



Ciao, colleghi artisti dell'IA! 👋 Benvenuti nel nostro tutorial adatto ai principianti su ComfyUI, uno strumento incredibilmente potente e flessibile per creare splendide opere d'arte generate dall'IA. 🎨 In questa guida, ti guideremo attraverso le basi di ComfyUI, esploreremo le sue funzionalità e ti aiuteremo a sbloccare il suo potenziale per portare la tua arte IA a un nuovo livello. 🚀
Trattaremo:
- 1. Cos'è ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. Da dove iniziare con ComfyUI?
- 1.3. Controlli di base
- 2. Flussi di lavoro ComfyUI: da testo a immagine
- 2.1. Selezione di un modello
- 2.2. Inserimento del prompt positivo e del prompt negativo
- 2.3. Generazione di un'immagine
- 2.4. Spiegazione tecnica di ComfyUI
- 2.4.1 Nodo Load Checkpoint
- 2.4.2. CLIP Text Encode
- 2.4.3. Immagine latente vuota
- 2.4.4. VAE
- 2.4.5. KSampler
- 3. Flusso di lavoro ComfyUI: da immagine a immagine
- 4. ComfyUI SDXL
- 5. ComfyUI Inpainting
- 6. ComfyUI Outpainting
- 7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. Upscale Pixel per algoritmo
- 7.1.2. Upscale Pixel per modello
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
- 8. ComfyUI ControlNet
- 9. ComfyUI Manager
- 9.1. Come installare nodi personalizzati mancanti
- 9.2. Come aggiornare i nodi personalizzati
- 9.3. Come caricare i nodi personalizzati nel tuo flusso di lavoro
- 10. Embedding ComfyUI
- 10.1. Embedding con autocompletamento
- 10.2. Peso dell'embedding
- 11. ComfyUI LoRA
- 11.1. Semplici flussi di lavoro LoRA
- 11.2. LoRA multipli
- 12. Scorciatoie e trucchi per ComfyUI
- 12.1. Copia e incolla
- 12.2. Spostare più nodi
- 12.3. Bypassare un nodo
- 12.4. Minimizzare un nodo
- 12.5. Generare un'immagine
- 12.6. Flusso di lavoro incorporato
- 12.7. Fissare i seed per risparmiare tempo
- 13. ComfyUI Online
1. Cos'è ComfyUI? 🤔#
ComfyUI è come avere una bacchetta magica 🪄 per creare senza sforzo splendide opere d'arte generate dall'IA. Nel suo nucleo, ComfyUI è un'interfaccia utente grafica (GUI) basata su nodi costruita sopra Stable Diffusion, un modello di apprendimento profondo all'avanguardia che genera immagini da descrizioni testuali. 🌟 Ma ciò che rende ComfyUI davvero speciale è il modo in cui permette agli artisti come te di liberare la tua creatività e dare vita alle tue idee più folli.
Immagina una tela digitale dove puoi costruire i tuoi flussi di lavoro unici per la generazione di immagini connettendo diversi nodi, ognuno dei quali rappresenta una funzione o un'operazione specifica. 🧩 È come costruire una ricetta visiva per i tuoi capolavori generati dall'IA!
Vuoi generare un'immagine da zero utilizzando un prompt testuale? C'è un nodo per questo! Vuoi applicare un sampler specifico o perfezionare il livello di rumore? Aggiungi semplicemente i nodi corrispondenti e guarda la magia accadere. ✨
Ma ecco la parte migliore: ComfyUI suddivide il flusso di lavoro in elementi riorganizzabili, dandoti la libertà di creare i tuoi flussi di lavoro personalizzati su misura per la tua visione artistica. 🖼️ È come avere un toolkit personalizzato che si adatta al tuo processo creativo.
1.1. ComfyUI vs. AUTOMATIC1111 🆚#
AUTOMATIC1111 è la GUI predefinita per Stable Diffusion. Quindi, dovresti usare ComfyUI invece? Confrontiamole:
✅ Vantaggi dell'utilizzo di ComfyUI:
- Leggero: Si esegue in modo rapido ed efficiente.
- Flessibile: Altamente configurabile per soddisfare le tue esigenze.
- Trasparente: Il flusso dei dati è visibile e facile da capire.
- Facile da condividere: Ogni file rappresenta un flusso di lavoro riproducibile.
- Buono per i prototipi: Crea prototipi con un'interfaccia grafica invece di codificare.
❌ Svantaggi dell'utilizzo di ComfyUI:
- Interfaccia incoerente: Ogni flusso di lavoro può avere un layout dei nodi diverso.
- Troppo dettaglio: Gli utenti medi potrebbero non aver bisogno di conoscere le connessioni sottostanti.
1.2. Da dove iniziare con ComfyUI? 🏁#
Crediamo che il modo migliore per imparare ComfyUI sia tuffarsi negli esempi e sperimentarlo in prima persona. 🙌 Ecco perché abbiamo creato questo tutorial unico che si distingue dagli altri. In questo tutorial, troverai una guida dettagliata passo dopo passo che puoi seguire.
Ma ecco la parte migliore: 🌟 Abbiamo integrato ComfyUI direttamente in questa pagina web! Sarai in grado di interagire con gli esempi di ComfyUI in tempo reale man mano che procedi nella guida.🌟 Tuffiamoci!
2. Flussi di lavoro ComfyUI: da testo a immagine 🖼️#
Iniziamo con il caso più semplice: generare un'immagine da testo. Fai clic su Queue Prompt per eseguire il flusso di lavoro. Dopo una breve attesa, dovresti vedere la tua prima immagine generata! Per controllare la tua coda, fai clic su View Queue.
Ecco un flusso di lavoro predefinito da testo a immagine da provare:
Elementi costitutivi di base 🕹️#
Il flusso di lavoro ComfyUI è composto da due elementi costitutivi di base: Nodi e Bordi.
- Nodi sono i blocchi rettangolari, ad esempio, Load Checkpoint, Clip Text Encoder, ecc. Ogni nodo esegue codice specifico e richiede input, output e parametri.
- Bordi sono i fili che collegano gli output e gli input tra i nodi.
Controlli di base 🕹️#
- Ingrandisci e rimpicciolisci usando la rotellina del mouse o il pizzicamento con due dita.
- Trascina e tieni premuto il punto di input o output per creare connessioni tra i nodi.
- Sposta l'area di lavoro tenendo premuto e trascinando con il tasto sinistro del mouse.
Approfondiamo i dettagli di questo flusso di lavoro.#
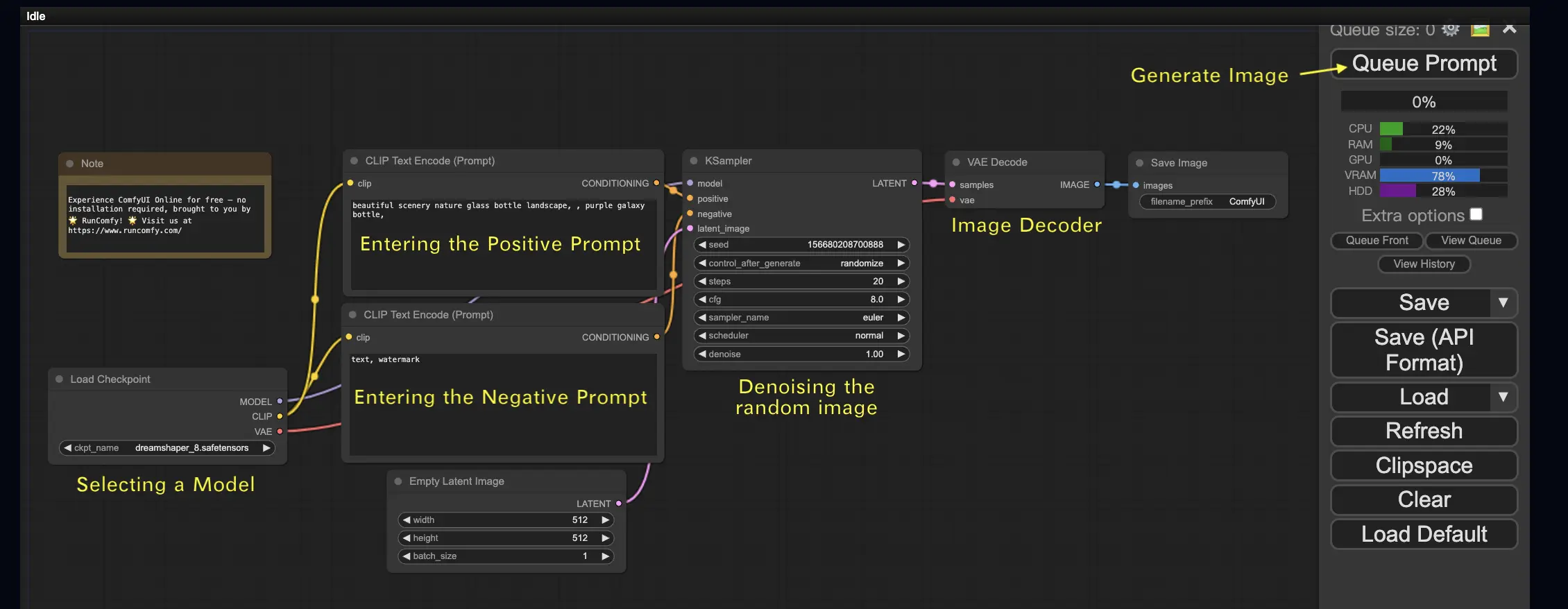
2.1. Selezione di un modello 🗃️#
Per prima cosa, seleziona un modello Stable Diffusion Checkpoint nel nodo Load Checkpoint. Fai clic sul nome del modello per visualizzare i modelli disponibili. Se facendo clic sul nome del modello non accade nulla, potresti dover caricare un modello personalizzato.
