться от исходного изображения и имеет более медленную скорость генерации.
Для получения дополнительных премиум-рабочих процессов восстановления/масштабирования посетите наш 🌟Список рабочих процессов ComfyUI🌟
8. ComfyUI ControlNet 🎮
Приготовьтесь вывести свое AI-искусство на новый уровень с помощью ControlNet, революционной технологии, которая меняет правила игры в генерации изображений!
ControlNet — это как волшебная палочка 🪄, которая дает вам беспрецедентный контроль над вашими сгенерированными ИИ изображениями. Он работает в паре с мощными моделями, такими как Stable Diffusion, улучшая их возможности и позволяя вам управлять процессом создания изображений, как никогда раньше!
Представьте, что вы можете указать края, позы людей, глубину или даже карты сегментации вашего желаемого изображения. 🌠 С ControlNet вы можете сделать именно это!
Если вы хотите углубиться в мир ControlNet и раскрыть его полный потенциал, у нас есть для вас подробное руководство по освоению ControlNet в ComfyUI! 📚 Оно наполнено пошаговыми руководствами и вдохновляющими примерами, чтобы помочь вам стать профессионалом в ControlNet. 🏆
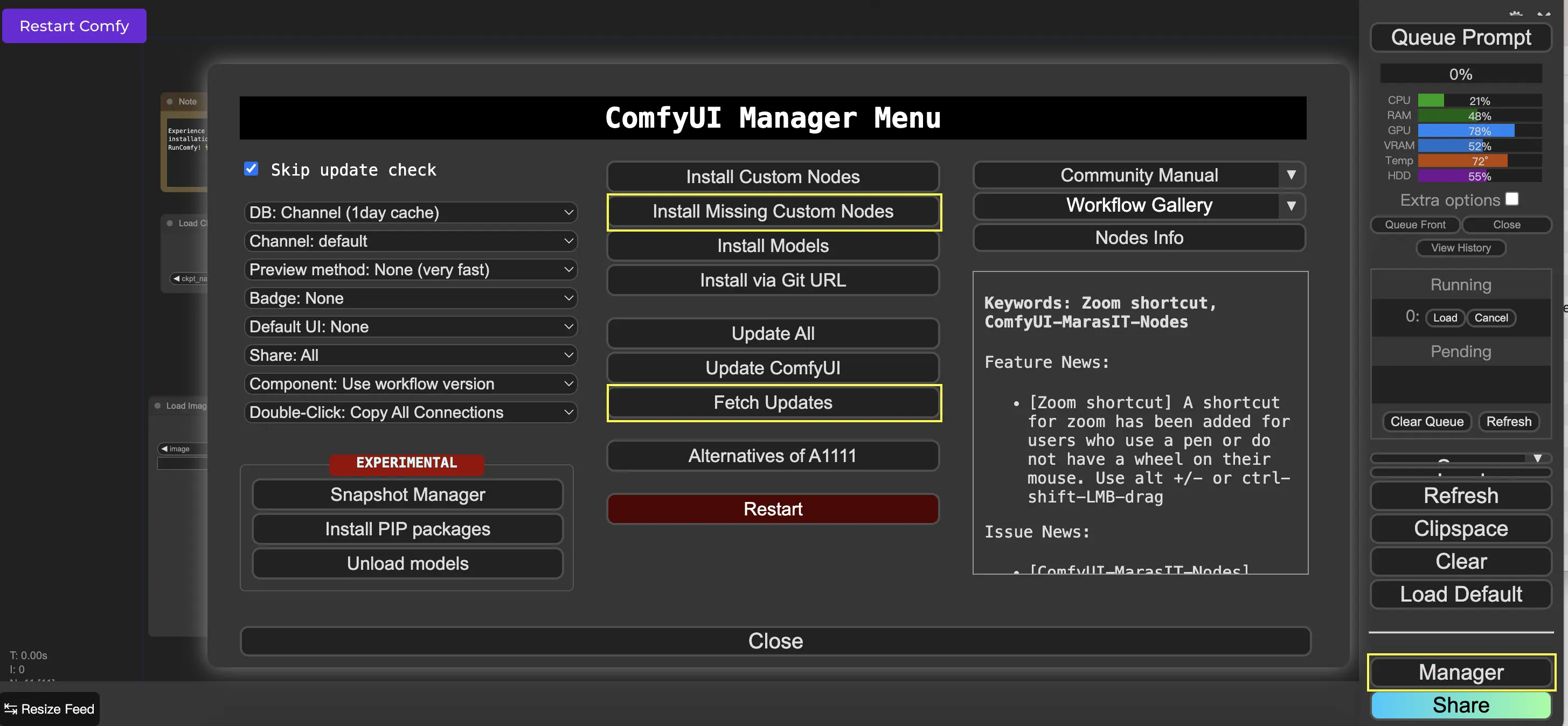
9. ComfyUI Manager 🛠️
ComfyUI Manager — это пользовательский узел, который позволяет вам устанавливать и обновлять другие пользовательские узлы через интерфейс ComfyUI. Вы найдете кнопку Manager в меню Queue Prompt.
