
Segment Anything V2, noto anche come SAM2, è un modello di intelligenza artificiale rivoluzionario sviluppato da Meta AI che rivoluziona la segmentazione degli oggetti sia in immagini che in video.
Cos'è Segment Anything V2 (SAM2)?#
Segment Anything V2 è un modello di intelligenza artificiale all'avanguardia che consente la segmentazione senza soluzione di continuità degli oggetti in immagini e video. È il primo modello unificato in grado di gestire compiti di segmentazione sia di immagini che di video con eccezionale accuratezza ed efficienza. Segment Anything V2 (SAM2) si basa sul successo del suo predecessore, il Segment Anything Model (SAM), estendendo le sue capacità di prompt ai video.
Con Segment Anything V2 (SAM2), gli utenti possono selezionare un oggetto in un'immagine o in un fotogramma video utilizzando vari metodi di input, come un clic, un riquadro di delimitazione o una maschera. Il modello segmenta quindi intelligentemente l'oggetto selezionato, consentendo l'estrazione e la manipolazione precise di elementi specifici all'interno del contenuto visivo.
Punti salienti di Segment Anything V2 (SAM2)#
- Prestazioni all'avanguardia: SAM2 supera i modelli esistenti nel campo della segmentazione degli oggetti sia per immagini che per video. Stabilisce un nuovo punto di riferimento per l'accuratezza e la precisione, superando le prestazioni del suo predecessore, SAM, nei compiti di segmentazione delle immagini.
- Modello unificato per immagini e video: SAM2 è il primo modello a fornire una soluzione unificata per la segmentazione degli oggetti sia in immagini che in video. Questa integrazione semplifica il flusso di lavoro per gli artisti AI, poiché possono utilizzare un unico modello per vari compiti di segmentazione.
- Capacità di segmentazione video migliorate: SAM2 eccelle nella segmentazione degli oggetti video, in particolare nel tracciamento delle parti degli oggetti. Supera i modelli di segmentazione video esistenti, offrendo una migliore accuratezza e coerenza nella segmentazione degli oggetti attraverso i fotogrammi.
- Riduzione del tempo di interazione: Rispetto ai metodi interattivi di segmentazione video esistenti, SAM2 richiede meno tempo di interazione da parte degli utenti. Questa efficienza consente agli artisti AI di concentrarsi maggiormente sulla loro visione creativa e di trascorrere meno tempo su compiti di segmentazione manuale.
- Design semplice e inferenza rapida: Nonostante le sue capacità avanzate, SAM2 mantiene un design architettonico semplice e offre velocità di inferenza rapide. Questo assicura che gli artisti AI possano integrare SAM2 nei loro flussi di lavoro senza compromettere le prestazioni o l'efficienza.
Come funziona Segment Anything V2 (SAM2)#
SAM2 estende la capacità di prompt di SAM ai video introducendo un modulo di memoria per sessione che cattura le informazioni sull'oggetto target, consentendo il tracciamento degli oggetti attraverso i fotogrammi, anche con scomparse temporanee. L'architettura di streaming elabora i fotogrammi video uno alla volta, comportandosi come SAM per le immagini quando il modulo di memoria è vuoto. Questo consente l'elaborazione video in tempo reale e la generalizzazione naturale delle capacità di SAM. SAM2 supporta anche le correzioni interattive della previsione della maschera basate sui prompt dell'utente. Il modello utilizza un'architettura a trasformatori con memoria di streaming ed è addestrato sul dataset SA-V, il più grande dataset di segmentazione video raccolto utilizzando un motore di dati model-in-the-loop che migliora sia il modello che i dati attraverso l'interazione dell'utente.
