
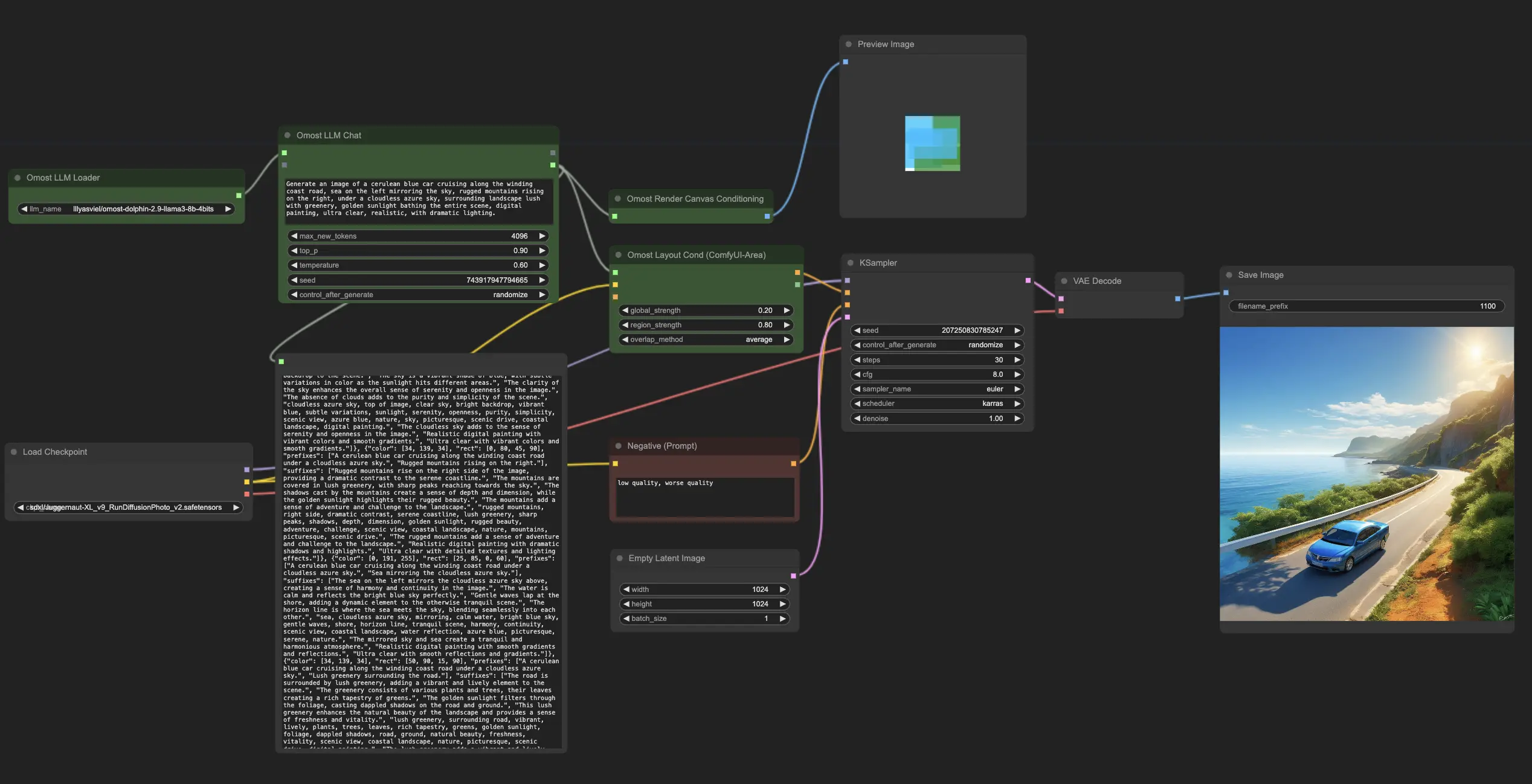

1. Was ist Omost?#
Omost, kurz für "Ihr Bild ist fast fertig!", ist ein innovatives Projekt, das die Codierungsfähigkeiten von Large Language Models (LLM) in die Bilderzeugung bzw. genauer gesagt in die Bildkompositionsfähigkeiten umwandelt. Der Name "Omost" hat eine doppelte Bedeutung: Er impliziert, dass jedes Mal, wenn Sie Omost verwenden, Ihr Bild fast fertig ist, und er bedeutet auch "omni" (multimodal) und "most" (das Beste daraus machen).
