





ComfyUI FLUX : Guide d'installation, workflows tels que FLUX-ControlNet, FLUX-LoRA et FLUX-IPAdapter... et accès en ligne
Updated: 8/26/2024
Bonjour, chers passionnés d'IA ! 👋 Bienvenue dans notre guide d'introduction à l'utilisation de FLUX dans ComfyUI. FLUX est un modèle de pointe développé par Black Forest Labs. 🌟 Dans ce tutoriel, nous plongerons dans les bases de ComfyUI FLUX, en montrant comment ce puissant modèle peut améliorer votre processus créatif et vous aider à repousser les limites de l'art généré par l'IA. 🚀
Nous couvrirons :
1. Introduction à FLUX
2. Différentes versions de FLUX
3. Exigences matérielles de FLUX
- 3.1. Exigences matérielles de FLUX.1 [Pro]
- 3.2. Exigences matérielles de FLUX.1 [Dev]
- 3.3. Exigences matérielles de FLUX.1 [Schnell]
4. Comment installer FLUX dans ComfyUI
- 4.1. Installer ou mettre à jour ComfyUI
- 4.2. Télécharger les encodeurs de texte et modèles CLIP de ComfyUI FLUX
- 4.3. Télécharger le modèle VAE FLUX.1
- 4.4. Télécharger le modèle UNET FLUX.1
5. Workflow ComfyUI FLUX | Téléchargement, accès en ligne, et guide
- 5.1. Workflow ComfyUI : FLUX Txt2Img
- 5.2. Workflow ComfyUI : FLUX Img2Img
- 5.3. Workflow ComfyUI : FLUX LoRA
- 5.4. Workflow ComfyUI : FLUX ControlNet
- 5.5. Workflow ComfyUI : FLUX Inpainting
- 5.6. Workflow ComfyUI : FLUX NF4 & Upscale
- 5.7. Workflow ComfyUI : FLUX IPAdapter
- 5.8. Workflow ComfyUI : Flux LoRA Trainer
- 5.9. Workflow ComfyUI : Flux Latent Upscale
1. Introduction à FLUX
FLUX.1, le modèle d'IA de pointe de Black Forest Labs, révolutionne notre façon de créer des images à partir de descriptions textuelles. Avec sa capacité inégalée à générer des images incroyablement détaillées et complexes correspondant étroitement aux indications saisies, FLUX.1 se distingue de la concurrence. Le secret du succès de FLUX.1 réside dans son architecture hybride unique, qui combine différents types de blocs de transformateurs et est alimentée par un impressionnant nombre de 12 milliards de paramètres. Cela permet à FLUX.1 de produire des images visuellement captivantes qui représentent avec précision les descriptions textuelles avec une précision remarquable.
L'un des aspects les plus excitants de FLUX.1 est sa polyvalence à générer des images dans divers styles, du photoréaliste à l'artistique. FLUX.1 possède même la capacité remarquable d'incorporer harmonieusement du texte dans les images générées, un exploit que beaucoup d'autres modèles peinent à réaliser. De plus, FLUX.1 est réputé pour son adhérence exceptionnelle aux indications, gérant sans effort des descriptions simples comme complexes. Cela a conduit à des comparaisons fréquentes entre FLUX.1 et d'autres modèles bien connus comme Stable Diffusion et Midjourney, FLUX.1 étant souvent le choix préféré en raison de sa nature conviviale et de ses résultats de premier ordre.
Les capacités impressionnantes de FLUX.1 en font un outil inestimable pour une large gamme d'applications, de la création de contenu visuel époustouflant et l'inspiration de conceptions innovantes à la facilitation de la visualisation scientifique. La capacité de FLUX.1 à générer des images extrêmement détaillées et précises à partir de descriptions textuelles ouvre un monde de possibilités pour les professionnels créatifs, les chercheurs et les passionnés. Alors que le domaine de l'imagerie générée par IA continue d'évoluer, FLUX.1 se tient à la pointe, établissant une nouvelle norme de qualité, de polyvalence et de facilité d'utilisation.
Black Forest Labs, la société d'IA pionnière derrière le révolutionnaire FLUX.1, a été fondée par Robin Rombach, une figure renommée dans l'industrie de l'IA qui a précédemment été un membre clé de Stability AI. Si vous souhaitez en savoir plus sur Black Forest Labs et leur travail révolutionnaire avec FLUX.1, assurez-vous de visiter leur site officiel à https://blackforestlabs.ai/.

2. Différentes versions de FLUX
FLUX.1 est disponible en trois versions différentes, chacune conçue pour répondre aux besoins spécifiques des utilisateurs :
- FLUX.1 [pro] : C'est la version haut de gamme qui offre la meilleure qualité et performance, parfaite pour un usage professionnel et des projets de haute envergure.
- FLUX.1 [dev] : Optimisée pour un usage non commercial, cette version maintient une sortie de haute qualité tout en étant plus efficace, ce qui la rend idéale pour les développeurs et les passionnés.
- FLUX.1 [schnell] : Cette version est axée sur la vitesse et la légèreté, ce qui la rend parfaite pour le développement local et les projets personnels. Elle est également open-source et disponible sous la licence Apache 2.0, la rendant accessible à un large éventail d'utilisateurs.
| Nom | Répertoire HuggingFace | Licence | md5sum |
FLUX.1 [pro] | Seulement disponible dans notre API. | ||
FLUX.1 [dev] | https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev Non-Commercial License | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] | https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. Exigences matérielles de FLUX
3.1. FLUX.1 [Pro] Exigences matérielles
- GPU recommandé : NVIDIA RTX 4090 ou équivalent avec 24 Go ou plus de VRAM. Le modèle est optimisé pour les GPU haut de gamme pour gérer ses opérations complexes.
- RAM : 32 Go ou plus de mémoire système.
- Espace disque : Environ 30 Go.
- Exigences de calcul : Une haute précision est requise ; utilisez FP16 (demi-précision) pour éviter les erreurs de mémoire. Pour de meilleurs résultats, il est suggéré d'utiliser la variante du modèle
fp16Clip pour une qualité maximale. - Autres exigences : Un SSD rapide est recommandé pour des temps de chargement plus rapides et des performances globales.
3.2. FLUX.1 [Dev] Exigences matérielles
- GPU recommandé : NVIDIA RTX 3080/3090 ou équivalent avec au moins 16 Go de VRAM. Cette version est un peu plus tolérante en termes de matériel par rapport au modèle Pro mais nécessite toujours une puissance GPU substantielle.
- RAM : 16 Go ou plus de mémoire système.
- Espace disque : Environ 25 Go.
- Exigences de calcul : Similaire au Pro, utilisez des modèles FP16, mais avec une légère tolérance pour des calculs de précision inférieure. Peut utiliser des modèles Clip
fp16oufp8en fonction des capacités du GPU. - Autres exigences : Un SSD rapide est recommandé pour des performances optimales.
3.3. FLUX.1 [Schnell] Exigences matérielles
- GPU recommandé : NVIDIA RTX 3060/4060 ou équivalent avec 12 Go de VRAM. Cette version est optimisée pour une inférence plus rapide et des exigences matérielles réduites.
- RAM : 8 Go ou plus de mémoire système.
- Espace disque : Environ 15 Go.
- Exigences de calcul : Cette version est moins exigeante et permet des calculs
fp8en cas de manque de mémoire. Elle est conçue pour être rapide et efficace, en mettant l'accent sur la vitesse plutôt que sur la qualité ultra-élevée. - Autres exigences : Un SSD est utile mais pas aussi critique que dans les versions Pro et Dev.
4. Comment installer FLUX dans ComfyUI
4.1. Installer ou mettre à jour ComfyUI
Pour utiliser efficacement FLUX.1 dans l'environnement ComfyUI, il est crucial de s'assurer que vous avez la dernière version de ComfyUI installée. Cette version prend en charge les fonctionnalités et intégrations nécessaires pour les modèles FLUX.1.
