Hallo2 | Animation de portrait synchronisée sur les lèvres
Hallo2 est un modèle d'IA avancé qui génère des animations de portraits de haute qualité, synchronisées sur les lèvres et pilotées par des entrées audio. En utilisant des techniques telles que les modèles de diffusion, l'encodage audio et la détection de visage, Hallo2 crée des animations en 4K avec des mouvements de bouche et des expressions précisément synchronisés. Intégré de manière transparente dans le cadre ComfyUI, Hallo2 permet aux utilisateurs de créer des animations de portraits réalistes et synchronisées sur les lèvres.Flux de travail ComfyUI Hallo2 Lip-Sync
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Hallo2 Lip-Sync
Description ComfyUI Hallo2 Lip-Sync
La technique Hallo2 a été développée par Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu et Jingdong Wang de l'Université Fudan et Baidu Inc. Pour plus d'informations, visitez . Les nœuds et le flux de travail ComfyUI_Hallo2 ont été développés par smthemex. Pour plus de détails, visitez . Tous les crédits à leurs contributions.
1. À propos de Hallo2
Hallo2 est un modèle de pointe pour générer des vidéos d'animation de portraits pilotées par audio de haute qualité et de longue durée en résolution 4K. Il s'appuie sur le modèle original Hallo avec plusieurs améliorations clés :
- Prend en charge la génération de vidéos beaucoup plus longues, jusqu'à des dizaines de minutes ou même des heures
- Génère des vidéos en résolution 4K
- Permet de contrôler l'expression et la pose à l'aide de messages textuels en plus de l'audio
Hallo2 y parvient en utilisant des techniques avancées telles que l'augmentation de données pour maintenir la cohérence sur de longues durées, la quantification vectorielle des codes latents pour la résolution 4K et un processus de débruitage amélioré guidé à la fois par l'audio et le texte.
2. Caractéristiques techniques de Hallo2
Hallo2 combine plusieurs modèles et techniques avancés d'IA pour créer ses vidéos de portraits de haute qualité :
- Modèle de diffusion : Il s'agit du "moteur" principal qui génère les images vidéo. Il commence par un bruit aléatoire et le raffine progressivement pour correspondre au résultat souhaité, guidé par les messages audio et textuels.
- 3D U-Net : C'est un type de réseau neuronal qui agit comme le "sculpteur" dans le processus de diffusion. Il examine l'image bruyante actuelle, l'audio et les instructions textuelles, et suggère comment changer le bruit pour le rendre plus proche du portrait final.
- Encodeur audio : Hallo2 utilise un modèle appelé Wav2Vec2 comme ses "oreilles" pour comprendre l'audio, convertissant la forme d'onde brute en une représentation compacte qui capture le ton, la vitesse et le contenu du discours.
- Détecteur de visage : Pour l'aider à se concentrer sur l'animation du visage, Hallo2 utilise un modèle de détection de visage pour localiser automatiquement le visage du portrait dans l'image de référence. Il sait alors où appliquer les mouvements des lèvres et des expressions.
- Compresseur d'images : Pour travailler efficacement avec des images 4K haute résolution, Hallo2 utilise un type spécial de modèle d'autoencodeur (VQ-VAE) pour les compresser en une "représentation latente" plus petite, puis les décoder en 4K à la fin. C'est comme la façon dont les JPEG réduisent la taille des fichiers image tout en préservant la qualité.
- Trucs d'augmentation : Pour aider à maintenir la qualité sur de longues vidéos, Hallo2 applique quelques "augmentations de données" astucieuses aux images générées précédentes avant de les utiliser pour influencer l'image suivante. Cela inclut l'effacement occasionnel de patchs aléatoires ou l'ajout de bruit subtil. Cela aide à prévenir les erreurs cumulatives qui pourraient autrement s'accumuler et ruiner la cohérence au fil du temps.
En résumé - Hallo2 prend en entrée un audio et une image de portrait, dispose d'un "agent" IA qui sculpte des images vidéo pour les assortir tout en restant fidèle au portrait original, et emploie quelques astuces supplémentaires pour garder tout synchronisé et cohérent même dans les longues vidéos. Toutes ces parties travaillent ensemble dans un pipeline à étapes multiples pour produire les résultats impressionnants que vous voyez.
