AnimateDiff + IPAdapter V1 | 画像からビデオへ
IPAdapterは、事前学習済みモデルに画像プロンプト機能を追加する軽量なソリューションです。 AnimateDiffとIPAdapterを一緒に使用することで、参照画像からより制御しやすいアニメーションを簡単に生成できます。ComfyUI AnimateDiff IPAdapter ワークフロー
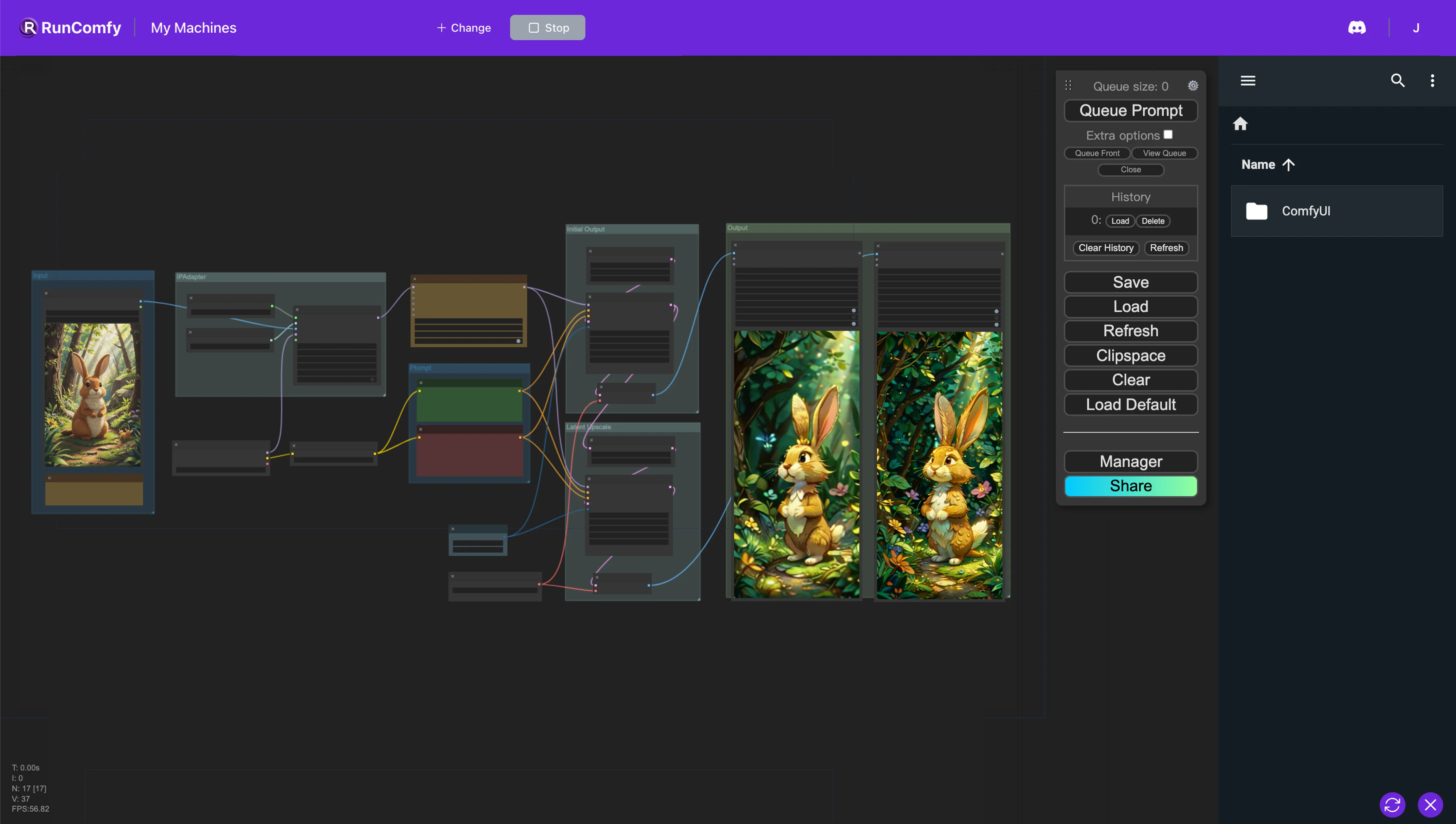
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI AnimateDiff IPAdapter 例
ComfyUI AnimateDiff IPAdapter 説明
1. ComfyUI ワークフロー: AnimateDiff + IPAdapter | 画像からビデオへ
このComfyUIワークフローは、AnimateDiffとIP-Adapterを使用して、参照画像からアニメーションを作成するように設計されています。AnimateDiffノードは、アニメーションのダイナミクスを調整するためのモデルとコンテキストのオプションを統合しています。逆に、IP-Adapterノードは、参照画像のスタイル、構図、または顔の特徴を模倣する方法で画像をプロンプトとして使用することを容易にし、生成されたアニメーションまたは画像のカスタマイズと品質を大幅に向上させます。
2. AnimateDiffの概要
の詳細をご確認ください。
3. IP-Adapterの概要
3.1. IP-Adapterの紹介
IP-Adapterは "Image Prompt Adapter" の略で、画像生成タスクで画像プロンプトを使用する機能でテキストから画像への拡散モデルを強化する新しいアプローチです。 IP-Adapterは、目的の画像を生成するために複雑なプロンプトエンジニアリングを必要とすることが多いテキストプロンプトの欠点に対処することを目的としています。テキストと並んで画像プロンプトを導入することで、画像合成プロセスを直感的かつ効果的に誘導する方法が可能になります。
IP-Adapterのさまざまなモデル
IP-Adapterスイートには、特定のユースケースと画像合成の複雑さのレベルに合わせて調整された様々なモデルが含まれています。利用可能な異なるモデルの概要は次のとおりです。
3.1.1. v1.5モデル
ip-adapter_sd15: バージョン1.5の標準モデルで、画像から画像への調整とテキストプロンプトの拡張にIP-Adapterの力を活用します。ip-adapter_sd15_light: 標準モデルの軽量版で、IP-Adapterテクノロジーを活用しながら、リソース集約型のアプリケーション向けに最適化されています。ip-adapter-plus_sd15: 生成された画像を元の参照画像により密接に合わせ、細部を改善する拡張モデル。ip-adapter-plus-face_sd15: IP-Adapter Plusと同様ですが、生成された画像での顔の特徴のより正確な複製に重点を置いています。ip-adapter-full-face_sd15: 全顔の詳細を強調するモデルで、高い忠実度で "顔の入れ替え" 効果を提供します。ip-adapter_sd15_vit-G: より詳細な画像特徴抽出のためにVision Transformer(ViT)BigG画像エンコーダーを使用する標準モデルのバリエーション。
3.1.2. SDXLモデル
ip-adapter_sdxl: より大きく複雑な画像プロンプトを処理するように設計された、SDXLの基本モデル。ip-adapter_sdxl_vit-h: ViT H画像エンコーダーとペアになったSDXLモデルで、パフォーマンスと計算効率のバランスを取ります。ip-adapter-plus_sdxl_vit-h: 画像プロンプトの詳細と品質が向上したSDXLモデルの高度なバージョン。ip-adapter-plus-face_sdxl_vit-h: 顔の詳細に重点を置いたSDXLバリアントで、顔の精度が最も重要なプロジェクトに最適です。
