Hallo2 | Lip-Sync-Porträtanimation
Hallo2 ist ein fortschrittliches KI-Modell, das hochwertige, lip-synchrone Porträtanimationen basierend auf Audioeingaben erzeugt. Durch den Einsatz von Techniken wie Diffusionsmodellen, Audio-Codierung und Gesichtserkennung erstellt Hallo2 4K-Animationen mit präzise synchronisierten Mundbewegungen und Ausdrücken. Nahtlos in das ComfyUI-Framework integriert, ermöglicht Hallo2 Benutzern die Erstellung lebensechter, lip-synchroner Porträtanimationen.ComfyUI Hallo2 Lip-Sync Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Hallo2 Lip-Sync Beispiele
ComfyUI Hallo2 Lip-Sync Beschreibung
Die Hallo2-Technik wurde von Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu und Jingdong Wang von der Fudan University und Baidu Inc. entwickelt. Für weitere Informationen besuchen Sie . Die ComfyUI_Hallo2-Knoten und der Workflow wurden von smthemex entwickelt. Für weitere Details besuchen Sie . Alle Anerkennungen für ihre Beiträge.
1. Über Hallo2
Hallo2 ist ein hochmodernes Modell zur Erstellung hochwertiger, langdauernder, 4K-Auflösung audiogesteuerter Porträtanimationsvideos. Es baut auf dem ursprünglichen Hallo-Modell auf und bietet mehrere wichtige Verbesserungen:
- Unterstützt die Erstellung von viel längeren Videos, bis zu Dutzenden von Minuten oder sogar Stunden
- Erzeugt Videos in 4K-Auflösung
- Ermöglicht die Steuerung von Ausdruck und Pose mit Hilfe von Textaufforderungen zusätzlich zu Audio
Hallo2 erreicht dies durch den Einsatz fortschrittlicher Techniken wie Datenaugmentation zur Konsistenzwahrung über lange Zeiträume, Vektorisierung latenter Codes für 4K-Auflösung und einen verbesserten Denoising-Prozess, der sowohl durch Audio als auch Text geführt wird.
2. Technische Merkmale von Hallo2
Hallo2 kombiniert mehrere fortschrittliche KI-Modelle und Techniken, um seine hochwertigen Porträtvideos zu erstellen:
- Diffusionsmodell: Dies ist der Kern-"Motor", der die Videoframes erzeugt. Es beginnt mit zufälligem Rauschen und verfeinert es allmählich, um das gewünschte Ergebnis zu erreichen, geleitet durch die Audio- und Textaufforderungen.
- 3D U-Net: Dies ist eine Art neuronales Netzwerk, das als "Bildhauer" im Diffusionsprozess fungiert. Es betrachtet das aktuelle rauschende Frame, das Audio und die Textanweisungen und schlägt vor, wie das Rauschen verändert werden soll, um mehr wie das endgültige Porträt auszusehen.
- Audio-Encoder: Hallo2 verwendet ein Modell namens Wav2Vec2 als seine "Ohren", um das Audio zu verstehen und die rohe Wellenform in eine kompakte Darstellung umzuwandeln, die Ton, Geschwindigkeit und Sprachinhalt erfasst.
- Gesichtserkennung: Um sich auf die Animation des Gesichts zu konzentrieren, verwendet Hallo2 ein Gesichtserkennungsmodell, um das Gesicht des Porträts im Referenzbild automatisch zu lokalisieren. Es weiß dann, wo die Lippen- und Ausdrucksbewegungen angewendet werden müssen.
- Bildkompressor: Um effizient mit hochauflösenden 4K-Bildern zu arbeiten, verwendet Hallo2 eine spezielle Art von Autoencoder-Modell (VQ-VAE), um sie in eine kleinere "latente" Darstellung zu komprimieren und sie am Ende wieder in 4K zu decodieren. Dies ist vergleichbar damit, wie JPEGs die Dateigröße von Bildern verkleinern, während die Qualität erhalten bleibt.