2.2. Inserimento del prompt positivo e del prompt negativo 📝#
Vedrai due nodi etichettati CLIP Text Encode (Prompt). Il prompt in alto è collegato all'input positivo del nodo KSampler, mentre il prompt in basso è collegato all'input negativo. Quindi inserisci il tuo prompt positivo in quello in alto e il tuo prompt negativo in quello in basso.
Il nodo CLIP Text Encode converte il prompt in token e li codifica in embedding utilizzando il text encoder.
💡 Suggerimento: Usa la sintassi (parola chiave:peso) per controllare il peso di una parola chiave, ad esempio, (parola chiave:1.2) per aumentare il suo effetto o (parola chiave:0.8) per diminuirlo.
2.3. Generazione di un'immagine 🎨#
Fai clic su Queue Prompt per eseguire il flusso di lavoro. Dopo una breve attesa, la tua prima immagine verrà generata!
2.4. Spiegazione tecnica di ComfyUI 🤓#
Il potere di ComfyUI risiede nella sua configurabilità. Comprendere cosa fa ogni nodo ti permette di adattarli alle tue esigenze. Ma prima di entrare nei dettagli, diamo un'occhiata al processo di Stable Diffusion per capire meglio come funziona ComfyUI.
Il processo di Stable Diffusion può essere riassunto in tre passaggi principali:
- Codifica del testo: Il prompt inserito dall'utente viene compilato in singoli vettori di caratteristiche di parole da un componente chiamato Text Encoder. Questo passaggio converte il testo in un formato che il modello può comprendere e con cui può lavorare.
- Trasformazione dello spazio latente: I vettori di caratteristiche del Text Encoder e un'immagine di rumore casuale vengono trasformati in uno spazio latente. In questo spazio, l'immagine casuale subisce un processo di denoising basato sui vettori di caratteristiche, risultando in un prodotto intermedio. Questo passaggio è dove avviene la magia, poiché il modello impara ad associare le caratteristiche del testo con le rappresentazioni visive.
- Decodifica dell'immagine: Infine, il prodotto intermedio dallo spazio latente viene decodificato dall'Image Decoder, convertendolo in un'immagine effettiva che possiamo vedere e apprezzare.
Ora che abbiamo una comprensione generale del processo di Stable Diffusion, immergiamoci nei componenti e nei nodi chiave di ComfyUI che rendono possibile questo processo.
2.4.1 Nodo Load Checkpoint 🗃️#
Il nodo Load Checkpoint in ComfyUI è cruciale per selezionare un modello Stable Diffusion. Un modello Stable Diffusion è composto da tre componenti principali: MODEL, CLIP e VAE. Esploriamo ogni componente e la sua relazione con i nodi corrispondenti in ComfyUI.
- MODEL: Il componente MODEL è il modello di predizione del rumore che opera nello spazio latente. È responsabile del processo principale di generazione di immagini dalla rappresentazione latente. In ComfyUI, l'output MODEL del nodo Load Checkpoint si collega al nodo KSampler, dove avviene il processo di diffusione inversa. Il nodo KSampler utilizza il MODEL per denoising iterativo della rappresentazione latente, raffinando gradualmente l'immagine fino a farla corrispondere al prompt desiderato.
- CLIP: CLIP (Contrastive Language-Image Pre-training) è un modello di linguaggio che preelabora i prompt positivi e negativi forniti dall'utente. Converte i prompt testuali in un formato che il MODEL può comprendere e utilizzare per guidare il processo di generazione delle immagini. In ComfyUI, l'output CLIP del nodo Load Checkpoint si collega al nodo CLIP Text Encode. Il nodo CLIP Text Encode prende i prompt forniti dall'utente e li alimenta nel modello di linguaggio CLIP, trasformando ogni parola in embedding. Questi embedding catturano il significato semantico delle parole e consentono al MODEL di generare immagini che si allineano ai prompt dati.
- VAE: VAE (Variational AutoEncoder) è responsabile della conversione dell'immagine tra lo spazio dei pixel e lo spazio latente. Consiste in un encoder che comprime l'immagine in una rappresentazione latente a dimensioni inferiori e un decoder che ricostruisce l'immagine dalla rappresentazione latente. Nel processo da testo a immagine, il VAE viene utilizzato solo nel passaggio finale per convertire l'immagine generata dallo spazio latente allo spazio dei pixel. Il nodo VAE Decode in ComfyUI prende l'output del nodo KSampler (che opera nello spazio latente) e utilizza la parte di decoder del VAE per trasformare la rappresentazione latente nell'immagine finale nello spazio dei pixel.
È importante notare che il VAE è un componente separato dal modello di linguaggio CLIP. Mentre CLIP si concentra sull'elaborazione dei prompt testuali, il VAE si occupa della conversione tra spazio dei pixel e spazio latente.
2.4.2. CLIP Text Encode 📝#
Il nodo CLIP Text Encode in ComfyUI è responsabile di prendere i prompt forniti dall'utente e inserirli nel modello di linguaggio CLIP. CLIP è un potente modello di linguaggio che comprende il significato semantico delle parole e può associarle a concetti visivi. Quando un prompt viene inserito nel nodo CLIP Text Encode, subisce un processo di trasformazione in cui ogni parola viene convertita in embedding. Questi embedding sono vettori ad alta dimensione che catturano le informazioni semantiche delle parole. Trasformando i prompt in embedding, CLIP consente al MODEL di generare immagini che riflettono accuratamente il significato e l'intento dei prompt dati.
2.4.3. Empty Latent Image 🌌#
Nel processo da testo a immagine, la generazione inizia con un'immagine casuale nello spazio latente. Questa immagine casuale funge da stato iniziale con cui il MODEL può lavorare. La dimensione dell'immagine latente è proporzionale alla dimensione effettiva dell'immagine nello spazio dei pixel. In ComfyUI, puoi regolare l'altezza e la larghezza dell'immagine latente per controllare la dimensione dell'immagine generata. Inoltre, puoi impostare la dimensione del batch per determinare il numero di immagini generate in ogni esecuzione.
Le dimensioni ottimali per le immagini latenti dipendono dallo specifico modello Stable Diffusion utilizzato. Per i modelli SD v1.5, le dimensioni consigliate sono 512x512 o 768x768, mentre per i modelli SDXL, la dimensione ottimale è 1024x1024. ComfyUI fornisce una gamma di rapporti di aspetto comuni tra cui scegliere, come 1:1 (quadrato), 3:2 (orizzontale), 2:3 (verticale), 4:3 (orizzontale), 3:4 (verticale), 16:9 (widescreen) e 9:16 (verticale). È importante notare che la larghezza e l'altezza dell'immagine latente devono essere divisibili per 8 per garantire la compatibilità con l'architettura del modello.
2.4.4. VAE 🔍#
Il VAE (Variational AutoEncoder) è un componente cruciale nel modello Stable Diffusion che gestisce la conversione delle immagini tra lo spazio dei pixel e lo spazio latente. È composto da due parti principali: un Image Encoder e un Image Decoder.
L'Image Encoder prende un'immagine nello spazio dei pixel e la comprime in una rappresentazione latente a dimensioni inferiori. Questo processo di compressione riduce significativamente la dimensione dei dati, consentendo un'elaborazione e un'archiviazione più efficienti. Ad esempio, un'immagine di dimensioni 512x512 pixel può essere compressa fino a una rappresentazione latente di dimensioni 64x64.
D'altra parte, l'Image Decoder, noto anche come VAE Decoder, è responsabile della ricostruzione dell'immagine dalla rappresentazione latente nello spazio dei pixel. Prende la rappresentazione latente compressa e la espande per generare l'immagine finale.
L'utilizzo di un VAE offre diversi vantaggi:
- Efficienza: comprimendo l'immagine in uno spazio latente a dimensioni inferiori, il VAE consente una generazione più veloce e tempi di addestramento più brevi. La dimensione ridotta dei dati consente un'elaborazione e un utilizzo della memoria più efficienti.
- Manipolazione dello spazio latente: lo spazio latente fornisce una rappresentazione più compatta e significativa dell'immagine. Ciò consente un controllo e una modifica più precisi dei dettagli e dello stile dell'immagine. Manipolando la rappresentazione latente, diventa possibile modificare aspetti specifici dell'immagine generata.
