LTX Video | De Imagen+Texto a Video
Lightricks ha desarrollado LTX Video, un modelo de generación de video que utiliza técnicas basadas en difusión. El modelo puede generar videos a partir de indicaciones de texto o una combinación de indicaciones de imagen y texto. LTX Video produce videos a una resolución de 768x512 y una tasa de fotogramas de 24 FPS. El modelo LTX ha sido entrenado en un conjunto de datos diverso para generar contenido de video variado. Descubra las técnicas detrás del modelo LTX y úselo dentro de ComfyUI.ComfyUI LTX Video Flujo de trabajo
- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI LTX Video Ejemplos
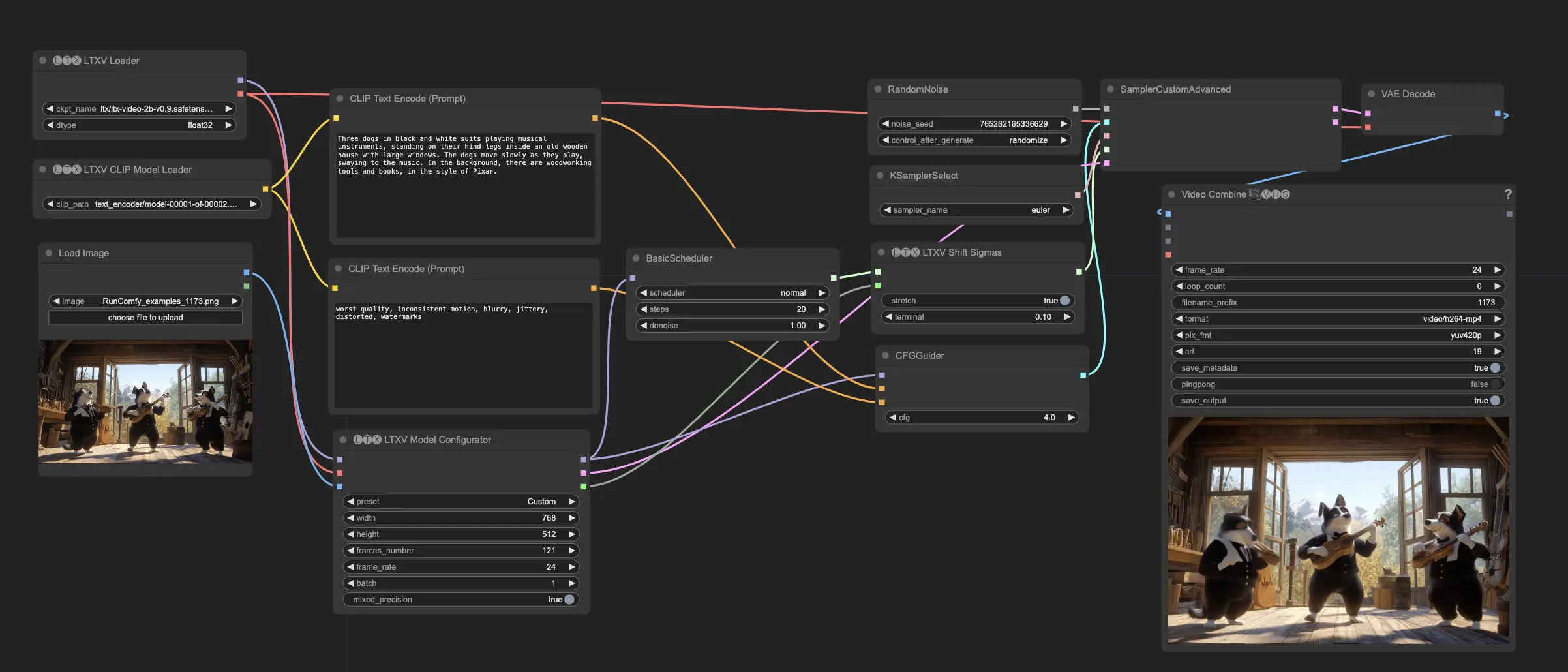
ComfyUI LTX Video Descripción
LTX Video es un modelo de generación de video basado en difusión desarrollado por Lightricks. Es capaz de generar videos a partir de indicaciones de texto (texto a video) o una combinación de indicaciones de imagen y texto (imagen+texto a video). LTX Video produce videos de 24 fotogramas por segundo (FPS) a una resolución de 768x512 más rápido de lo que pueden ser vistos. El modelo ha sido entrenado en un conjunto de datos a gran escala que contiene videos diversos, lo que le permite generar contenido de video realista y variado a altas resoluciones.
