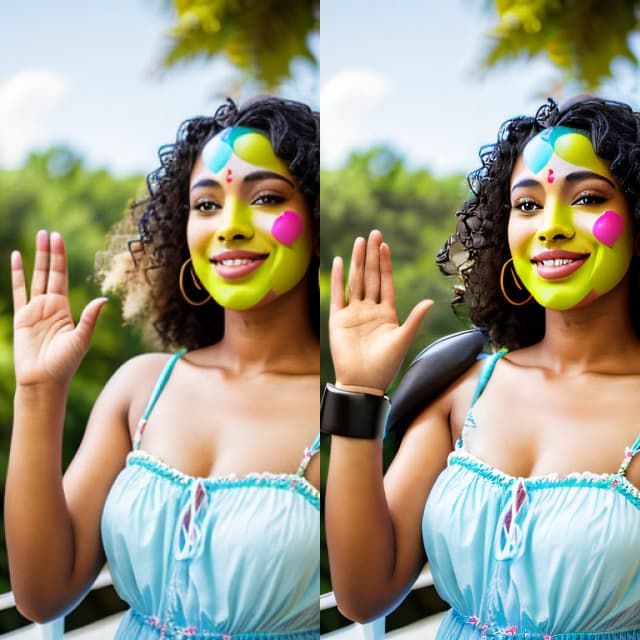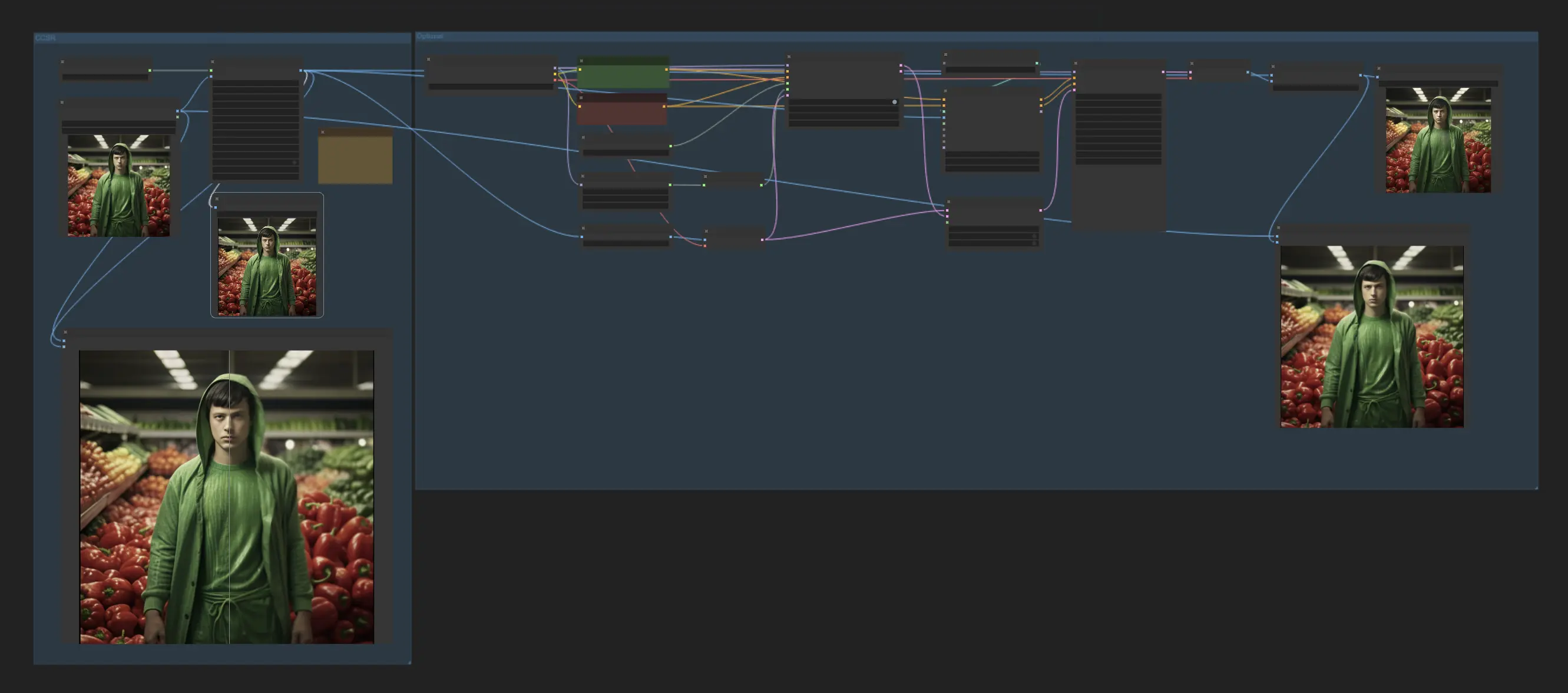
1. ComfyUI CCSR | ComfyUI Upscale Workflow#
Ce workflow ComfyUI intègre le modèle CCSR (Content Consistent Super-Resolution), conçu pour améliorer la cohérence du contenu dans les tâches de super-résolution. Après l'application du modèle CCSR, il y a une étape optionnelle qui implique une mise à l'échelle supplémentaire en ajoutant du bruit et en utilisant le modèle ControlNet recolor. C'est une fonctionnalité expérimentale que les utilisateurs peuvent explorer.
Par défaut, ce workflow est configuré pour la mise à l'échelle d'images. Pour mettre à l'échelle des vidéos, remplacez simplement "load image" par "load video" et changez "save image" en "combine video".
2. Introduction à CCSR#
Les modèles de diffusion latente pré-entraînés ont été reconnus pour leur potentiel à améliorer la qualité perceptuelle des résultats de super-résolution (SR) d'images. Cependant, ces modèles produisent souvent des résultats variables pour des images basse résolution identiques dans différentes conditions de bruit. Cette variabilité, bien qu'avantageuse pour la génération d'images à partir de texte, pose des défis pour les tâches de SR, qui exigent une cohérence dans la préservation du contenu.
Pour améliorer la fiabilité de la SR basée sur des priors de diffusion, CCSR (Content Consistent Super-Resolution) utilise une stratégie qui combine des modèles de diffusion pour affiner les structures d'image avec des réseaux antagonistes génératifs (GANs) pour améliorer les détails fins. Il introduit une stratégie d'apprentissage de pas de temps non uniforme pour entraîner un réseau de diffusion compact. Ce réseau reconstruit efficacement et de manière stable les structures principales d'une image, tandis que le décodeur pré-entraîné d'un auto-encodeur variationnel (VAE) est ajusté par un entraînement antagoniste pour l'amélioration des détails. Cette approche aide CCSR à réduire considérablement la stochasticité associée aux méthodes de SR basées sur des priors de diffusion, améliorant ainsi la cohérence du contenu dans les résultats de SR et accélérant le processus de génération d'images.
3. Comment utiliser ComfyUI CCSR pour la mise à l'échelle d'images#
3.1. Modèles CCSR#
real-world_ccsr.ckpt : Modèle CCSR pour la restauration d'images réelles.
bicubic_ccsr.ckpt : Modèle CCSR pour la restauration d'images bicubiques.