Tuttavia, ci sono anche alcuni svantaggi da considerare:
- Perdita di dati: durante il processo di codifica e decodifica, alcuni dettagli dell'immagine originale potrebbero andare persi. Le fasi di compressione e ricostruzione possono introdurre artefatti o lievi variazioni nell'immagine finale rispetto all'originale.
- Limitata cattura dei dati originali: lo spazio latente a dimensioni inferiori potrebbe non essere in grado di catturare completamente tutte le caratteristiche e i dettagli intricati dell'immagine originale. Alcune informazioni potrebbero andare perse durante il processo di compressione, risultando in una rappresentazione leggermente meno accurata dei dati originali.
Nonostante queste limitazioni, il VAE svolge un ruolo vitale nel modello Stable Diffusion consentendo un'efficiente conversione tra lo spazio dei pixel e lo spazio latente, facilitando una generazione più veloce e un controllo più preciso sulle immagini generate.
2.4.5. KSampler ⚙️#
Il nodo KSampler in ComfyUI è il cuore del processo di generazione delle immagini in Stable Diffusion. È responsabile del denoising dell'immagine casuale nello spazio latente per farla corrispondere al prompt fornito dall'utente. Il KSampler impiega una tecnica chiamata diffusione inversa, in cui raffina iterativamente la rappresentazione latente rimuovendo il rumore e aggiungendo dettagli significativi sulla base della guida dagli embedding CLIP.
Il nodo KSampler offre diversi parametri che consentono agli utenti di perfezionare il processo di generazione delle immagini:
Seed: il valore del seed controlla il rumore iniziale e la composizione dell'immagine finale. Impostando un seed specifico, gli utenti possono ottenere risultati riproducibili e mantenere la coerenza tra più generazioni.
Control_after_generation: questo parametro determina come cambia il valore del seed dopo ogni generazione. Può essere impostato su randomize (genera un nuovo seed casuale per ogni esecuzione), increment (aumenta il valore del seed di 1), decrement (diminuisce il valore del seed di 1) o fixed (mantiene costante il valore del seed).
Step: il numero di passaggi di campionamento determina l'intensità del processo di raffinamento. Valori più alti comportano meno artefatti e immagini più dettagliate, ma aumentano anche il tempo di generazione.
Sampler_name: questo parametro consente agli utenti di scegliere lo specifico algoritmo di campionamento utilizzato dal KSampler. Diversi algoritmi di campionamento possono fornire risultati leggermente diversi e avere velocità di generazione variabili.
Scheduler: lo scheduler controlla come cambia il livello di rumore a ogni passaggio del processo di denoising. Determina la velocità con cui il rumore viene rimosso dalla rappresentazione latente.
Denoise: il parametro denoise imposta la quantità di rumore iniziale che dovrebbe essere cancellata dal processo di denoising. Un valore di 1 significa che tutto il rumore verrà rimosso, risultando in un'immagine pulita e dettagliata.
Regolando questi parametri, puoi ottimizzare il processo di generazione delle immagini per ottenere i risultati desiderati.
Ora, sei pronto a intraprendere il tuo viaggio con ComfyUI?#
A RunComfy, abbiamo creato l'esperienza online ComfyUI definitiva appositamente per te. Dì addio alle installazioni complicate! 🎉 Prova subito ComfyUI Online e libera il tuo potenziale artistico come mai prima d'ora! 🎉
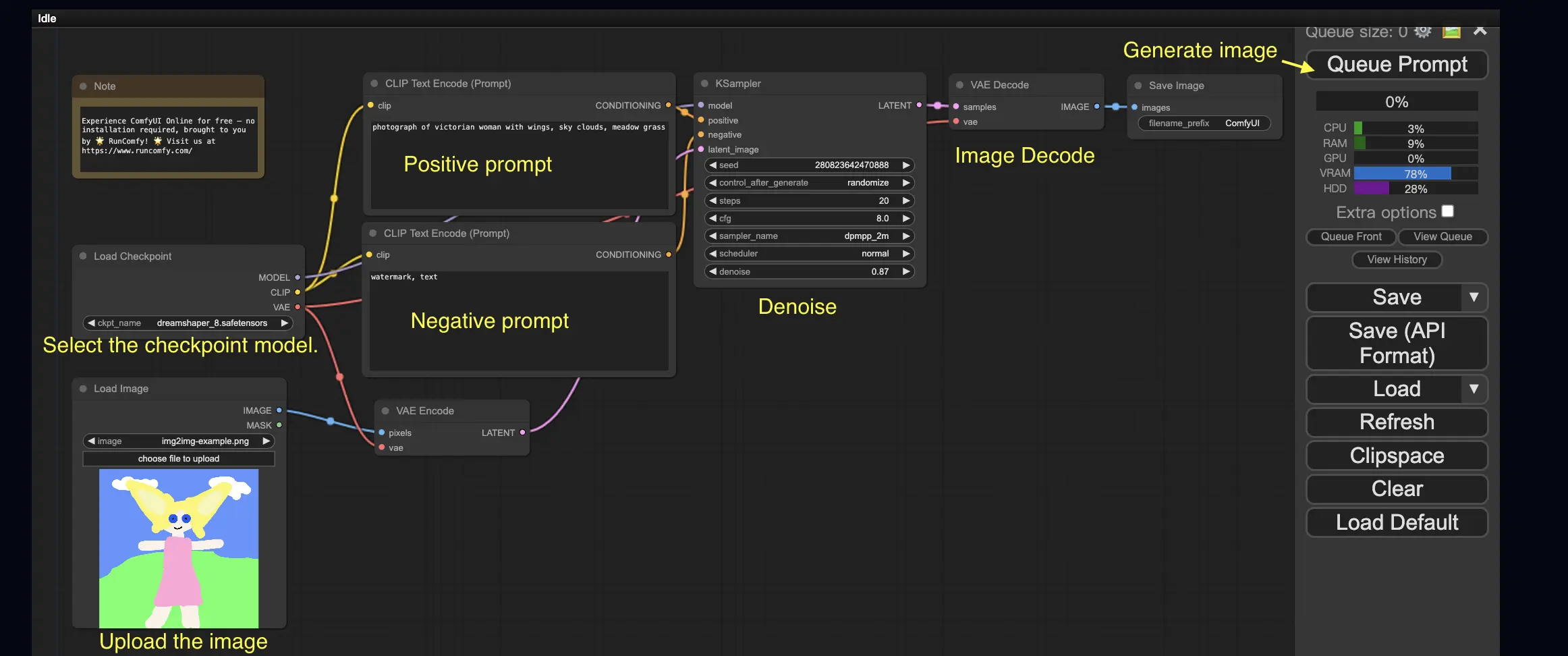
3. Flusso di lavoro ComfyUI: da immagine a immagine 🖼️#
Il flusso di lavoro da immagine a immagine genera un'immagine basata su un prompt e un'immagine di input. Provalo tu stesso!
Per utilizzare il flusso di lavoro da immagine a immagine:
- Seleziona il modello checkpoint.
- Carica l'immagine come prompt immagine.
- Rivedi i prompt positivi e negativi.
- Opzionalmente regola il denoising (forza di denoising) nel nodo KSampler.
- Premi Queue Prompt per avviare la generazione.
Per ulteriori flussi di lavoro ComfyUI premium, visita la nostra 🌟Lista dei flussi di lavoro ComfyUI🌟
4. ComfyUI SDXL 🚀#
Grazie alla sua estrema configurabilità, ComfyUI è una delle prime GUI a supportare il modello Stable Diffusion XL. Proviamolo!
Per utilizzare il flusso di lavoro ComfyUI SDXL:
- Rivedi i prompt positivi e negativi.
- Premi Queue Prompt per avviare la generazione.