9.1. Как установить отсутствующие пользовательские узлы 📥
Если рабочий процесс требует пользовательских узлов, которые вы не установили, выполните следующие шаги:
- Нажмите Manager в```json меню.
- Нажмите Install Missing Custom Nodes.
- Полностью перезапустите ComfyUI.
- Обновите браузер.
9.2. Как обновить пользовательские узлы 🔄
- Нажмите Manager в меню.
- Нажмите Fetch Updates (может занять некоторое время).
- Нажмите Install Custom Nodes.
- Если обновление доступно, рядом с установленным пользовательским узлом появится кнопка Update.
- Нажмите Update, чтобы обновить узел.
- Перезапустите ComfyUI.
- Обновите браузер.
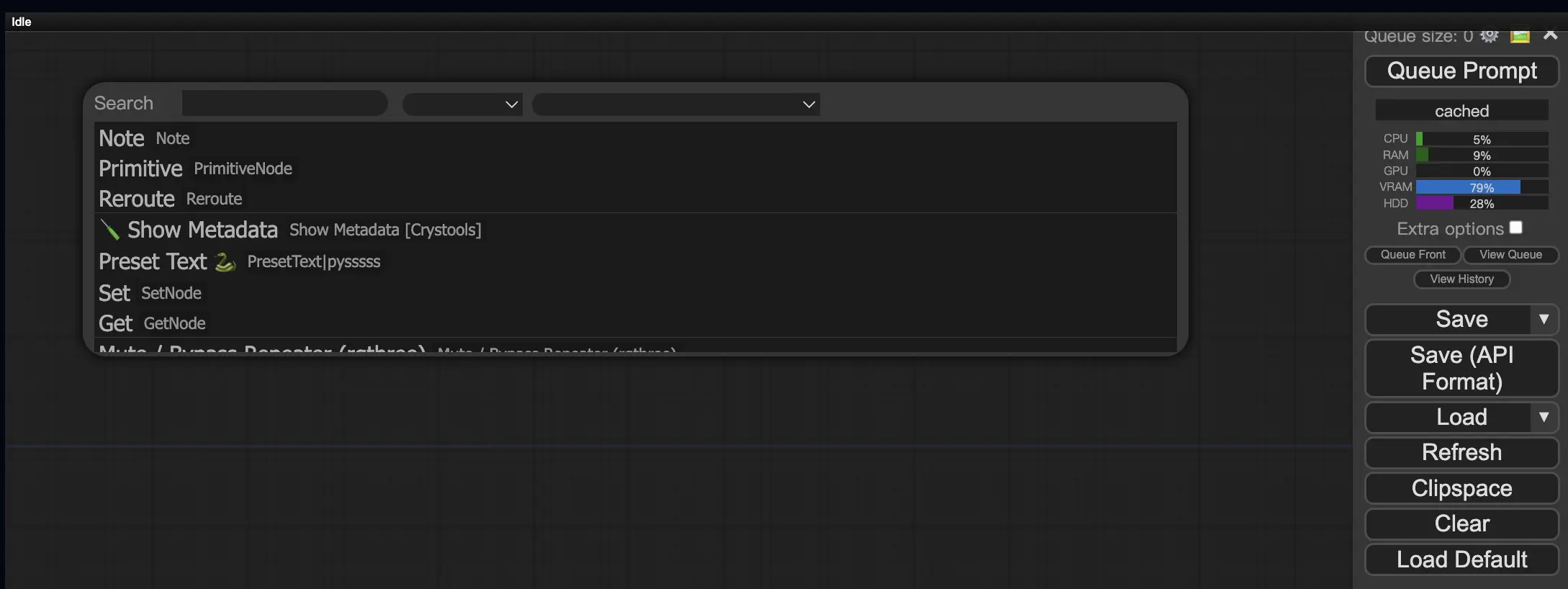
9.3. Как загрузить пользовательские узлы в ваш рабочий процесс 🔍
Дважды щелкните любую пустую область, чтобы вызвать меню для поиска узлов.
