Mappe di profondità Z | Animazioni simili a quelle di Houdini
Scopri il potere di creare animazioni simili a quelle di Houdini utilizzando il workflow innovativo delle mappe di profondità Z di ComfyUI. Questo workflow di ComfyUI ti mostrerà come applicare manipolazioni di profondità e generare animazioni affascinanti utilizzando solo immagini 2D. Che tu sia un artista, un designer o un appassionato, sarai in grado di creare animazioni sorprendenti che sembrano realizzate con tecniche avanzate 3D, lavorando con la semplicità delle immagini 2D in ComfyUI.ComfyUI Z-Depth Maps Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Z-Depth Maps Esempi
ComfyUI Z-Depth Maps Descrizione
Hai mai desiderato creare sorprendenti animazioni simili a quelle di Houdini ma ti sei sentito intimidito dalla complessità del software 3D? Non cercare oltre! Questo workflow innovativo di ComfyUI ti guiderà attraverso il processo di applicazione delle manipolazioni di profondità (Z-Depth) e generazione di animazioni affascinanti utilizzando solo immagini 2D.
Che tu sia un artista, un designer o un appassionato, sarai in grado di generare animazioni sorprendenti che sembrano e si sentono come se fossero state create utilizzando tecniche avanzate 3D, lavorando con la semplicità e la facilità delle immagini 2D in ComfyUI.
Step 1: Creazione di un'immagine iniziale
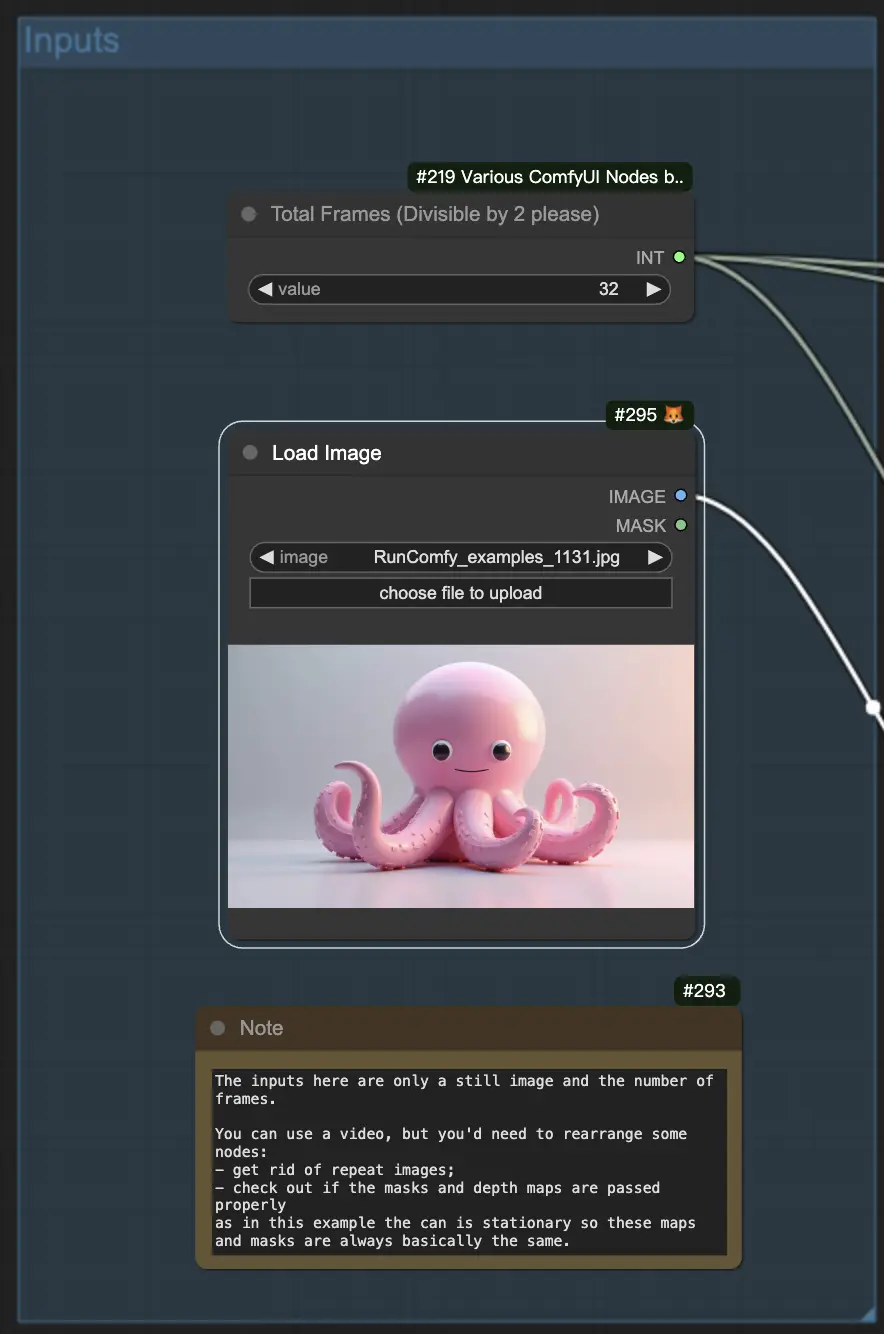
Per iniziare, dovrai generare un'immagine iniziale che servirà come base per la tua animazione. Una volta ottenuta l'immagine, ridimensionala a una dimensione più piccola, come 1 megapixel, per mantenere gestibile la dimensione del file.
Step 2: Creazione di un'animazione con maschera da una singola immagine
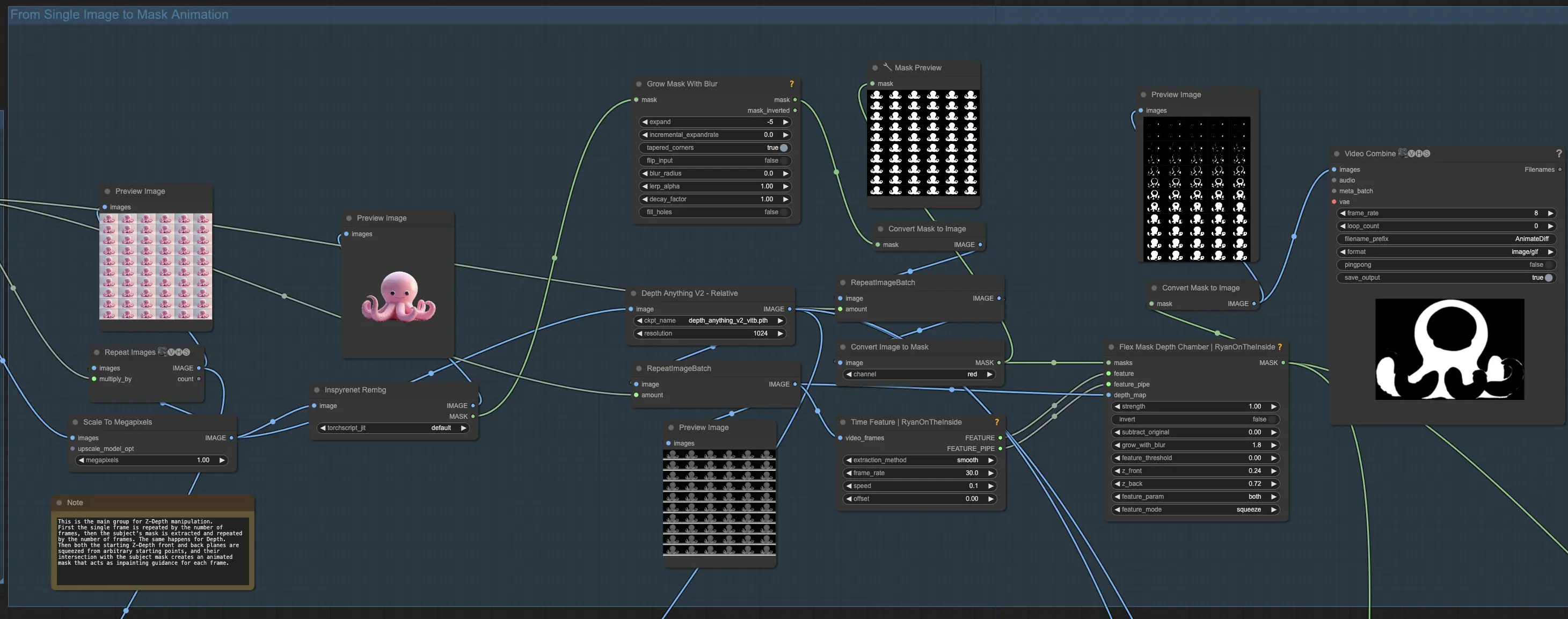
In questo passaggio, trasformerai la tua singola immagine in un'animazione con maschera. Inizia creando un video dalla tua singola immagine ripetendola per un numero desiderato di fotogrammi, ad esempio 32. Per isolare il tuo soggetto, rimuovi lo sfondo utilizzando un modello di rimozione dello sfondo come InSPyR-Net. Dopo aver rimosso lo sfondo, contrai leggermente la maschera risultante di alcuni pixel per assicurarti che funzioni bene con il processo di manipolazione della profondità.
