EchoMimic | Animations de Portraits Dirigées par l'Audio
EchoMimic est un outil qui vous permet de créer des têtes parlantes réalistes et des gestes corporels qui se synchronisent parfaitement avec l'audio fourni. En exploitant des techniques avancées d'IA, EchoMimic analyse l'entrée audio et génère des expressions faciales réalistes, des mouvements des lèvres et un langage corporel qui correspondent parfaitement aux mots et émotions prononcés. Avec EchoMimic, vous pouvez donner vie à vos personnages et créer un contenu animé qui captive votre public.Flux de travail ComfyUI EchoMimic
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI EchoMimic
Description ComfyUI EchoMimic
EchoMimic est un outil pour générer des animations de portraits dirigées par l'audio de manière réaliste. Il utilise des techniques d'apprentissage profond pour analyser l'audio d'entrée et générer des expressions faciales, des mouvements des lèvres et des gestes de la tête qui correspondent étroitement au contenu émotionnel et phonétique du discours.
EchoMimic V2 a été développé par une équipe de chercheurs du Département de Technologie Terminale chez Alipay, Ant Group, comprenant Rang Meng, Xingyu Zhang, Yuming Li, et Chenguang Ma. Pour des informations détaillées, veuillez visiter /. Le nœud ComfyUI_EchoMimic a été développé par /. Tout le crédit revient à leur contribution significative.
EchoMimic V1 et V2
- EchoMimic V1 : Animations de Portraits Dirigées par l'Audio Réalistes avec Contrôle des Repères Personnalisable
- EchoMimic V2 : Animations Humaines Expressives et Semi-Corporelles Simplifiées