El Modelo LTX Video y los Nodos ComfyUI-LTXVideo fueron desarrollados por Lightricks. Todo el crédito va a su trabajo en la creación de LTX Video. Para obtener más información sobre LTX Video y los proyectos de Lightricks, por favor visite su repositorio de GitHub en https://github.com/Lightricks/LTX-Video o su sitio web en https://www.lightricks.com/ltxv.
Técnicas detrás del Modelo LTX
LTX Video utiliza un enfoque basado en Difusión para generar videos. Los modelos de difusión funcionan deshaciendo gradualmente el ruido de una entrada ruidosa a lo largo de múltiples pasos de tiempo para generar el resultado final. En el caso de LTX Video, el modelo toma una representación latente ruidosa como entrada y la desruida iterativamente para producir una secuencia de fotogramas de video. El proceso de desruido está guiado por las indicaciones de texto o imagen+texto proporcionadas, que controlan el contenido y el estilo del video generado.
Las técnicas clave empleadas por LTX Video incluyen:
- Generación de video basada en difusión: Al aprovechar los modelos de difusión, LTX Video puede generar videos de alta calidad con movimiento realista y consistencia entre fotogramas.
- Síntesis de texto a video: LTX Video puede generar videos únicamente basados en descripciones textuales, permitiendo a los usuarios crear videos personalizados desde cero usando indicaciones en lenguaje natural.
- Síntesis de imagen+texto a video: LTX Video también admite la generación de videos combinando una imagen inicial con una indicación de texto. Esto permite a los usuarios proporcionar un punto de partida para el video y guiar su contenido y estilo utilizando texto.
Cómo Usar el Flujo de Trabajo de LTX Video en ComfyUI
- Prepare la Entrada:
- El flujo de trabajo predeterminado es la generación de video de imagen + texto. Proporcione una imagen inicial junto con una indicación de texto. La imagen sirve como punto de partida, y el modelo generará un video basado en tanto la imagen como el texto acompañante. Tenga en cuenta que este modelo requiere indicaciones largas y descriptivas; si la indicación es demasiado corta, la calidad sufrirá considerablemente.
- Configure los Parámetros del Modelo:
- Establezca la resolución deseada y el número de fotogramas para el contenido generado. La resolución debe ser divisible por 32, y el número de fotogramas debe ser divisible por 8 + 1 (por ejemplo, 257 fotogramas). LTX funciona mejor con resoluciones inferiores a 720x1280 píxeles y menos de 257 fotogramas.
- Ajuste otros parámetros como los pasos de difusión, el horario de ruido y la escala de orientación según sus requisitos. Estos parámetros controlan la calidad y diversidad del resultado generado.
- Genere el Contenido:
- La salida tendrá la resolución y el número de fotogramas especificados, y se alineará con la indicación de entrada proporcionada.
Limitaciones del Modelo LTX
- LTX Video no está diseñado ni es capaz de proporcionar información factual.
- Como modelo estadístico, LTX Video podría amplificar los sesgos sociales existentes presentes en los datos de entrenamiento.
- Los videos generados pueden no coincidir perfectamente con las indicaciones proporcionadas.
- La calidad del seguimiento de la indicación depende en gran medida del estilo de indicación utilizado.
Licencia
Por favor, use el modelo para propósitos bajo la

