Hunyuan Video | テキストからビデオへ
Hunyuan Videoは、Tencentによって開発されたオープンソースのビデオ基盤モデルです。これは、先端技術であるデータキュレーション、画像とビデオの共同トレーニング、最適化されたインフラストラクチャを活用して、高品質で大規模なビデオ生成を可能にします。ComfyUI Hunyuan Video ワークフロー
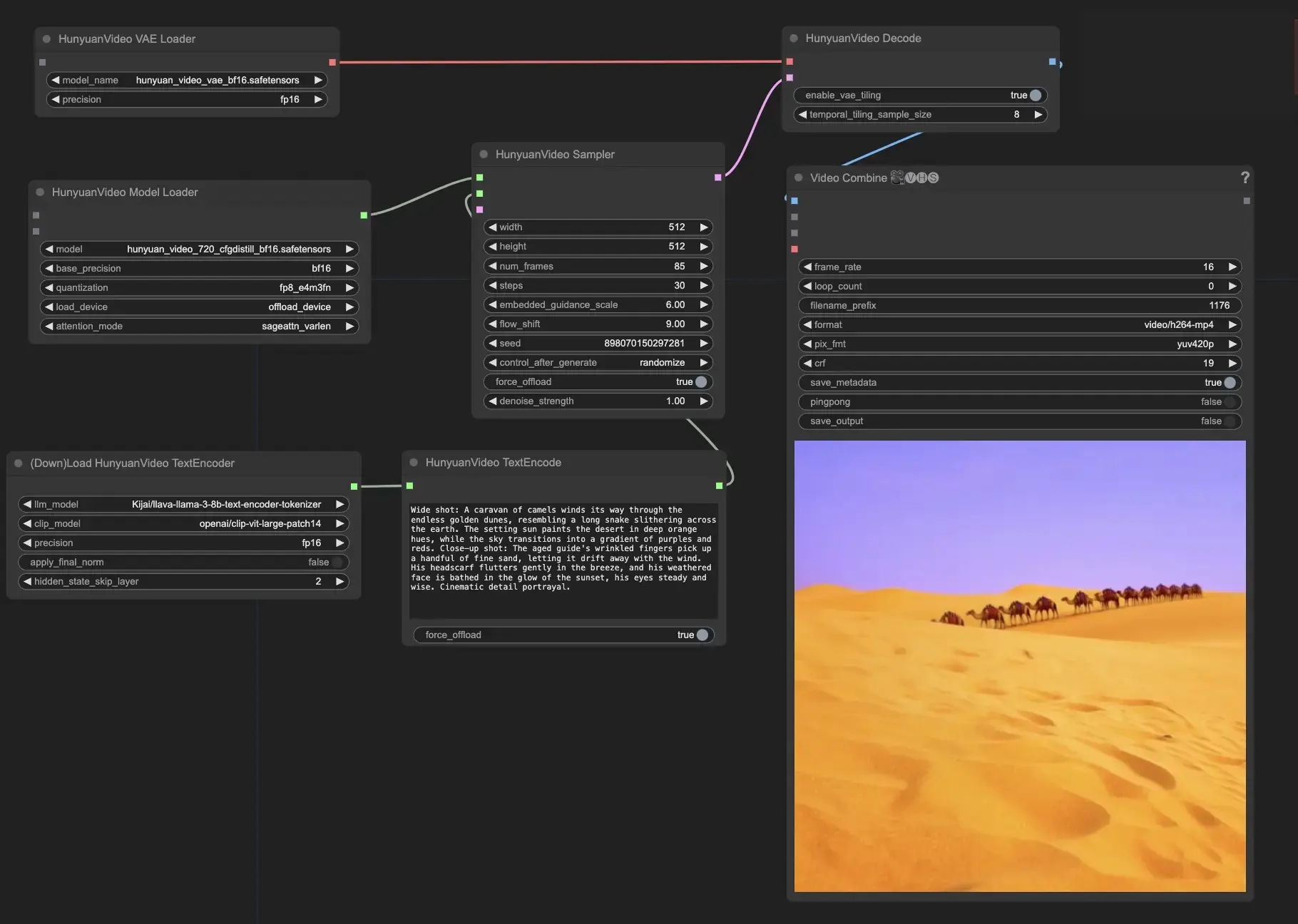
このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Hunyuan Video 例
ComfyUI Hunyuan Video 説明
は、Tencentという先進的な技術企業によって開発された、トップクラスのクローズドソースモデルに匹敵する、またはそれを超える性能を提供する革新的なオープンソースビデオ基盤モデルです。Hunyuan Videoは、データキュレーション、画像とビデオの共同モデルトレーニング、大規模モデルのトレーニングと推論のための効率的なインフラストラクチャなど、最新技術をモデル学習に取り入れています。Hunyuan Videoは、13億を超えるパラメータを持つ最大のオープンソースビデオ生成モデルを誇ります。
Hunyuan Videoの主要な機能には以下が含まれます
- Hunyuan Videoは、画像とビデオの両方を生成するための統一されたアーキテクチャを提供します。それは、「デュアルストリームからシングルストリーム」という特別なTransformerモデルデザインを使用しています。これは、モデルが最初にビデオとテキスト情報を別々に処理し、それから最終的な出力を作成するためにそれらを組み合わせることを意味します。これにより、モデルはビジュアルとテキストの説明の関係をよりよく理解できます。
- Hunyuan Videoのテキストエンコーダーは、Multimodal Large Language Model (MLLM)に基づいています。他の人気のあるテキストエンコーダー、例えばCLIPやT5-XXLと比較して、MLLMはテキストと画像の整合性に優れています。また、コンテンツに関するより詳細な説明と推論を提供できます。これにより、Hunyuan Videoは入力テキストにより正確に一致するビデオを生成できます。
- 高解像度および高フレームレートのビデオを効率的に処理するために、Hunyuan VideoはCausalConv3Dを備えた3D Variational Autoencoder (VAE)を使用します。このコンポーネントは、ビデオと画像を潜在空間と呼ばれる小さな表現に圧縮します。この圧縮空間で作業することで、Hunyuan Videoは、あまり多くの計算リソースを使用せずに、元の解像度とフレームレートでビデオをトレーニングおよび生成できます。
- Hunyuan Videoには、ユーザーの入力テキストをモデルの好みにより適合させるプロンプトリライトモデルが含まれています。利用可能なモードは2つあり、NormalとMasterです。Normalモードはユーザーの指示の理解を改善することに焦点を当て、Masterモードはより高い視覚品質のビデオを作成することに重点を置きます。ただし、Masterモードは時折、テキストの特定の詳細よりもビデオをより良く見せることを優先する場合があります。
ComfyUIでHunyuan Videoを使用する
このノードと関連するワークフローは、Kijaiによって開発されました。この革新的な作品に対し、Kijaiにすべての功績を捧げます。RunComfyプラットフォーム上では、彼の貢献をコミュニティに紹介しています。
- テキストプロンプトを入力する: HunyuanVideoTextEncodeノードの"prompt"フィールドに、希望するテキストプロンプトを入力します。に参考用のプロンプト例があります。
- HunyuanVideoSamplerノードで出力ビデオ設定を構成します:
- "width"および"height"を希望の解像度に設定します
- "num_frames"を希望するビデオ長にフレーム単位で設定します
- "steps"はノイズ除去/サンプリングステップの数を制御します(デフォルト: 30)
- "embedded_guidance_scale"はプロンプトガイダンスの強さを決定します(デフォルト: 6.0)
- "flow_shift"はビデオの長さに影響します(値が大きいほど短いビデオになります、デフォルト: 9.0)


