LayerDiffuse | Texto a imagen transparente
El modelo LayerDiffuse introduce un enfoque novedoso para la manipulación de imágenes, permitiendo la creación directa de imágenes transparentes. Dentro de este flujo de trabajo de LayerDiffuse de ComfyUI, se integran tres subflujos de trabajo especializados: creación de imágenes transparentes, generación de fondo a partir del primer plano y el proceso inverso de crear el primer plano basado en el fondo existente.ComfyUI LayerDiffuse Flujo de trabajo

- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI LayerDiffuse Ejemplos

ComfyUI LayerDiffuse Descripción
1. Descripción general del flujo de trabajo de LayerDiffuse de ComfyUI
El flujo de trabajo de LayerDiffuse de ComfyUI integra tres subflujos de trabajo especializados: creación de imágenes transparentes, generación de fondo a partir del primer plano y el proceso inverso de generar el primer plano basado en el fondo existente. Cada uno de estos subflujos de trabajo de LayerDiffuse opera de forma independiente, brindándole la flexibilidad de elegir y activar la funcionalidad específica de LayerDiffuse que satisfaga sus necesidades creativas.
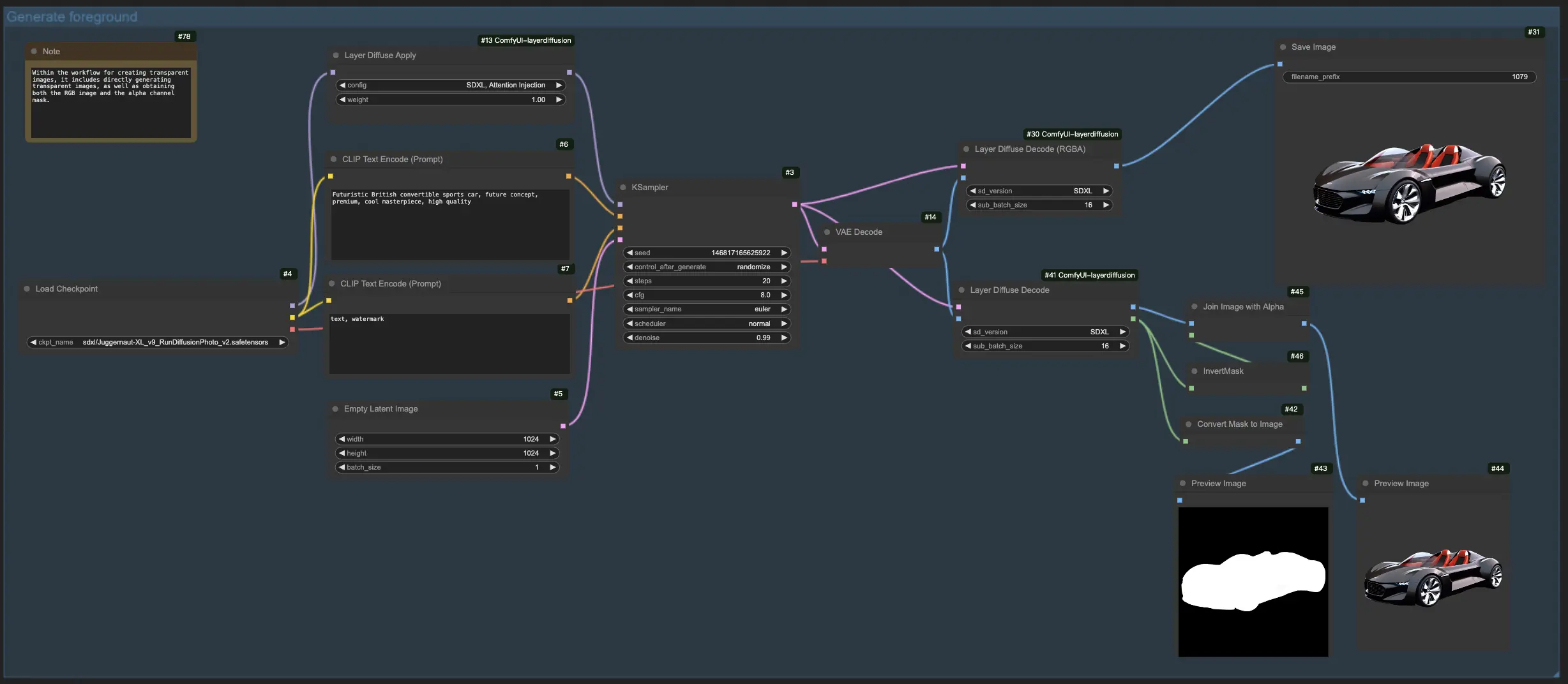
1.1. Creación de imágenes transparentes con LayerDiffuse:
Este flujo de trabajo permite la creación directa de imágenes transparentes, brindándole la flexibilidad de generar imágenes con o sin especificar la máscara del canal alfa.