La principale différence est qu'EchoMimic V2 vise à réaliser une animation humaine mi-corps frappante tout en simplifiant les conditions de contrôle inutiles par rapport à EchoMimic V1. EchoMimic V2 utilise une stratégie novatrice d'Harmonisation Dynamique Audio-Posture pour améliorer les expressions faciales et les gestes corporels.
Forces et Faiblesses d'EchoMimic V2
Forces :
- EchoMimic V2 génère des animations de portraits très réalistes et expressives dirigées par l'audio
- EchoMimic V2 étend l'animation au haut du corps, pas seulement à la région de la tête
- EchoMimic V2 réduit la complexité des conditions tout en maintenant la qualité de l'animation par rapport à EchoMimic V1
- EchoMimic V2 intègre sans effort les données de portrait pour améliorer les expressions faciales
Faiblesses :
- EchoMimic V2 nécessite une source audio adaptée au portrait pour de meilleurs résultats
- EchoMimic V2 manque actuellement de code de synchronisation des poses, utilisant un fichier de pose par défaut
- Générer des animations longues et de haute qualité avec EchoMimic V2 peut être intensif en calcul
- EchoMimic V2 fonctionne mieux sur des images de portraits recadrées plutôt que des photos en pied
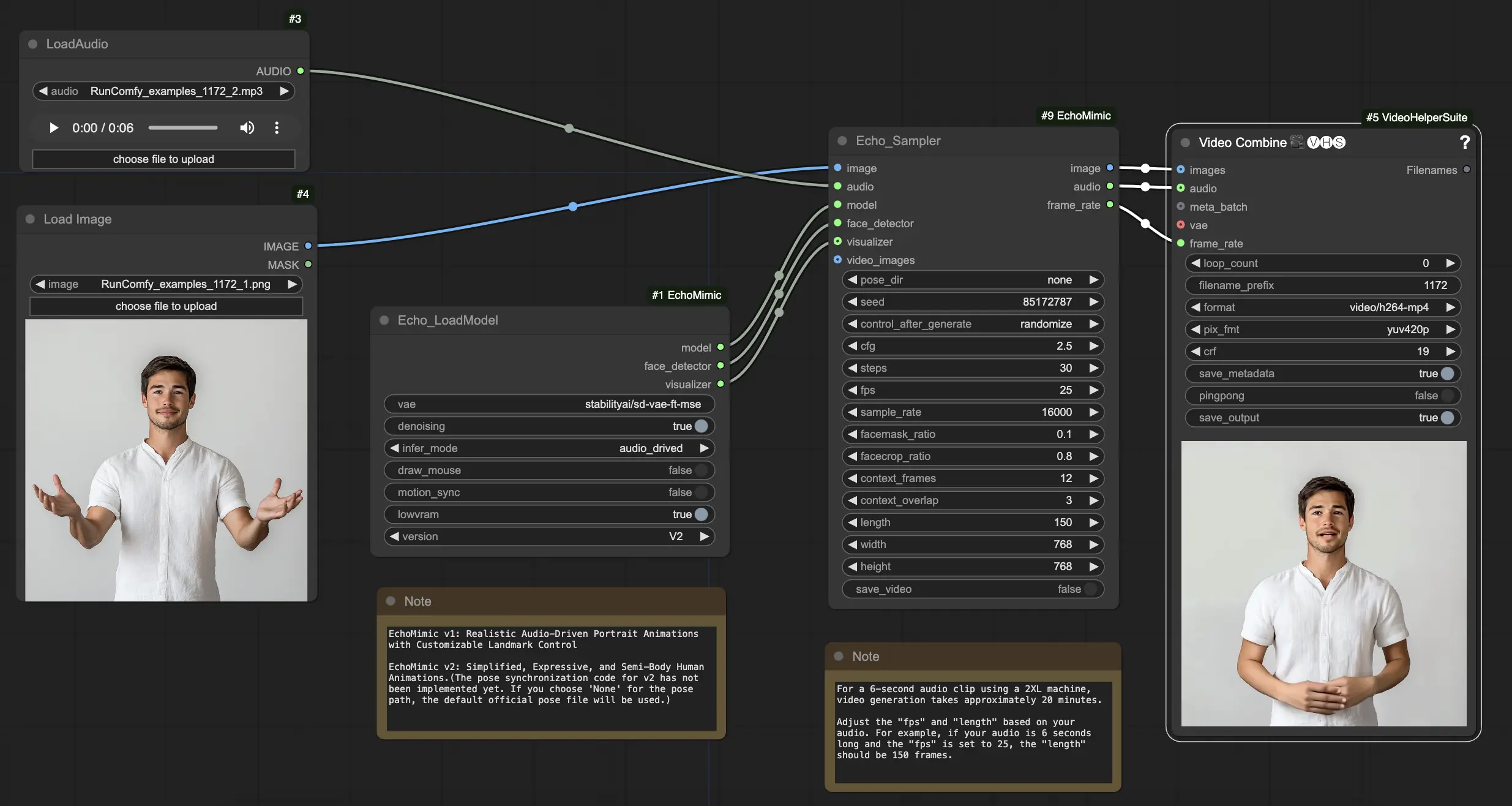
Comment Utiliser le Workflow ComfyUI EchoMimic
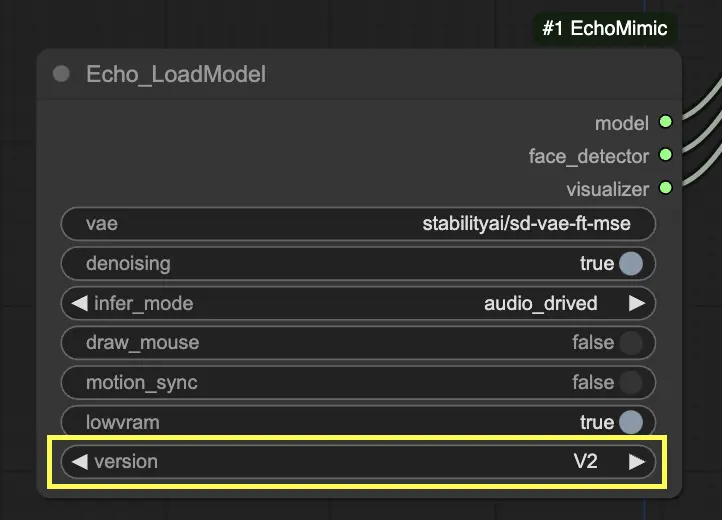
Dans le nœud "Echo_LoadModel", vous avez la possibilité de sélectionner entre EchoMimic v1 et EchoMimic v2 :
- EchoMimic v1 : Cette version se concentre sur la génération d'animations de portraits dirigées par l'audio réalistes avec la possibilité de personnaliser le contrôle des repères. Elle est bien adaptée pour créer des animations faciales réalistes qui correspondent étroitement à l'audio d'entrée.
