LayerDiffuse | Text zu transparentem Bild
Das LayerDiffuse-Modell führt einen neuartigen Ansatz zur Bildmanipulation ein, der die direkte Erstellung transparenter Bilder ermöglicht. In diesem ComfyUI LayerDiffuse-Workflow sind drei spezialisierte Sub-Workflows integriert: die Erstellung transparenter Bilder, die Generierung des Hintergrunds aus dem Vordergrund und der umgekehrte Prozess der Erstellung des Vordergrunds basierend auf dem vorhandenen Hintergrund.ComfyUI LayerDiffuse Arbeitsablauf

- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI LayerDiffuse Beispiele

ComfyUI LayerDiffuse Beschreibung
1. Übersicht über den ComfyUI LayerDiffuse-Workflow
Der ComfyUI LayerDiffuse-Workflow integriert drei spezialisierte Sub-Workflows: die Erstellung transparenter Bilder, die Generierung des Hintergrunds aus dem Vordergrund und den umgekehrten Prozess der Generierung des Vordergrunds basierend auf dem vorhandenen Hintergrund. Jeder dieser LayerDiffuse-Sub-Workflows arbeitet unabhängig voneinander und bietet Ihnen die Flexibilität, die spezifische LayerDiffuse-Funktionalität auszuwählen und zu aktivieren, die Ihren kreativen Anforderungen entspricht.
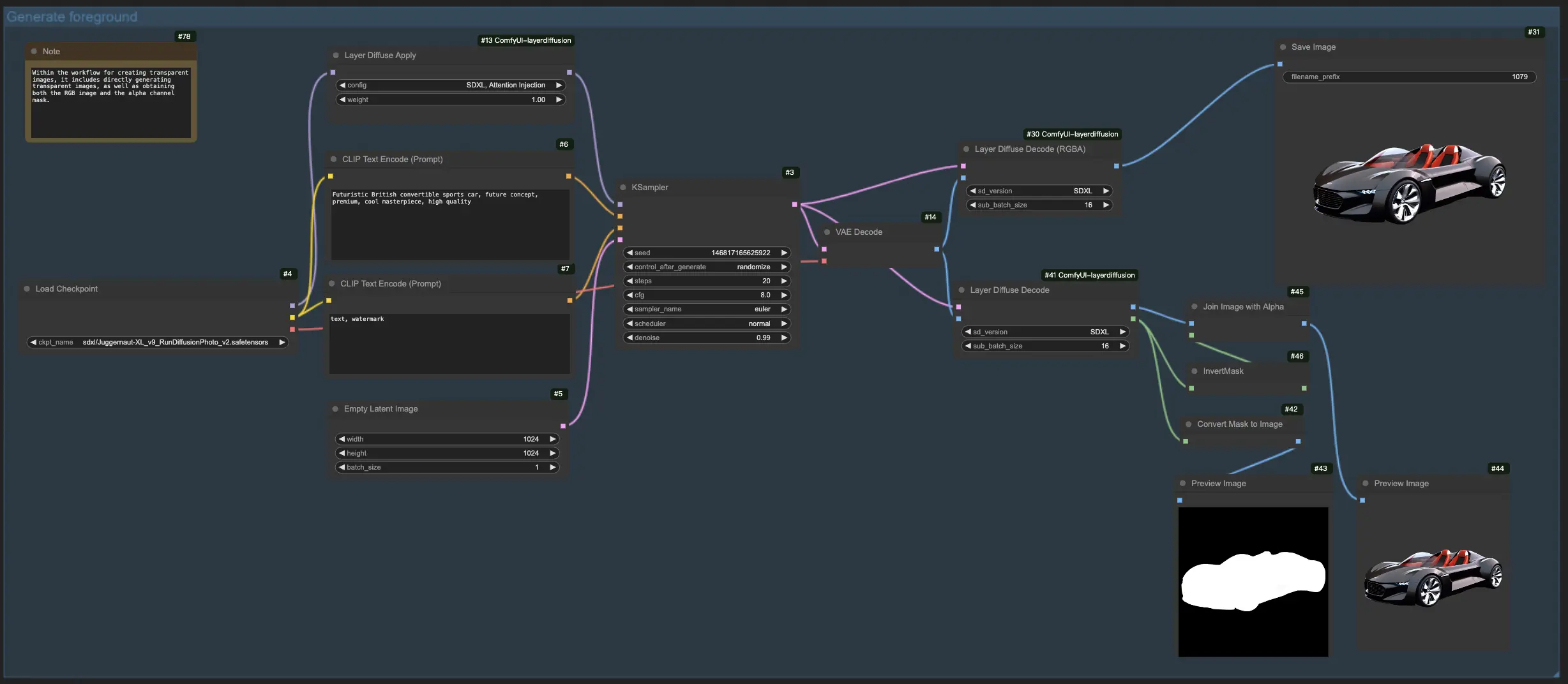
1.1. Erstellung transparenter Bilder mit LayerDiffuse:
Dieser Workflow ermöglicht die direkte Erstellung transparenter Bilder und bietet Ihnen die Flexibilität, Bilder mit oder ohne Angabe der Alpha-Kanal-Maske zu generieren.
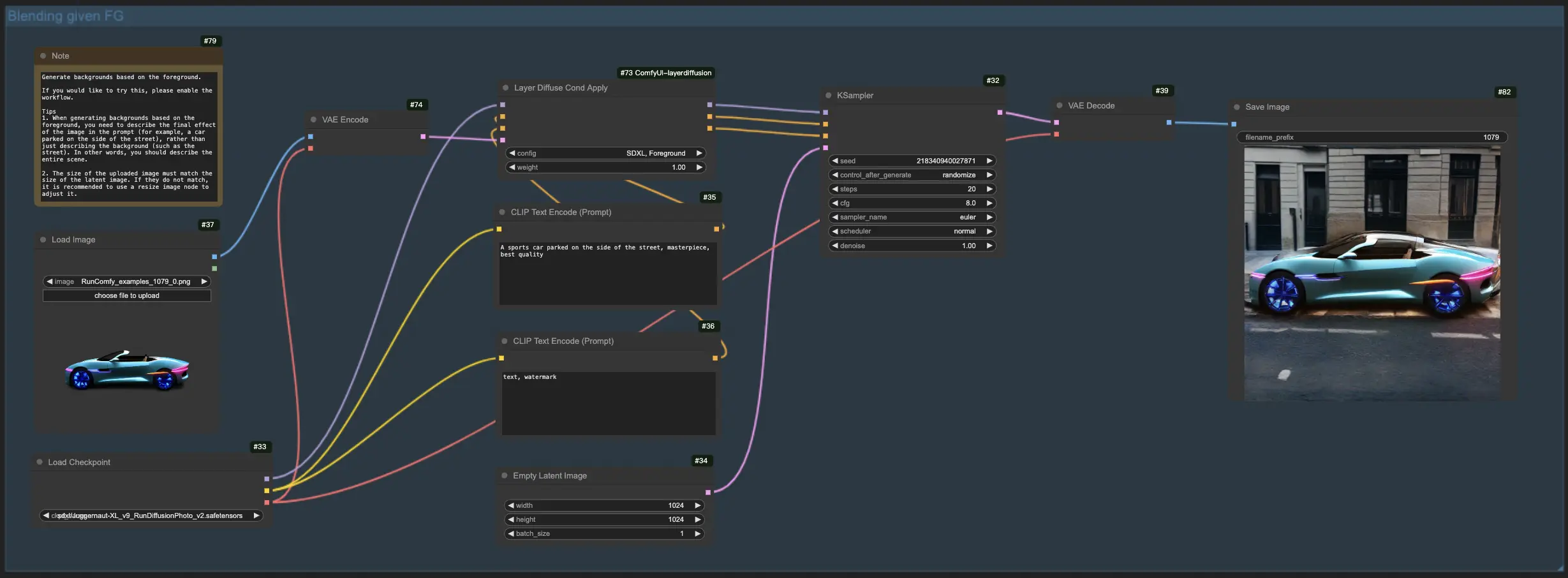
1.2. Generierung des Hintergrunds aus dem Vordergrund mit LayerDiffuse:
Laden Sie für diesen LayerDiffuse-Workflow zunächst Ihr Vordergrundbild hoch und erstellen Sie einen beschreibenden Prompt. LayerDiffuse kombiniert dann diese Elemente, um das gewünschte Bild zu erzeugen. Beim Erstellen Ihres Prompts für LayerDiffuse ist es entscheidend, die gesamte Szene zu beschreiben (z. B. "ein am Straßenrand geparktes Auto") anstatt nur das Hintergrundelement zu beschreiben (z. B. "die Straße").