3. Comment utiliser le flux de travail ComfyUI Hallo2
Hallo2 a été intégré dans ComfyUI via un flux de travail personnalisé avec plusieurs nœuds spécialisés. Voici comment l'utiliser :
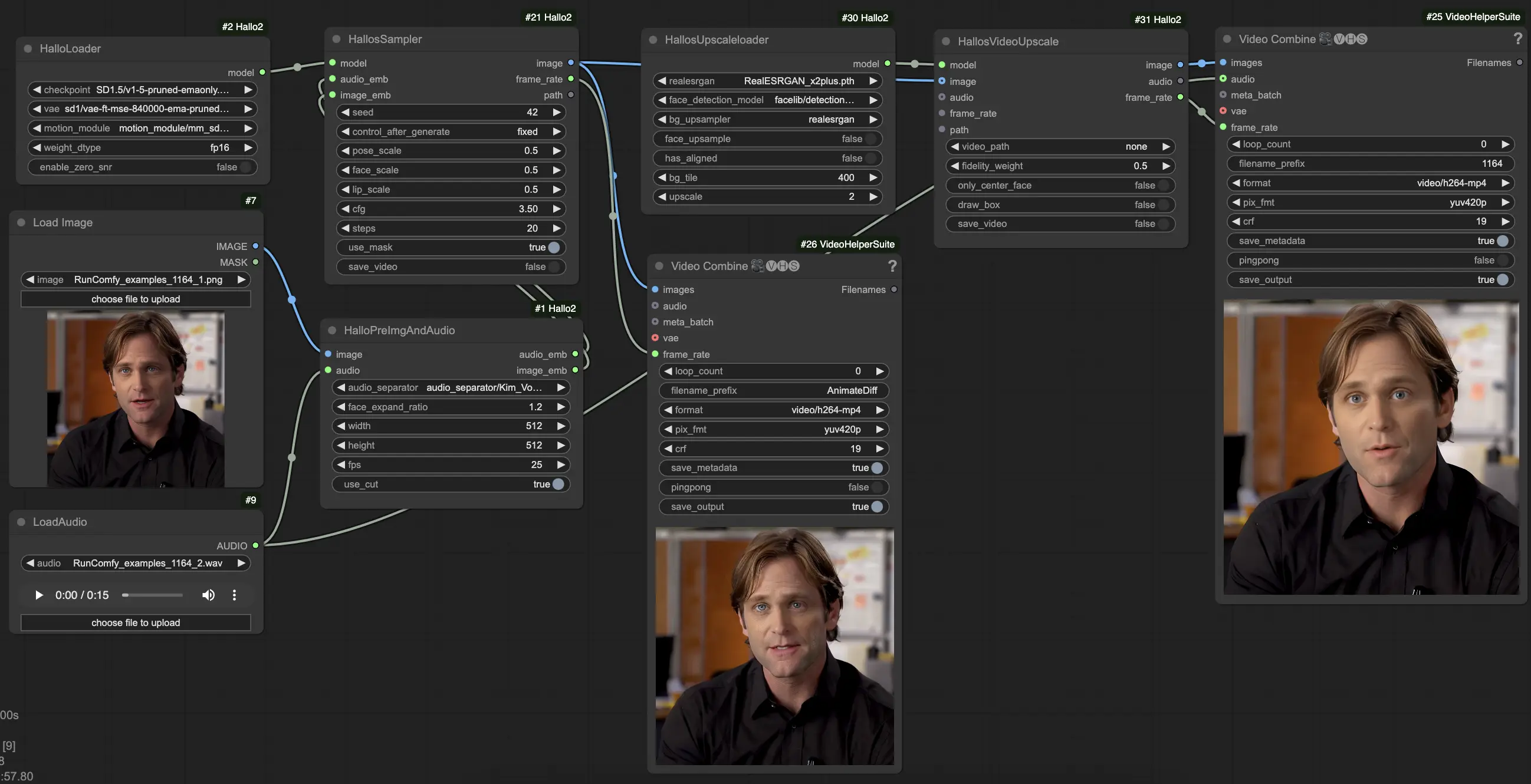
- Chargez votre image de portrait de référence en utilisant le nœud
LoadImage. Il doit s'agir d'un portrait clair de face. (Conseils : plus votre portrait de référence est bien cadré et éclairé, meilleurs seront les résultats. Évitez les profils latéraux, les occlusions, les arrière-plans chargés, etc.) - Chargez votre audio de conduite en utilisant le nœud
LoadAudio. Il doit correspondre à l'humeur que vous souhaitez que le portrait exprime. - Connectez l'image et l'audio au nœud
HalloPreImgAndAudio. Cela prétraite l'image et l'audio en incorporations. Paramètres clés :audio_separator: Modèle pour séparer la parole du bruit de fond. Laissez généralement par défaut.face_expand_ratio: Combien étendre la région du visage détectée. Des valeurs plus élevées incluent plus de cheveux/arrière-plan.width/height: Résolution de génération. Des valeurs plus élevées sont plus lentes mais plus détaillées. 512-1024 carré est un bon équilibre.fps: FPS vidéo cible. 25 est un bon défaut.
- Chargez le modèle Hallo2 principal en utilisant le nœud
HalloLoader. Pointez-le vers votre point de contrôle Hallo2, VAE, et fichiers de module de mouvement. - Connectez les incorporations d'image et d'audio prétraitées ainsi que le modèle chargé au nœud
HalloSampler. Cela effectue la génération vidéo réelle. Paramètres clés :seed: Graine aléatoire qui détermine les détails mineurs. Changez-la si vous n'aimez pas le premier résultat.pose_scale/face_scale/lip_scale: Combien échelle l'intensité des mouvements de pose, d'expression faciale et de lèvres. 1.0 = pleine intensité, 0.0 = gelé.cfg: Échelle de guidage sans classificateur. Plus élevé = suit plus étroitement le conditionnement mais est moins diversifié.steps: Nombre d'étapes de débruitage. Plus d'étapes = meilleure qualité mais plus lent.
- À ce stade, vous pouvez voir la vidéo générée. Pour améliorer encore la qualité avec la super-résolution, ajoutez les nœuds
HallosUpscaleloaderetHallosVideoUpscaleà la fin de la chaîne. Le chargeur d'upscaling lit un modèle d'upscaling préentraîné, tandis que le nœud d'upscaling effectue réellement l'upscaling en 4K.


