IPAdapter V1 FaceID Plus | 一貫したキャラクター
IPAdapter Face Plus V2モデルを使用して、キャラクターデザインの可能性を最大限に引き出しましょう。このワークフローにより、クリエイターは様々なスタイルでキャラクターの特徴を一貫して維持することができます。様々なスタイルを探求するために、自由に異なるチェックポイントやLoRAモデルを使用してくださいComfyUI Consistent Characters ワークフロー
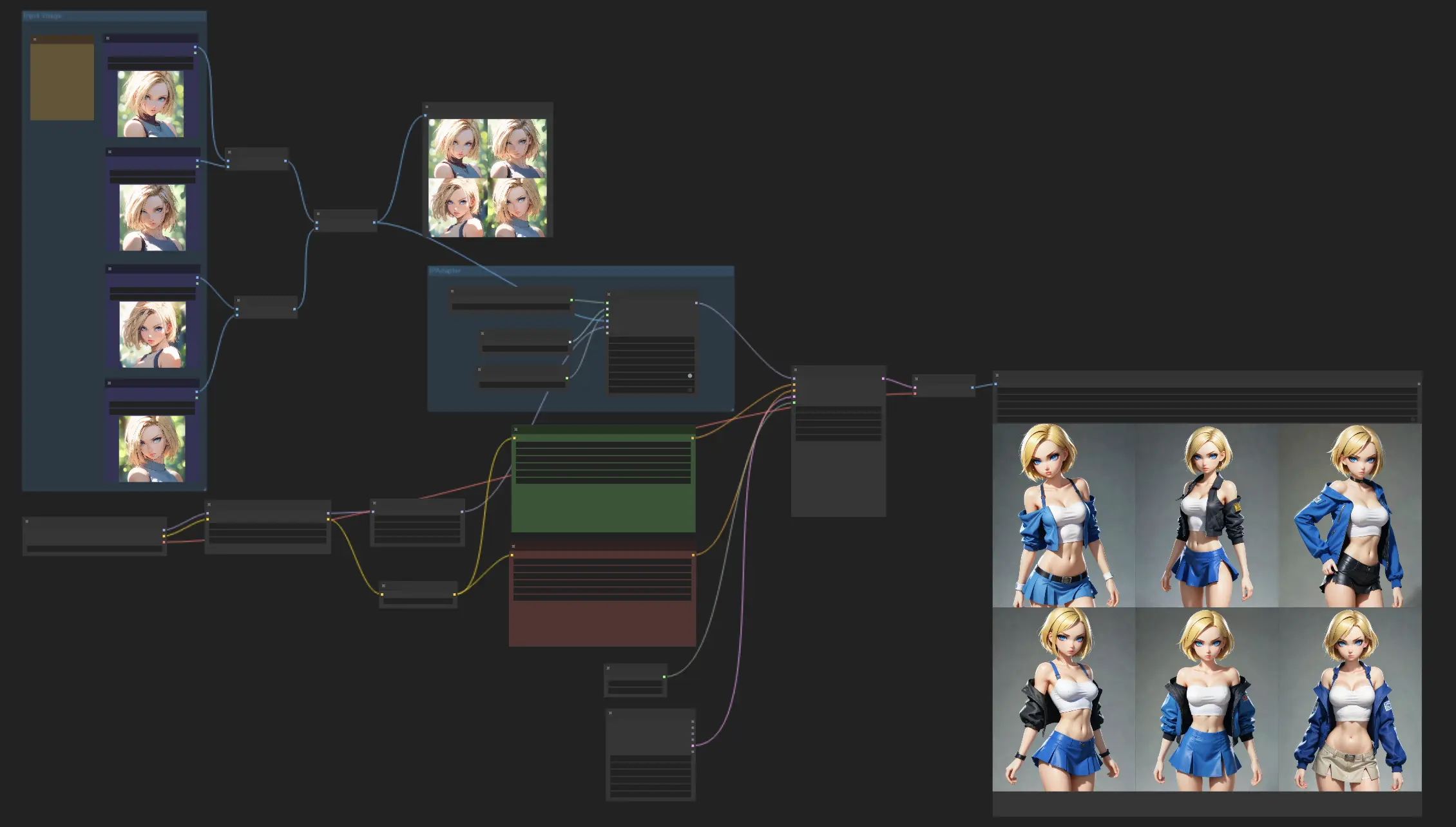
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Consistent Characters 例

ComfyUI Consistent Characters 説明
1. 一貫したキャラクターワークフロー
このワークフローは、IPAdapter Face Plus V2モデルを活用して、一貫した外観のキャラクターを作成することに重点を置いています。いくつかの参照画像をアップロードすることから始めるだけで、Face Plus V2モデルが魔法のように同じ顔の特徴を維持した一連の画像を作成します。様々なスタイルを探求しながら、キャラクターの外観を一貫させるために、自由に異なるチェックポイントやLoRAモデルを組み合わせてください。
2. IPAdapter FaceID/FaceID Plusの概要
v1.5 FaceID