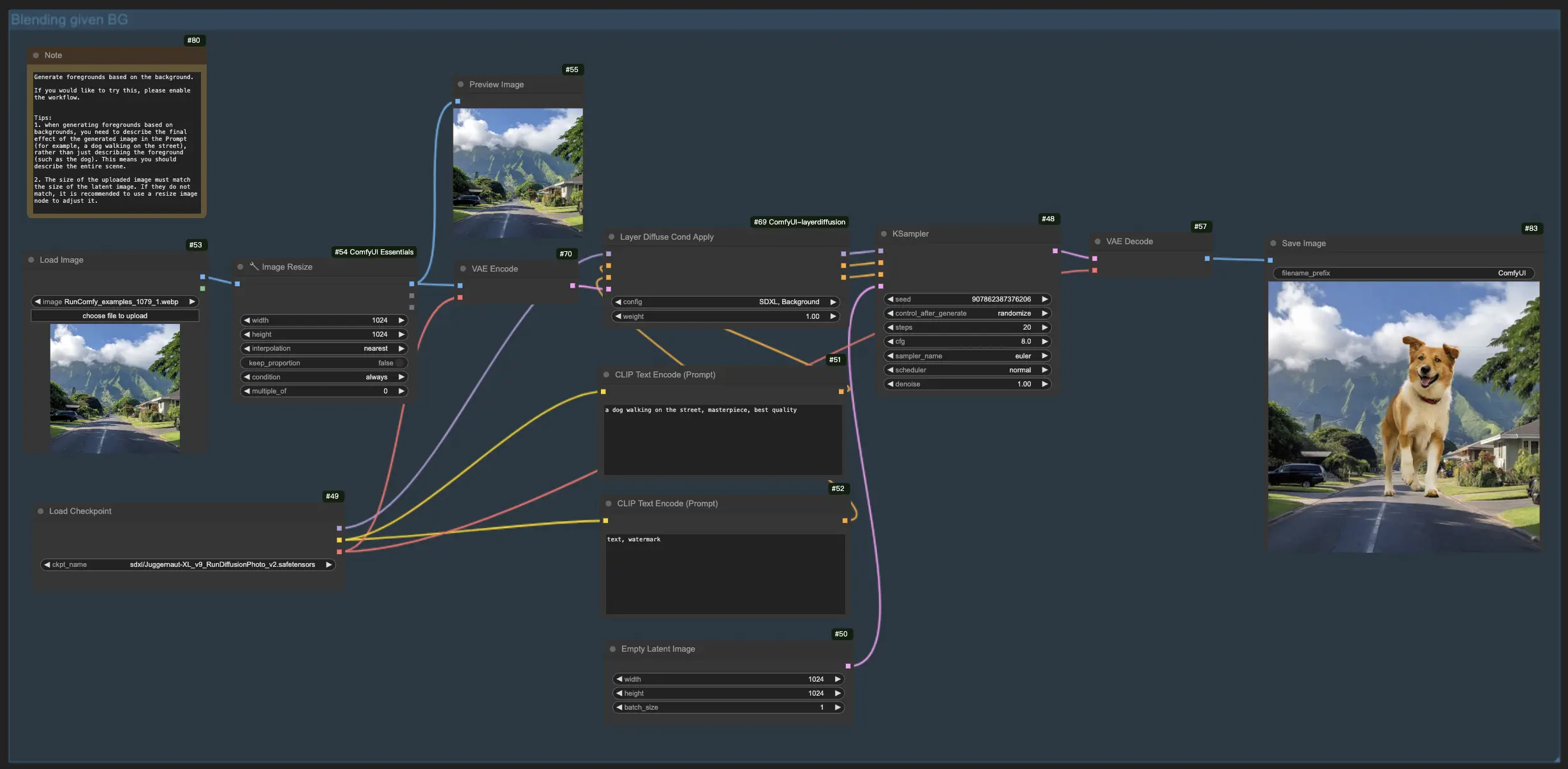
1.3. Generierung des Vordergrunds basierend auf dem Hintergrund:
Diese LayerDiffuse-Funktionalität spiegelt den vorherigen Workflow wider und kehrt den Fokus um, mit dem Ziel, Vordergrundelemente mit einem vorhandenen Hintergrund zu verschmelzen. Daher müssen Sie das Hintergrundbild hochladen und das geplante Endbild in Ihrem Prompt beschreiben, wobei Sie die gesamte Szene (z. B. "ein Hund, der auf der Straße spazieren geht") gegenüber einzelnen Elementen (z. B. "der Hund") betonen.
Weitere LayerDiffuse-Workflows finden Sie auf
2. Wirksamkeit des LayerDiffuse-Workflows
Während der Prozess der Erstellung transparenter Bilder robust ist und zuverlässig hochwertige Ergebnisse liefert, sind die Workflows zum Mischen von Hintergründen und Vordergründen eher experimentell. Sie erreichen möglicherweise nicht immer eine perfekte Mischung, was auf die innovative, aber sich entwickelnde Natur dieser Technologie hinweist.
3. Technische Einführung in LayerDiffuse
LayerDiffuse ist ein innovativer Ansatz, der es großen vortrainierten latenten Diffusionsmodellen ermöglichen soll, Bilder mit Transparenz zu generieren. Diese Technik führt das Konzept der "latenten Transparenz" ein, bei dem die Transparenz des Alphakanals direkt in die latente Mannigfaltigkeit bestehender