Stable Diffusion 3.5
Stable Diffusion 3.5 (SD3.5) è un nuovo modello open-source che genera immagini diversificate e di alta qualità da prompt testuali. SD3.5 eccelle nella creazione di vari stili e nel rispettare i prompt. Nonostante alcune limitazioni in anatomia e risoluzione, SD3.5 è uno strumento potente per la creazione visiva. Esplora SD3.5 in ComfyUI per creare visuali sorprendenti con facilità.ComfyUI Stable Diffusion 3.5 Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Stable Diffusion 3.5 Esempi




ComfyUI Stable Diffusion 3.5 Descrizione
Stability AI ha presentato , un modello AI generativo multimodale open-source che include diverse varianti come Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo e Stable Diffusion 3.5 (SD3.5) Medium. Questi modelli sono altamente personalizzabili, in grado di funzionare su hardware consumer. I modelli SD3.5 Large e Large Turbo sono immediatamente disponibili, mentre la versione Medium sarà rilasciata il 29 ottobre 2024.
1. Come funziona Stable Diffusion 3.5 (SD3.5)
A livello tecnico, Stable Diffusion 3.5 (SD3.5) prende un prompt testuale come input, lo codifica in uno spazio latente usando encoder testuali basati su transformer, e poi decodifica quella rappresentazione latente in un'immagine di output usando un decoder basato su diffusione. Gli encoder testuali transformer, come il modello CLIP (Contrastive Language-Image Pre-training), mappano il prompt di input in una rappresentazione compressa semanticamente significativa nello spazio latente. Questo codice latente viene poi denoizzato iterativamente dal decoder di diffusione su più passaggi temporali per generare l'immagine finale di output. Il processo di diffusione coinvolge la rimozione graduale del rumore da una rappresentazione latente inizialmente rumorosa, condizionata sull'embedding testuale, fino a che emerge un'immagine pulita.
Le diverse dimensioni del modello in Stable Diffusion 3.5 (SD3.5) (Large, Medium) si riferiscono al numero di parametri addestrabili - 8 miliardi per il modello Large e 2,5 miliardi per il Medium. Più parametri generalmente consentono al modello di catturare più conoscenze e sfumature dai suoi dati di addestramento. I modelli Turbo sono versioni distillate che sacrificano un po' di qualità per velocità di inferenza molto più rapide. La distillazione comporta l'addestramento di un modello "studente" più piccolo per imitare gli output di un modello "insegnante" più grande, cercando di mantenere la maggior parte delle capacità in un'architettura più efficiente.
2. Punti di forza dei modelli Stable Diffusion 3.5 (SD3.5)
2.1. Personalizzabilità
I modelli Stable Diffusion 3.5 (SD3.5) sono progettati per essere facilmente ottimizzati e costruiti per applicazioni specifiche. La Query-Key Normalization è stata integrata nei blocchi transformer per stabilizzare l'addestramento e semplificare ulteriori sviluppi. Questa tecnica normalizza i punteggi di attenzione nei livelli transformer, il che può rendere il modello più robusto e più facile da adattare a nuovi set di dati tramite apprendimento di trasferimento.
2.2. Diversità degli Output
Stable Diffusion 3.5 (SD3.5) mira a generare immagini rappresentative della diversità del mondo senza la necessità di estesi prompt. Può raffigurare persone con tonalità di pelle, caratteristiche e estetiche diverse. Questo è probabilmente dovuto al modello addestrato su un ampio e diversificato set di dati di immagini provenienti da tutto il web.
2.3. Ampia Gamma di Stili
I modelli Stable Diffusion 3.5 (SD3.5) sono in grado di generare immagini in una vasta gamma di stili, tra cui rendering 3D, fotorealismo, pittura, arte lineare, anime e altro ancora. Questa versatilità li rende adatti a molti casi d'uso. La diversità di stile emerge dalla capacità del modello di diffusione di catturare molti diversi schemi visivi e estetiche nel suo spazio latente.
