Stable Diffusion 3.5
Stable Diffusion 3.5 (SD3.5) 是一个新的开源模型,可以从文本提示生成多样化、高质量的图像。SD3.5 擅长创建各种风格并遵循提示。尽管在解剖学和分辨率上存在一些局限性,SD3.5 是一个强大的视觉创作工具。在 ComfyUI 中探索 SD3.5,轻松创建令人惊叹的视觉效果。ComfyUI Stable Diffusion 3.5 工作流程
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Stable Diffusion 3.5 示例




ComfyUI Stable Diffusion 3.5 描述
Stability AI 发布了 ,这是一个开源的多模态生成 AI 模型,包含多个变体,如 Stable Diffusion 3.5 (SD3.5) Large、Stable Diffusion 3.5 (SD3.5) Large Turbo 和 Stable Diffusion 3.5 (SD3.5) Medium。这些模型高度可定制,能够在消费者硬件上运行。SD3.5 Large 和 Large Turbo 模型已立即可用,而 Medium 版本将于 2024 年 10 月 29 日发布。
1. Stable Diffusion 3.5 (SD3.5) 的工作原理
在技术层面,Stable Diffusion 3.5 (SD3.5) 将文本提示作为输入,使用基于 transformer 的文本编码器将其编码到潜在空间中,然后使用基于扩散的解码器将该潜在表示解码为输出图像。transformer 文本编码器,如 CLIP (Contrastive Language-Image Pre-training) 模型,将输入提示映射到潜在空间中的语义上有意义的压缩表示。然后,扩散解码器在多个时间步中迭代去噪该潜在代码,以生成最终的图像输出。扩散过程涉及逐步去除初始噪声的潜在表示中的噪声,该过程以文本嵌入为条件,直到出现清晰的图像。
Stable Diffusion 3.5 (SD3.5) 的不同模型尺寸 (Large, Medium) 指的是可训练参数的数量 - Large 模型为 80 亿,Medium 为 25 亿。更多的参数通常允许模型从其训练数据中捕获更多的知识和细微差别。Turbo 模型是经过蒸馏的版本,牺牲了一些质量以换取更快的推理速度。蒸馏涉及训练一个较小的 "student" 模型来模仿较大 "teacher" 模型的输出,旨在以更高效的架构保留大部分能力。
2. Stable Diffusion 3.5 (SD3.5) 模型的优势
2.1. 可定制性
Stable Diffusion 3.5 (SD3.5) 模型设计为易于微调和为特定应用构建。Query-Key Normalization 被集成到 transformer 块中,以稳定训练并简化进一步开发。这种技术对 transformer 层中的注意力分数进行归一化,可以使模型更稳健,更易于通过迁移学习适应新数据集。
2.2. 输出多样性
Stable Diffusion 3.5 (SD3.5) 旨在生成代表世界多样性的图像,而无需大量提示。它可以描绘具有不同肤色、特征和美学的人物。这可能是因为模型在互联网上的大量多样化图像数据集上进行了训练。
2.3. 风格多样性
Stable Diffusion 3.5 (SD3.5) 模型能够生成多种风格的图像,包括 3D 渲染、照片真实感、绘画、线条艺术、动漫等。这种多样性使其适用于许多用例。风格多样性源于扩散模型在其潜在空间中捕获许多不同视觉模式和美学的能力。
