
Segment Anything V2, también conocido como SAM2, es un modelo de IA revolucionario desarrollado por Meta AI que revoluciona la segmentación de objetos tanto en imágenes como en videos.
¿Qué es Segment Anything V2 (SAM2)?
Segment Anything V2 es un modelo de IA de última generación que permite la segmentación perfecta de objetos en imágenes y videos. Es el primer modelo unificado capaz de manejar tareas de segmentación de imágenes y videos con una precisión y eficiencia excepcionales. Segment Anything V2 (SAM2) se basa en el éxito de su predecesor, el Segment Anything Model (SAM), al extender sus capacidades de entrada al dominio del video.
Con Segment Anything V2 (SAM2), los usuarios pueden seleccionar un objeto en una imagen o fotograma de video utilizando varios métodos de entrada, como un clic, un cuadro delimitador o una máscara. El modelo luego segmenta inteligentemente el objeto seleccionado, permitiendo la extracción y manipulación precisas de elementos específicos dentro del contenido visual.
Puntos destacados de Segment Anything V2 (SAM2)
- Rendimiento de última generación: SAM2 supera a los modelos existentes en el campo de la segmentación de objetos tanto en imágenes como en videos. Establece un nuevo punto de referencia para la precisión y la exactitud, superando el rendimiento de su predecesor, SAM, en tareas de segmentación de imágenes.
- Modelo unificado para imágenes y videos: SAM2 es el primer modelo en proporcionar una solución unificada para segmentar objetos tanto en imágenes como en videos. Esta integración simplifica el flujo de trabajo para los artistas de IA, ya que pueden usar un solo modelo para diversas tareas de segmentación.
- Capacidades mejoradas de segmentación de video: SAM2 sobresale en la segmentación de objetos en video, particularmente en el seguimiento de partes de objetos. Supera a los modelos de segmentación de video existentes, ofreciendo una mejor precisión y consistencia en la segmentación de objetos a lo largo de los fotogramas.
- Tiempo de interacción reducido: En comparación con los métodos interactivos de segmentación de video existentes, SAM2 requiere menos tiempo de interacción por parte de los usuarios. Esta eficiencia permite a los artistas de IA centrarse más en su visión creativa y pasar menos tiempo en tareas de segmentación manual.
- Diseño simple y rápida inferencia: A pesar de sus capacidades avanzadas, SAM2 mantiene un diseño arquitectónico simple y ofrece velocidades de inferencia rápidas. Esto asegura que los artistas de IA puedan integrar SAM2 en sus flujos de trabajo sin problemas, sin comprometer el rendimiento o la eficiencia.
Cómo funciona Segment Anything V2 (SAM2)
SAM2 extiende la capacidad de entrada de SAM a los videos introduciendo un módulo de memoria por sesión que captura la información del objeto objetivo, permitiendo el seguimiento de objetos a lo largo de los fotogramas, incluso con desapariciones temporales. La arquitectura de transmisión procesa los fotogramas de video uno a la vez, comportándose como SAM para imágenes cuando el módulo de memoria está vacío. Esto permite el procesamiento de video en tiempo real y la generalización natural de las capacidades de SAM. SAM2 también admite correcciones interactivas de predicción de máscaras basadas en indicaciones del usuario. El modelo utiliza una arquitectura de transformador con memoria de transmisión y está entrenado en el conjunto de datos SA-V, el conjunto de datos de segmentación de video más grande recolectado utilizando un motor de datos en el bucle que mejora tanto el modelo como los datos a través de la interacción del usuario.
Cómo usar Segment Anything V2 (SAM2) en ComfyUI
Este flujo de trabajo de ComfyUI admite la selección de un objeto en un fotograma de video utilizando un clic/punto.
1. Cargar Video (Subir)
Carga de Video: Selecciona y sube el video que deseas procesar.

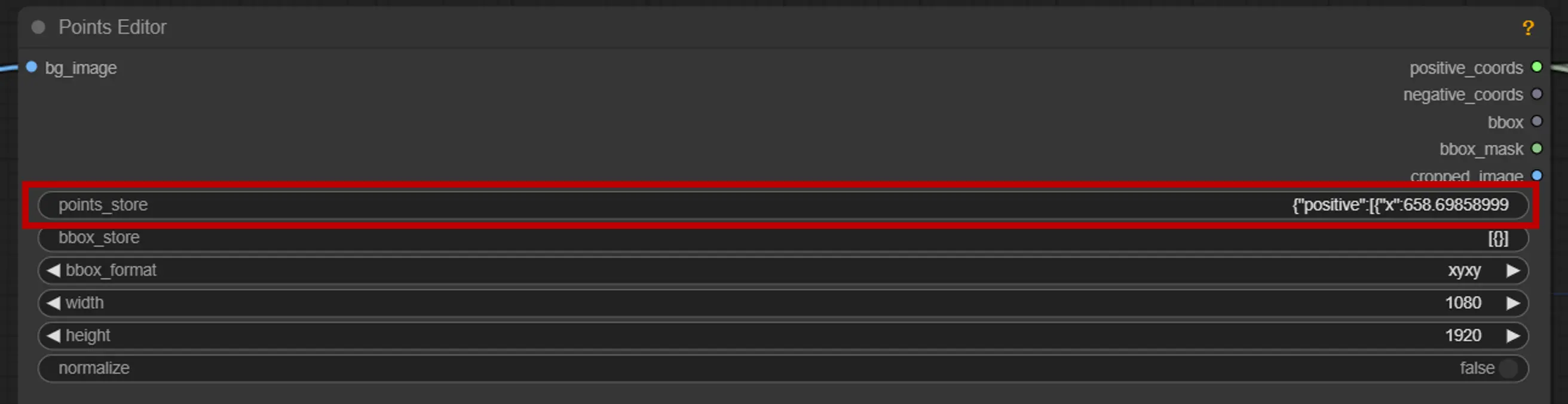
2. Editor de Puntos
punto clave: Coloca tres puntos clave en el lienzo—positive0, positive1 y negative0:
positive0 y positive1 marcan las regiones u objetos que deseas segmentar.
negative0 ayuda a excluir áreas no deseadas o distracciones.

points_store: Te permite agregar o eliminar puntos según sea necesario para refinar el proceso de segmentación.
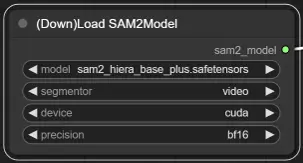
3. Selección de Modelo de SAM2
Opciones de Modelo: Elige entre los modelos SAM2 disponibles: tiny, small, large o base_plus. Los modelos más grandes proporcionan mejores resultados pero requieren más tiempo de carga.
Para más información, visita Kijai ComfyUI-segment-anything-2.