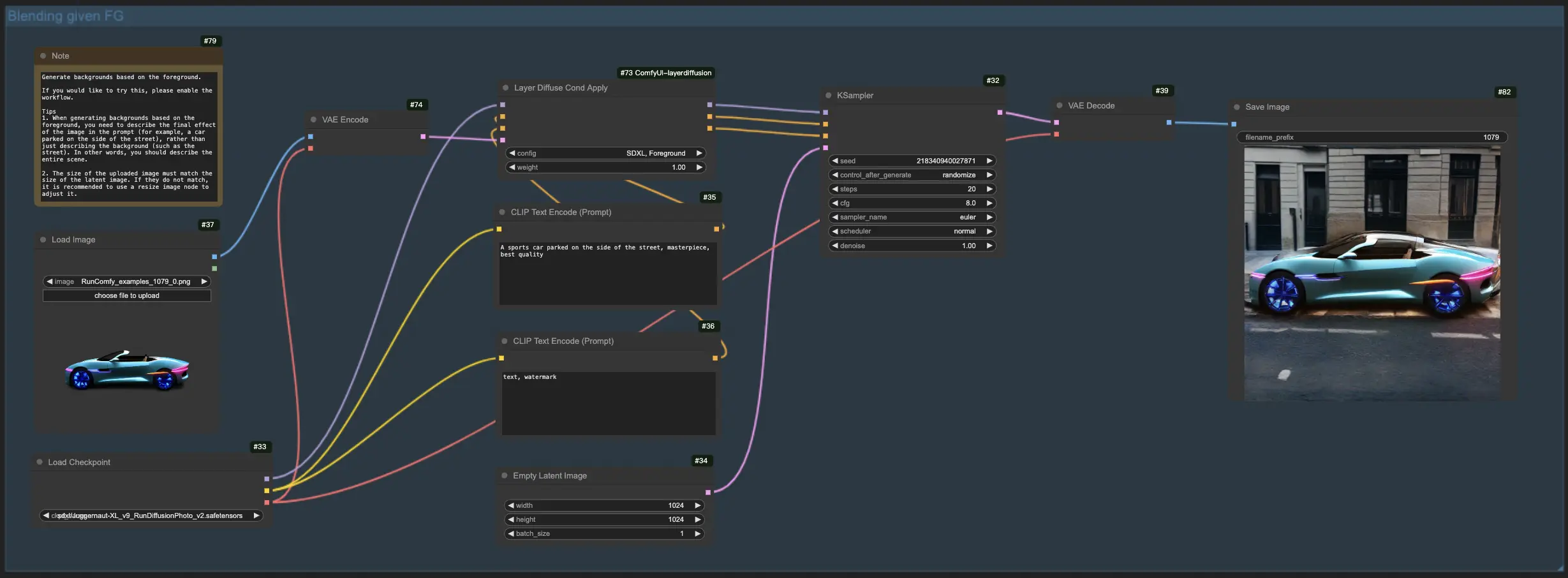
1.2. Generación de fondo a partir del primer plano con LayerDiffuse:
Para este flujo de trabajo de LayerDiffuse, comience cargando su imagen de primer plano y creando un mensaje descriptivo. LayerDiffuse luego combina estos elementos para producir la imagen deseada. Al redactar su mensaje para LayerDiffuse, es crucial detallar la escena completa (por ejemplo, "un automóvil estacionado al costado de la calle") en lugar de simplemente describir el elemento de fondo (por ejemplo, "la calle").