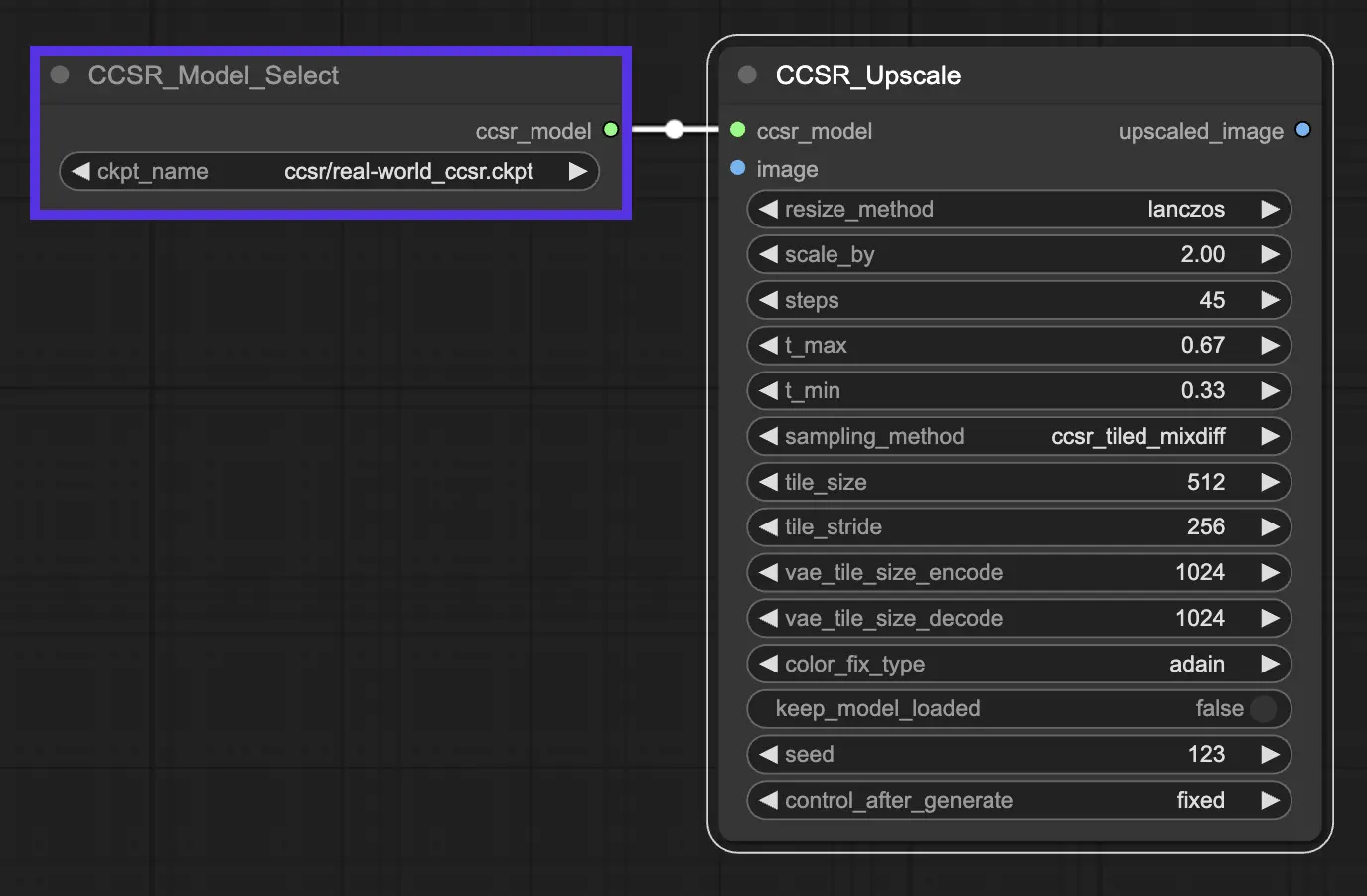
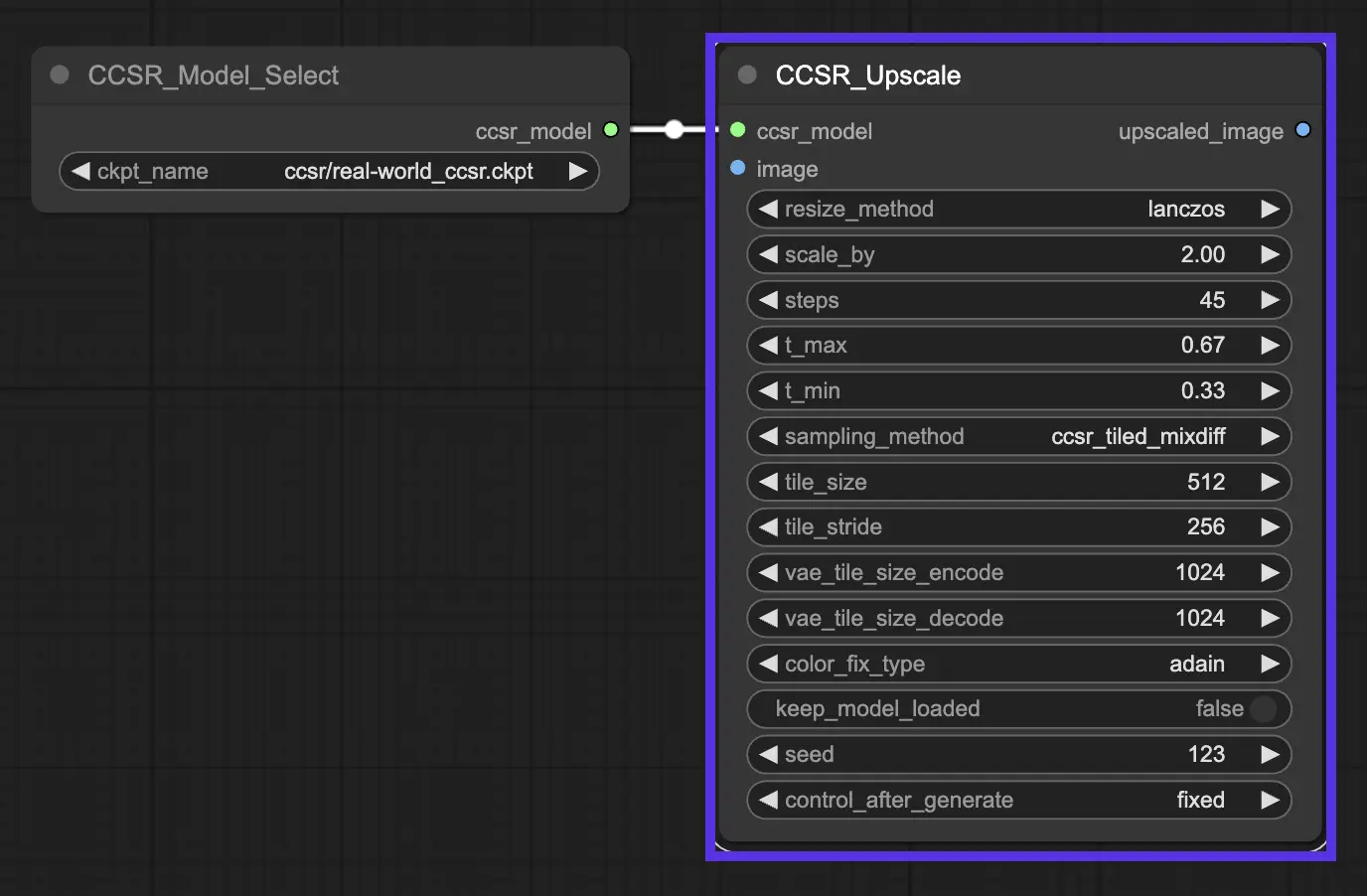
3.2. Paramètres clés dans CCSR#
-scale_by : Ce paramètre spécifie l'échelle de super-résolution, déterminant dans quelle mesure les images ou vidéos d'entrée sont agrandies.
-steps : Fait référence au nombre d'étapes dans le processus de diffusion. Il contrôle le nombre d'itérations que le modèle effectue pour affiner les détails et les structures de l'image.
-t_max et -t_min : Ces paramètres définissent les seuils maximum et minimum pour la stratégie d'apprentissage de pas de temps non uniforme utilisée dans le modèle CCSR.