4.2. Télécharger les encodeurs de texte et modèles CLIP de ComfyUI FLUX
Pour des performances optimales et une génération d'images précise à partir de texte en utilisant FLUX.1, vous devrez télécharger des encodeurs de texte spécifiques et des modèles CLIP. Les modèles suivants sont essentiels, en fonction du matériel de votre système :
| Nom du fichier du modèle | Taille | Remarque | Lien |
t5xxl_fp16.safetensors | 9.79 GB | Pour de meilleurs résultats, si vous avez une haute VRAM et RAM (plus de 32 Go de RAM). | Télécharger |
t5xxl_fp8_e4m3fn.safetensors | 4.89 GB | Pour une utilisation de mémoire réduite (8-12 Go) | Télécharger |
clip_l.safetensors | 246 MB | Télécharger |
Étapes pour télécharger et installer :
- Téléchargez le modèle
clip_l.safetensors. - En fonction de la VRAM et de la RAM de votre système, téléchargez soit
t5xxl_fp8_e4m3fn.safetensors(pour une VRAM inférieure) soitt5xxl_fp16.safetensors(pour une VRAM et RAM plus élevées). - Placez les modèles téléchargés dans le répertoire
ComfyUI/models/clip/. Remarque : Si vous avez déjà utilisé SD 3 Medium, vous pouvez déjà avoir ces modèles.
4.3. Télécharger le modèle VAE FLUX.1
Le modèle d'Autoencodeur Variationnel (VAE) est crucial pour améliorer la qualité de la génération d'images dans FLUX.1. Le modèle VAE suivant est disponible en téléchargement :
| Nom du fichier | Taille | Lien |
ae.safetensors | 335 MB | Télécharger(opens in a new tab) |
Étapes pour télécharger et installer :
- Téléchargez le fichier modèle
ae.safetensors. - Placez le fichier téléchargé dans le répertoire
ComfyUI/models/vae. - Pour une identification facile, il est recommandé de renommer le fichier en
flux_ae.safetensors.
4.4. Télécharger le modèle UNET FLUX.1
Le modèle UNET est l'épine dorsale de la synthèse d'images dans FLUX.1. En fonction des spécifications de votre système, vous pouvez choisir entre différentes variantes :
| Nom du fichier | Taille | Lien | Remarque |
flux1-dev.safetensors | 23.8GB | Télécharger | Si vous avez une haute VRAM et RAM. |
flux1-schnell.safetensors | 23.8GB | Télécharger | Pour une utilisation de mémoire réduite |
Étapes pour télécharger et installer :
- Téléchargez le modèle UNET approprié en fonction de la configuration mémoire de votre système.
- Placez le fichier modèle téléchargé dans le répertoire
ComfyUI/models/unet/.
5. Workflow ComfyUI FLUX | Téléchargement, accès en ligne, et guide
Nous mettrons continuellement à jour le Workflow ComfyUI FLUX pour vous fournir les workflows les plus récents et les plus complets pour générer des images époustouflantes en utilisant ComfyUI FLUX.
5.1. Workflow ComfyUI : FLUX Txt2Img
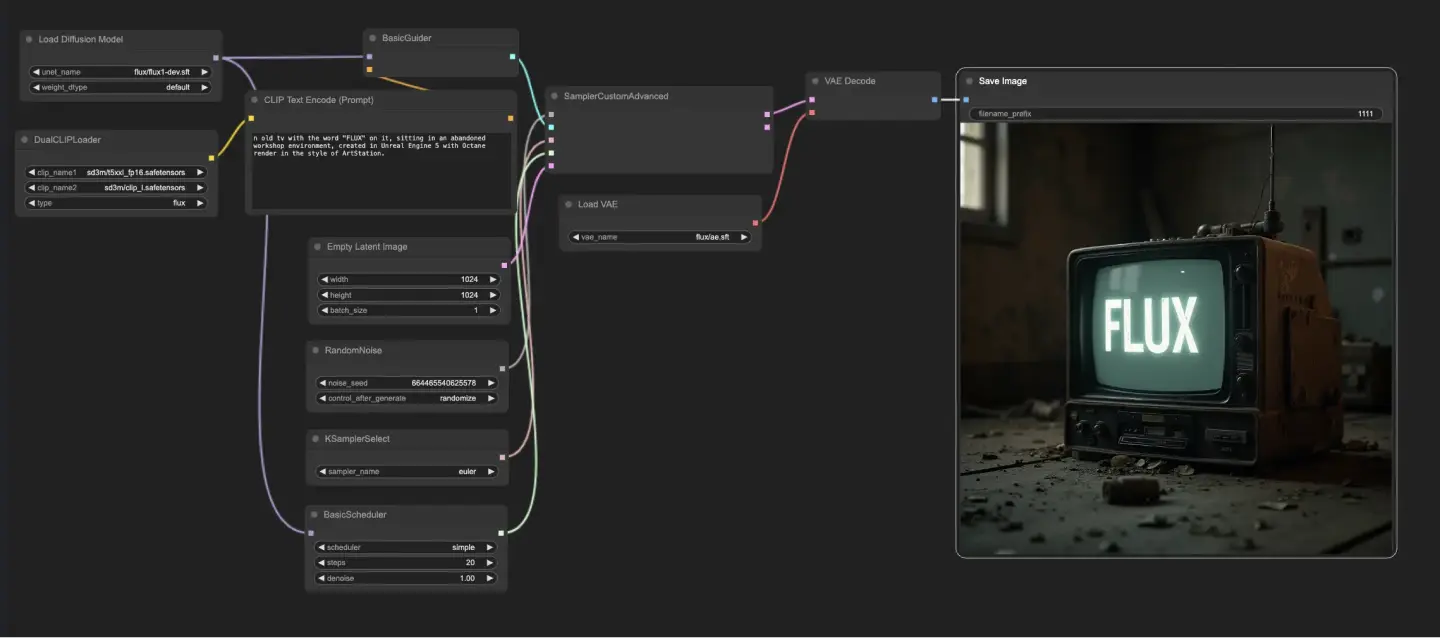
5.1.1. ComfyUI FLUX Txt2Img : Télécharger
5.1.2. Version en ligne de ComfyUI FLUX Txt2Img : ComfyUI FLUX Txt2Img
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX Txt2Img sans effort.
5.1.3. Explication de ComfyUI FLUX Txt2Img :
Le workflow ComfyUI FLUX Txt2Img commence par le chargement des composants essentiels, y compris le FLUX UNET (UNETLoader), le FLUX CLIP (DualCLIPLoader), et le FLUX VAE (VAELoader). Ceux-ci forment la base du processus de génération d'images ComfyUI FLUX.
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : flux/flux1-schnell.sft ; flux/flux1-dev.sft
- DualCLIPLoader : Charge le modèle CLIP pour l'encodage de texte.
- Modèle d'Embedding 1 : sd3m/t5xxl_fp8_e4m3fn.safetensors ; sd3m/t5xxl_fp16.safetensors
- Modèle d'Embedding 2 : sd3m/clip_g.safetensors ; sd3m/clip_l.safetensors
- Groupement : La stratégie de groupement pour le modèle CLIP est flux
- VAELoader : Charge le modèle d'Autoencodeur Variationnel (VAE) pour le décodage des représentations latentes.
- Modèle VAE : flux/ae.sft
L'invite de texte, qui décrit la sortie souhaitée, est encodée en utilisant le CLIPTextEncode. Ce nœud prend l'invite de texte comme entrée et produit l'encodage de texte conditionnant, qui guide ComfyUI FLUX pendant la génération.
Pour initier le processus de génération ComfyUI FLUX, une représentation latente vide est créée en utilisant le EmptyLatentImage. Cela sert de point de départ pour que ComfyUI FLUX puisse construire.
Le BasicGuider joue un rôle crucial en guidant le processus de génération ComfyUI FLUX. Il prend l'encodage de texte conditionnant et le FLUX UNET chargé comme entrées, assurant que la sortie générée correspond à la description textuelle fournie.
