
The Hallo2 technique was developed by Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, and Jingdong Wang from Fudan University and Baidu Inc. For more information, visit Hallo2 GitHub. ComfyUI_Hallo2 nodes and workflow was developed by smthemex. For more details, visit ComfyUI_Hallo2 GitHub. All credits to their contributions.
1. About Hallo2#
Hallo2 is a cutting-edge model for generating high-quality, long-duration, 4K resolution audio-driven portrait animation videos. It builds upon the original Hallo model with several key improvements:
- Supports generating much longer videos, up to tens of minutes or even hours long
- Generates videos at 4K resolution
- Allows controlling expression and pose using textual prompts in addition to audio
Hallo2 achieves this by using advanced techniques like data augmentation to maintain consistency over long durations, vector quantization of latent codes for 4K resolution, and an improved denoising process guided by both audio and text.
2. Technical Features of Hallo2#
Hallo2 combines several advanced AI models and techniques to create its high-quality portrait videos:
- Diffusion Model: This is the core "engine" that generates the video frames. It starts with random noise and gradually refines it to match the desired output, guided by the audio and text prompts.
- 3D U-Net: This is a type of neural network that acts as the "sculptor" in the diffusion process. It looks at the current noisy frame, the audio, and the text instructions, and suggests how to change the noise to make it look more like the final portrait.
- Audio Encoder: Hallo2 uses a model called Wav2Vec2 as its "ears" to understand the audio, converting the raw waveform into a compact representation that captures tone, speed, and speech content.
- Face Detector: To help it focus on animating the face, Hallo2 uses a face detection model to automatically locate the portrait's face in the reference image. It then knows where to apply the lip and expression movements.
- Image Compressor: To efficiently work with high-res 4K images, Hallo2 uses a special type of autoencoder model (VQ-VAE) to compress them into a smaller "latent" representation, and then decode them back to 4K at the end. This is like how JPEGs shrink image file sizes while preserving quality.
- Augmentation Tricks: To help maintain quality over long videos, Hallo2 applies some clever "data augmentations" to the previous generated frames before using them to influence the next frame. These include occasionally erasing random patches or adding subtle noise. This helps prevent compounding errors that could otherwise build up and ruin the consistency over time.