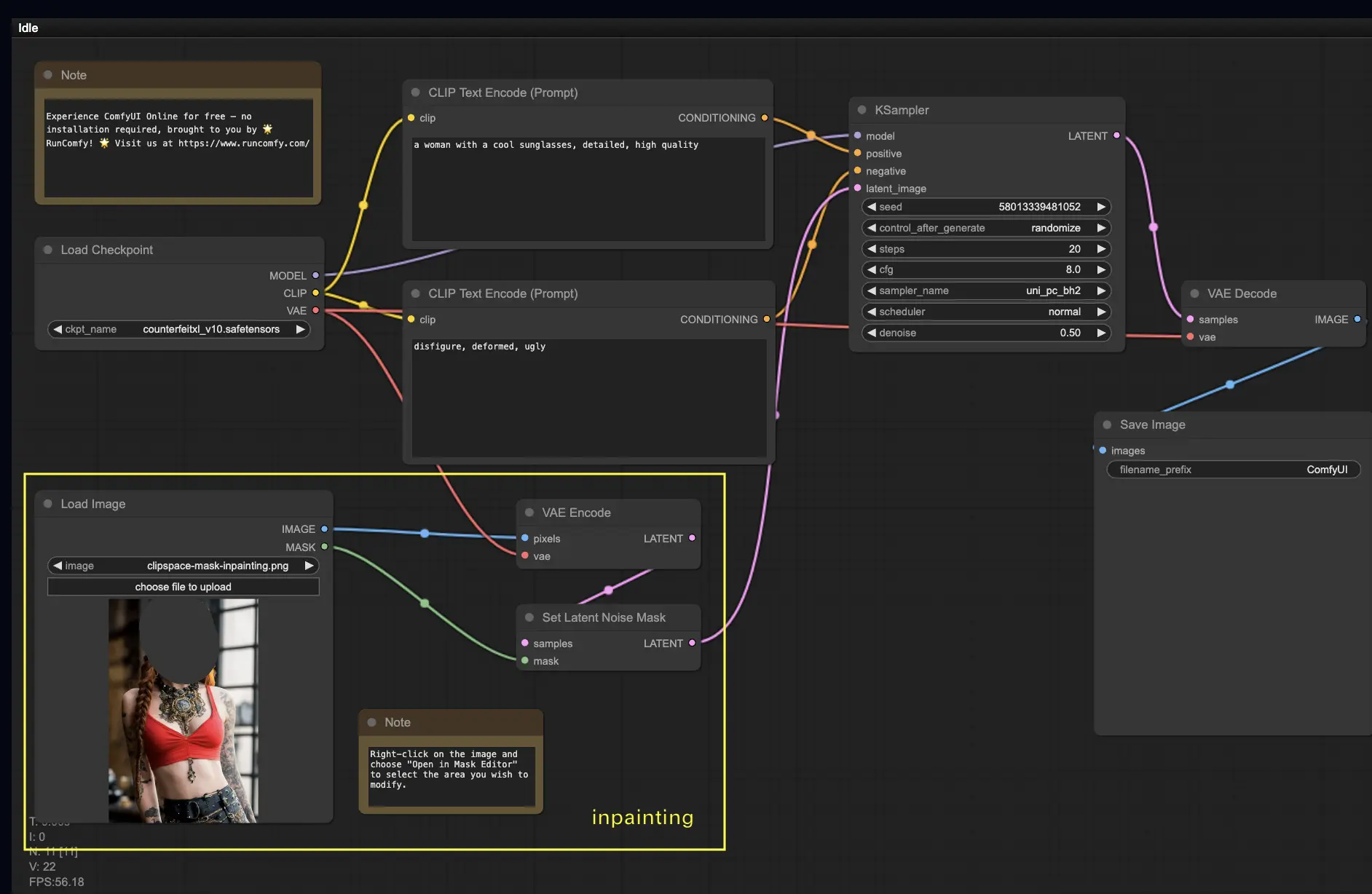
5. ComfyUI Inpainting 🎨#
Immergiamoci in qualcosa di più complesso: l'inpainting! Quando hai un'immagine fantastica ma vuoi modificare parti specifiche, l'inpainting è il metodo migliore. Provalo qui!
Per utilizzare il flusso di lavoro di inpainting:
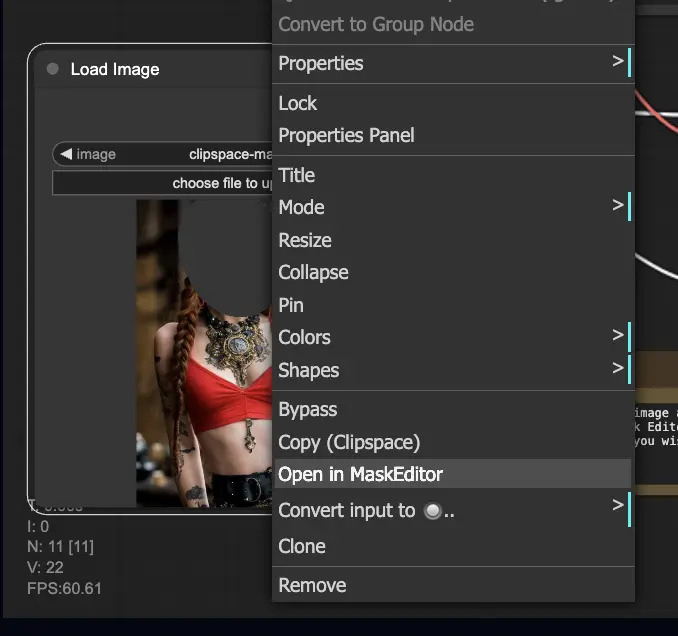
- Carica un'immagine che desideri inpaintare.
- Fai clic con il pulsante destro del mouse sull'immagine e seleziona "Apri in MaskEditor". Maschera l'area da rigenerare, quindi fai clic su "Salva nel nodo".
- Seleziona un modello Checkpoint:
- Questo flusso di lavoro funziona solo con un modello Stable Diffusion standard, non con un modello Inpainting.
- Se vuoi utilizzare un modello inpainting, sostituisci i nodi "VAE Encode" e "Set Noise Latent Mask" con il nodo "VAE Encode (Inpaint)", appositamente progettato per i modelli inpainting.
- Personalizza il processo di inpainting:
- Nel nodo CLIP Text Encode (Prompt), puoi inserire informazioni aggiuntive per guidare l'inpainting. Ad esempio, puoi specificare lo stile, il tema o gli elementi che desideri includere nell'area di inpainting.
- Imposta la forza originale di denoising (denoise), ad esempio 0.6.
- Premi Queue Prompt per eseguire l'inpainting.
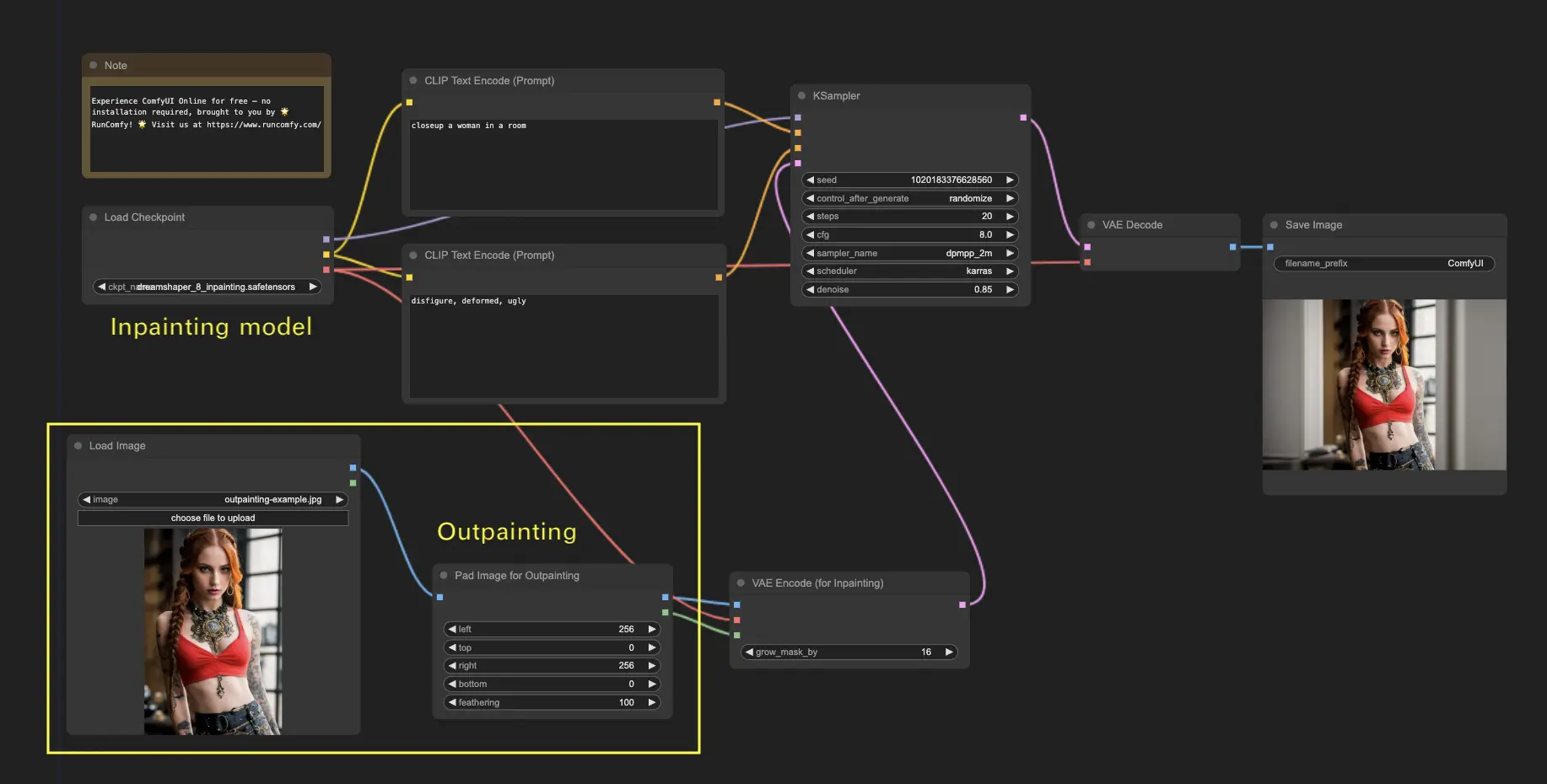
6. ComfyUI Outpainting 🖌️#
L'outpainting è un'altra tecnica entusiasmante che ti permette di espandere le tue immagini oltre i loro confini originali. 🌆 È come avere una tela infinita con cui lavorare!