Le KSamplerSelect vous permet de choisir la méthode d'échantillonnage pour la génération ComfyUI FLUX, tandis que le RandomNoise génère du bruit aléatoire comme entrée pour ComfyUI FLUX. Le BasicScheduler planifie les niveaux de bruit (sigmas) pour chaque étape du processus de génération, contrôlant le niveau de détail et de clarté dans la sortie finale.
Le SamplerCustomAdvanced rassemble tous les composants du workflow ComfyUI FLUX Txt2Img. Il prend le bruit aléatoire, le guide, l'échantillonneur sélectionné, les sigmas planifiés, et la représentation latente vide comme entrées. Grâce à un processus d'échantillonnage avancé, il génère une représentation latente qui représente l'invite de texte.
Enfin, le VAEDecode décode la représentation latente générée en la sortie finale en utilisant le FLUX VAE chargé. Le SaveImage vous permet de sauvegarder la sortie générée à un emplacement spécifié, préservant la création époustouflante rendue possible par le workflow ComfyUI FLUX Txt2Img.
5.2. Workflow ComfyUI : FLUX Img2Img
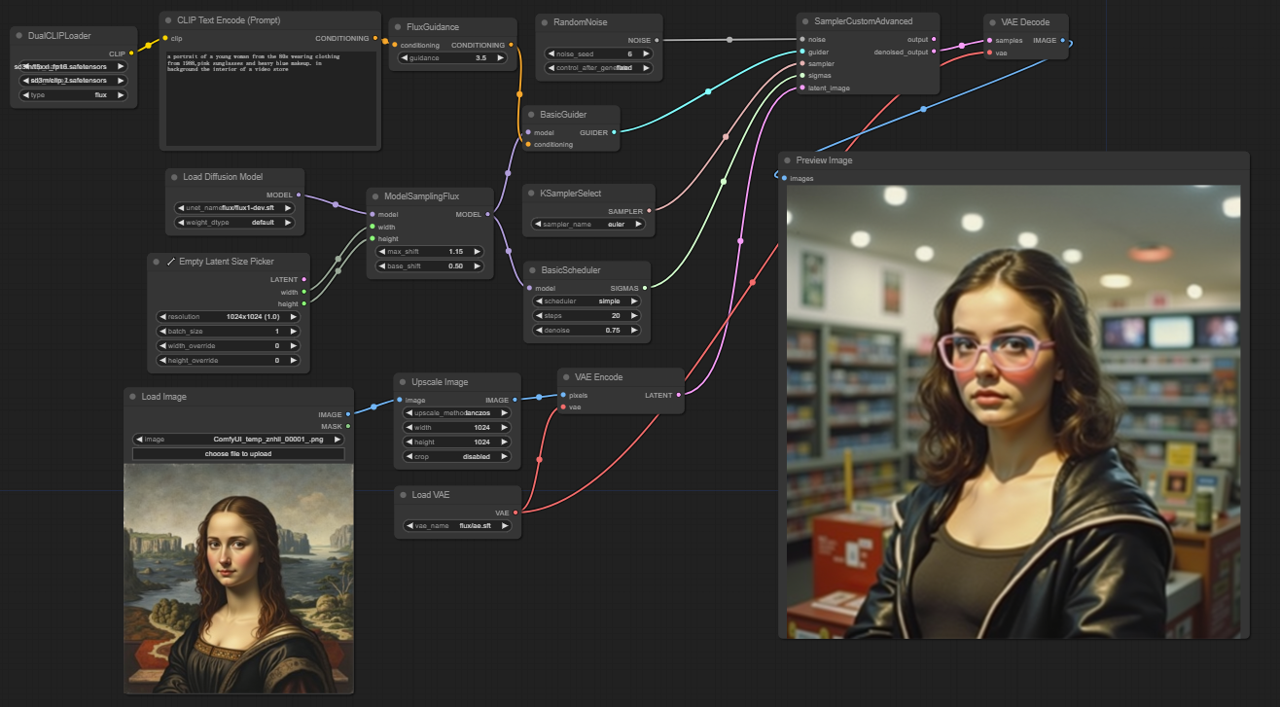
5.2.1. ComfyUI FLUX Img2Img : Télécharger
5.2.2. Version en ligne de ComfyUI FLUX Img2Img : ComfyUI FLUX Img2Img
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX Img2Img sans effort.
5.2.3. Explication de ComfyUI FLUX Img2Img :
Le workflow ComfyUI FLUX Img2Img s'appuie sur la puissance de ComfyUI FLUX pour générer des sorties basées à la fois sur les invites de texte et les représentations d'entrée. Il commence par le chargement des composants nécessaires, y compris le modèle CLIP (DualCLIPLoader), le modèle UNET (UNETLoader), et le modèle VAE (VAELoader).
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : flux/flux1-schnell.sft ; flux/flux1-dev.sft
- DualCLIPLoader : Charge le modèle CLIP pour l'encodage de texte.
- Modèle d'Embedding 1 : sd3m/t5xxl_fp8_e4m3fn.safetensors ; sd3m/t5xxl_fp16.safetensors
- Modèle d'Embedding 2 : sd3m/clip_g.safetensors ; sd3m/clip_l.safetensors
- Groupement : La stratégie de groupement pour le modèle CLIP est flux
- VAELoader : Charge le modèle d'Autoencodeur Variationnel (VAE) pour le décodage des représentations latentes.
- Modèle VAE : flux/ae.sft
La représentation d'entrée, qui sert de point de départ pour le processus ComfyUI FLUX Img2Img, est chargée en utilisant le LoadImage. Le ImageScale redimensionne ensuite la représentation d'entrée à la taille souhaitée, assurant la compatibilité avec ComfyUI FLUX.
La représentation d'entrée redimensionnée est encodée en utilisant le VAEEncode, la convertissant en une représentation latente. Cette représentation latente capture les caractéristiques et détails essentiels de l'entrée, fournissant une base pour que ComfyUI FLUX puisse travailler.
L'invite de texte, décrivant les modifications ou améliorations souhaitées de l'entrée, est encodée en utilisant le CLIPTextEncode. Le FluxGuidance applique ensuite une guidance au conditionnement basé sur l'échelle de guidance spécifiée, influençant la force de l'influence de l'invite de texte sur la sortie finale.
Le ModelSamplingFlux définit les paramètres d'échantillonnage pour ComfyUI FLUX, y compris le reéchantillonnage de l'étape de temps, le ratio de padding, et les dimensions de sortie. Ces paramètres contrôlent la granularité et la résolution de la sortie générée.
Le KSamplerSelect vous permet de choisir la méthode d'échantillonnage pour la génération ComfyUI FLUX, tandis que le BasicGuider guide le processus de génération basé sur l'encodage de texte conditionnant et le FLUX UNET chargé.
Le bruit aléatoire est généré en utilisant le RandomNoise, et le BasicScheduler planifie les niveaux de bruit (sigmas) pour chaque étape du processus de génération. Ces composants introduisent des variations contrôlées et affinent les détails dans la sortie finale.
Le SamplerCustomAdvanced rassemble le bruit aléatoire, le guide, l'échantillonneur sélectionné, les sigmas planifiés, et la représentation latente de l'entrée. Grâce à un processus d'échantillonnage avancé, il génère une représentation latente qui incorpore les modifications spécifiées par l'invite de texte tout en préservant les caractéristiques essentielles de l'entrée.
Enfin, le VAEDecode décode la représentation latente débruitée en la sortie finale en utilisant le FLUX VAE chargé. Le PreviewImage affiche un aperçu de la sortie générée, montrant les résultats impressionnants obtenus par le workflow ComfyUI FLUX Img2Img.
