
LatentSync is a state-of-the-art end-to-end lip sync framework that harnesses the power of audio-conditioned latent diffusion models for realistic lip sync generation. What sets LatentSync apart is its ability to directly model the intricate correlations between audio and visual components without relying on any intermediate motion representation, revolutionizing the approach to lip sync synthesis.
At the core of LatentSync's pipeline is the integration of Stable Diffusion, a powerful generative model renowned for its exceptional ability to capture and generate high-quality images. By leveraging Stable Diffusion's capabilities, LatentSync can effectively learn and reproduce the complex dynamics between speech audio and corresponding lip movements, resulting in highly accurate and convincing lip sync animations.
One of the key challenges in diffusion-based lip sync methods is maintaining temporal consistency across generated frames, which is crucial for realistic results. LatentSync tackles this issue head-on with its groundbreaking Temporal REPresentation Alignment (TREPA) module, specifically designed to enhance the temporal coherence of lip sync animations. TREPA employs advanced techniques to extract temporal representations from the generated frames using large-scale self-supervised video models. By aligning these representations with the ground truth frames, LatentSync's framework ensures a high degree of temporal coherence, resulting in remarkably smooth and convincing lip sync animations that closely match the audio input.
1.1 How to Use LatentSync Workflow?#
Note: The LatentSync node has been updated to version 1.6 (latest version).
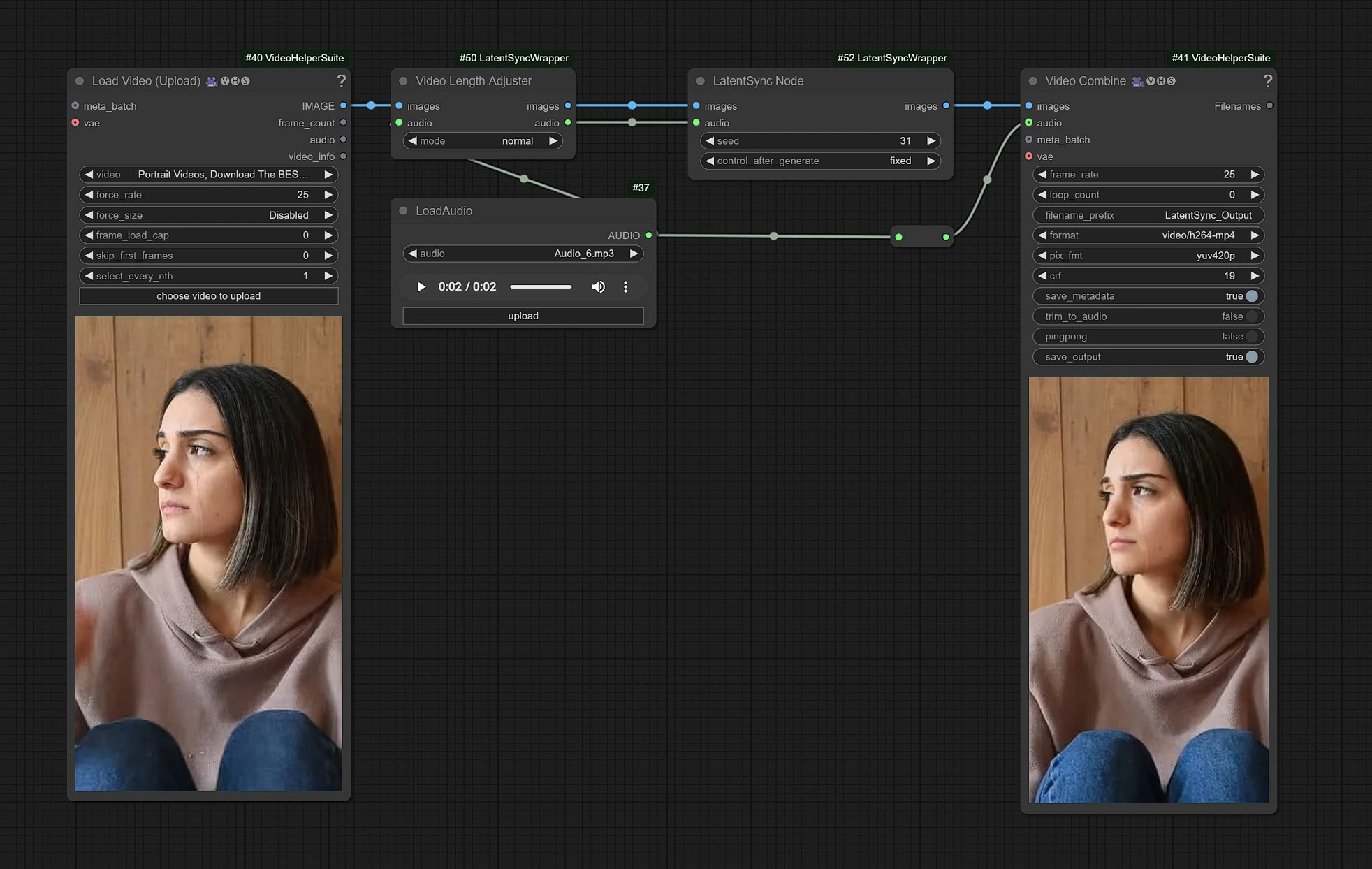