Per utilizzare il flusso di lavoro di outpainting di ComfyUI:
- Inizia con un'immagine che desideri espandere.
- Utilizza il nodo Pad Image for Outpainting nel tuo flusso di lavoro.
- Configura le impostazioni di outpainting:
- left, top, right, bottom: specifica il numero di pixel da espandere in ogni direzione.
- feathering: regola la fluidità della transizione tra l'immagine originale e l'area outpaintata. Valori più alti creano una sfumatura più graduale ma possono introdurre un effetto di sfocatura.
- Personalizza il processo di outpainting:
- Nel nodo CLIP Text Encode (Prompt), puoi inserire informazioni aggiuntive per guidare l'outpainting. Ad esempio, puoi specificare lo stile, il tema o gli elementi che desideri includere nell'area espansa.
- Sperimenta con diversi prompt per ottenere i risultati desiderati.
- Affina il nodo VAE Encode (for Inpainting):
- Regola il parametro grow_mask_by per controllare la dimensione della maschera di outpainting. Per risultati ottimali, si consiglia un valore superiore a 10.
- Premi Queue Prompt per avviare il processo di outpainting.
Per ulteriori flussi di lavoro di inpainting/outpainting premium, visita la nostra 🌟Lista dei flussi di lavoro ComfyUI🌟
7. ComfyUI Upscale ⬆️#
Procediamo con l'esplorazione dell'upscale di ComfyUI. Introdurremo tre flussi di lavoro fondamentali per aiutarti a eseguire l'upscale in modo efficiente.
Ci sono due metodi principali per l'upscale:
- Upscale pixel: upscala direttamente l'immagine visibile.
- Input: immagine, Output: immagine upscalata
- Upscale latent: upscala l'immagine invisibile nello spazio latente.
- Input: latente, Output: latente upscalato (richiede la decodifica per diventare un'immagine visibile)
7.1. Upscale Pixel 🖼️#
Due modi per ottenerlo:
- Usando algoritmi: velocità di generazione più elevata, ma risultati leggermente inferiori rispetto ai modelli.
- Usando modelli: risultati migliori, ma tempi di generazione più lunghi.
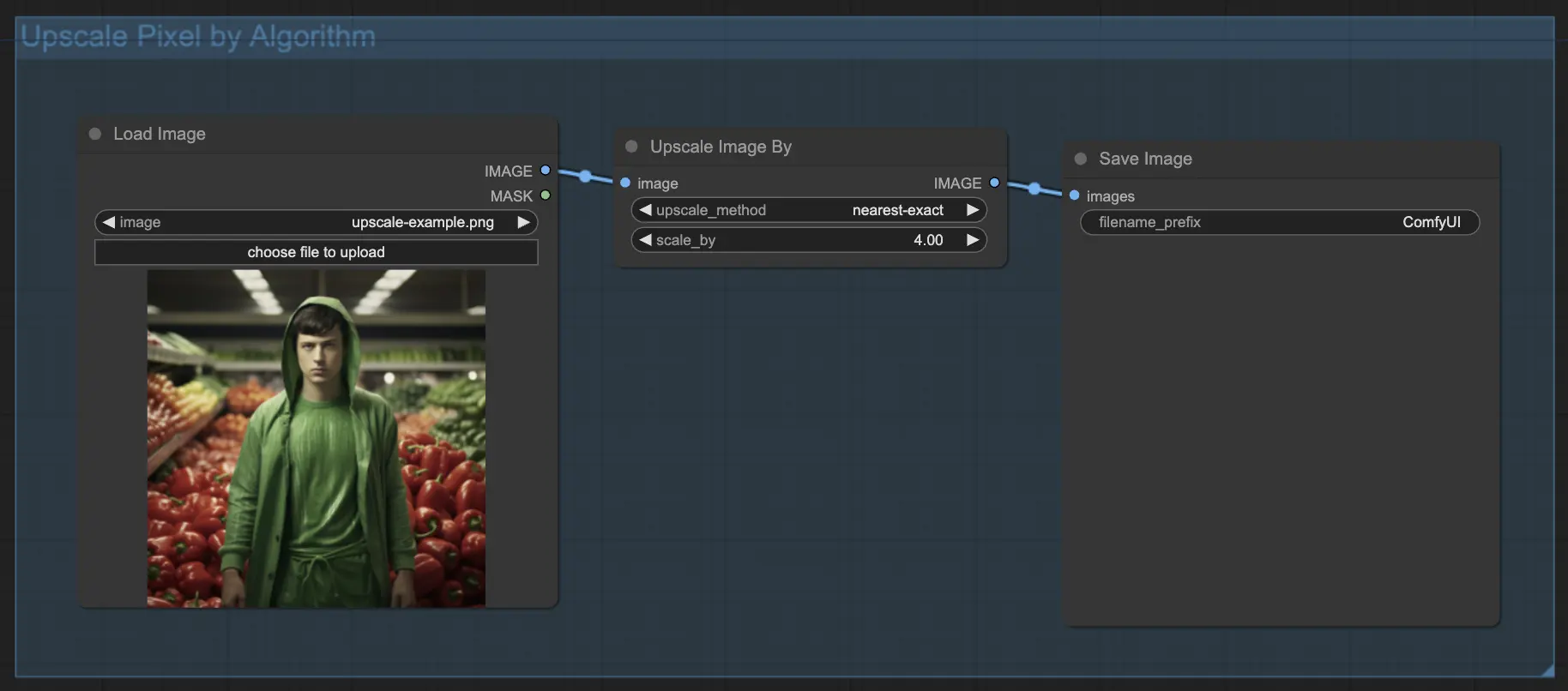
7.1.1. Upscale Pixel per algoritmo 🧮#
- Aggiungi il nodo Upscale Image by.
- parametro method: scegli l'algoritmo di upscale (bicubic, bilinear, nearest-exact).
- parametro Scale: specifica il fattore di upscale (ad es. 2 per 2x).
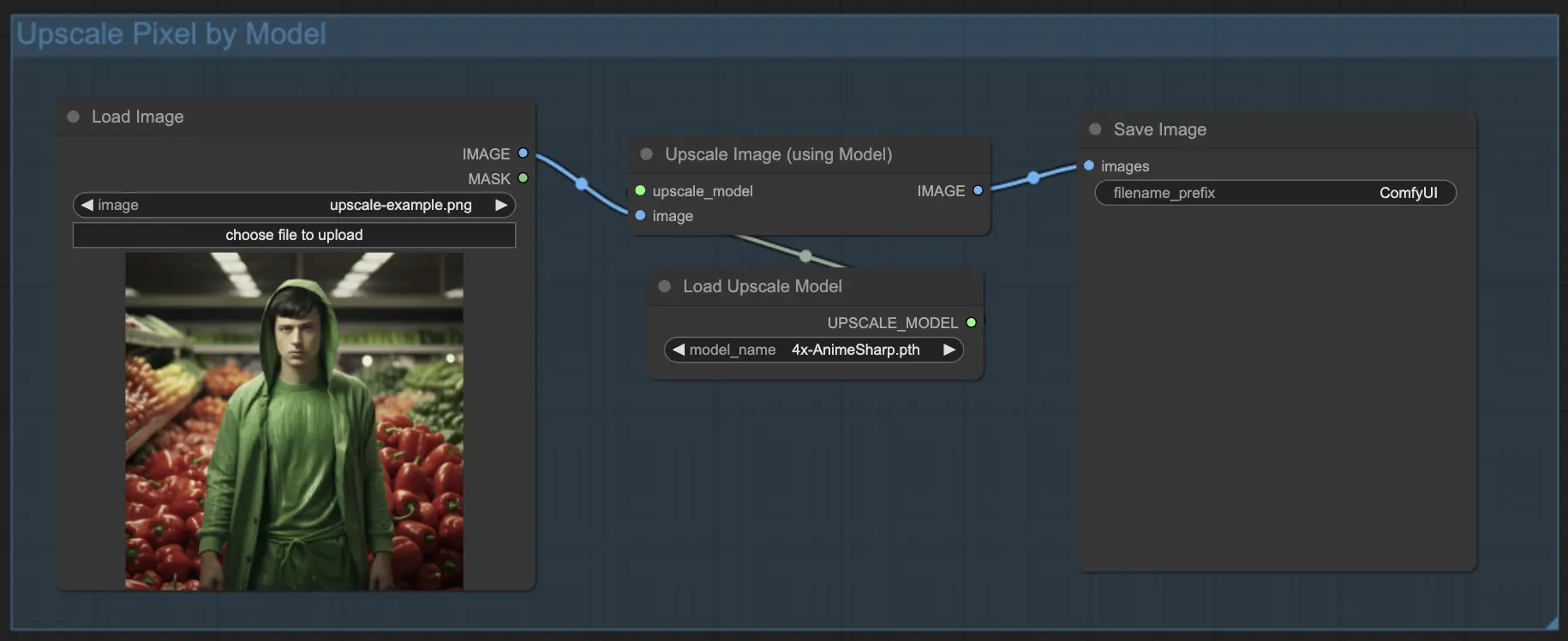
7.1.2. Upscale Pixel per modello 🤖#
- Aggiungi il nodo Upscale Image (using Model).