5.3. Workflow ComfyUI : FLUX LoRA
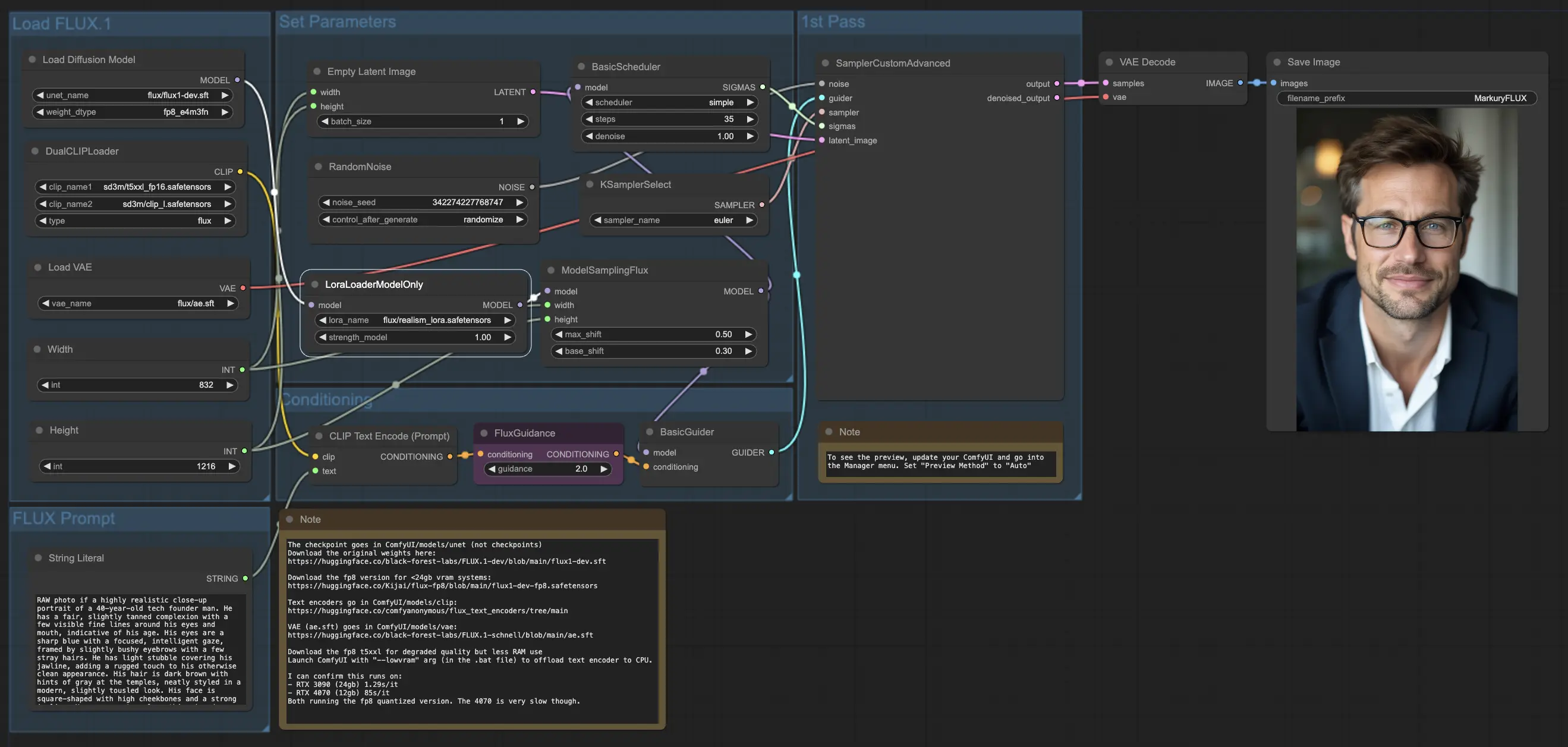
5.3.1. ComfyUI FLUX LoRA : Télécharger
5.3.2. Version en ligne de ComfyUI FLUX LoRA : ComfyUI FLUX LoRA
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX LoRA sans effort.
5.3.3. Explication de ComfyUI FLUX LoRA :
Le workflow ComfyUI FLUX LoRA exploite la puissance de l'Adaptation de Rang Inférieur (LoRA) pour améliorer les performances de ComfyUI FLUX. Il commence par le chargement des composants nécessaires, y compris le modèle UNET (UNETLoader), le modèle CLIP (DualCLIPLoader), le modèle VAE (VAELoader), et le modèle LoRA (LoraLoaderModelOnly).
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : flux/flux1-dev.sft
- DualCLIPLoader : Charge le modèle CLIP pour l'encodage de texte.
- Modèle d'Embedding 1 : sd3m/t5xxl_fp8_e4m3fn.safetensors ; sd3m/t5xxl_fp16.safetensors
- Modèle d'Embedding 2 : sd3m/clip_g.safetensors ; sd3m/clip_l.safetensors
- Groupement : La stratégie de groupement pour le modèle CLIP est flux
- VAELoader : Charge le modèle d'Autoencodeur Variationnel (VAE) pour le décodage des représentations latentes.
- Modèle VAE : flux/ae.sft
- LoraLoaderModelOnly : Charge le modèle LoRA (Adaptation de Rang Inférieur) pour améliorer le modèle UNET.
- Modèle de chargement : flux/realism_lora.safetensors
L'invite de texte, qui décrit la sortie souhaitée, est spécifiée en utilisant le StringLiteral. Le CLIPTextEncode encode ensuite l'invite de texte, générant l'encodage de texte conditionnant qui guide le processus de génération ComfyUI FLUX.
Le FluxGuidance applique une guidance au texte conditionnant encodé, influençant la force et la direction de l'adhérence de ComfyUI FLUX à l'invite de texte.
Une représentation latente vide, servant de point de départ pour la génération, est créée en utilisant le EmptyLatentImage. La largeur et la hauteur de la sortie générée sont spécifiées en utilisant le IntLiteral, assurant les dimensions souhaitées du résultat final.
Le ModelSamplingFlux définit les paramètres d'échantillonnage pour ComfyUI FLUX, y compris le ratio de padding et le reéchantillonnage de l'étape de temps. Ces paramètres contrôlent la résolution et la granularité de la sortie générée.
Le KSamplerSelect vous permet de choisir la méthode d'échantillonnage pour la génération ComfyUI FLUX, tandis que le BasicGuider guide le processus de génération basé sur l'encodage de texte conditionnant et le FLUX UNET chargé amélioré avec FLUX LoRA.
Le bruit aléatoire est généré en utilisant le RandomNoise, et le BasicScheduler planifie les niveaux de bruit (sigmas) pour chaque étape du processus de génération. Ces composants introduisent des variations contrôlées et affinent les détails dans la sortie finale.
Le SamplerCustomAdvanced rassemble le bruit aléatoire, le guide, l'échantillonneur sélectionné, les sigmas planifiés, et la représentation latente vide. Grâce à un processus d'échantillonnage avancé, il génère une représentation latente qui représente l'invite de texte, exploitant la puissance de FLUX et l'amélioration FLUX LoRA.
Enfin, le VAEDecode décode la représentation latente générée en la sortie finale en utilisant le FLUX VAE chargé. Le SaveImage vous permet de sauvegarder la sortie générée à un emplacement spécifié, préservant la création époustouflante rendue possible par le workflow ComfyUI FLUX LoRA.