Omost bietet vortrainierte LLM-Modelle, die Code generieren, um visuelle Bildinhalte mit dem virtuellen Canvas-Agent von Omost zu komponieren. Diese Leinwand kann dann von spezifischen Implementierungen von Bildgeneratoren gerendert werden, um die endgültigen Bilder zu erstellen. Omost ist darauf ausgelegt, den Prozess der Bilderzeugung zu vereinfachen und zu verbessern, sodass er für AI-Künstler zugänglich und effizient ist.
2. Wie Omost funktioniert#
2.1. Leinwand und Beschreibungen#
Omost verwendet eine virtuelle Leinwand, auf der Elemente des Bildes beschrieben und positioniert werden. Die Leinwand ist in ein Raster von 9x9=81 Positionen unterteilt, was eine präzise Platzierung der Elemente ermöglicht. Diese Positionen werden weiter in Begrenzungsrahmen verfeinert, sodass 729 verschiedene mögliche Standorte für jedes Element zur Verfügung stehen. Dieser strukturierte Ansatz stellt sicher, dass Elemente genau und konsistent platziert werden.
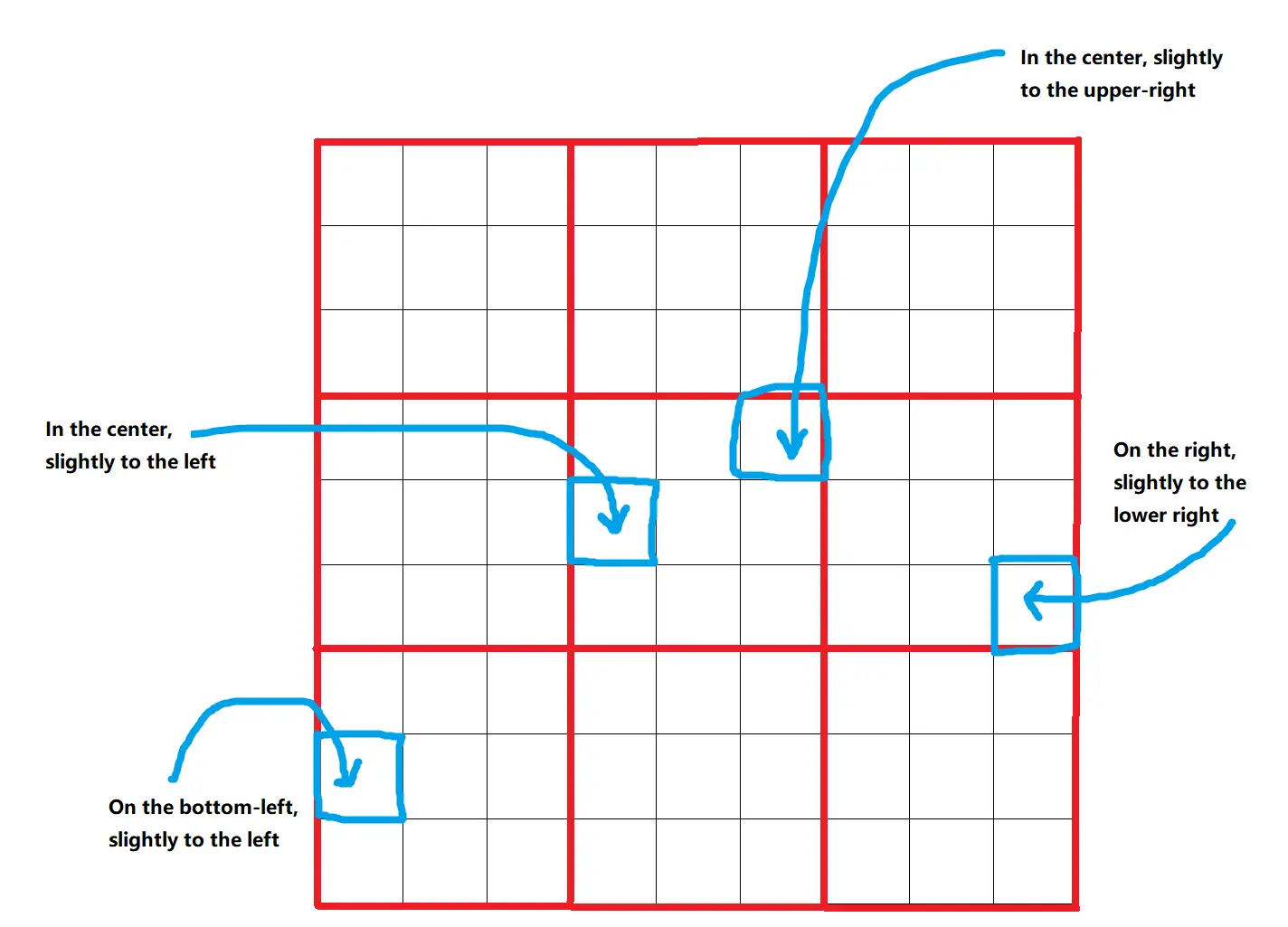
2.2. Tiefe und Farbe#
Elemente auf der Leinwand werden mit einem distance_to_viewer Parameter versehen, der sie in Hintergrund-zu-Vordergrund-Schichten sortiert. Dieser Parameter dient als relativer Tiefenindikator und stellt sicher, dass näher gelegene Elemente vor weiter entfernten erscheinen. Zusätzlich liefert der Parameter HTML_web_color_name eine grobe Farbrepräsentation für die anfängliche Darstellung, die mit Diffusionsmodellen verfeinert werden kann. Diese anfängliche Farbe hilft, die Komposition vor der Feinabstimmung zu visualisieren.