- Augmentierungstricks: Um die Qualität über lange Videos hinweg zu erhalten, wendet Hallo2 einige clevere "Datenaugmentierungen" auf die zuvor generierten Frames an, bevor sie zur Beeinflussung des nächsten Frames verwendet werden. Dazu gehört gelegentliches Löschen zufälliger Bereiche oder das Hinzufügen subtilen Rauschens. Dies hilft, kumulative Fehler zu verhindern, die sich sonst aufbauen und die Konsistenz im Laufe der Zeit ruinieren könnten.
Zusammengefasst - Hallo2 nimmt Audio und ein Porträtbild auf, hat einen KI-"Agenten", der Videoframes formt, um sie anzupassen, während es dem ursprünglichen Porträt treu bleibt und einige zusätzliche Tricks anwendet, um alles synchron und kohärent zu halten, selbst in langen Videos. Alle diese Teile arbeiten zusammen in einer mehrstufigen Pipeline, um die beeindruckenden Ergebnisse zu erzielen, die Sie sehen.
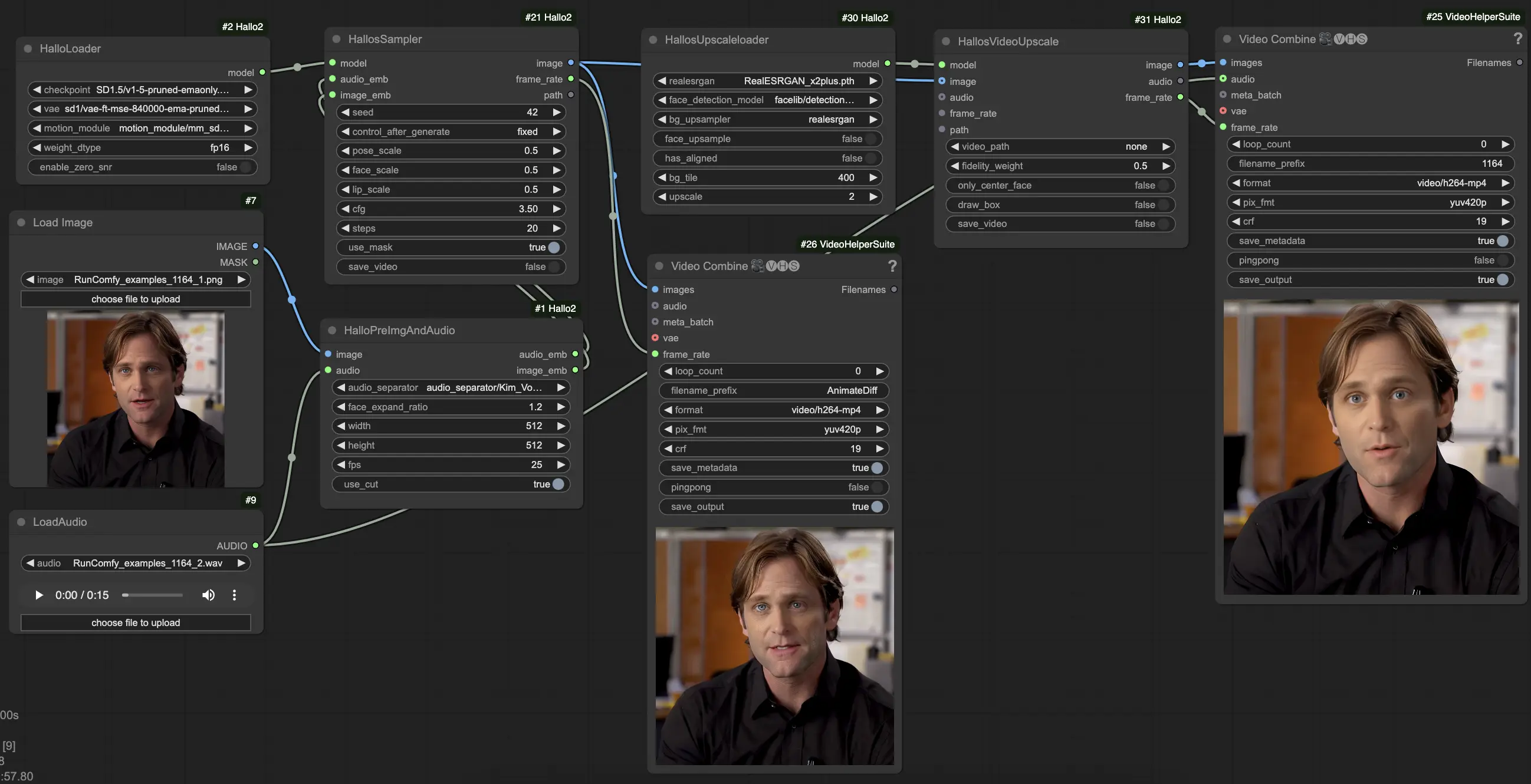
3. So verwenden Sie den ComfyUI Hallo2 Workflow
Hallo2 wurde über einen benutzerdefinierten Workflow mit mehreren spezialisierten Knoten in ComfyUI integriert. So verwenden Sie es:
- Laden Sie Ihr Referenzporträtbild mit dem
LoadImage-Knoten. Dies sollte ein klares frontales Porträt sein. (Tipps: Je besser gerahmt und beleuchtet Ihr Referenzporträt ist, desto besser werden die Ergebnisse sein. Vermeiden Sie Seitenprofile, Verdeckungen, unruhige Hintergründe etc.) - Laden Sie Ihr treibendes Audio mit dem
LoadAudio-Knoten. Es sollte die Stimmung widerspiegeln, die das Porträt ausdrücken soll. - Verbinden Sie das Bild und das Audio mit dem