5.4. Workflow ComfyUI : FLUX ControlNet
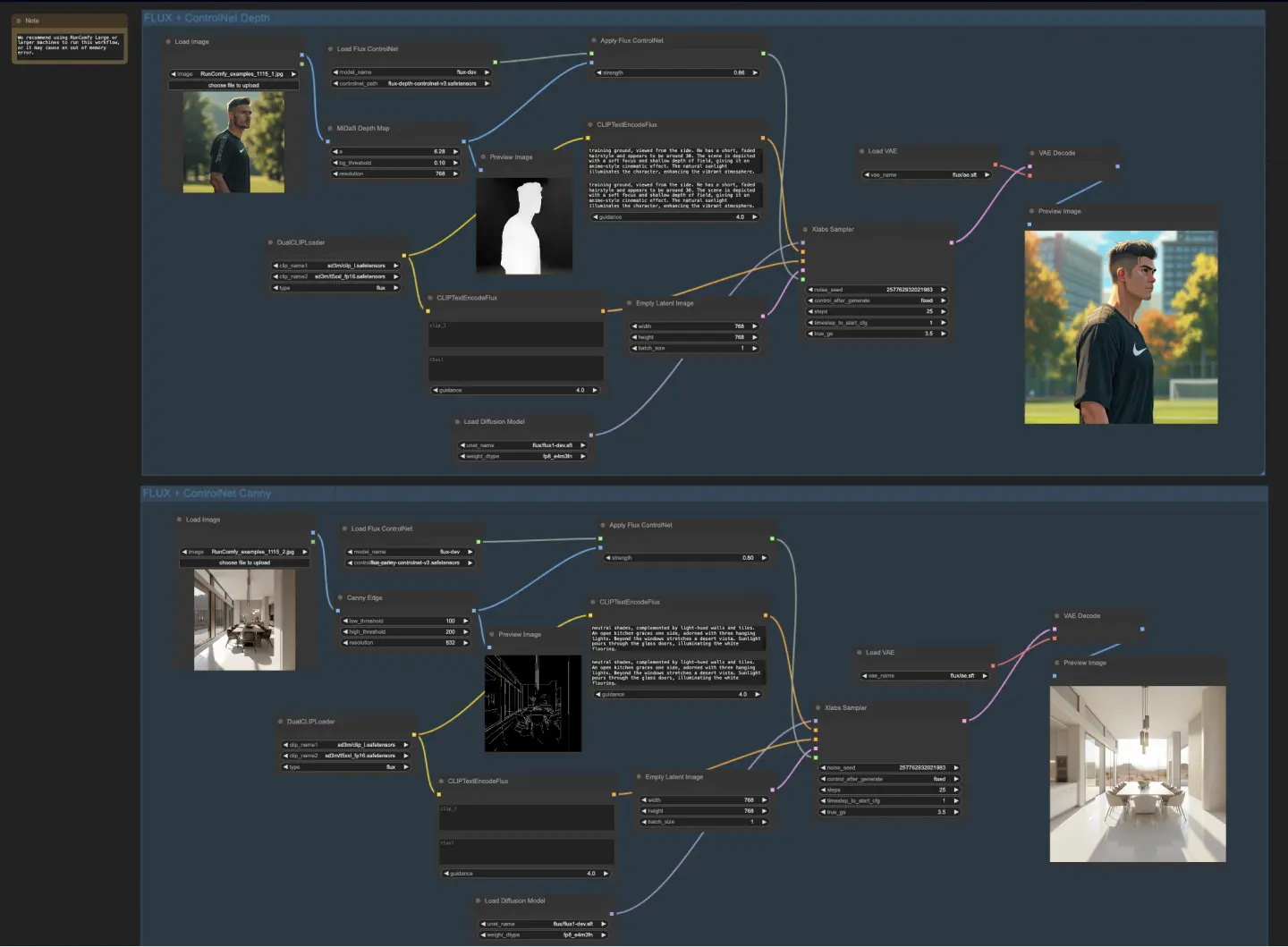
5.4.1. ComfyUI FLUX ControlNet : Télécharger
5.4.2. Version en ligne de ComfyUI FLUX ControlNet : ComfyUI FLUX ControlNet
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX ControlNet sans effort.
5.4.3. Explication de ComfyUI FLUX ControlNet :
Le workflow ComfyUI FLUX ControlNet démontre l'intégration de ControlNet avec ComfyUI FLUX pour une génération de sortie améliorée. Le workflow présente deux exemples : le conditionnement basé sur la profondeur et le conditionnement basé sur les bords de Canny.
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : flux/flux1-dev.sft
- DualCLIPLoader : Charge le modèle CLIP pour l'encodage de texte.
- Modèle d'Embedding 1 : sd3m/t5xxl_fp8_e4m3fn.safetensors ; sd3m/t5xxl_fp16.safetensors
- Modèle d'Embedding 2 : sd3m/clip_g.safetensors ; sd3m/clip_l.safetensors
- Groupement : La stratégie de groupement pour le modèle CLIP est flux
- VAELoader : Charge le modèle d'Autoencodeur Variationnel (VAE) pour le décodage des représentations latentes.
- Modèle VAE : flux/ae.sft
Dans le workflow basé sur la profondeur, la représentation d'entrée subit un prétraitement en utilisant le MiDaS-DepthMapPreprocessor, générant une carte de profondeur. La carte de profondeur est ensuite passée par l'ApplyFluxControlNet (Depth) avec le FLUX ControlNet chargé pour le conditionnement de profondeur. La condition FLUX ControlNet résultante sert d'entrée au XlabsSampler (Depth), avec le FLUX UNET chargé, l'encodage de texte conditionnant, l'encodage de texte négatif, et la représentation latente vide. Le XlabsSampler génère une représentation latente basée sur ces entrées, qui est ensuite décodée en la sortie finale en utilisant le VAEDecode.
- MiDaS-DepthMapPreprocessor (Depth) : Prétraite l'image d'entrée pour l'estimation de profondeur en utilisant MiDaS.
- LoadFluxControlNet : Charge le modèle ControlNet.
- Chemin : flux-depth-controlnet.safetensors
De même, dans le workflow basé sur les bords de Canny, la représentation d'entrée subit un prétraitement en utilisant le CannyEdgePreprocessor pour générer des bords de Canny. La représentation des bords de Canny est passée par l'ApplyFluxControlNet (Canny) avec le FLUX ControlNet chargé pour le conditionnement des bords de Canny. La condition FLUX ControlNet résultante sert d'entrée au XlabsSampler (Canny), avec le FLUX UNET chargé, l'encodage de texte conditionnant, l'encodage de texte négatif, et la représentation latente vide. Le XlabsSampler génère une représentation latente basée sur ces entrées, qui est ensuite décodée en la sortie finale en utilisant le VAEDecode.
- CannyEdgePreprocessor (Canny) : Prétraite l'image d'entrée pour la détection des bords de Canny.
- LoadFluxControlNet : Charge le modèle ControlNet.
- Chemin : flux-canny-controlnet.safetensors
Le workflow ComfyUI FLUX ControlNet incorpore des nœuds pour charger les composants nécessaires (DualCLIPLoader, UNETLoader, VAELoader, LoadFluxControlNet), encoder les invites de texte (CLIPTextEncodeFlux), créer des représentations latentes vides (EmptyLatentImage), et prévisualiser les sorties générées et prétraitées (PreviewImage).
En tirant parti de la puissance de FLUX ControlNet, le workflow ComfyUI FLUX ControlNet permet la génération de sorties qui s'alignent sur des conditionnements spécifiques, tels que des cartes de profondeur ou des bords de Canny. Ce niveau supplémentaire de contrôle et de guidance améliore la flexibilité et la précision du processus de génération, permettant la création de sorties époustouflantes et contextuellement pertinentes en utilisant ComfyUI FLUX.
5.5. Workflow ComfyUI : FLUX Inpainting
5.5.1. ComfyUI FLUX Inpainting : Télécharger
5.5.2. Version en ligne de ComfyUI FLUX Inpainting : ComfyUI FLUX Inpainting
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX Inpainting sans effort.
