AnimateDiff + IPAdapter V1 | Bild zu Video
IPAdapter ist eine leichtgewichtige Lösung, die vortrainierte Modelle mit Bildprompt-Funktionen erweitert. Durch die Verwendung von AnimateDiff zusammen mit IPAdapter können Sie mühelos besser steuerbare Animationen aus Referenzbildern generieren.ComfyUI AnimateDiff IPAdapter Arbeitsablauf
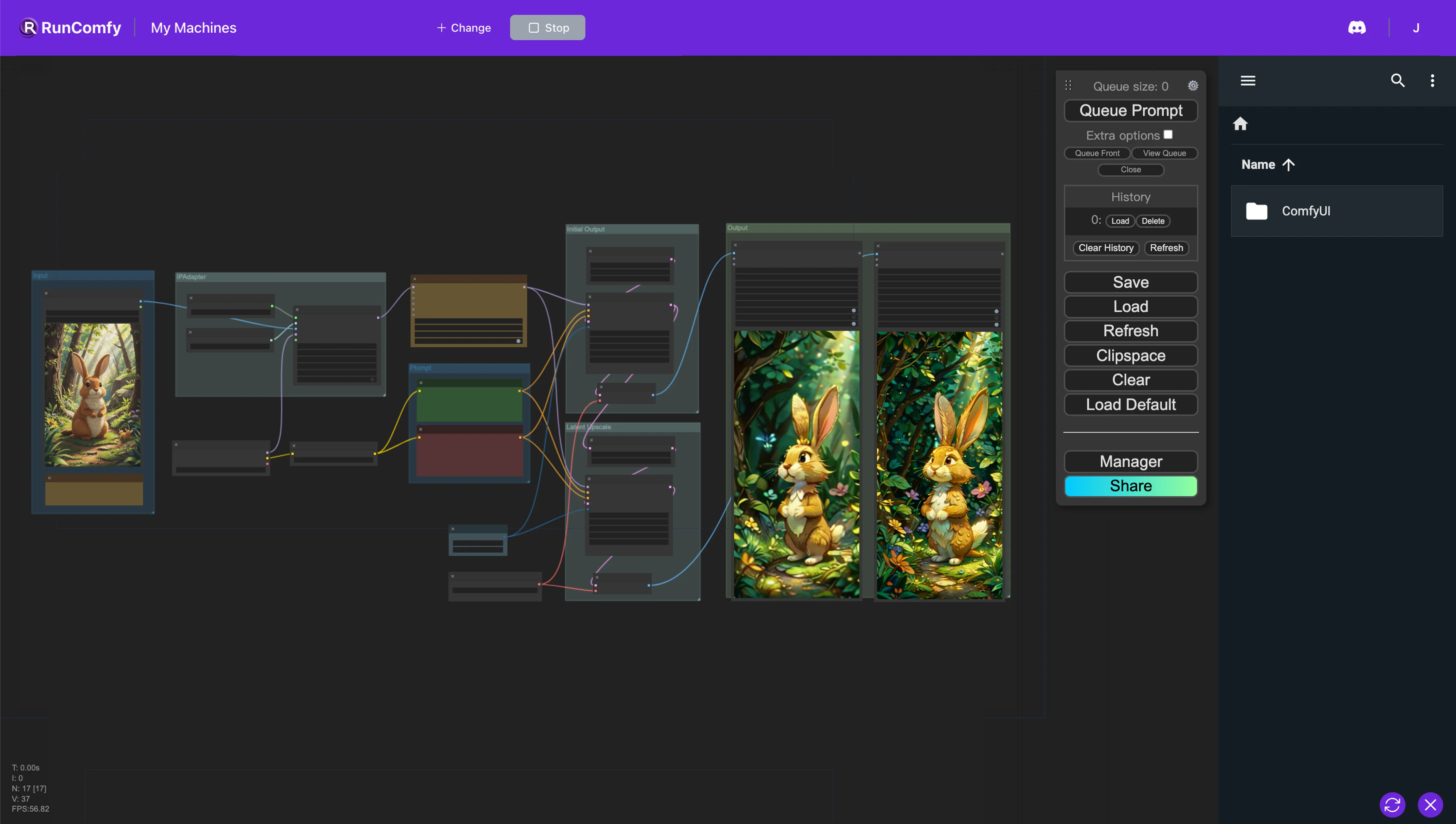
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI AnimateDiff IPAdapter Beispiele
ComfyUI AnimateDiff IPAdapter Beschreibung
1. ComfyUI Workflow: AnimateDiff + IPAdapter | Bild zu Video
Dieser ComfyUI-Workflow wurde für die Erstellung von Animationen aus Referenzbildern unter Verwendung von AnimateDiff und IP-Adapter entwickelt. Der AnimateDiff-Knoten integriert Modell- und Kontextoptionen zur Anpassung der Animationsdynamik. Umgekehrt erleichtert der IP-Adapter-Knoten die Verwendung von Bildern als Prompts in einer Weise, die den Stil, die Komposition oder die Gesichtszüge des Referenzbildes nachahmen kann, was die Anpassung und Qualität der generierten Animationen oder Bilder erheblich verbessert.