HalloPreImgAndAudio-Knoten. Dies verarbeitet das Bild und das Audio in Einbettungen vor. Wichtige Parameter:audio_separator: Modell zur Trennung von Sprache und Hintergrundgeräuschen. Normalerweise auf Standard lassen.face_expand_ratio: Wie stark der erkannte Gesichtsbereich erweitert wird. Höhere Werte umfassen mehr von den Haaren/Hintergrund.width/height: Erzeugungsauflösung. Höhere Werte sind langsamer, aber detaillierter. 512-1024 Quadrat ist ein guter Kompromiss.fps: Zielvideo-FPS. 25 ist ein guter Standard.
- Laden Sie das Kernmodell Hallo2 mit dem
HalloLoader-Knoten. Zeigen Sie auf Ihre Hallo2-Checkpoint-, VAE- und Bewegungsmodul-Dateien. - Verbinden Sie die vorverarbeiteten Bild- und Audioeinbettungen zusammen mit dem geladenen Modell mit dem
HalloSampler-Knoten. Dies führt die eigentliche Videogenerierung durch. Wichtige Parameter:seed: Zufallswert, der kleine Details bestimmt. Ändern Sie ihn, wenn Ihnen das erste Ergebnis nicht gefällt.pose_scale/face_scale/lip_scale: Wie stark die Intensität von Pose, Gesichtsausdruck und Lippenbewegungen skaliert wird. 1.0 = volle Intensität, 0.0 = eingefroren.cfg: Classifier-free Guidance-Skala. Höher = folgt der Konditionierung genauer, aber weniger vielfältig.steps: Anzahl der Denoising-Schritte. Mehr Schritte = bessere Qualität, aber langsamer.
- An diesem Punkt können Sie das generierte Video ansehen. Um die Qualität weiter mit Superauflösung zu verbessern, fügen Sie die
HallosUpscaleloader- undHallosVideoUpscale-Knoten am Ende der Kette hinzu. Der Upscale-Loader liest ein vortrainiertes Upscaling-Modell ein, während der Upscaler-Knoten das Upscaling auf 4K durchführt.