2.3. Prompt-Engineering#
Omost verwendet Sub-Prompts, die kurze, eigenständige Beschreibungen von Elementen sind, um detaillierte und kohärente Bildkompositionen zu erzeugen. Jeder Sub-Prompt hat weniger als 75 Tokens und beschreibt ein Element unabhängig. Diese Sub-Prompts werden zu vollständigen Prompts für das LLM zusammengeführt, wodurch sichergestellt wird, dass die erzeugten Bilder genau und semantisch reichhaltig sind. Diese Methode stellt sicher, dass die Textkodierung effizient ist und semantische Kürzungsfehler vermieden werden.
2.4. Regional Prompter#
Omost implementiert fortschrittliche Techniken zur Manipulation der Aufmerksamkeit, um regionale Prompts zu handhaben, sodass jeder Teil des Bildes genau nach den gegebenen Beschreibungen erzeugt wird. Techniken wie die Manipulation der Aufmerksamkeitswerte stellen sicher, dass die Aktivierungen innerhalb maskierter Bereiche gefördert und außerhalb entmutigt werden. Diese präzise Kontrolle über die Aufmerksamkeit führt zu hochwertigen, regionsspezifischen Bildgenerierungen.
3. Detaillierte Erklärung der ComfyUI Omost-Knoten#
3.1. Omost LLM Loader Node#
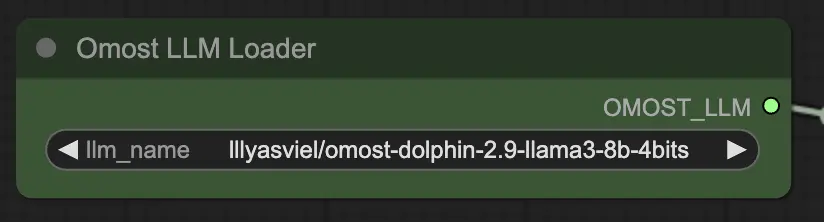
Eingabeparameter des Omost LLM Loader Node#
llm_name: Der Name des vortrainierten LLM-Modells, das geladen werden soll. Verfügbare Optionen umfassen:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
Dieser Parameter gibt an, welches Modell geladen werden soll, wobei jedes unterschiedliche Fähigkeiten und Optimierungen bietet.