- EchoMimic v2 : Cette version vise à simplifier le processus d'animation tout en offrant des animations humaines expressives et semi-corporelles. Elle étend l'animation au-delà de la région faciale pour inclure les mouvements du haut du corps. Cependant, veuillez noter que la fonction de synchronisation des poses pour v2 n'est pas encore implémentée dans la version actuelle du workflow ComfyUI. Si vous sélectionnez 'None' pour le chemin de pose, le fichier de pose officiel par défaut sera utilisé à la place.
Voici un guide étape par étape sur l'utilisation du workflow ComfyUI fourni :
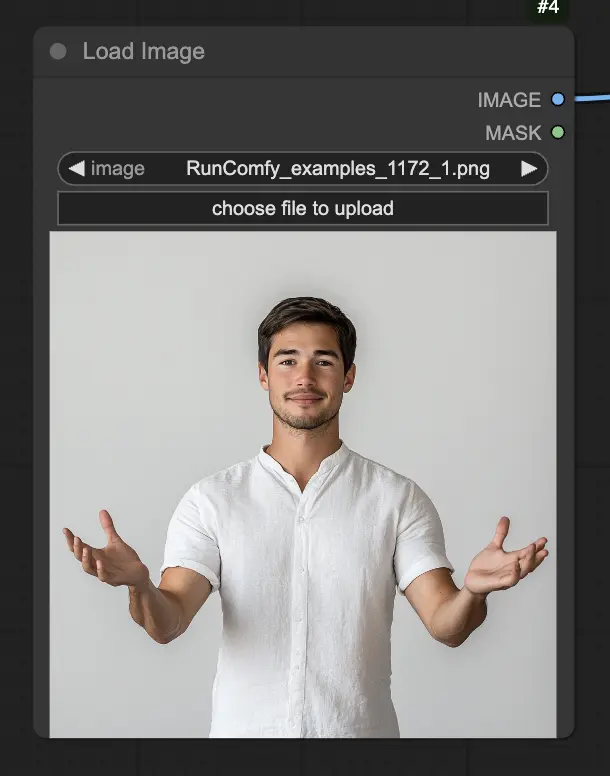
Étape 1. Chargez votre image de portrait en utilisant le nœud LoadImage. Cela devrait être une photo en gros plan de la tête et des épaules du sujet.
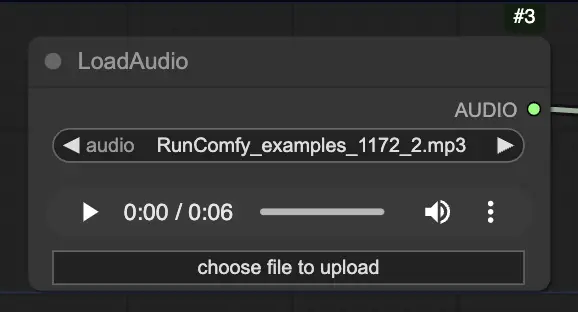
Étape 2. Chargez votre fichier audio en utilisant le nœud LoadAudio. Le discours dans l'audio doit correspondre à l'identité du sujet du portrait.
Étape 3. Utilisez le nœud Echo_LoadModel pour charger le modèle EchoMimic. Paramètres clés :
- Choisissez la version (V1 ou V2).
- Sélectionnez le mode d'inférence, par exemple le mode dirigé par l'audio.