Come usare Segment Anything V2 (SAM2) in ComfyUI#
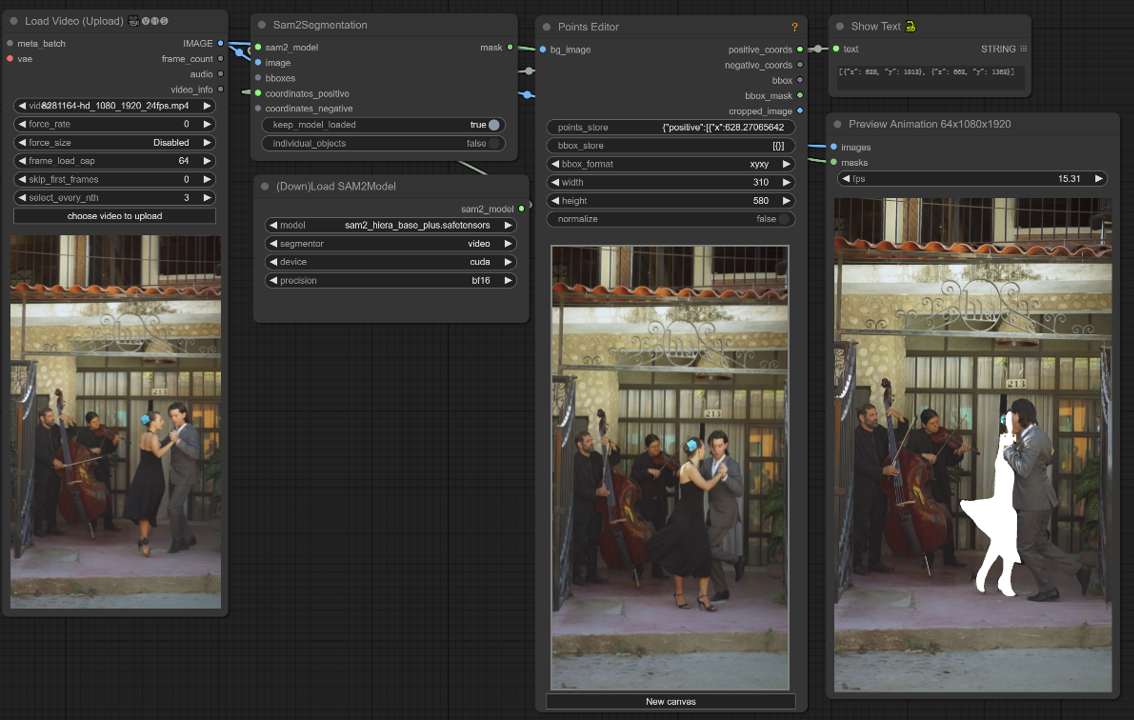
Questo flusso di lavoro ComfyUI supporta la selezione di un oggetto in un fotogramma video utilizzando un clic/punto.
1. Carica Video (Upload)#
Caricamento Video: Seleziona e carica il video che desideri elaborare.

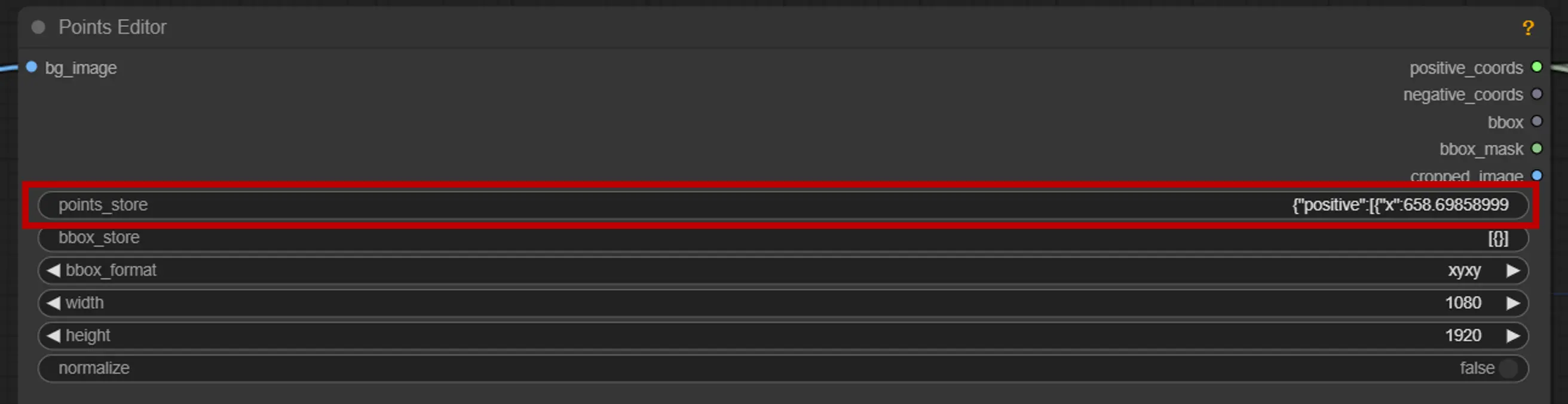
2. Editor di Punti#
Punto chiave: Posiziona tre punti chiave sulla tela—positive0, positive1 e negative0:
positive0 e positive1 segnano le regioni o gli oggetti che vuoi segmentare.
negative0 aiuta a escludere aree indesiderate o distrazioni.

points_store: Ti permette di aggiungere o rimuovere punti secondo necessità per affinare il processo di segmentazione.
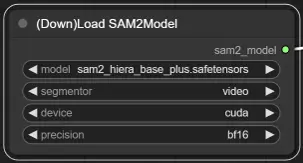
3. Selezione del Modello di SAM2#
Opzioni del Modello: Scegli tra i modelli SAM2 disponibili: tiny, small, large o base_plus. I modelli più grandi forniscono risultati migliori ma richiedono più tempo di caricamento.
Per ulteriori informazioni, visita Kijai ComfyUI-segment-anything-2.