- Aggiungi il nodo Load Upscale Model.
- Scegli un modello adatto al tuo tipo di immagine (ad es. anime o vita reale).
- Seleziona il fattore di upscale (X2 o X4).
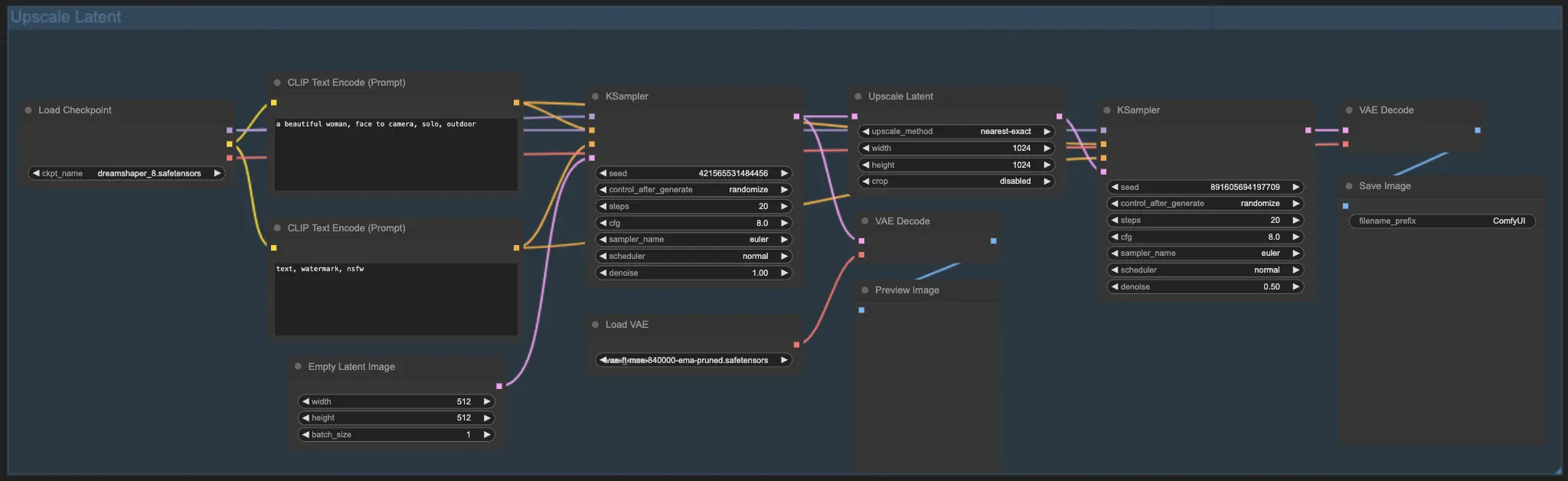
7.2. Upscale Latent ⚙️#
Un altro metodo di upscale è l'Upscale Latent, noto anche come Hi-res Latent Fix Upscale, che esegue l'upscale direttamente nello spazio latente.
7.3. Upscale Pixel vs. Upscale Latent 🆚#
- Upscale Pixel: ingrandisce solo l'immagine senza aggiungere nuove informazioni. Generazione più veloce, ma può avere un effetto di sfocatura e mancanza di dettagli.
- Upscale Latent: oltre a ingrandire, cambia alcune delle informazioni dell'immagine originale, arricchendo i dettagli. Può deviare dall'immagine originale e ha una velocità di generazione più lenta.
Per ulteriori flussi di lavoro di restore/upscale premium, visita la nostra 🌟Lista dei flussi di lavoro ComfyUI🌟
8. ComfyUI ControlNet 🎮#
Preparati a portare la tua arte AI a un livello superiore con ControlNet, una tecnologia rivoluzionaria che rivoluziona la generazione di immagini!
ControlNet è come una bacchetta magica 🪄 che ti concede un controllo senza precedenti sulle tue immagini generate dall'AI. Lavora fianco a fianco con potenti modelli come Stable Diffusion, migliorando le loro capacità e permettendoti di guidare il processo di creazione delle immagini come mai prima d'ora!
Immagina di poter specificare i bordi, le pose umane, la profondità o addirittura le mappe di segmentazione dell'immagine desiderata. 🌠 Con ControlNet, puoi farlo!
Se sei desideroso di immergerti più a fondo nel mondo di ControlNet e di sfruttarne appieno le potenzialità, ti abbiamo coperto. Dai un'occhiata al nostro tutorial dettagliato su padroneggiare ControlNet in ComfyUI! 📚 È ricco di guide passo passo ed esempi stimolanti per aiutarti a diventare un professionista di ControlNet. 🏆
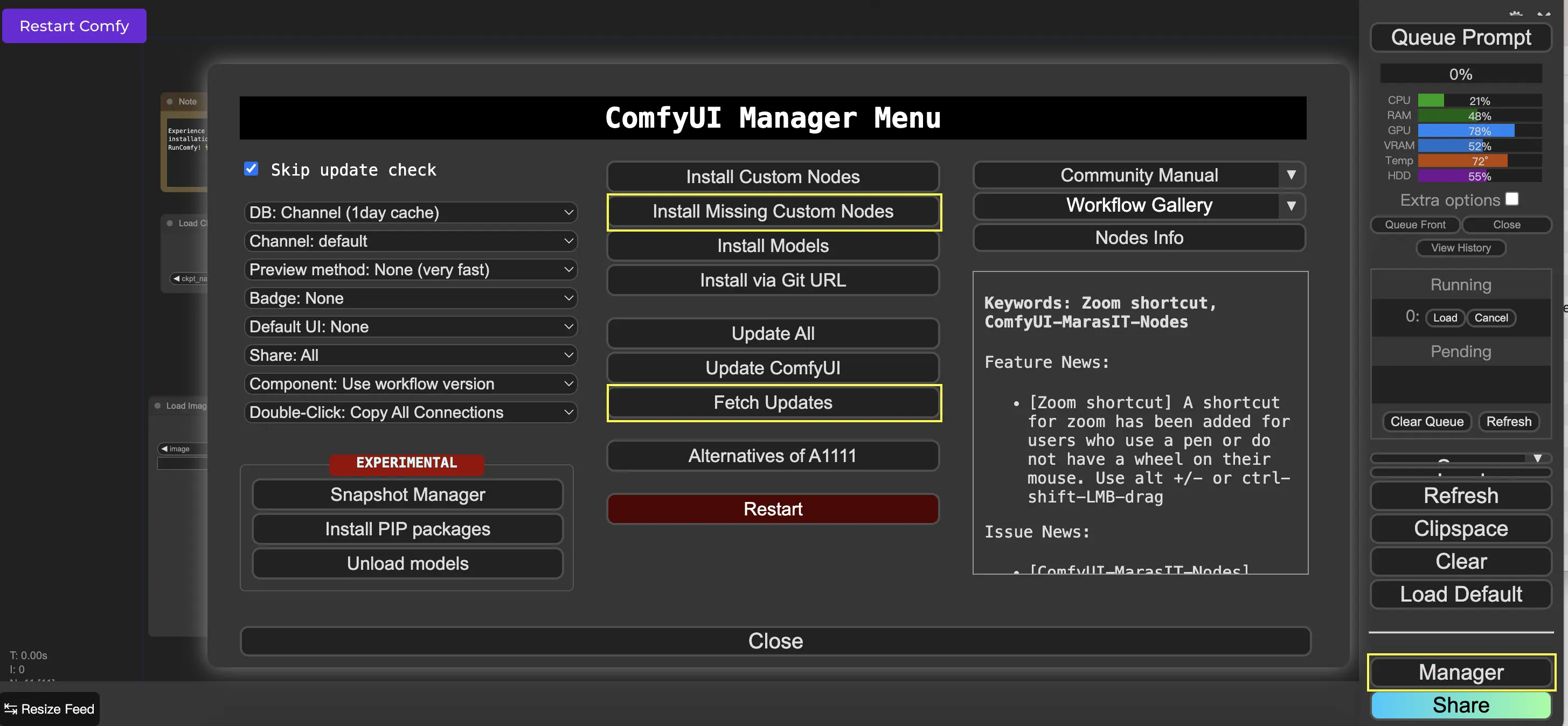
9. ComfyUI Manager 🛠️#
ComfyUI Manager è un nodo personalizzato che ti consente di installare e aggiornare altri nodi personalizzati attraverso l'interfaccia di ComfyUI. Troverai il pulsante Manager nel menu Queue Prompt.