2.4. 强大的提示遵循性
特别是对于 Stable Diffusion 3.5 (SD3.5) Large 模型,SD3.5 在生成与输入文本提示语义意义一致的图像方面表现良好。与其他模型相比,它在提示匹配指标上排名较高。这种准确将文本翻译为图像的能力由 transformer 文本编码器的语言理解能力驱动。
3. Stable Diffusion 3.5 (SD3.5) 模型的局限性与缺点
3.1. 在解剖学和物体交互方面的困难
与大多数文本到图像模型一样,Stable Diffusion 3.5 (SD3.5) 在渲染真实的人体解剖学方面仍然存在困难,尤其是在复杂姿势下的手、脚和面部。物体与手之间的交互通常会失真。这可能是因为仅从 2D 图像学习 3D 空间关系和物理的所有细微差别的挑战。
3.2. 分辨率限制
Stable Diffusion 3.5 (SD3.5) Large 模型适合生成 1 兆像素图像(1024x1024),而 Medium 模型最高达到约 2 兆像素。对于 SD3.5 来说,在更高分辨率下生成连贯的图像具有挑战性。这一限制源于扩散架构的计算和内存约束。
3.3. 偶发故障和幻觉
由于 Stable Diffusion 3.5 (SD3.5) 模型允许从相同提示生成多样化的输出,并且不同的随机种子可能导致一些不可预测性。缺乏具体提示可能导致出现故障或意外元素。这是扩散采样过程中固有的属性,该过程中涉及随机性。
3.4. 不完全达到绝对前沿水平
根据一些早期测试,在图像质量和连贯性方面,Stable Diffusion 3.5 (SD3.5) 目前尚未达到像 Midjourney 这样的最先进文本到图像模型的性能。而 Stable Diffusion 3.5 (SD3.5) 和 FLUX.1 的早期比较显示每个模型在不同领域表现出色。虽然 FLUX.1 在生成照片真实感图像方面似乎具有优势,SD3.5 Large 在生成动漫风格作品方面更为擅长,无需额外的微调或修改。
4. ComfyUI 中的 Stable Diffusion 3.5
在 RunComfy,我们已为您预加载了 Stable Diffusion 3.5 (SD3.5) 模型,方便您开始使用。您可以直接进入并使用示例工作流进行推理
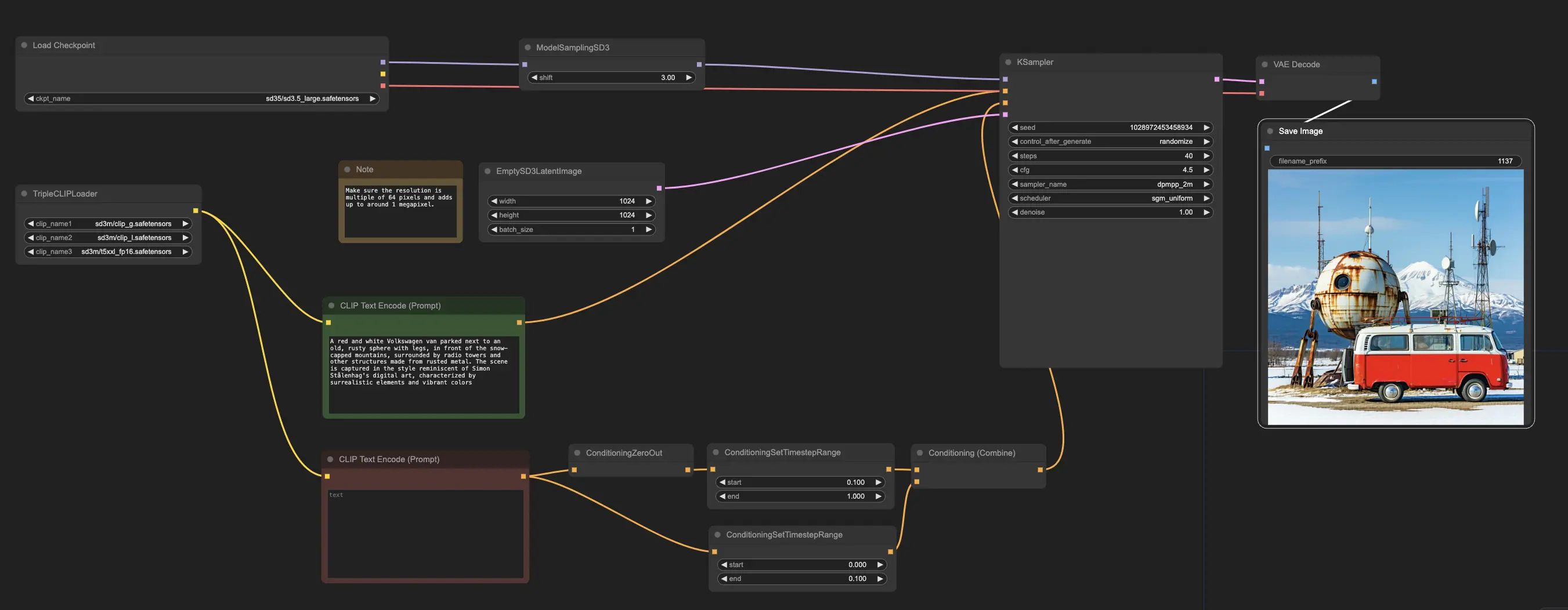
示例工作流从 CheckpointLoaderSimple 节点开始,该节点加载预训练的 Stable Diffusion 3.5 Large 模型。为了帮助将您的文本提示翻译成模型能够理解的格式,TripleCLIPLoader 节点用于加载相应的编码器。这些编码器在指导图像生成过程中基于您提供的文本起着至关重要的作用。
然后,EmptySD3LatentImage 节点创建一个指定尺寸的空白画布,通常为 1024x1024 像素,作为模型生成图像的起点。CLIPTextEncode 节点处理您提供的文本提示,使用加载的编码器创建一组模型遵循的指令。
在将这些指令发送到模型之前,它们通过 ConditioningCombine、ConditioningZeroOut 和 ConditioningSetTimestepRange 节点进行进一步优化。这些节点移除任何负面提示的影响,指定提示在生成过程中应用的时间,并将指令组合成一个单一的、连贯的集合。
最后,您可以使用 ModelSamplingSD3 节点微调图像生成过程,调整采样模式、步骤数和模型输出比例等各种设置。最后,KSampler 节点让您控制步骤数、指令影响力的强度(CFG 比例)和用于生成的特定算法,从而实现所需的结果。