2. Übersicht über AnimateDiff
Bitte lesen Sie die Details zu
3. Übersicht über IP-Adapter
3.1. Einführung in IP-Adapter
IP-Adapter steht für "Image Prompt Adapter" und ist ein neuartiger Ansatz zur Verbesserung von Text-zu-Bild-Diffusionsmodellen mit der Fähigkeit, Bildprompts bei der Bildgenerierung zu verwenden. IP-Adapter zielt darauf ab, die Mängel von Textprompts zu beheben, die oft komplexes Prompt Engineering erfordern, um gewünschte Bilder zu erzeugen. Die Einführung von Bildprompts neben Text ermöglicht eine intuitivere und effektivere Möglichkeit, den Bildsyntheseprozess zu steuern.
Verschiedene Modelle von IP-Adapter
Die IP-Adapter-Suite umfasst eine Vielzahl von Modellen, die jeweils auf spezifische Anwendungsfälle und Komplexitätsstufen der Bildsynthese zugeschnitten sind. Hier ist eine Übersicht über die verschiedenen verfügbaren Modelle:
3.1.1. v1.5-Modelle
ip-adapter_sd15: Das Standardmodell für Version 1.5, das die Leistungsfähigkeit von IP-Adapter für die Bild-zu-Bild-Konditionierung und die Erweiterung von Textprompts nutzt.ip-adapter_sd15_light: Eine leichtere Version des Standardmodells, optimiert für weniger ressourcenintensive Anwendungen, die dennoch IP-Adapter-Technologie nutzen.ip-adapter-plus_sd15: Ein erweitertes Modell, das Bilder erzeugt, die enger an das ursprüngliche Referenzbild angelehnt sind und die Details verbessern.ip-adapter-plus-face_sd15: Ähnlich wie IP-Adapter Plus, mit einem Fokus auf eine genauere Nachbildung der Gesichtszüge in den generierten Bildern.ip-adapter-full-face_sd15: Ein Modell, das die Details des gesamten Gesichts betont und wahrscheinlich einen "Face Swap"-Effekt mit hoher Wiedergabetreue bietet.ip-adapter_sd15_vit-G: Eine Variante des Standardmodells, die den Vision Transformer (ViT) BigG-Bildcodierer für eine detailliertere Extraktion von Bildmerkmalen verwendet.
3.1.2. SDXL-Modelle
ip-adapter_sdxl: Das Basismodell für SDXL, das für die Verarbeitung größerer und komplexerer Bildprompts ausgelegt ist.ip-adapter_sdxl_vit-h: Das SDXL-Modell in Kombination mit dem ViT H-Bildcodierer, das Leistung und Recheneffizienz ausbalanciert.ip-adapter-plus_sdxl_vit-h: Eine fortschrittliche Version des SDXL-Modells mit verbesserter Bildprompt-Detailtreue und -Qualität.ip-adapter-plus-face_sdxl_vit-h: Eine SDXL-Variante, die sich auf Gesichtsdetails konzentriert und ideal für Projekte ist, bei denen die Genauigkeit der Gesichtszüge von größter Bedeutung ist.
