
1. À propos de CogVideoX-5B#
CogVideoX-5B est un modèle de diffusion texte en vidéo de pointe développé par Zhipu AI à l'Université Tsinghua. Faisant partie de la série CogVideoX, ce modèle crée des vidéos directement à partir de prompts textuels en utilisant des techniques avancées d'IA telles qu'un 3D Variational Autoencoder (VAE) et un Expert Transformer. CogVideoX-5B génère des résultats de haute qualité, cohérents dans le temps, capturant des mouvements complexes et des sémantiques détaillées.
Avec CogVideoX-5B, vous obtenez une clarté et une fluidité exceptionnelles. Le modèle assure une transition fluide, capturant des détails complexes et des éléments dynamiques avec une précision extraordinaire. L'utilisation de CogVideoX-5B réduit les incohérences et les artefacts, conduisant à une présentation soignée et engageante. Les sorties haute fidélité de CogVideoX-5B facilitent la création de scènes richement détaillées et cohérentes à partir de prompts textuels, en faisant un outil essentiel pour une qualité et un impact visuel de premier ordre.
2. La Technique de CogVideoX-5B#
2.1 3D Causal Variational Autoencoder (VAE) de CogVideoX-5B#
Le 3D Causal VAE est un composant clé de CogVideoX-5B, permettant une génération efficace de vidéos en compressant les données vidéo à la fois spatialement et temporellement. Contrairement aux modèles traditionnels qui utilisent des VAEs 2D pour traiter chaque image individuellement—souvent entraînant un scintillement entre les images—CogVideoX-5B utilise des convolutions 3D pour capturer à la fois les informations spatiales et temporelles en une seule fois. Cette approche assure des transitions fluides et cohérentes entre les images.
L'architecture du 3D Causal VAE comprend un encodeur, un décodeur et un régularisateur d'espace latent. L'encodeur compresse les données vidéo en une représentation latente, que le décodeur utilise ensuite pour reconstruire la vidéo. Un régularisateur Kullback-Leibler (KL) contraint l'espace latent, assurant que la vidéo encodée reste dans une distribution gaussienne. Cela aide à maintenir une haute qualité vidéo lors de la reconstruction.
Caractéristiques Clés du 3D Causal VAE
- Compression Spatiale et Temporelle : Le VAE compresse les données vidéo par un facteur de 4x dans la dimension temporelle et 8x8 dans les dimensions spatiales, atteignant un ratio de compression total de 4x8x8. Cela réduit les demandes de calcul, permettant au modèle de traiter des vidéos plus longues avec moins de ressources.
- Convolution Causale : Pour préserver l'ordre des images dans une vidéo, le modèle utilise des convolutions temporellement causales. Cela assure que les images futures n'influencent pas la prédiction des images actuelles ou passées, maintenant l'intégrité de la séquence pendant la génération.
- Parallélisme de Contexte : Pour gérer la lourde charge computationnelle du traitement des longues vidéos, le modèle utilise le parallélisme de contexte dans la dimension temporelle, répartissant la charge de travail sur plusieurs appareils. Cela optimise le processus d'entraînement et réduit l'utilisation de la mémoire.
2.2 Architecture Expert Transformer de CogVideoX-5B#
L'architecture expert transformer de CogVideoX-5B est conçue pour gérer efficacement l'interaction complexe entre les données textuelles et vidéo. Elle utilise une technique d'adaptive LayerNorm pour traiter les espaces de caractéristiques distincts du texte et de la vidéo.
Caractéristiques Clés de l'Expert Transformer
- Patchification : Après que le 3D Causal VAE a encodé les données vidéo, elles sont divisées en plus petits patchs le long des dimensions spatiales. Ce processus, appelé patchification, convertit la vidéo en une séquence de segments plus petits, facilitant le traitement par le transformer et l'alignement avec les données textuelles correspondantes.
- 3D Rotary Positional Embedding (RoPE) : Pour capturer les relations spatiales et temporelles au sein de la vidéo, CogVideoX-5B étend le RoPE 2D traditionnel à 3D. Cette technique d'embedding applique un encodage positionnel aux dimensions x, y et t de la vidéo, aidant le transformer à modéliser efficacement les longues séquences vidéo et à maintenir la cohérence entre les images.
- Expert Adaptive LayerNorm (AdaLN) : Le transformer utilise une adaptive LayerNorm experte pour traiter séparément les embeddings textuels et vidéo. Cela permet au modèle d'aligner les différents espaces de caractéristiques du texte et de la vidéo, permettant une fusion fluide de ces deux modalités.
2.3 Techniques d'Entraînement Progressif de CogVideoX-5B#
CogVideoX-5B utilise plusieurs techniques d'entraînement progressif pour améliorer ses performances et sa stabilité lors de la génération de vidéos.
Stratégies Clés d'Entraînement Progressif
- Entraînement de Durée Mixte : Le modèle est entraîné sur des vidéos de différentes longueurs au sein du même lot. Cette technique améliore la capacité du modèle à généraliser, lui permettant de générer des vidéos de différentes durées tout en maintenant une qualité constante.
- Entraînement Progressif en Résolution : Le modèle est d'abord entraîné sur des vidéos de basse résolution, puis affiné progressivement sur des vidéos de haute résolution. Cette approche permet au modèle d'apprendre la structure et le contenu de base des vidéos avant de raffiner sa compréhension à des résolutions plus élevées.