So in summary - Hallo2 takes in audio and a portrait image, has an AI "agent" that sculpts video frames to match them while staying true to the original portrait, and employs some extra tricks to keep everything synced and coherent even in long videos. All of these parts work together in a multi-step pipeline to produce the impressive results you see.
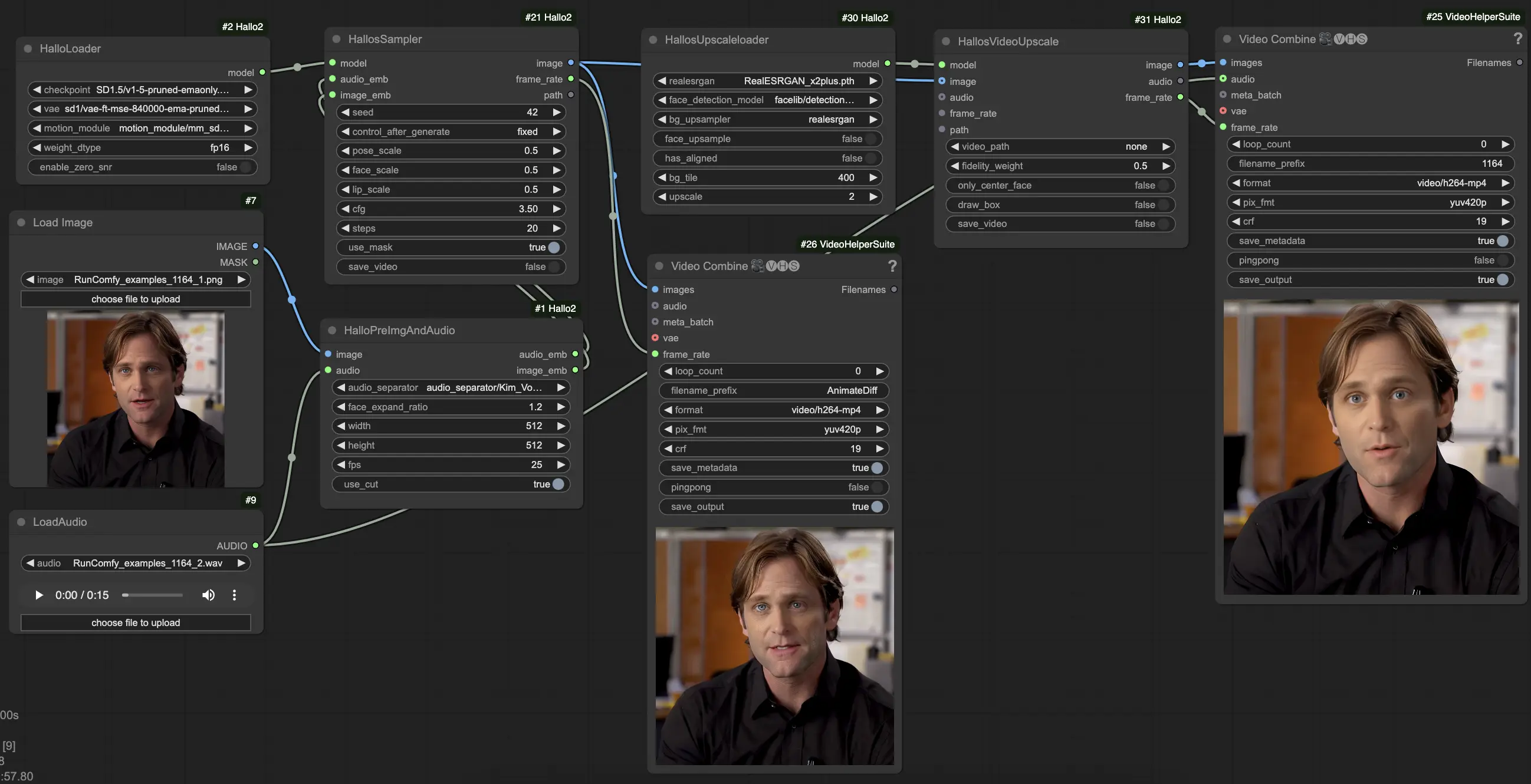
3. How to Use ComfyUI Hallo2 Workflow#
Hallo2 has been integrated into ComfyUI via a custom workflow with several specialized nodes. Here's how to use it:
- Load your reference portrait image using the
LoadImagenode. This should be a clear front-facing portrait. (Tips: The better framed and lit your reference portrait is, the better the results will be. Avoid side profiles, occlusions, busy backgrounds etc.) - Load your driving audio using the
LoadAudionode. It should match the mood you want the portrait to emote. - Connect the image and audio to the
HalloPreImgAndAudionode. This preprocesses the image and audio into embeddings. Key parameters:audio_separator: Model for separating speech from background noise. Generally leave at default.face_expand_ratio: How much to expand the detected face region by. Higher values include more of the hair/background.width/height: Generation resolution. Higher values are slower but more detailed. 512-1024 square is a good balance.fps: Target video FPS. 25 is a good default.
- Load the core Hallo2 model using the
HalloLoadernode. Point it to your Hallo2 checkpoint, VAE, and motion module files. - Connect the preprocessed image and audio embeddings along with the loaded model to the
HalloSamplernode. This performs the actual video generation. Key parameters:seed: Random seed which determines minor details. Change it if you don't like the first result.pose_scale/face_scale/lip_scale: How much to scale the intensity of pose, facial expression, and lip movements. 1.0 = full intensity, 0.0 = frozen.cfg: Classifier-free guidance scale. Higher = follows conditioning more closely but is less diverse.steps: Number of denoising steps. More steps = better quality but slower.
- At this point, you can view the generated video. To further improve quality with super-resolution, add the
HallosUpscaleloaderandHallosVideoUpscalenodes to the end of the chain. The upscale loader reads in a pretrained upscaling model, while the upscaler node actually performs the upscaling to 4K.