Successivamente, estrai le informazioni di profondità dal tuo singolo fotogramma e collegale al controllo della profondità net. Ripeti l'immagine di profondità per lo stesso numero di fotogrammi del tuo video. Passa i fotogrammi di profondità ripetuti ai nodi Time Feature e Flex Mask Depth Chamber. Il nodo Time Feature guiderà l'animazione nel tempo con una velocità di fotogrammi fissa. Imposta il tempo dell'effetto su "smooth" e scegli un valore di velocità basso, come 0.1.
Le caratteristiche temporali controlleranno il taglio del tuo soggetto lungo l'asse della profondità Z. Regola la posizione iniziale dei piani Z-front e Z-back per iniziare l'azione a metà del tuo soggetto. Sposta entrambi i piani utilizzando il parametro "feature" con un movimento "squeeze" per creare l'effetto di taglio desiderato. Per migliorare l'effetto di diffusione differenziale e garantire transizioni più fluide, aggiungi una piccola quantità di sfocatura utilizzando l'impostazione "grow with blur".
Alla fine di questo passaggio, avrai convertito la tua singola immagine in un'animazione con maschera pronta per il processo di manipolazione della profondità e taglio. Questa animazione con maschera servirà come base per creare l'effetto simile a Houdini nei passaggi successivi del workflow.