9.1. Come installare i nodi personalizzati mancanti 📥#
Se un flusso di lavoro richiede nodi personalizzati che non hai installato, segui questi passaggi:
- Fai clic su Manager nel Menu.
- Fai clic su Installa nodi personalizzati mancanti.
- Riavvia completamente ComfyUI.
- Aggiorna il browser.
9.2. Come aggiornare i nodi personalizzati 🔄#
- Fai clic su Manager nel Menu.
- Fai clic su Fetch Updates (potrebbe richiedere del tempo).
- Fai clic su Installa nodi personalizzati.
- Se è disponibile un aggiornamento, apparirà un pulsante Aggiorna accanto al nodo personalizzato installato.
- Fai clic su Aggiorna per aggiornare il nodo.
- Riavvia ComfyUI.
- Aggiorna il browser.
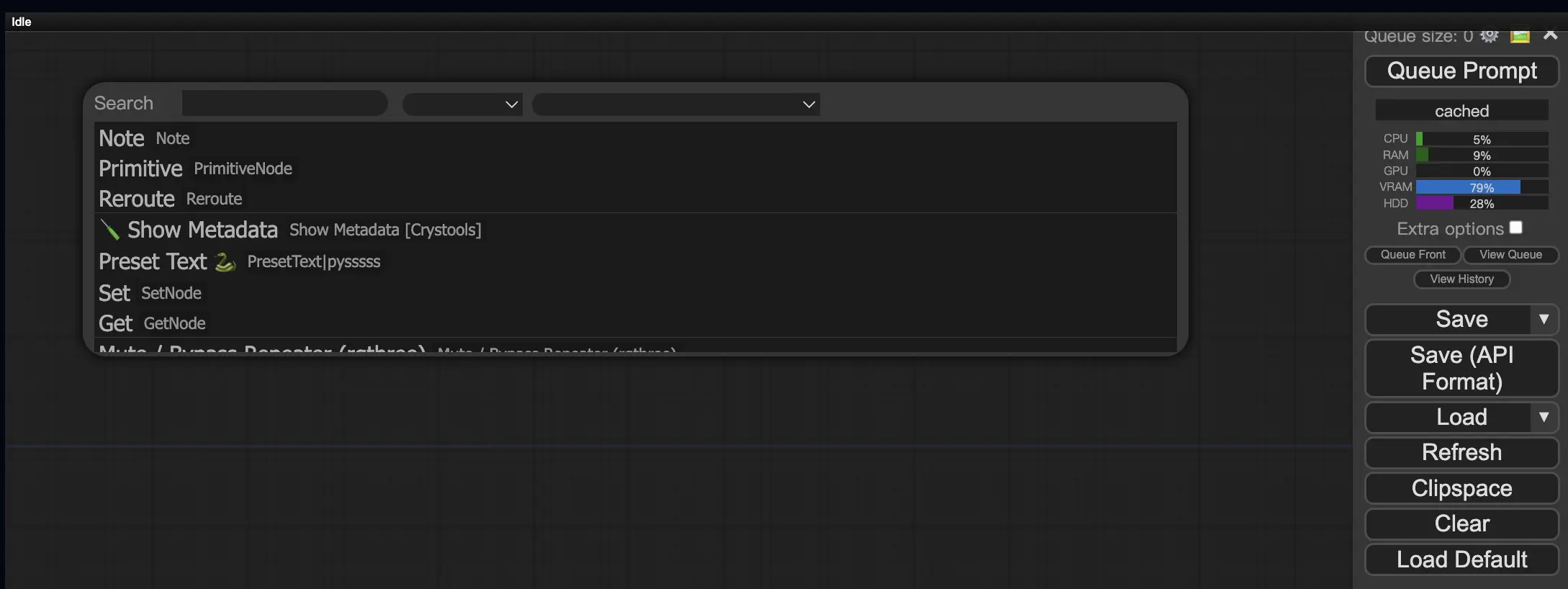
9.3. Come caricare i nodi personalizzati nel tuo flusso di lavoro 🔍#
Fai doppio clic su un'area vuota per visualizzare un menu per cercare i nodi.
10. Embedding ComfyUI 📝#
Gli embedding, noti anche come textual inversion, sono una potente funzionalità di ComfyUI che ti consente di iniettare concetti o stili personalizzati nelle tue immagini generate dall'AI. 💡 È come insegnare all'AI una nuova parola o frase e associarla a caratteristiche visive specifiche.
Per utilizzare gli embedding in ComfyUI, digita semplicemente "embedding:" seguito dal nome del tuo embedding nella casella del prompt positivo o negativo. Ad esempio:
embedding: BadDream
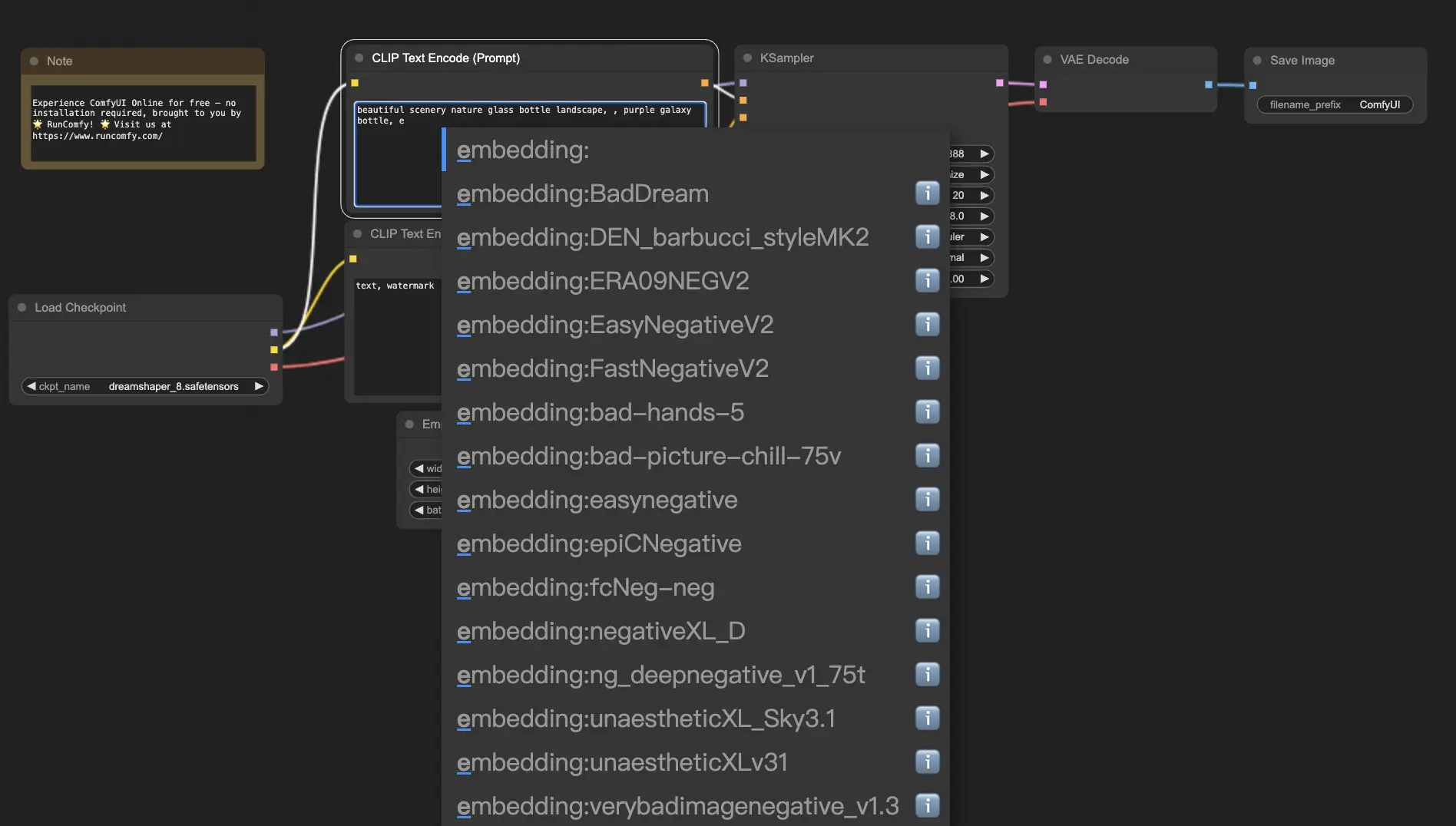
Quando utilizzi questo prompt, ComfyUI cercherà un file di embedding denominato "BadDream" nella cartella ComfyUI > modelli > embedding. 📂 Se trova una corrispondenza, applicherà le caratteristiche visive corrispondenti all'immagine generata.