Ausgabeparameter des Omost LLM Loader Node#
OMOST_LLM: Das geladene LLM-Modell.
Diese Ausgabe liefert das geladene LLM, bereit, um Bildbeschreibungen und Kompositionen zu erzeugen.
3.2. Omost LLM Chat Node#
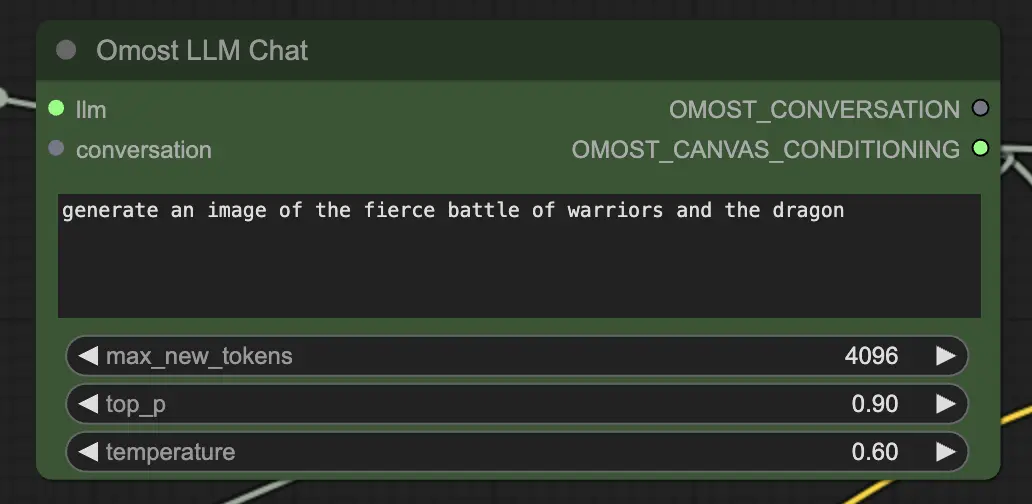
Eingabeparameter des Omost LLM Chat Node#
llm: Das vomOmostLLMLoadergeladene LLM-Modell.text: Der Text-Prompt, um ein Bild zu erzeugen. Dies ist der Haupteingang, in dem Sie die Szene oder Elemente beschreiben, die Sie erzeugen möchten.max_new_tokens: Maximale Anzahl neuer Tokens, die erzeugt werden sollen. Dies steuert die Länge des erzeugten Textes, wobei eine höhere Zahl detailliertere Beschreibungen ermöglicht.top_p: Steuert die Vielfalt des erzeugten Outputs. Ein Wert näher an 1,0 umfasst mehr diverse Möglichkeiten, während ein niedrigerer Wert sich auf die wahrscheinlichsten Ergebnisse konzentriert.temperature: Steuert die Zufälligkeit des erzeugten Outputs. Höhere Werte führen zu zufälligeren Outputs, während niedrigere Werte den Output deterministischer machen.conversation(Optional): Vorheriger Gesprächskontext. Dies ermöglicht es dem Modell, von vorherigen Interaktionen fortzufahren und den Kontext und die Kohärenz beizubehalten.
Ausgabeparameter des Omost LLM Chat Node#
OMOST_CONVERSATION: Der Gesprächsverlauf, einschließlich der neuen Antwort. Dies hilft, den Dialog zu verfolgen und den Kontext über mehrere Interaktionen hinweg zu erhalten.OMOST_CANVAS_CONDITIONING: Die erzeugten Canvas-Konditionierungsparameter zur Darstellung. Diese Parameter definieren, wie die Elemente auf der Leinwand platziert und beschrieben werden.
3.3. Omost Render Canvas Conditioning Node#
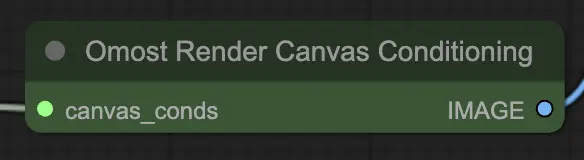
Eingabeparameter des Omost Render Canvas Conditioning Node#
canvas_conds: Die Canvas-Konditionierungsparameter. Diese Parameter umfassen detaillierte Beschreibungen und Positionen der Elemente auf der Leinwand.