10. Встраивание ComfyUI 📝
Встраивания, также известные как текстовая инверсия, являются мощной функцией в ComfyUI, которая позволяет вам вносить пользовательские концепции или стили в ваши сгенерированные ИИ изображения. 💡 Это как научить ИИ новому слову или фразе и ассоциировать их с определенными визуальными характеристиками.
Чтобы использовать встраивания в ComfyUI, просто введите "embedding:" за которым следует имя вашего встраивания в поле положительного или отрицательного запроса. Например:
embedding: BadDream
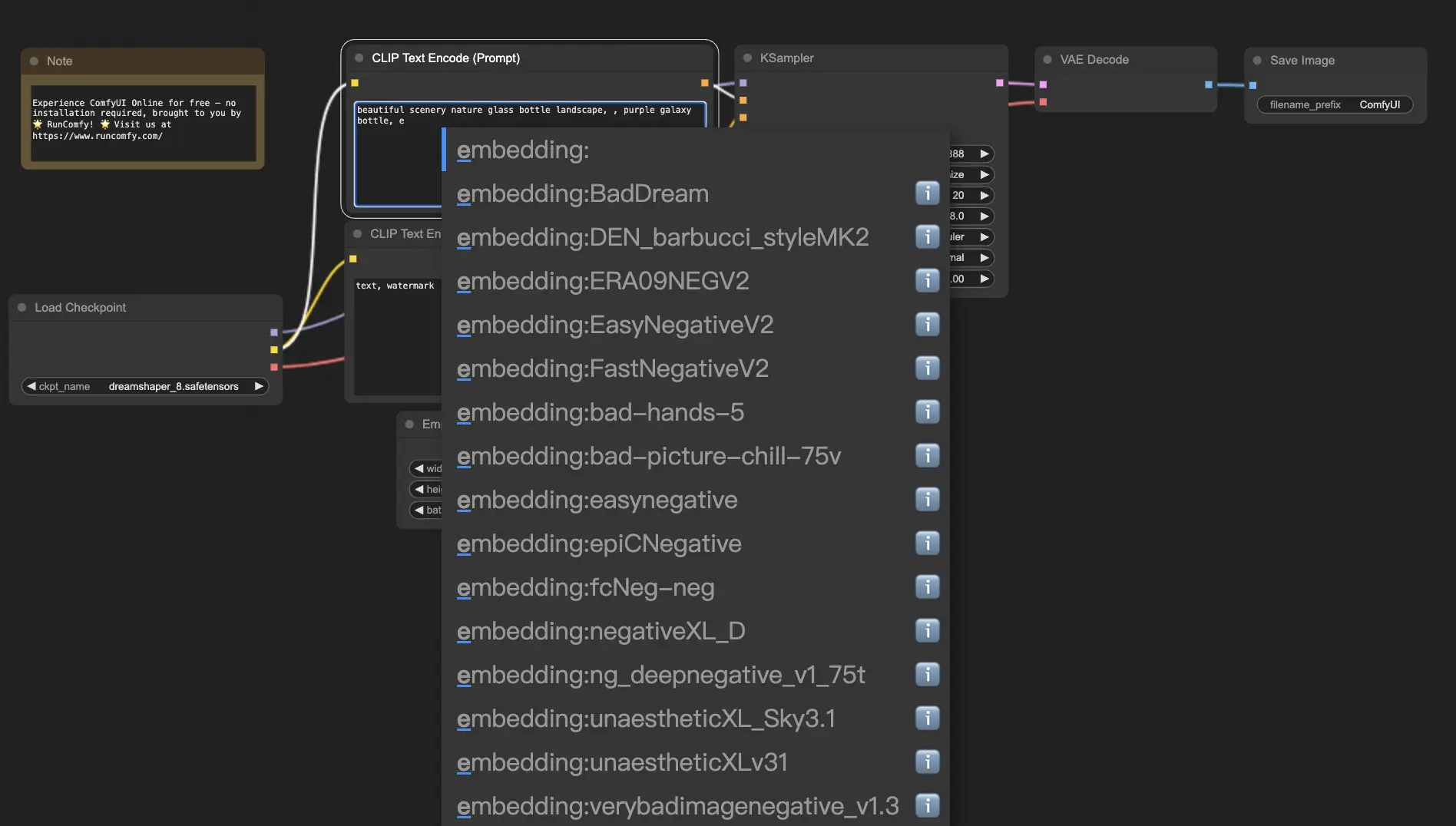
Когда вы используете этот запрос, ComfyUI будет искать файл встраивания с именем "BadDream" в папке ComfyUI > models > embeddings. 📂 Если он найдет совпадение, он применит соответствующие визуальные характеристики к вашему сгенерированному изображению.