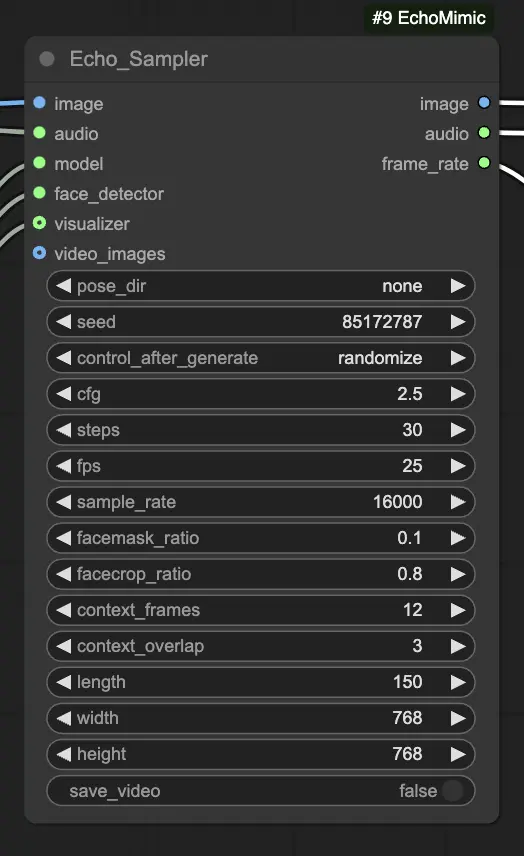
Étape 4. Connectez l'image, l'audio et le modèle chargé au nœud Echo_Sampler. Paramètres clés :
- pose_dir : Le chemin du répertoire pour les fichiers de séquence de poses utilisés dans les modes d'animation dirigés par les poses. Si réglé sur "none", aucune séquence de poses ne sera utilisée.
- seed : La graine aléatoire pour générer des résultats cohérents à travers les exécutions. Elle doit être un entier entre 0 et MAX_SEED.
- cfg : L'échelle de guidage sans classificateur, contrôlant l'intensité de la condition audio. Des valeurs plus élevées entraînent des mouvements plus prononcés dirigés par l'audio. La valeur par défaut est 2.5, et elle peut varier de 0.0 à 10.0.
- steps : Le nombre d'étapes de diffusion pour générer chaque image. Des valeurs plus élevées produisent des animations plus fluides mais prennent plus de temps à générer. La valeur par défaut est 30, et elle peut varier de 1 à 100.
- fps : Le taux de trame de la vidéo de sortie en images par seconde. La valeur par défaut est 25, et elle peut varier de 5 à 100.
- sample_rate : Le taux d'échantillonnage de l'audio d'entrée en Hz. La valeur par défaut est 16000, et elle peut varier de 8000 à 48000 par incréments de 1000.
- facemask_ratio : Le ratio de la zone du masque facial par rapport à la zone totale de l'image. Il contrôle la taille de la région autour du visage qui est animée. La valeur par défaut est 0.1, et elle peut varier de 0.0 à 1.0.
- facecrop_ratio : Le ratio de la zone de recadrage du visage par rapport à la zone totale de l'image. Il détermine combien de l'image est dédiée à la région du visage. La valeur par défaut est 0.8, et elle peut varier de 0.0 à 1.0.
- context_frames : Le nombre de cadres passés et futurs à utiliser comme contexte pour générer chaque image. La valeur par défaut est 12, et elle peut varier de 0 à 50.
- context_overlap : Le nombre de cadres qui se chevauchent entre les fenêtres de contexte adjacentes. La valeur par défaut est 3, et elle peut varier de 0 à 10.
- length : La durée de la vidéo de sortie en images. Elle doit être basée sur la durée de votre audio d'entrée et le paramètre fps. Par exemple, si votre audio dure 6 secondes et que le fps est réglé sur 25, la durée doit être de 150 images. La durée peut varier de 50 à 5000 images.
- width : La largeur des images vidéo de sortie en pixels. La valeur par défaut est 512, et elle peut varier de 128 à 1024 par incréments de 64.
- height : La hauteur des images vidéo de sortie en pixels. La valeur par défaut est 512, et elle peut varier de 128 à 1024 par incréments de 64.
Veuillez noter que la génération de vidéo peut prendre du temps. Par exemple, créer une vidéo à partir d'un clip audio de 6 secondes en utilisant une machine 2XL sur RunComfy prend environ 20 minutes.