- Échantillonnage Uniforme Explicite : Pour stabiliser le processus d'entraînement, CogVideoX-5B utilise un échantillonnage uniforme explicite, définissant différents intervalles d'échantillonnage temporel pour chaque rang parallèle de données. Cette méthode accélère la convergence et assure que le modèle apprend efficacement sur l'ensemble de la séquence vidéo.
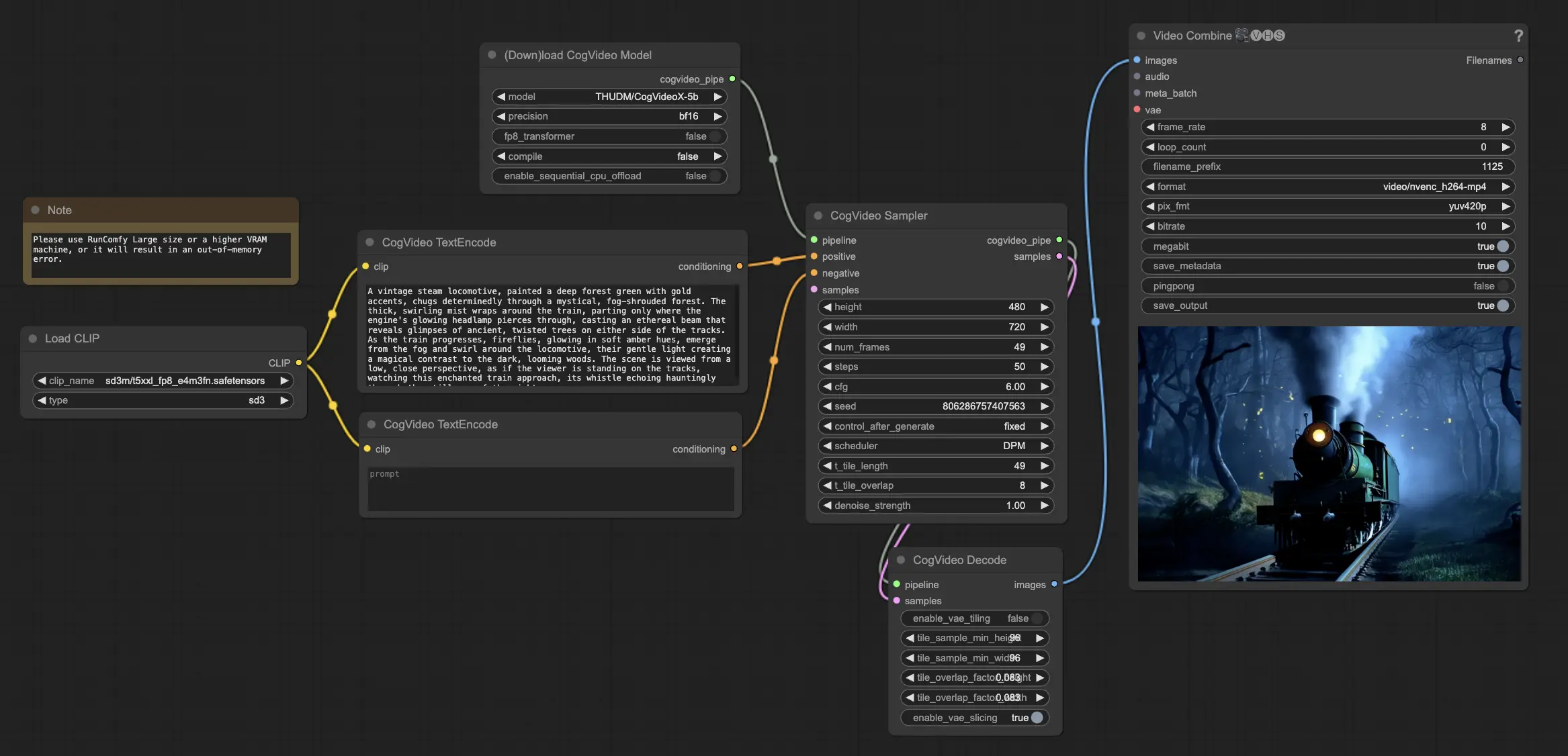
3. Comment Utiliser le Workflow ComfyUI CogVideoX-5B#
Étape 1 : Charger le Modèle CogVideoX-5B#
Commencez par charger le modèle CogVideoX-5B dans le workflow ComfyUI. Les modèles CogVideoX-5B ont été préchargés sur la plateforme RunComfy.
Étape 2 : Saisir Votre Prompt Textuel#
Entrez votre prompt textuel souhaité dans le nœud désigné pour guider le processus de génération vidéo de CogVideoX-5B. CogVideoX-5B excelle à interpréter et transformer les prompts textuels en contenu vidéo dynamique.
4. Accord de Licence#
Le code des modèles CogVideoX est publié sous la Licence Apache 2.0.
Le modèle CogVideoX-2B (y compris son module Transformers et son module VAE) est publié sous la Licence Apache 2.0.
Le modèle CogVideoX-5B (module Transformers) est publié sous la Licence CogVideoX.