Modelle eincodiert wird. Dies ermöglicht die Erstellung transparenter Bilder oder mehrerer transparenter Ebenen, ohne die ursprüngliche latente Verteilung des vortrainierten Modells wesentlich zu verändern. Ziel ist es, die hohe Ausgabequalität dieser Modelle beizubehalten und gleichzeitig die Fähigkeit zur Erzeugung von Bildern mit Transparenz hinzuzufügen.
Um dies zu erreichen, verfeinert LayerDiffuse vortrainierte latente Diffusionsmodelle, indem es deren latenten Raum anpasst, um Transparenz als latenten Offset einzubeziehen. Dieser Prozess beinhaltet minimale Änderungen am Modell und bewahrt dessen ursprüngliche Qualitäten und Leistung. Das Training von LayerDiffuse nutzt einen Datensatz von 1 Million transparenten Bildebenenpaaren, die durch ein Human-in-the-Loop-Schema gesammelt wurden, um eine große Vielfalt an Transparenzeffekten zu gewährleisten.
Es hat sich gezeigt, dass die Methode an verschiedene Open-Source-Bildgeneratoren anpassbar ist und in verschiedene Systeme zur bedingten Steuerung integriert werden kann. Diese Vielseitigkeit ermöglicht eine Reihe von Anwendungen, wie z. B. die Erzeugung von Bildern mit vordergrund-/hintergrundspezifischer Transparenz, die Erstellung von Ebenen mit gemeinsamen Generierungsfähigkeiten und die Steuerung des strukturellen Inhalts der Ebenen.