5.5.3. Explication de ComfyUI FLUX Inpainting :
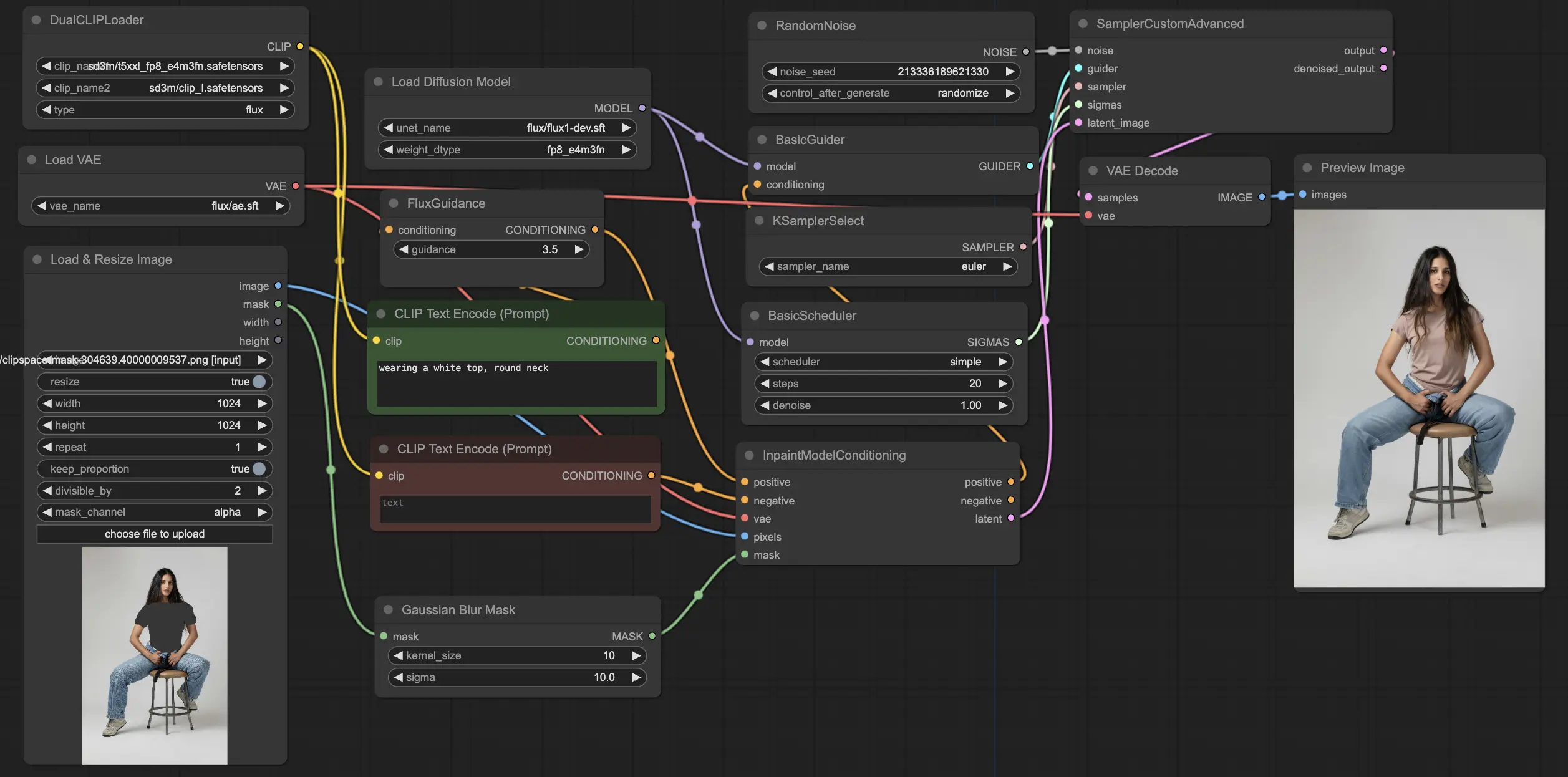
Le workflow ComfyUI FLUX Inpainting démontre la capacité de ComfyUI FLUX à effectuer de l'inpainting, ce qui implique de remplir des régions manquantes ou masquées d'une sortie en fonction du contexte environnant et des invites de texte fournies. Le workflow commence par le chargement des composants nécessaires, y compris le modèle UNET (UNETLoader), le modèle VAE (VAELoader), et le modèle CLIP (DualCLIPLoader).
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : flux/flux1-schnell.sft ; flux/flux1-dev.sft
- DualCLIPLoader : Charge le modèle CLIP pour l'encodage de texte.
- Modèle d'Embedding 1 : sd3m/t5xxl_fp8_e4m3fn.safetensors ; sd3m/t5xxl_fp16.safetensors
- Modèle d'Embedding 2 : sd3m/clip_g.safetensors ; sd3m/clip_l.safetensors
- Groupement : La stratégie de groupement pour le modèle CLIP est flux
- VAELoader : Charge le modèle d'Autoencodeur Variationnel (VAE) pour le décodage des représentations latentes.
- Modèle VAE : flux/ae.sft
Les invites de texte positives et négatives, qui décrivent le contenu et le style souhaités pour la région à repeindre, sont encodées en utilisant les CLIPTextEncodes. Le texte conditionnant positif est davantage guidé en utilisant le FluxGuidance pour influencer le processus d'inpainting de ComfyUI FLUX.
La représentation d'entrée et le masque sont chargés et redimensionnés en utilisant le LoadAndResizeImage, assurant la compatibilité avec les exigences de ComfyUI FLUX. Le ImpactGaussianBlurMask applique un flou gaussien au masque, créant une transition plus douce entre la région à repeindre et la représentation originale.
Le InpaintModelConditioning prépare le conditionnement pour l'inpainting FLUX en combinant le texte conditionnant positif guidé, le texte conditionnant négatif encodé, le FLUX VAE chargé, la représentation d'entrée chargée et redimensionnée, et le masque flouté. Ce conditionnement sert de base pour le processus d'inpainting ComfyUI FLUX.
Le bruit aléatoire est généré en utilisant le RandomNoise, et la méthode d'échantillonnage est sélectionnée en utilisant le KSamplerSelect. Le BasicScheduler planifie les niveaux de bruit (sigmas) pour le processus d'inpainting ComfyUI FLUX, contrôlant le niveau de détail et de clarté dans la région à repeindre.
Le BasicGuider guide le processus d'inpainting ComfyUI FLUX basé sur le conditionnement préparé et le FLUX UNET chargé. Le SamplerCustomAdvanced effectue le processus d'échantillonnage avancé, prenant le bruit aléatoire généré, le guide, l'échantillonneur sélectionné, les sigmas planifiés, et la représentation latente de l'entrée comme entrées. Il produit la représentation latente repeinte.
Enfin, le VAEDecode décode la représentation latente repeinte en la sortie finale, fusionnant harmonieusement la région repeinte avec la représentation originale. Le PreviewImage affiche la sortie finale, montrant les capacités impressionnantes d'inpainting de FLUX.
En tirant parti de la puissance de FLUX et du workflow d'inpainting soigneusement conçu, FLUX Inpainting permet la création de sorties repeintes visuellement cohérentes et contextuellement pertinentes. Que ce soit pour restaurer des parties manquantes, supprimer des objets indésirables, ou modifier des régions spécifiques, le workflow d'inpainting ComfyUI FLUX fournit un outil puissant pour l'édition et la manipulation.
5.6. Workflow ComfyUI : FLUX NF4
5.6.1. ComfyUI FLUX NF4 : Télécharger
5.6.2. Version en ligne de ComfyUI FLUX NF4 : ComfyUI FLUX NF4
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX NF4 sans effort.
