IPAdapter V1 FaceID Plus | Personnages cohérents
Libérez tout le potentiel de vos conceptions de personnages avec le modèle IPAdapter Face Plus V2. Ce flux de travail permet aux créateurs de maintenir des caractéristiques cohérentes des personnages à travers divers styles. N'hésitez pas à utiliser différents points de contrôle ou modèles LoRA pour explorer une variété de stylesFlux de travail ComfyUI Consistent Characters
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
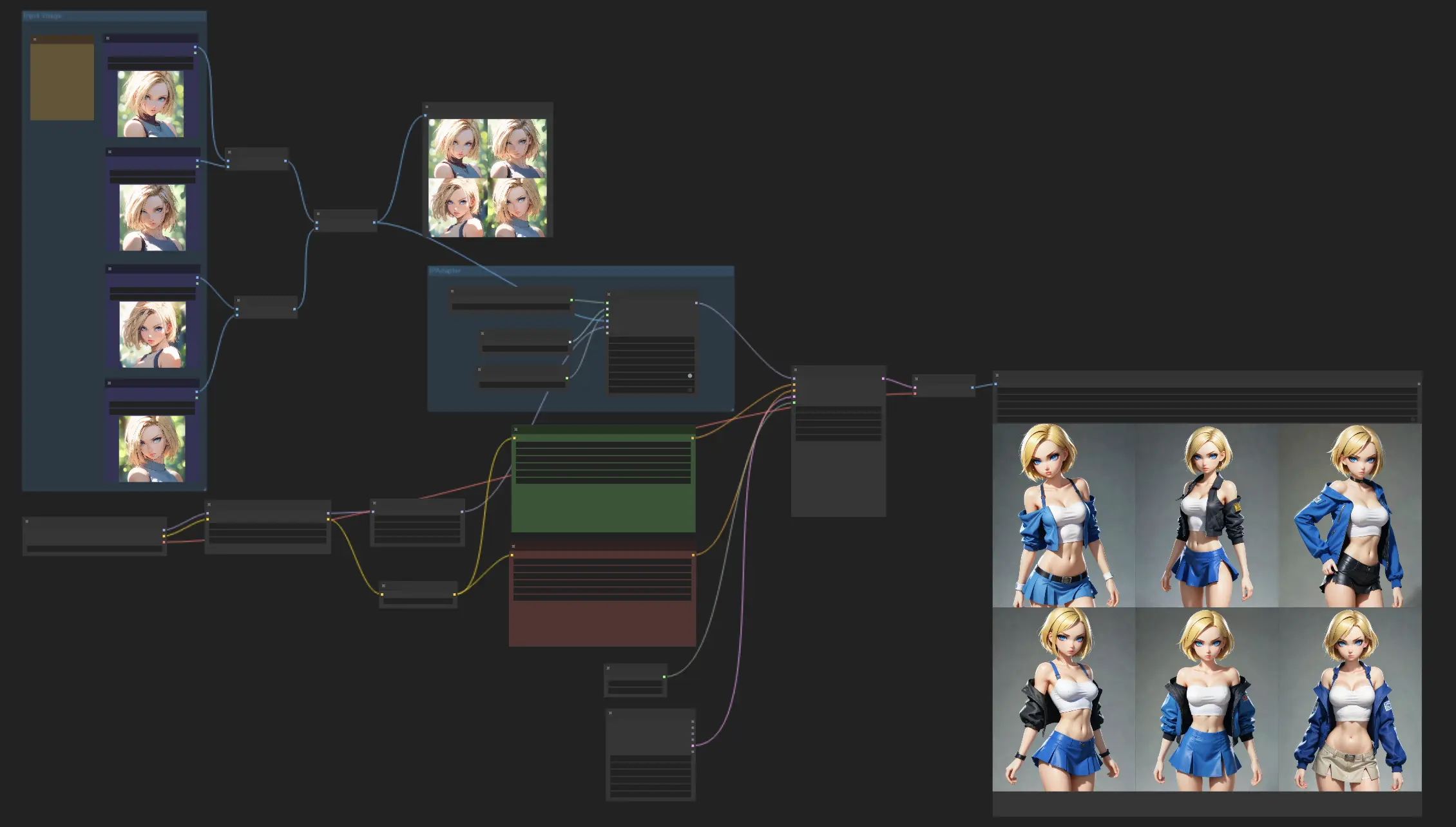
Exemples ComfyUI Consistent Characters

Description ComfyUI Consistent Characters
1. Flux de travail pour des personnages cohérents
Ce flux de travail consiste à créer des personnages avec une apparence cohérente, en tirant parti du modèle IPAdapter Face Plus V2. Commencez simplement par télécharger quelques images de référence, puis laissez le modèle Face Plus V2 faire des merveilles, en créant une série d'images qui conservent les mêmes caractéristiques faciales. N'hésitez pas à mélanger les choses avec différents points de contrôle ou modèles LoRA pour explorer une variété de styles, tout en gardant l'apparence de votre personnage cohérente.