Step 3: Generazione dell'animazione
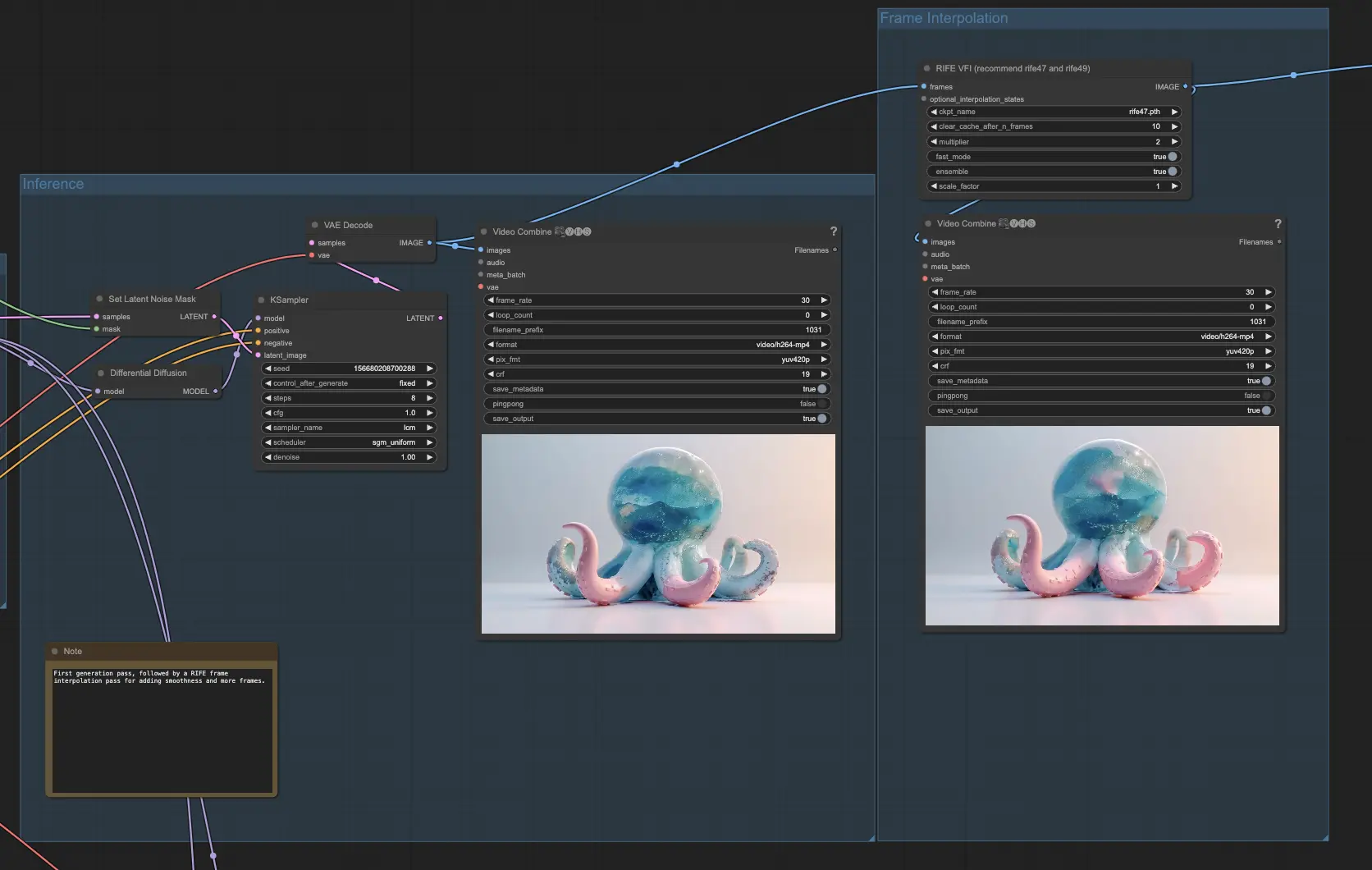
In questo passaggio, darai vita alla tua animazione generando fotogrammi utilizzando l'animazione con maschera preparata e le informazioni di profondità. Inizia caricando un checkpoint, come il checkpoint 1.5 per AnimateDiff, insieme a eventuali LoRAs desiderati per migliorare la qualità e lo stile dei fotogrammi generati.
Imposta un semplice passaggio di condizionamento con un prompt positivo che descriva la porzione della maschera risultante che verrà tagliata. Questo prompt guiderà il processo di generazione e aiuterà a mantenere la coerenza durante tutta l'animazione. Applica una profondità ControlNet basata sulla profondità del tuo soggetto originale per garantire che i fotogrammi generati mantengano le caratteristiche di profondità desiderate.
Se hai aree più grandi che necessitano di in-painting, puoi opzionalmente abilitare il gruppo IP Adapter per gestire meglio quelle regioni. Esegui l'inferenza con la Diffusione Differenziale e imposta la maschera del rumore latente. Codifica i 32 fotogrammi della tua immagine originale e manipola lo spazio latente con il rumore per ciascun fotogramma, ma solo nell'area bianca corrispondente che è stata tagliata.