2.4. Forte Adesione ai Prompt
Specialmente per il modello Stable Diffusion 3.5 (SD3.5) Large, SD3.5 eccelle nel generare immagini che si allineano con il significato semantico dei prompt testuali di input. Si classifica altamente rispetto ad altri modelli sulle metriche di corrispondenza dei prompt. Questa capacità di tradurre accuratamente il testo in immagini è alimentata dalle capacità di comprensione linguistica dell'encoder testuale transformer.
3. Limitazioni e Svantaggi dei modelli Stable Diffusion 3.5 (SD3.5)
3.1. Difficoltà con Anatomia e Interazioni tra Oggetti
Come la maggior parte dei modelli testo-immagine, Stable Diffusion 3.5 (SD3.5) ha ancora difficoltà a rendere l'anatomia umana realistica, specialmente mani, piedi e volti in pose complesse. Le interazioni tra oggetti e mani sono spesso distorte. Questo è probabilmente dovuto alla sfida di apprendere tutte le sfumature delle relazioni spaziali 3D e della fisica da sole immagini 2D.
3.2. Risoluzione Limitata
Il modello Stable Diffusion 3.5 (SD3.5) Large è ideale per immagini da 1 megapixel (1024x1024), mentre il Medium raggiunge al massimo circa 2 megapixel. Generare immagini coerenti a risoluzioni più elevate è una sfida per SD3.5. Questa limitazione deriva dai vincoli computazionali e di memoria dell'architettura di diffusione.
3.3. Glitch e Allucinazioni Occasionali
Poiché i modelli Stable Diffusion 3.5 (SD3.5) consentono un'ampia diversità di output dallo stesso prompt con diversi semi casuali, ci può essere una certa imprevedibilità. Prompt che mancano di specificità possono portare alla comparsa di elementi glitch o inaspettati. Questa è una proprietà intrinseca del processo di campionamento di diffusione, che coinvolge casualità.
3.4. Non Raggiunge il Taglio all'Avanguardia Assoluto
Secondo alcuni primi test, in termini di qualità e coerenza dell'immagine, Stable Diffusion 3.5 (SD3.5) non corrisponde attualmente alle prestazioni dei modelli testo-immagine all'avanguardia come Midjourney. E i primi confronti tra Stable Diffusion 3.5 (SD3.5) e FLUX.1 rivelano che ciascun modello eccelle in aree diverse. Mentre FLUX.1 sembra avere un vantaggio nella produzione di immagini fotorealistiche, SD3.5 Large ha una maggiore competenza nella generazione di opere d'arte in stile anime senza richiedere ulteriori ottimizzazioni o modifiche.