Встраивания — это отличный способ персонализировать ваше ИИ-искусство и достичь определенных стилей или эстетики. 🎨 Вы можете создать свои собственные встраивания, обучив их на наборе изображений, представляющих желаемую концепцию или стиль.
10.1. Встраивание с автозаполнением 🔠
Запоминание точных имен ваших встраиваний может быть хлопотным, особенно если у вас большая коллекция. 😅 Вот тут на помощь приходит пользовательский узел ComfyUI-Custom-Scripts!
Чтобы включить автозаполнение имен встраиваний:
- Откройте ComfyUI Manager, нажав на "Manager" в верхнем меню.
- Перейдите в "Install Custom nodes" и найдите "ComfyUI-Custom-Scripts".
- Нажмите "Install", чтобы добавить пользовательский узел в вашу установку ComfyUI.
- Перезапустите ComfyUI, чтобы применить изменения.
Как только у вас будет установлен узел ComfyUI-Custom-Scripts, использование встраиваний станет более удобным. 😊 Просто начните вводить "embedding:" в поле запроса, и появится список доступных встраиваний. Вы можете выбрать нужное встраивание из списка, сэкономив время и усилия!
10.2. Вес встраивания ⚖️
Знаете ли вы, что вы можете контролировать силу ваших встраиваний? 💪 Поскольку встраивания по сути являются ключевыми словами, вы можете применять к ним веса так же, как и к обычным ключевым словам в ваших запросах.
Чтобы настроить вес встраивания, используйте следующий синтаксис:
(embedding: BadDream:1.2)
В этом примере вес встраивания "BadDream" увеличен на 20%. Более высокие веса (например, 1.2) сделают встраивание более заметным, в то время как более низкие веса (например, 0.8) уменьшат его влияние. 🎚️ Это дает вам еще больше контроля над окончательным результатом!
11. ComfyUI LoRA 🧩
LoRA, сокращение от Low-rank Adaptation, — это еще одна захватывающая функция в ComfyUI, которая позволяет вам модифицировать и точно настраивать ваши контрольные модели. 🎨 Это как добавление небольшой специализированной модели поверх вашей базовой модели для достижения определенных стилей или включения пользовательских элементов.
Модели LoRA компактны и эффективны, что делает их легкими в использовании и обмене. Они обычно используются для задач, таких как изменение художественного стиля изображения или внедрение конкретного человека или объекта в сгенерированный результат.
Когда вы применяете модель LoRA к контрольной модели, она модифицирует компоненты MODEL и CLIP, оставляя VAE (Вариационный Автоэнкодер) нетронутым. Это означает, что LoRA фокусируется на настройке содержания и стиля изображения без изменения его общей структуры.
11.1. Как использовать LoRA 🔧
Использование LoRA в ComfyUI просто. Давайте рассмотрим самый простой метод:
- Выберите контрольную модель, которая будет служить основой для вашей генерации изображений.
- Выберите модель LoRA, которую вы хотите применить для изменения стиля или включения конкретных элементов.
- Пересмотрите положительные и отрицательные запросы, чтобы направить процесс генерации изображений.
- Нажмите "Queue Prompt", чтобы начать генерацию изображения с примененной LoRA. ▶
ComfyUI затем объединит контрольную модель и модель LoRA для создания изображения, которое отражает указанные запросы и включает модификации, введенные LoRA.
11.2. Несколько LoRA 🧩🧩
Но что, если вы хотите применить несколько LoRA к одному изображению? Не проблема! ComfyUI позволяет использовать две или более LoRA в одном рабочем процессе текст-в-изображение.