Per migliorare ulteriormente la fluidità e la scorrevolezza della tua animazione, passa i fotogrammi risultanti attraverso un nodo RIFE (Real-Time Intermediate Flow Estimation) per l'interpolazione dei fotogrammi. Questo processo raddoppierà il numero di fotogrammi, rendendo effettivamente il tuo video più lungo e fluido. Interpolando tra i fotogrammi generati, RIFE aiuta a creare un'animazione più senza soluzione di continuità e visivamente accattivante.
Alla fine di questo passaggio, avrai generato un'animazione completa basata sulla tua immagine originale, le informazioni di profondità e l'animazione con maschera.
Step 4: Fusione di diverse animazioni (opzionale)
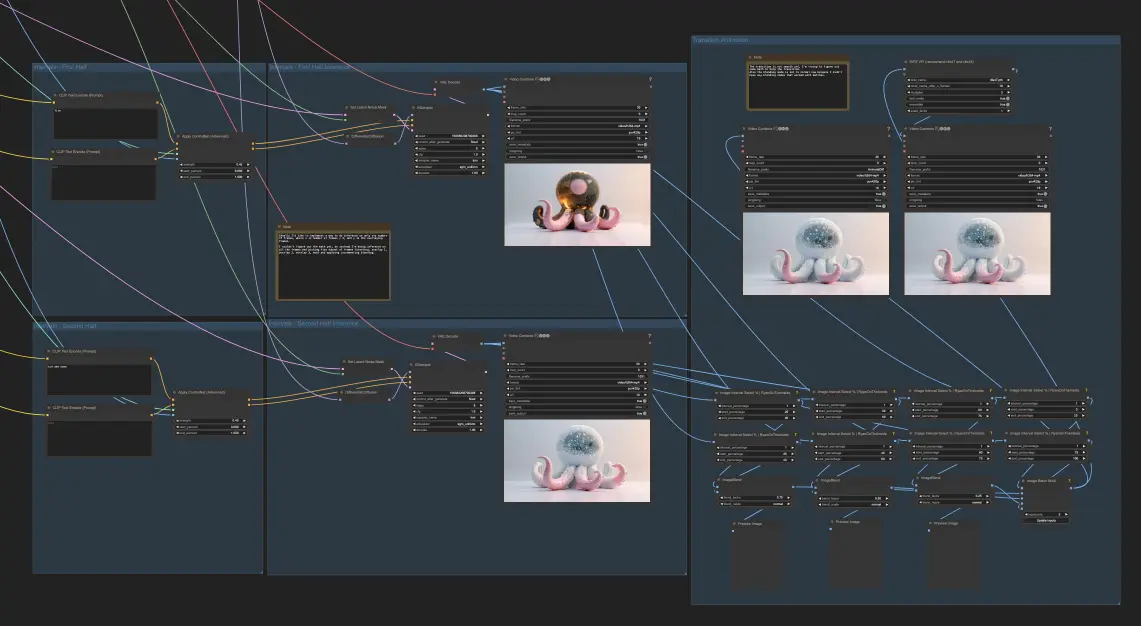
Se vuoi portare la tua animazione al livello successivo, puoi generare due diverse animazioni, come fuoco e ghiaccio, utilizzando lo stesso processo di prima ma con prompt diversi e ricondizionando la profondità. Dividi l'intervallo dell'immagine in cinque sezioni. Prendi il primo 25% di un'animazione e il restante 25% (dal 75% al 100%) dell'altra animazione come punti di partenza e di arrivo. Miscela i punti centrali (dal 25% al 40%, dal 40% al 60%, dal 60% al 75%) di entrambe le animazioni in modo che la fusione risultante inizi più come la prima animazione e diventi gradualmente più simile alla seconda animazione.