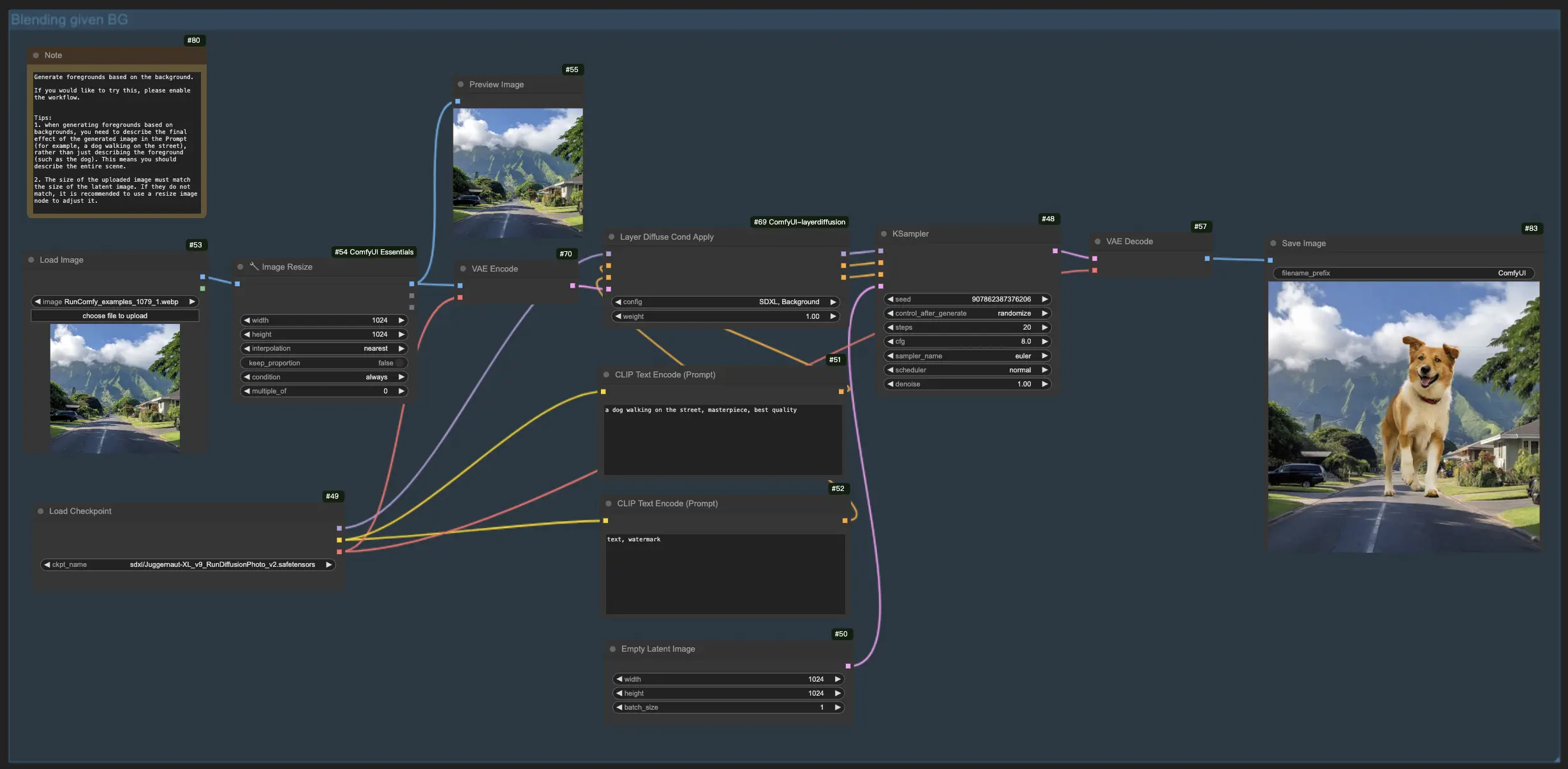
1.3. Generación del primer plano basado en el fondo:
Reflejando el flujo de trabajo anterior, esta funcionalidad de LayerDiffuse invierte el enfoque, con el objetivo de fusionar elementos del primer plano con un fondo existente. Por lo tanto, debe cargar la imagen de fondo y describir la imagen final prevista en su mensaje, enfatizando la escena completa (por ejemplo, "un perro caminando por la calle") sobre los elementos individuales (por ejemplo, "el perro").
Para más flujos de trabajo de LayerDiffuse, consúltelo en
2. Eficacia del flujo de trabajo de LayerDiffuse
Si bien el proceso de creación de imágenes transparentes es sólido y produce resultados de alta calidad de manera confiable, los flujos de trabajo para combinar fondos y primeros planos son más experimentales. Es posible que no siempre logren una combinación perfecta, lo que indica la naturaleza innovadora pero en desarrollo de esta tecnología.
3. Introducción técnica a LayerDiffuse
LayerDiffuse es un enfoque innovador diseñado para permitir que los modelos de difusión latente preentrenados a gran escala generen imágenes con transparencia. Esta técnica introduce el concepto de "transparencia latente", que implica codificar la transparencia del canal alfa directamente en la variedad latente de los modelos existentes. Esto permite la creación de imágenes transparentes o múltiples capas transparentes sin alterar significativamente la distribución latente original del modelo preentrenado. El objetivo es mantener la salida de alta calidad de estos modelos mientras se agrega la capacidad de generar imágenes con transparencia.
Para lograr esto, LayerDiffuse ajusta con precisión los modelos de difusión latente preentrenados ajustando su espacio latente para incluir la transparencia como un desplazamiento latente. Este proceso implica cambios mínimos en el modelo, preservando sus cualidades y rendimiento originales. El entrenamiento de LayerDiffuse utiliza un conjunto de datos de 1 millón de pares de capas de imágenes transparentes, recopilados a través de un esquema humano en el bucle para garantizar una amplia variedad de efectos de transparencia.
Se ha demostrado que el método es adaptable a varios generadores de imágenes de código abierto y se puede integrar en diferentes sistemas de control condicional. Esta versatilidad permite una variedad de aplicaciones, como generar imágenes con transparencia específica de primer plano/fondo, crear capas con capacidades de generación conjunta y controlar el contenido estructural de las capas.