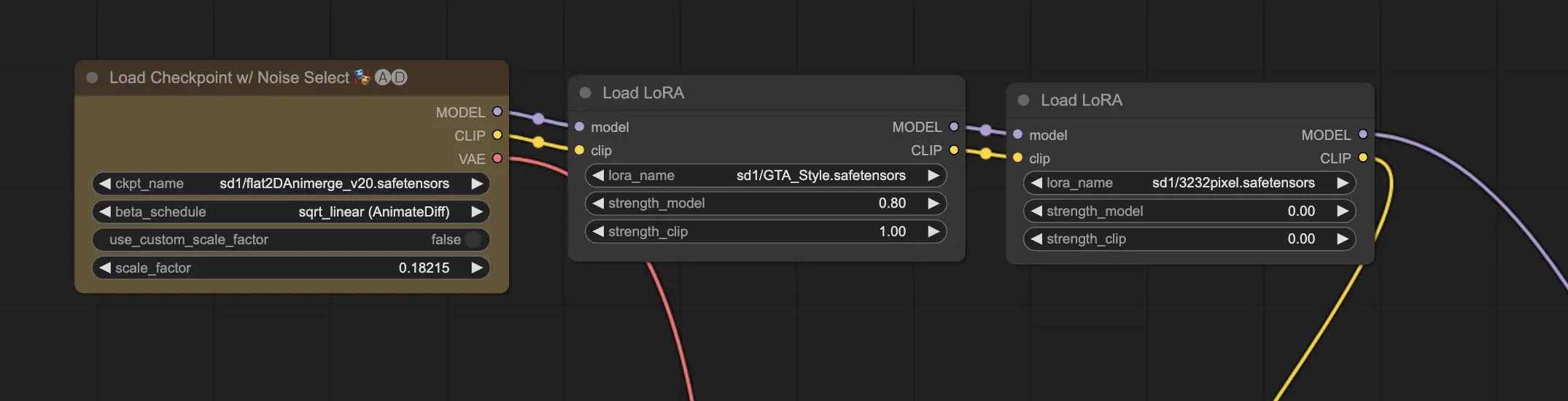
Процесс аналогичен использованию одной LoRA, но вам нужно будет выбрать несколько моделей LoRA вместо одной. ComfyUI применит LoRA последовательно, что означает, что каждая LoRA будет строиться на модификациях, введенных предыдущей.
Это открывает мир возможностей для комбинирования различных стилей, элементов и модификаций в ваших сгенерированных ИИ изображениях. 🌍💡 Экспериментируйте с разными комбинациями LoRA, чтобы достичь уникальных и креативных результатов!
12. Сокращения и трюки для ComfyUI ⌨️🖱️
12.1. Копирование и вставка 📋
- Выберите узел и нажмите Ctrl+C, чтобы скопировать.
- Нажмите Ctrl+V, чтобы вставить.
- Нажмите Ctrl+Shift+V, чтобы вставить с сохранением входных соединений.
12.2. Перемещение нескольких узлов 🖱️
- Создайте группу, чтобы переместить набор узлов вместе.
- Или удерживайте Ctrl и перетаскивайте, чтобы создать рамку для выбора нескольких узлов, или удерживайте Ctrl, чтобы выбрать несколько узлов по отдельности.
- Чтобы переместить выбранные узлы, удерживайте Shift и перемещайте мышь.
12.3. Обход узла 🔇
- Временно отключите узел, отключив его. Выберите узел и нажмите Ctrl+M.
- Для отключения группы узлов нет сочетания клавиш. Выберите Bypass Group Node в меню правой кнопки мыши или отключите первый узел в группе, чтобы отключить её.
12.4. Минимизация узла 🔍
- Нажмите на точку в левом верхнем углу узла, чтобы минимизировать его.
12.5. Генерация изображения ▶️
- Нажмите Ctrl+Enter, чтобы добавить рабочий процесс в очередь и сгенерировать изображения.
12.6. Встроенный рабочий процесс 🖼️
- ComfyUI сохраняет весь рабочий процесс в метаданных файла PNG, который он генерирует. Чтобы загрузить рабочий процесс, перетащите изображение в ComfyUI.
12.7. Фиксация семян для экономии времени ⏰
- ComfyUI повторно запускает узел только в случае изменения входных данных. При работе с длинной цепочкой узлов сэкономьте время, зафиксировав семя, чтобы избежать повторной генерации предыдущих результатов.
13. ComfyUI Online 🚀
Поздравляем с завершением руководства для начинающих по ComfyUI! 🙌 Теперь вы готовы погрузиться в захватывающий мир создания ИИ-искусства. Но зачем мучиться с установкой, если можно начать творить прямо сейчас? 🤔
На RunComfy мы упростили для вас использование ComfyUI онлайн без какой-либо настройки. Наш сервис ComfyUI Online загружен более чем 200 популярными узлами и моделями, а также более чем 50 потрясающими рабочими процессами, чтобы вдохновить ваши творения.
🌟 Независимо от того, являетесь ли вы новичком или опытным AI-художником, RunComfy имеет всё необходимое, чтобы воплотить ваши художественные видения в жизнь. 💡 Не ждите больше — попробуйте ComfyUI Online сейчас и ощутите мощь создания ИИ-искусства у себя под рукой! 🚀