このモデルは顔認識の基本バージョンであり、テキストプロンプト、コントロールネット、マスクによって拡張された変化に対応しています。平均的な調整力が特徴であり、一般的な顔の調整タスクに適しています。基本FaceIDモデルはCLIP vision encoderを使用しないため、複雑なエンコーダー設定の必要がない、よりシンプルな設定を意味します。
v1.5 FaceID Plus
FaceID Plusモデルは、より強力な画像間の調整効果を目的とした、より強力なバリアントです。ViT-H image encoderの使用を必要とし、詳細な顔のモデリングにはより高い処理能力が必要であることを示唆しています。
v1.5 FaceID Plus v2
FaceID Plusを改良したこのモデルは、さらに詳細な顔の調整を可能にする機能強化を導入しています。FaceID Plusと同様に、ViT-H image encoderを利用します。このモデルは、より細かなニーズに対応した顔のモデリングの品質向上を目指しています。
v1.5 FaceID Portrait
ポートレート専用に設計されたこのモデルは、CLIP vision encoderを使用しません。ポートレート設定内で高品質の顔画像を生成することに特化し、ポートレート画像生成のための特殊なアプローチを提供する可能性があります。
SDXL FaceID
FaceIDのSDXL版は、CLIP vision encoderを使用せず、SDXLアーキテクチャでの使用に適しています。スケーラブルなディープラーニングアーキテクチャに重点を置いたSDXLスイート内の基本モデルを表し、顔認識タスクに特化しています。