2. Aperçu d'IPAdapter FaceID/FaceID Plus
v1.5 FaceID
Ce modèle est la version de base pour l'identification des visages, permettant des variations augmentées par des invites textuelles, des control nets et des masques. Il est noté pour sa force moyenne en conditionnement, ce qui le rend approprié pour les tâches générales de conditionnement des visages. Le modèle FaceID de base n'utilise pas d'encodeur de vision CLIP, ce qui implique une configuration plus simple sans avoir besoin de configurations d'encodeur complexes.
v1.5 FaceID Plus
Le modèle FaceID Plus est une variante plus puissante, conçue pour des effets de conditionnement d'image à image plus forts. Il nécessite l'utilisation de l'encodeur d'image ViT-H, indiquant son besoin de capacités de traitement plus élevées pour une modélisation détaillée des visages.
v1.5 FaceID Plus v2
Une itération sur le FaceID Plus, ce modèle introduit des améliorations pour un conditionnement des visages encore plus détaillé. Semblable à FaceID Plus, il utilise l'encodeur d'image ViT-H. Ce modèle vise à fournir une qualité accrue dans la modélisation des visages, répondant à des exigences plus nuancées.
v1.5 FaceID Portrait
Conçu spécifiquement pour les portraits, ce modèle n'utilise pas d'encodeur de vision CLIP. Il se concentre sur la génération d'images faciales de haute qualité dans des paramètres de portrait, offrant potentiellement une approche spécialisée pour la génération d'images de portrait.
SDXL FaceID
La variante SDXL de FaceID est adaptée pour une utilisation avec l'architecture SDXL, n'employant pas d'encodeur de vision CLIP. Il représente un modèle de base dans la suite SDXL, conçu pour des architectures d'apprentissage profond évolutives, se concentrant sur les tâches d'identification des visages.
SDXL FaceID Plus v2
Il s'agit d'une version plus puissante du modèle FaceID pour l'architecture SDXL, utilisant l'encodeur d'image ViT-H. Il est conçu pour offrir des effets de conditionnement des visages améliorés dans le cadre SDXL, visant des tâches de génération d'images de haute qualité.