3.1.3. FaceID-Modelle
FaceID: Ein Modell, das InsightFace verwendet, um Face-ID-Embeddings zu extrahieren, und einen einzigartigen Ansatz für die gesichtsbezogene Bildgenerierung bietet.FaceID Plus: Eine verbesserte Version des FaceID-Modells, die InsightFace für Gesichtsmerkmale und CLIP-Bildcodierung für globale Gesichtsmerkmale kombiniert.FaceID Plus v2: Eine Iteration von FaceID Plus mit einem verbesserten Modell-Checkpoint und der Möglichkeit, ein Gewicht auf das CLIP-Bildembedding zu setzen.FaceID Portrait: Ein Modell, das FaceID ähnelt, aber dafür ausgelegt ist, mehrere Bilder von zugeschnittenen Gesichtern für eine vielfältigere Gesichtskonditionierung zu akzeptieren.
3.1.4. SDXL FaceID-Modelle
FaceID SDXL: Die SDXL-Version von FaceID, die dasselbe InsightFace-Modell wie v1.5 beibehält, aber für SDXL-Anwendungen skaliert ist.FaceID Plus v2 SDXL: Eine SDXL-Anpassung von FaceID Plus v2 für hochauflösende Bildgenerierung mit verbesserter Wiedergabetreue.
3.2. Hauptmerkmale von IP-Adapter
3.2.1. Integration von Text- und Bildprompts: Die einzigartige Fähigkeit des IP-Adapters, sowohl Text- als auch Bildprompts zu verwenden, ermöglicht eine multimodale Bildgenerierung und bietet ein vielseitiges und leistungsstarkes Werkzeug zur Steuerung der Ausgaben von Diffusionsmodellen.
3.2.2. Entkoppelter Kreuzaufmerksamkeitsmechanismus: Der IP-Adapter verwendet eine entkoppelte Kreuzaufmerksamkeitsstrategie, die die Effizienz des Modells bei der Verarbeitung verschiedener Modalitäten verbessert, indem Text- und Bildmerkmale getrennt werden.
3.2.3. Leichtgewichtiges Modell: Trotz seiner umfassenden Funktionalität behält der IP-Adapter eine relativ geringe Parameteranzahl (22 Millionen) bei und bietet eine Leistung, die mit der von feinabgestimmten Bildprompt-Modellen vergleichbar ist oder diese übertrifft.
3.2.4. Kompatibilität und Generalisierung: Der IP-Adapter ist für eine breite Kompatibilität mit bestehenden kontrollierbaren Werkzeugen ausgelegt und kann auf benutzerdefinierte Modelle angewendet werden, die vom selben Basismodell abgeleitet sind, um die Generalisierung zu verbessern.
3.2.5. Strukturkontrolle: IP-Adapter unterstützt eine detaillierte Strukturkontrolle, die es Erstellern ermöglicht, den Bildgenerierungsprozess mit größerer Präzision zu steuern.
3.2.6. Bild-zu-Bild- und Inpainting-Fähigkeiten: Mit Unterstützung für bildgeführte Bild-zu-Bild-Übersetzung und Inpainting erweitert der IP-Adapter den Umfang möglicher Anwendungen und ermöglicht kreative und praktische Verwendungen in einer Vielzahl von Bildsynthese-Aufgaben.
3.2.7. Anpassung mit verschiedenen Encodern: Der IP-Adapter ermöglicht die Verwendung verschiedener Encoder, wie OpenClip ViT H 14 und ViT BigG 14, zur Verarbeitung von Referenzbildern. Diese Flexibilität erleichtert die Handhabung verschiedener Bildauflösungen und -komplexitäten, was ihn zu einem vielseitigen Werkzeug für Ersteller macht, die den Bildgenerierungsprozess an spezifische Anforderungen oder gewünschte Ergebnisse anpassen möchten.
Die Einbeziehung der IP-Adapter-Technologie in Bildgenerierungsprojekte vereinfacht nicht nur die Erstellung komplexer und detaillierter Bilder, sondern verbessert auch erheblich die Qualität und Wiedergabetreue der generierten Bilder im Vergleich zu den ursprünglichen Prompts. Durch die Überbrückung der Lücke zwischen Text- und Bildprompts bietet IP-Adapter einen leistungsstarken, intuitiven und effizienten Ansatz zur Steuerung der Feinheiten der Bildsynthese, was ihn zu einem unverzichtbaren Werkzeug im Arsenal digitaler Künstler, Designer und Ersteller macht, die innerhalb des ComfyUI-Workflows oder in jedem anderen Kontext arbeiten, der qualitativ hochwertige, maßgeschneiderte Bildgenerierung erfordert.