This is the LatentSync workflow, Left Side nodes are inputs for uploading video, Middle is processing LatentSync nodes, and right is the outputs node.
- Upload your Video in input nodes.
- Upload your Audio input of dialouges.
- Click Render !!!
1.2 Video Input#
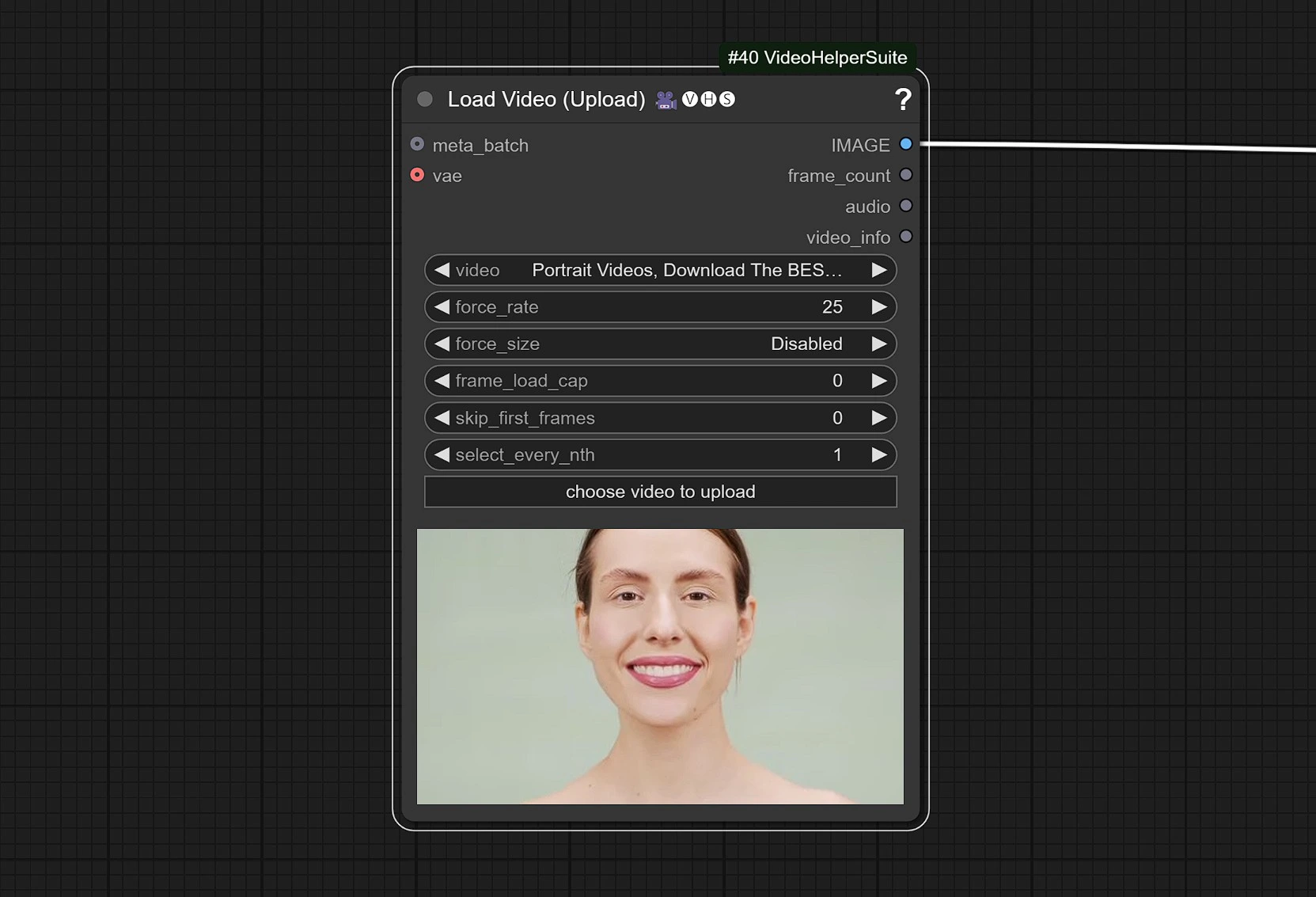
- Click and Upload your Reference Video which has face in it.
The video is adjusted to 25 FPS to sync properly with the Audio model
1.3 Audio Input#
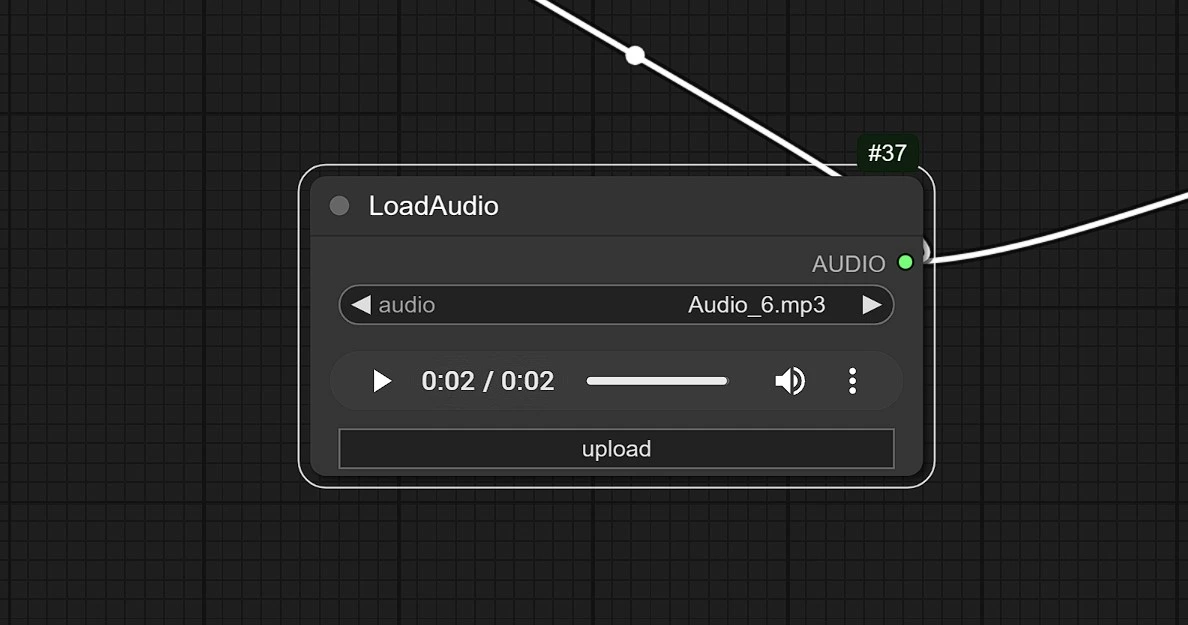
- Click and Upload your audio here.
LatentSync sets a new benchmark for lip sync with its innovative approach to audio-visual generation. By combining precision, temporal consistency, and the power of Stable Diffusion, LatentSync transforms the way we create synchronized content. Redefine what's possible in lip sync with LatentSync.