-sampling_method :
CCSR (Normal, Untiled): Cette approche utilise une méthode d'échantillonnage normale, non carrelée. Elle est simple et ne divise pas l'image en tuiles pour le traitement. Bien que cela puisse être efficace pour assurer la cohérence du contenu sur l'ensemble de l'image, cela consomme également beaucoup de VRAM. Cette méthode convient le mieux aux scénarios où la VRAM est abondante et où la plus grande cohérence possible sur l'ensemble de l'image est requise.CCSR_Tiled_MixDiff: Cette approche carrelée traite chaque tuile de l'image séparément, ce qui aide à gérer l'utilisation de la VRAM plus efficacement en ne nécessitant pas que l'image entière soit en mémoire à la fois. Cependant, un inconvénient notable est le potentiel de coutures visibles où les tuiles se rencontrent, car chaque tuile est traitée indépendamment, conduisant à des incohérences possibles aux bordures des tuiles.CCSR_Tiled_VAE_Gaussian_Weights: Cette méthode vise à corriger le problème de couture observé dans l'approche CCSR_Tiled_MixDiff en utilisant des poids gaussiens pour mélanger les tuiles plus en douceur. Cela peut réduire considérablement la visibilité des coutures, offrant une apparence plus cohérente aux bordures des tuiles. Cependant, ce mélange peut parfois être moins précis et pourrait introduire du bruit supplémentaire dans l'image super-résolue, affectant la qualité globale de l'image.
-tile_size et -tile_stride : Ces paramètres font partie de la fonctionnalité de diffusion carrelée, qui est intégrée à CCSR pour économiser de la mémoire GPU pendant l'inférence. Le carrelage fait référence au traitement de l'image par patchs plutôt qu'en entier, ce qui peut être plus efficace en mémoire. -tile_size spécifie la taille de chaque tuile, et -tile_diffusion_stride contrôle la stride ou le chevauchement entre les tuiles.
-color_fix_type: Ce paramètre indique la méthode utilisée pour la correction ou l'ajustement des couleurs dans le processus de super-résolution. adain est l'une des méthodes employées pour la correction des couleurs afin de s'assurer que les couleurs de l'image super-résolue correspondent le plus possible à l'image d'origine.
4. Plus de détails sur CCSR#
La super-résolution d'images, qui vise à récupérer des images haute résolution (HR) à partir de leurs homologues basse résolution (LR), relève le défi posé par la dégradation de la qualité lors de la capture d'image. Alors que les techniques de SR existantes basées sur l'apprentissage profond se sont principalement concentrées sur l'optimisation de l'architecture des réseaux de neurones par rapport à des dégradations simples et connues, elles ne parviennent pas à gérer les dégradations complexes rencontrées dans des scénarios réels. Les avancées récentes ont inclus le développement d'ensembles de données et de méthodes simulant des dégradations d'images plus complexes pour se rapprocher de ces défis réels.
L'étude souligne également les limites des fonctions de perte traditionnelles, telles que ℓ1 et MSE, qui ont tendance à produire des détails trop lisses dans les sorties SR. Bien que la perte SSIM et la perte perceptuelle atténuent ce problème dans une certaine mesure, obtenir des détails d'image réalistes reste un défi. Les GANs sont apparus comme une approche réussie pour améliorer les détails des images, mais leur application aux images naturelles entraîne souvent des artefacts visuels en raison de la nature diversifiée des scènes naturelles.
Les modèles probabilistes de diffusion de débruitage (DDPM) et leurs variantes ont montré un potentiel significatif, surpassant les GANs dans la génération de priors divers et de haute qualité pour la restauration d'images, y compris la SR. Ces modèles, cependant, ont eu du mal à s'adapter aux dégradations complexes et variées présentes dans les applications réelles.
L'approche CCSR cherche à relever ces défis en assurant des résultats de super-résolution stables et cohérents. Elle exploite les priors de diffusion pour générer des structures cohérentes et emploie un entraînement antagoniste génératif pour l'amélioration des détails et des textures. En adoptant une stratégie d'échantillonnage de pas de temps non uniforme et en ajustant un décodeur VAE pré-entraîné, CCSR obtient des résultats SR stables et cohérents en termes de contenu plus efficacement que les méthodes SR existantes basées sur les priors de diffusion.