Gli embedding sono un ottimo modo per personalizzare la tua arte AI e ottenere stili o estetiche specifiche. 🎨 Puoi creare i tuoi embedding addestrandoli su un set di immagini che rappresentano il concetto o lo stile desiderato.
10.1. Embedding con autocompletamento 🔠#
Ricordare i nomi esatti dei tuoi embedding può essere una seccatura, soprattutto se ne hai una vasta collezione. 😅 È qui che il nodo personalizzato ComfyUI-Custom-Scripts viene in soccorso!
Per abilitare l'autocompletamento dei nomi degli embedding:
- Apri ComfyUI Manager facendo clic su "Manager" nel menu in alto.
- Vai su "Installa nodi personalizzati" e cerca "ComfyUI-Custom-Scripts".
- Fai clic su "Installa" per aggiungere il nodo personalizzato alla tua configurazione ComfyUI.
- Riavvia ComfyUI per applicare le modifiche.
Una volta installato il nodo ComfyUI-Custom-Scripts, sperimenterai un modo più intuitivo di utilizzare gli embedding. 😊 Inizia semplicemente a digitare "embedding:" in una casella di prompt e apparirà un elenco di embedding disponibili. Puoi quindi selezionare l'embedding desiderato dall'elenco, risparmiando tempo e fatica!
10.2. Peso dell'embedding ⚖️#
Sapevi che puoi controllare la forza dei tuoi embedding? 💪 Poiché gli embedding sono essenzialmente parole chiave, puoi applicare pesi ad essi proprio come faresti con le parole chiave regolari nei tuoi prompt.
Per regolare il peso di un embedding, utilizza la seguente sintassi:
(embedding: BadDream:1.2)
In questo esempio, il peso dell'embedding "BadDream" viene aumentato del 20%. Quindi pesi più alti (ad esempio, 1.2) renderanno l'embedding più prominente, mentre pesi più bassi (ad esempio, 0.8) ridurranno la sua influenza. 🎚️ Questo ti dà ancora più controllo sul risultato finale!
11. ComfyUI LoRA 🧩#
LoRA, abbreviazione di Low-rank Adaptation, è un'altra entusiasmante funzionalità di ComfyUI che ti consente di modificare e affinare i tuoi modelli checkpoint. 🎨 È come aggiungere un piccolo modello specializzato sopra il tuo modello di base per ottenere stili specifici o incorporare elementi personalizzati.
I modelli LoRA sono compatti ed efficienti, rendendoli facili da usare e condividere. Sono comunemente usati per attività come la modifica dello stile artistico di un'immagine o l'iniezione di una persona o un oggetto specifico nel risultato generato.
Quando applichi un modello LoRA a un modello checkpoint, esso modifica i componenti MODEL e CLIP lasciando inalterato il VAE (Variational Autoencoder). Ciò significa che il LoRA si concentra sulla regolazione del contenuto e dello stile dell'immagine senza alterarne la struttura complessiva.
11.1. Come utilizzare LoRA 🔧#
Utilizzare LoRA in ComfyUI è semplice. Diamo un'occhiata al metodo più semplice:
- Seleziona un modello checkpoint che funga da base per la generazione delle immagini.
- Scegli un modello LoRA che desideri applicare per modificare lo stile o iniettare elementi specifici.
- Rivedi i prompt positivi e negativi per guidare il processo di generazione delle immagini.
- Fai clic su "Queue Prompt" per iniziare a generare l'immagine con il LoRA applicato. ▶
ComfyUI combinerà quindi il modello checkpoint e il modello LoRA per creare un'immagine che rifletta i prompt specificati e incorpori le modifiche introdotte dal LoRA.
11.2. LoRA multipli 🧩🧩#
Ma se volessi applicare più LoRA a una singola immagine? Nessun problema! ComfyUI ti consente di utilizzare due o più LoRA nello stesso flusso di lavoro da testo a immagine.
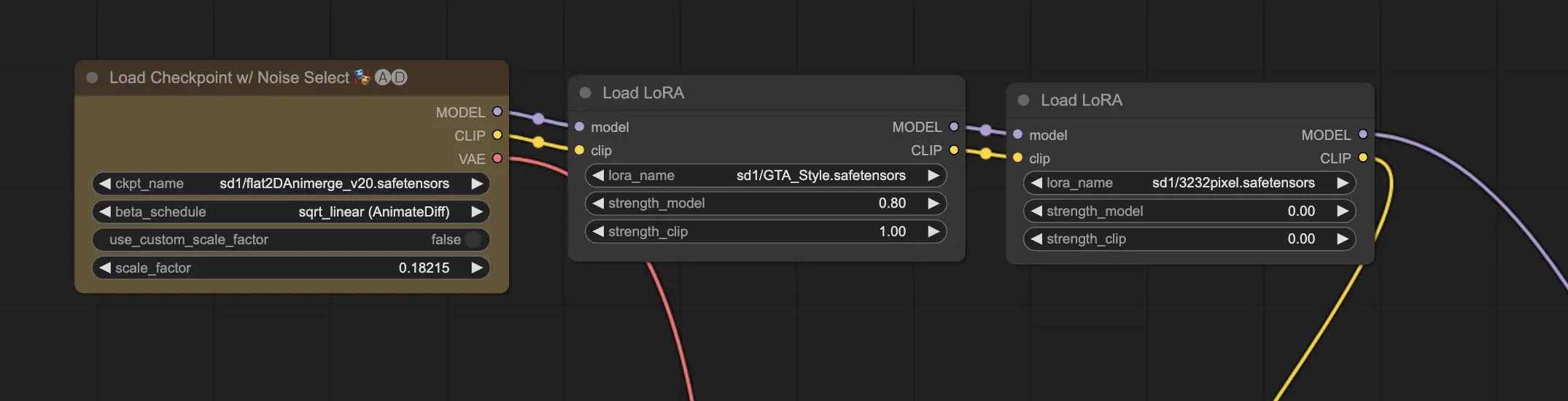
Il processo è simile all'utilizzo di un singolo LoRA, ma dovrai selezionare più modelli LoRA invece di uno solo. ComfyUI applicherà i LoRA in sequenza, il che significa che ogni LoRA si baserà sulle modifiche introdotte dal precedente.
Questo apre un mondo di possibilità per combinare diversi stili, elementi e modifiche nelle tue immagini generate dall'AI. 🌍💡 Sperimenta diverse combinazioni di LoRA per ottenere risultati unici e creativi!
12. Scorciatoie e trucchi per ComfyUI ⌨️🖱️#
12.1. Copia e incolla 📋#
- Seleziona un nodo e premi Ctrl+C per copiare.
- Premi Ctrl+V per incollare.
- Premi Ctrl+Shift+V per incollare con le connessioni di input intatte.
12.2. Spostare più nodi 🖱️#
- Crea un gruppo per spostare un insieme di nodi insieme.
- In alternativa, tieni premuto Ctrl e trascina per creare una casella per selezionare più nodi o tieni premuto Ctrl per selezionare più nodi individualmente.
- Per spostare i nodi selezionati, tieni premuto Shift e sposta il mouse.
12.3. Bypassare un nodo 🔇#
- Disabilita temporaneamente un nodo silenziandolo. Seleziona un nodo e premi Ctrl+M.
- Non c'è una scorciatoia da tastiera per silenziare un gruppo. Seleziona Bypass Group Node nel menu di scelta rapida o silenzia il primo nodo del gruppo per disabilitarlo.
12.4. Minimizzare un nodo 🔍#
- Fai clic sul punto nell'angolo in alto a sinistra del nodo per minimizzarlo.
12.5. Generare un'immagine ▶️#
- Premi Ctrl+Invio per mettere in coda il flusso di lavoro e generare immagini.
12.6. Flusso di lavoro incorporato 🖼️#
- ComfyUI salva l'intero flusso di lavoro nei metadati del file PNG che genera. Per caricare il flusso di lavoro, trascina e rilascia l'immagine in ComfyUI.
12.7. Fissare i seed per risparmiare tempo ⏰#
- ComfyUI riesegue un nodo solo se l'input cambia. Quando si lavora su una lunga catena di nodi, risparmiare tempo fissando il seed per evitare di rigenerare i risultati a monte.
13. ComfyUI Online 🚀#
Complimenti per aver completato questa guida per principianti a ComfyUI! 🙌 Ora sei pronto a tuffarti nell'entusiasmante mondo della creazione di arte AI. Ma perché preoccuparsi dell'installazione quando puoi iniziare a creare subito? 🤔
A RunComfy, abbiamo reso semplice per te utilizzare ComfyUI online senza alcuna configurazione. Il nostro servizio ComfyUI Online viene fornito precaricato con oltre 200 nodi e modelli popolari, insieme a oltre 50 flussi di lavoro mozzafiato per ispirare le tue creazioni.
🌟 Che tu sia un principiante o un artista AI esperto, RunComfy ha tutto ciò di cui hai bisogno per dare vita alle tue visioni artistiche. 💡 Non aspettare oltre – prova subito ComfyUI Online e sperimenta il potere della creazione artistica AI a portata di mano! 🚀