3.1.3. FaceIDモデル
FaceID: InsightFaceを使用してFace ID embeddingsを抽出するモデルで、顔関連の画像生成にユニークなアプローチを提供します。FaceID Plus: InsightFaceで顔の特徴を、CLIP画像エンコーディングでグローバルな顔の特徴を組み合わせたFaceIDモデルの改良版。FaceID Plus v2: 改善されたモデルチェックポイントとCLIP画像の埋め込みに重みを設定する機能を備えたFaceID Plusの反復。FaceID Portrait: FaceIDと同様のモデルですが、より多様な顔の調整のために、トリミングされた複数の顔画像を受け入れるように設計されています。
3.1.4. SDXL FaceIDモデル
FaceID SDXL: v1.5と同じInsightFaceモデルを維持しながら、SDXLアプリケーション用にスケーリングされたFaceIDのSDXLバージョン。FaceID Plus v2 SDXL: 高精細な画像生成のためのFaceID Plus v2のSDXL適応で、忠実度が向上しています。
3.2. IP-Adapterの主な特徴
3.2.1. テキストと画像プロンプトの統合: テキストと画像の両方のプロンプトを使用するIP-Adapterのユニークな機能は、多様なモダリティの画像生成を可能にし、拡散モデルの出力を制御するための汎用性の高い強力なツールを提供します。
3.2.2. 分離されたクロスアテンションメカニズム: IP-Adapterは、テキストと画像の特徴を分離することにより、多様なモダリティの処理におけるモデルの効率を高める分離されたクロスアテンション戦略を採用しています。
3.2.3. 軽量モデル: 包括的な機能にもかかわらず、IP-Adapterはパラメーター数が比較的少なく(22M)、微調整された画像プロンプトモデルに匹敵またはそれ以上のパフォーマンスを提供します。
3.2.4. 互換性と一般化: IP-Adapterは、既存の制御可能なツールとの幅広い互換性を備えており、同じベースモデルから派生したカスタムモデルに適用して一般化を強化できます。
3.2.5. 構造制御: IP-Adapterは、詳細な構造制御をサポートしているため、クリエイターはより高い精度で画像生成プロセスを誘導できます。
3.2.6. 画像から画像への変換とインペインティング機能: 画像ガイド付きの画像から画像への変換とインペインティングをサポートすることで、IP-Adapterは可能なアプリケーションの範囲を広げ、さまざまな画像合成タスクでの創造的で実用的な使用を可能にします。
3.2.7. さまざまなエンコーダーによるカスタマイズ: IP-Adapterでは、OpenClip ViT H 14やViT BigG 14などのさまざまなエンコーダーを使用して参照画像を処理できます。この柔軟性により、異なる画像解像度や複雑さを処理でき、特定のニーズや望ましい結果に合わせて画像生成プロセスを調整したいクリエイターにとって汎用性の高いツールになります。
IP-Adapterテクノロジーを画像生成プロジェクトに組み込むことで、複雑で詳細な画像の作成が簡素化されるだけでなく、生成された画像の元のプロンプトに対する品質と忠実度も大幅に向上します。 IP-Adapterは、テキストと画像のプロンプトの間のギャップを埋めることにより、画像合成のニュアンスを制御するための強力で直感的かつ効率的なアプローチを提供し、ComfyUIワークフロー内または高品質のカスタマイズされた画像生成を要求する他のコンテキストで作業するデジタルアーティスト、デザイナー、クリエイターの不可欠なツールとなっています。