5.6.3. Explication de ComfyUI FLUX NF4 :
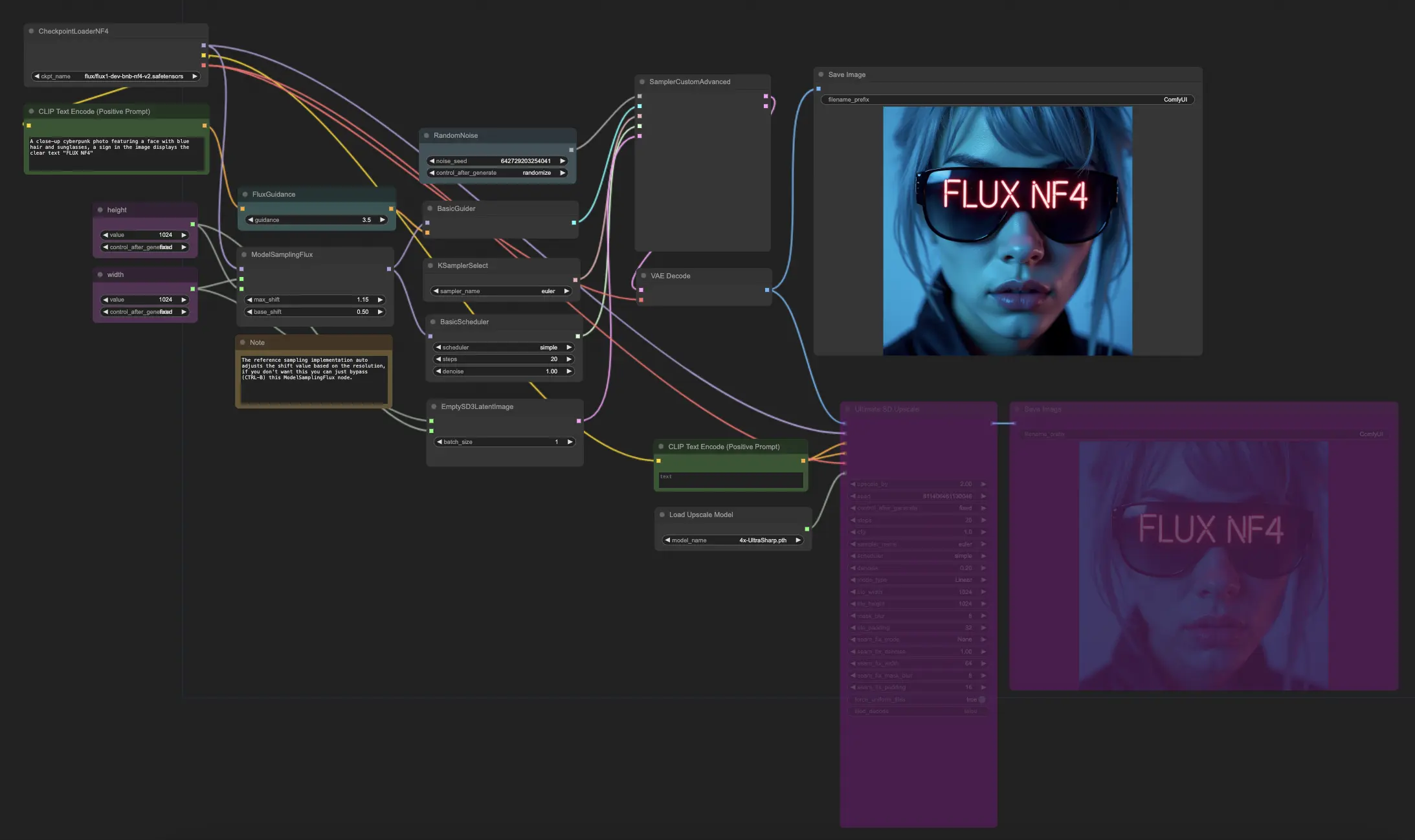
Le workflow ComfyUI FLUX NF4 présente l'intégration de ComfyUI FLUX avec l'architecture NF4 (Normalizing Flow 4) pour une génération de sorties de haute qualité. Le workflow commence par le chargement des composants nécessaires en utilisant le CheckpointLoaderNF4, qui inclut le FLUX UNET, le FLUX CLIP, et le FLUX VAE.
- UNETLoader : Charge le modèle UNET pour la génération d'images.
- Checkpoint : TBD
Les nœuds PrimitiveNode (height) et PrimitiveNode (width) spécifient la hauteur et la largeur souhaitées de la sortie générée. Le nœud ModelSamplingFlux définit les paramètres d'échantillonnage pour ComfyUI FLUX en fonction du FLUX UNET chargé et de la hauteur et largeur spécifiées.
Le nœud EmptySD3LatentImage crée une représentation latente vide en tant que point de départ pour la génération. Le nœud BasicScheduler planifie les niveaux de bruit (sigmas) pour le processus de génération ComfyUI FLUX.
Le nœud RandomNoise génère du bruit aléatoire pour le processus de génération ComfyUI FLUX. Le nœud BasicGuider guide le processus de génération basé sur le FLUX conditionné ComfyUI.
Le nœud KSamplerSelect sélectionne la méthode d'échantillonnage pour la génération ComfyUI FLUX. Le nœud SamplerCustomAdvanced effectue le processus d'échantillonnage avancé, prenant le bruit aléatoire généré, le guide, l'échantillonneur sélectionné, les sigmas planifiés, et la représentation latente vide comme entrées. Il produit la représentation latente générée.
Le nœud VAEDecode décode la représentation latente générée en la sortie finale en utilisant le FLUX VAE chargé. Le nœud SaveImage sauvegarde la sortie générée à un emplacement spécifié.
Pour le redimensionnement, le nœud UltimateSDUpscale est utilisé. Il prend la sortie générée, le FLUX chargé, le conditionnement positif et négatif pour le redimensionnement, le FLUX VAE chargé, et le redimensionnement FLUX chargé comme entrées. Le nœud CLIPTextEncode (Upscale Positive Prompt) encode l'invite de texte positive pour le redimensionnement. Le nœud UpscaleModelLoader charge le redimensionnement FLUX. Le nœud UltimateSDUpscale effectue le processus de redimensionnement et produit la représentation redimensionnée. Enfin, le nœud SaveImage (Upscaled) sauvegarde la sortie redimensionnée à un emplacement spécifié.
En tirant parti de la puissance de ComfyUI FLUX et de l'architecture NF4, le workflow ComfyUI FLUX NF4 permet la génération de sorties de haute qualité avec une fidélité et un réalisme améliorés. L'intégration transparente de ComfyUI FLUX avec l'architecture NF4 fournit un outil puissant pour créer des sorties époustouflantes et captivantes.
5.7. Workflow ComfyUI : FLUX IPAdapter
5.7.1. ComfyUI FLUX IPAdapter : Télécharger
5.7.2. Version en ligne de ComfyUI FLUX IPAdapter : ComfyUI FLUX IPAdapter
Sur la plateforme RunComfy, notre version en ligne précharge tous les modes et nœuds nécessaires pour vous. De plus, nous offrons des machines GPU haute performance, vous assurant de profiter de l'expérience ComfyUI FLUX IPAdapter sans effort.
5.7.3. Explication de ComfyUI FLUX IPAdapter :
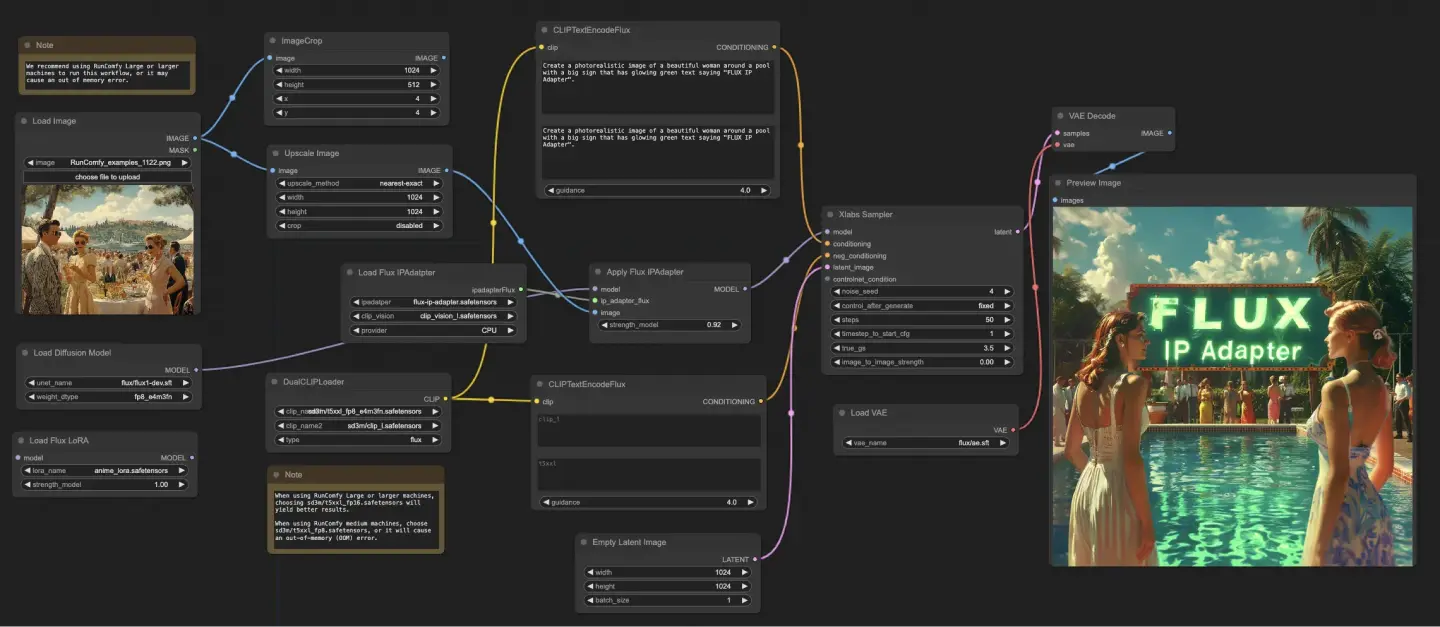
Le workflow ComfyUI FLUX IPAdapter commence par le chargement des modèles nécessaires, y compris le modèle UNET (UNETLoader), le modèle CLIP (DualCLIPLoader), et le modèle VAE (VAELoader).