4. Stable Diffusion 3.5 in ComfyUI
Da RunComfy, abbiamo reso facile per te iniziare a utilizzare i modelli Stable Diffusion 3.5 (SD3.5) precaricandoli per tua comodità. Puoi iniziare subito ed eseguire inferenze utilizzando il flusso di lavoro di esempio
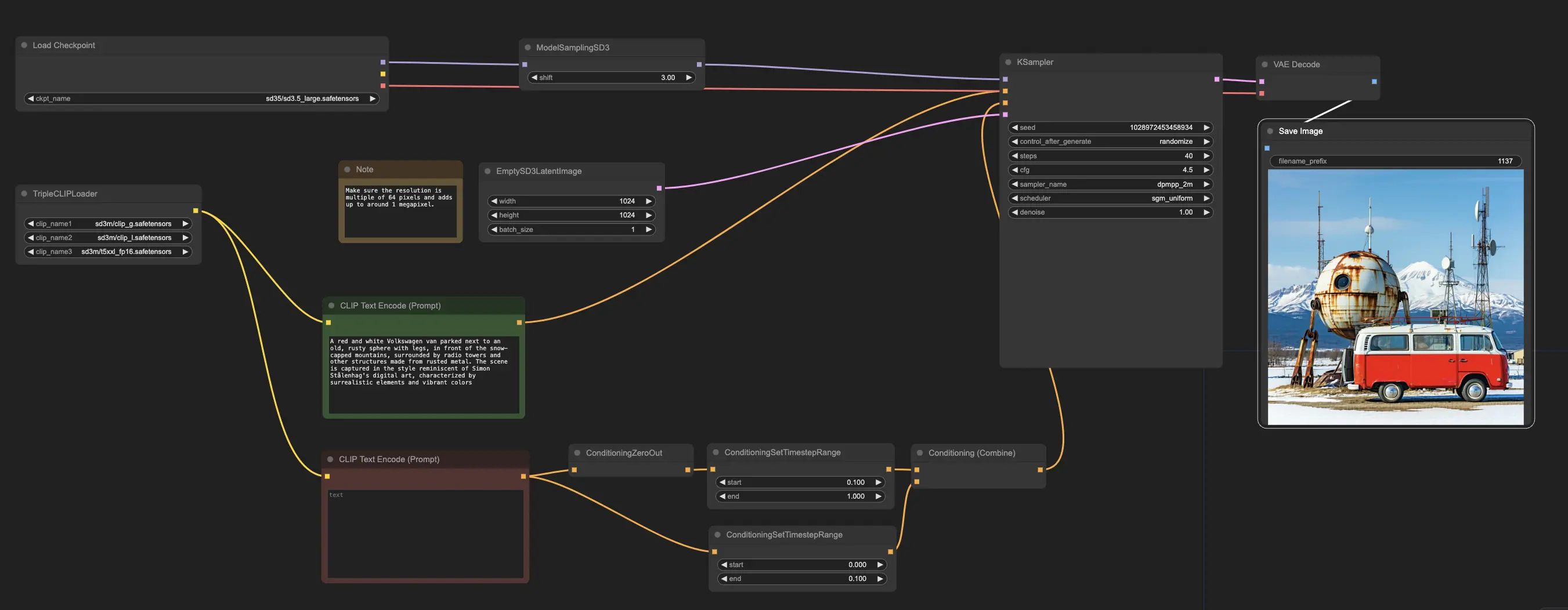
Il flusso di lavoro di esempio inizia con il nodo CheckpointLoaderSimple, che carica il modello pre-addestrato Stable Diffusion 3.5 Large. E per aiutarti a tradurre i tuoi prompt testuali in un formato che il modello può comprendere, il nodo TripleCLIPLoader viene utilizzato per caricare gli encoder corrispondenti. Questi encoder sono fondamentali per guidare il processo di generazione delle immagini in base al testo che fornisci.
Il nodo EmptySD3LatentImage crea quindi una tela vuota con le dimensioni specificate, tipicamente 1024x1024 pixel, che serve come punto di partenza per il modello per generare l'immagine. I nodi CLIPTextEncode elaborano i prompt testuali che fornisci, utilizzando gli encoder caricati per creare un insieme di istruzioni che il modello deve seguire.
Prima che queste istruzioni siano inviate al modello, subiscono un ulteriore affinamento attraverso i nodi ConditioningCombine, ConditioningZeroOut e ConditioningSetTimestepRange. Questi nodi rimuovono l'influenza di eventuali prompt negativi, specificano quando i prompt dovrebbero essere applicati durante il processo di generazione e combinano le istruzioni in un unico insieme coerente.
Infine, puoi ottimizzare il processo di generazione delle immagini usando il nodo ModelSamplingSD3, che ti consente di regolare varie impostazioni come la modalità di campionamento, il numero di passaggi e la scala di output del modello. Infine, il nodo KSampler ti dà controllo sul numero di passaggi, sulla forza dell'influenza delle istruzioni (scala CFG) e sull'algoritmo specifico utilizzato per la generazione, permettendoti di ottenere i risultati desiderati.