SDXL FaceID Plus v2
これは、ViT-H image encoderを利用するSDXLアーキテクチャ用のFaceIDモデルの強化版です。SDXLフレームワーク内で強化された顔の調整効果を提供することを目的とし、高品質の画像生成タスクを対象としています。
3. IPAdapter FaceID/FaceID Plusの使用方法
3.1. FaceID/FaceID Plusモデルの選択
画像作成を開始するには、希望するFaceIDまたはFaceID Plusモデルを選択します。設定内では、重みとノイズの両方を調整するオプションがあります。これらの調整は、生成された画像の外観を微調整し、目指す正確なルックを実現するための鍵となります。
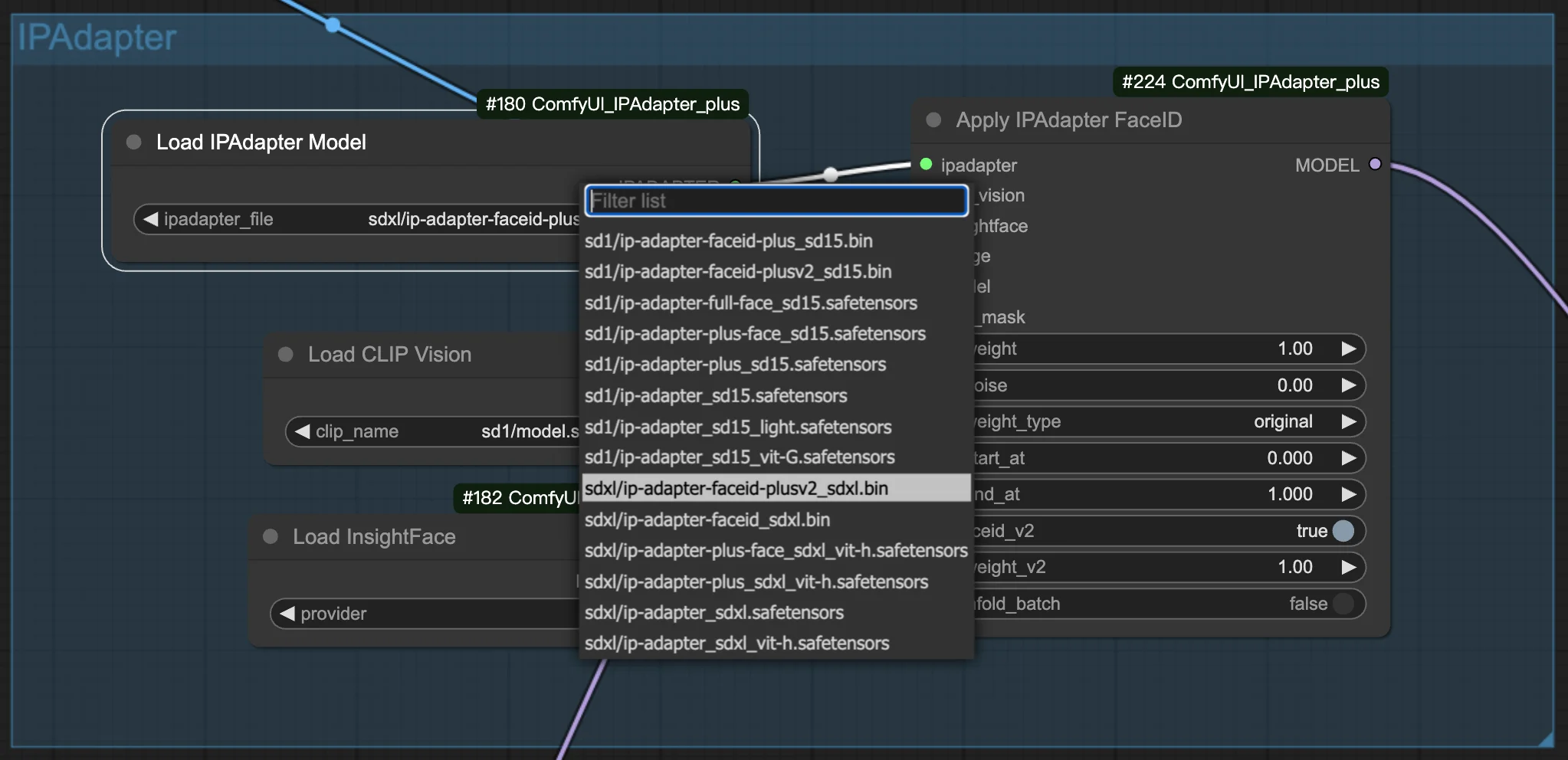
3.2. 参照画像の準備
IPAdapter FaceIDノードを使用する際、CLIP visionモデルは参照画像をリサイズし、224x224ピクセルの寸法に中央揃えすることで処理します。この自動調整は画像の中心に焦点を合わせるため、キャラクターの顔のような画像の主要被写体を中央に配置することが重要です。特にポートレートやランドスケープ画像で被写体が中央からずれていると、期待通りの結果が得られない可能性があります。最良の結果を得るには、正方形の画像を使用し、被写体を中央に配置することを強くお勧めします。