Les invites de texte positives et négatives sont encodées en utilisant le CLIPTextEncodeFlux. Le texte conditionnant positif est utilisé pour guider le processus de génération ComfyUI FLUX.
L'image d'entrée est chargée en utilisant le LoadImage. Le LoadFluxIPAdapter charge l'IP-Adapter pour le modèle FLUX, qui est ensuite appliqué au modèle UNET chargé en utilisant l'ApplyFluxIPAdapter. Le ImageScale redimensionne l'image d'entrée à la taille souhaitée avant d'appliquer l'IP-Adapter.
- LoadFluxIPAdapter : Charge l'IP-Adapter pour le modèle FLUX.
- Modèle IP Adapter : flux-ip-adapter.safetensors
- Encodeur de vision CLIP : clip_vision_l.safetensors
Le EmptyLatentImage crée une représentation latente vide en tant que point de départ pour la génération ComfyUI FLUX.
Le XlabsSampler effectue le processus d'échantillonnage, prenant le FLUX UNET avec l'IP-Adapter appliqué, l'encodage de texte positif et négatif, et la représentation latente vide comme entrées. Il génère une représentation latente.
Le VAEDecode décode la représentation latente générée en la sortie finale en utilisant le FLUX VAE chargé. Le nœud PreviewImage affiche un aperçu de la sortie finale.
Le workflow ComfyUI FLUX IPAdapter tire parti de la puissance de ComfyUI FLUX et de l'IP-Adapter pour générer des sorties de haute qualité qui s'alignent sur les invites de texte fournies. En appliquant l'IP-Adapter au FLUX UNET, le workflow permet la génération de sorties qui capturent les caractéristiques et le style souhaités spécifiés dans le conditionnement de texte.
5.8. Workflow ComfyUI : Flux LoRA Trainer

5.8.1. ComfyUI FLUX LoRA Trainer : Télécharger
5.8.2. Explication de ComfyUI Flux LoRA Trainer :
Le workflow ComfyUI FLUX LoRA Trainer se compose de plusieurs étapes pour entraîner un LoRA en utilisant l'architecture FLUX dans ComfyUI.
Sélection et configuration de ComfyUI FLUX : Le nœud FluxTrainModelSelect est utilisé pour sélectionner les composants pour l'entraînement, y compris l'UNET, le VAE, le CLIP, et l'encodeur de texte CLIP. Le nœud OptimizerConfig configure les paramètres de l'optimiseur pour l'entraînement ComfyUI FLUX, tels que le type d'optimiseur, le taux d'apprentissage, et la décroissance du poids. Les nœuds TrainDatasetGeneralConfig et TrainDatasetAdd sont utilisés pour configurer le jeu de données d'entraînement, y compris la résolution, les paramètres d'augmentation, et les tailles de lot.
Initialisation de l'entraînement ComfyUI FLUX : Le nœud InitFluxLoRATraining initialise le processus d'entraînement LoRA en utilisant les composants sélectionnés, la configuration du jeu de données, et les paramètres de l'optimiseur. Le nœud FluxTrainValidationSettings configure les paramètres de validation pour l'entraînement, tels que le nombre d'échantillons de validation, la résolution, et la taille de lot.
Boucle d'entraînement ComfyUI FLUX : Le nœud FluxTrainLoop effectue la boucle d'entraînement pour le LoRA, itérant pour un nombre spécifié d'étapes. Après chaque boucle d'entraînement, le nœud FluxTrainValidate valide le LoRA entraîné en utilisant les paramètres de validation et génère des sorties de validation. Le nœud PreviewImage affiche un aperçu des résultats de validation. Le nœud FluxTrainSave sauvegarde le LoRA entraîné à des intervalles spécifiés.
Visualisation de la perte ComfyUI FLUX : Le nœud VisualizeLoss visualise laperte d'entraînement au cours de l'entraînement. Le nœud SaveImage sauvegarde le graphique de la perte pour une analyse ultérieure.
Traitement des sorties de validation ComfyUI FLUX : Les nœuds AddLabel et SomethingToString sont utilisés pour ajouter des étiquettes aux sorties de validation, indiquant les étapes d'entraînement. Les nœuds ImageBatchMulti et ImageConcatFromBatch combinent et concatènent les sorties de validation en un seul résultat pour une visualisation plus facile.
Finalisation de l'entraînement ComfyUI FLUX : Le nœud FluxTrainEnd finalise le processus d'entraînement LoRA et sauvegarde le LoRA entraîné. Le nœud UploadToHuggingFace peut être utilisé pour télécharger le LoRA entraîné sur Hugging Face pour le partage et une utilisation ultérieure avec ComfyUI FLUX.
5.9. Workflow ComfyUI : Flux Latent Upscaler
5.9.1. ComfyUI Flux Latent Upscaler : Télécharger
5.9.2. Explication de ComfyUI Flux Latent Upscaler :
Le workflow ComfyUI Flux Latent Upscale commence par le chargement des composants nécessaires, y compris le CLIP (DualCLIPLoader), l'UNET (UNETLoader), et le VAE (VAELoader). L'invite de texte est encodée en utilisant le nœud CLIPTextEncode, et la guidance est appliquée en utilisant le nœud FluxGuidance.
Le nœud SDXLEmptyLatentSizePicker+ spécifie la taille de la représentation latente vide, qui sert de point de départ pour le processus de redimensionnement dans FLUX. La représentation latente est ensuite traitée à travers une série d'étapes de redimensionnement et de recadrage en utilisant les nœuds LatentUpscale et LatentCrop.
Le processus de redimensionnement est guidé par le texte conditionnant encodé et utilise le nœud SamplerCustomAdvanced avec la méthode d'échantillonnage sélectionnée (KSamplerSelect) et les niveaux de bruit planifiés (BasicScheduler). Le nœud ModelSamplingFlux définit les paramètres d'échantillonnage.
La représentation latente redimensionnée est ensuite composée avec la représentation latente originale en utilisant le nœud LatentCompositeMasked et un masque généré par les nœuds SolidMask et FeatherMask. Le bruit est injecté dans la représentation latente redimensionnée en utilisant le nœud InjectLatentNoise+.
Enfin, la représentation latente redimensionnée est décodée en la sortie finale en utilisant le nœud VAEDecode, et un affûtage intelligent est appliqué en utilisant le nœud ImageSmartSharpen+. Le nœud PreviewImage affiche un aperçu de la sortie finale générée par ComfyUI FLUX.
Le workflow ComfyUI FLUX Latent Upscaler inclut également diverses opérations mathématiques en utilisant les nœuds SimpleMath+, SimpleMathFloat+, SimpleMathInt+, et SimpleMathPercent+ pour calculer les dimensions, ratios, et autres paramètres pour le processus de redimensionnement.