Ausgabeparameter des Omost Render Canvas Conditioning Node#
IMAGE: Das gerenderte Bild basierend auf den Canvas-Konditionierungen. Diese Ausgabe ist die visuelle Darstellung der beschriebenen Szene, erzeugt aus den Konditionierungsparametern.
3.4. Omost Layout Cond Node#
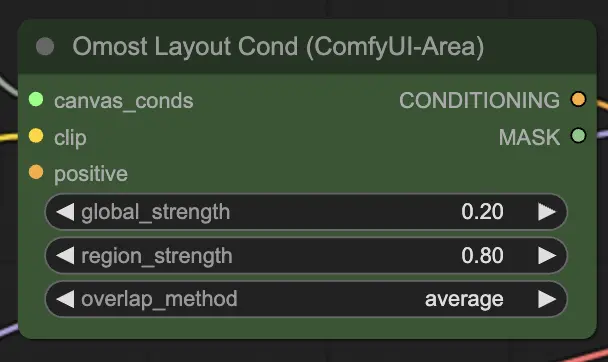
Eingabeparameter des Omost Layout Cond Node#
canvas_conds: Die Canvas-Konditionierungsparameter.clip: Das CLIP-Modell zur Textkodierung. Dieses Modell kodiert die Textbeschreibungen in Vektoren, die vom Bildgenerator verwendet werden können.global_strength: Die Stärke der globalen Konditionierung. Dies steuert, wie stark die Gesamtbeschreibung das Bild beeinflusst.region_strength: Die Stärke der regionalen Konditionierung. Dies steuert, wie stark die spezifischen regionalen Beschreibungen ihre jeweiligen Bereiche beeinflussen.overlap_method: Die Methode zur Handhabung überlappender Bereiche (z.B.overlay,average). Dies definiert, wie überlappende Bereiche im Bild gemischt werden.positive(Optional): Zusätzliche positive Konditionierung. Dies kann zusätzliche Prompts oder Bedingungen umfassen, um spezifische Aspekte des Bildes zu verbessern.
Ausgabeparameter des Omost Layout Cond Node#
CONDITIONING: Die Konditionierungsparameter zur Bilderzeugung. Diese Parameter leiten den Bilderzeugungsprozess und stellen sicher, dass das Ergebnis der beschriebenen Szene entspricht.MASK: Die Maske, die für die Konditionierung verwendet wird. Diese hilft bei der Fehlersuche und der Anwendung zusätzlicher Bedingungen auf spezifische Bereiche.
3.5. Omost Load Canvas Conditioning Node#
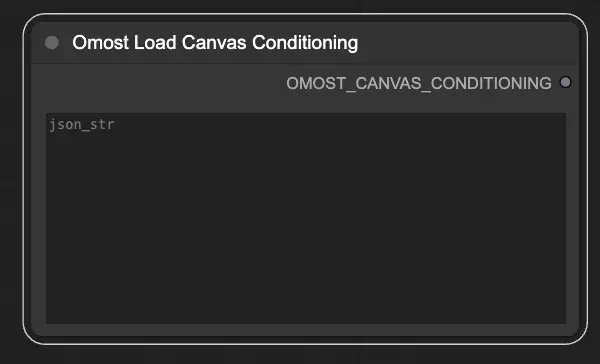
Eingabeparameter des Omost Load Canvas Conditioning Node#
json_str: Der JSON-String, der die Canvas-Konditionierungsparameter darstellt. Dies ermöglicht das Laden vordefinierter Konditionen aus einer JSON-Datei.
Ausgabeparameter des Omost Load Canvas Conditioning Node#
OMOST_CANVAS_CONDITIONING: Die geladenen Canvas-Konditionierungsparameter. Diese Parameter initialisieren die Leinwand mit spezifischen Konditionen und sind bereit für die Bilderzeugung.