3. Comment utiliser IPAdapter FaceID/FaceID Plus
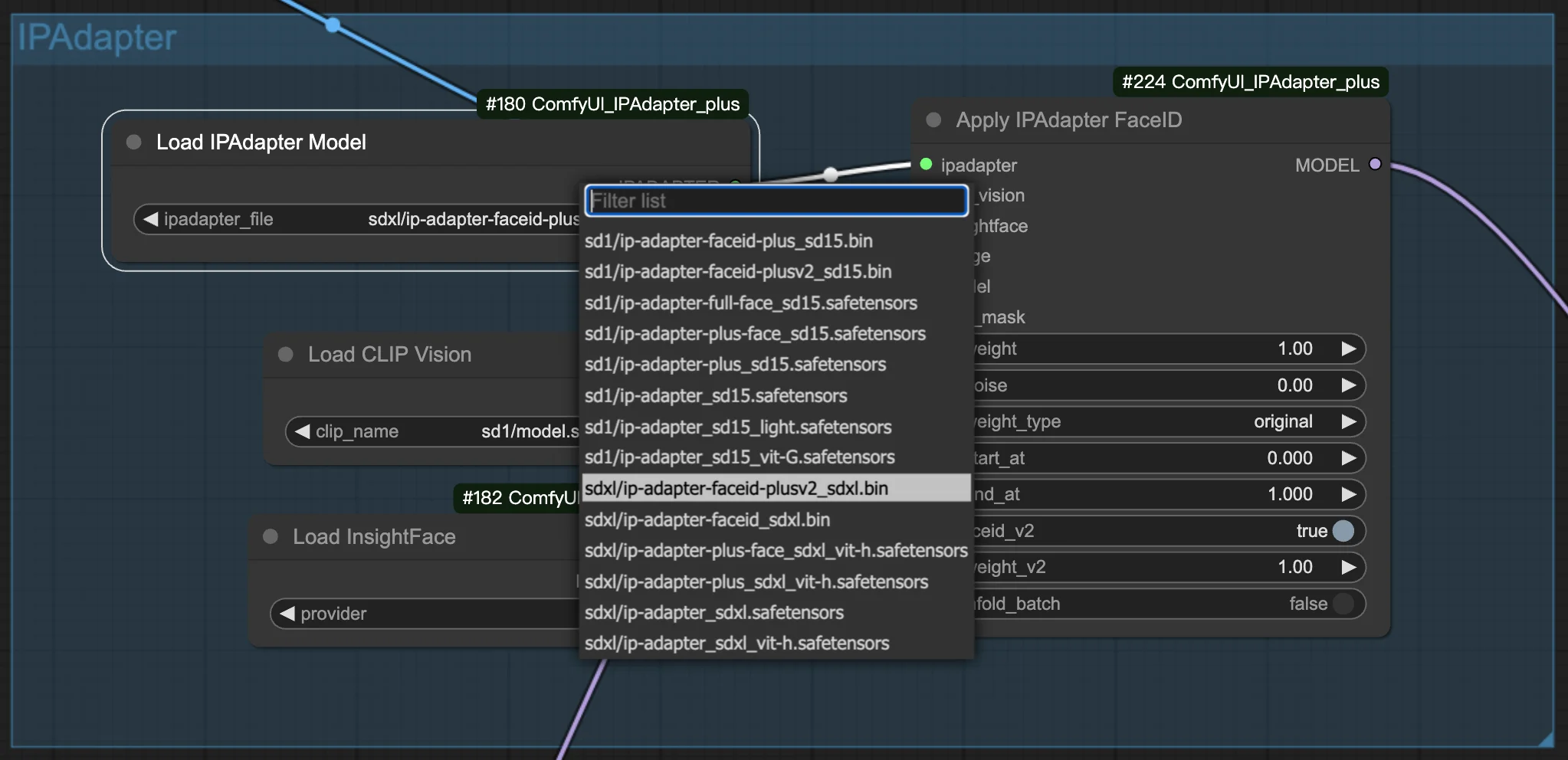
3.1. Choisir le modèle FaceID/FaceID Plus
Sélectionnez votre modèle FaceID ou FaceID Plus préféré pour commencer à créer vos images. Dans les paramètres, vous trouverez des options pour ajuster à la fois les poids et le bruit. Ces ajustements sont essentiels pour affiner l'apparence de vos images générées, vous permettant d'obtenir l'aspect précis que vous recherchez.
3.2. Préparer l'image de référence
Lorsque vous utilisez des nœuds IPAdapter FaceID, le modèle de vision CLIP traite votre image de référence en la redimensionnant et en la centrant à une dimension de 224x224 pixels. Cet ajustement automatique se concentre sur le centre de l'image, il est donc crucial que le sujet principal de votre image, comme le visage d'un personnage, soit positionné de manière centrée. Si le sujet est décentré, en particulier dans les images portrait ou paysage, les résultats pourraient ne pas répondre à vos attentes. Pour de meilleurs résultats, il est fortement recommandé d'utiliser des images carrées avec le sujet centré.





