LTX Video | 画像+テキストからビデオ
Lightricksは、拡散ベースの技術を使用したビデオ生成モデルであるLTX Videoを開発しました。このモデルは、テキストプロンプトまたは画像とテキストの組み合わせプロンプトからビデオを生成できます。LTX Videoは768x512の解像度で24 FPSのビデオを出力します。LTXモデルは多様なデータセットでトレーニングされ、多様なビデオコンテンツを生成します。LTXモデルの技術を発見し、ComfyUI内で使用してみましょう。ComfyUI LTX Video ワークフロー
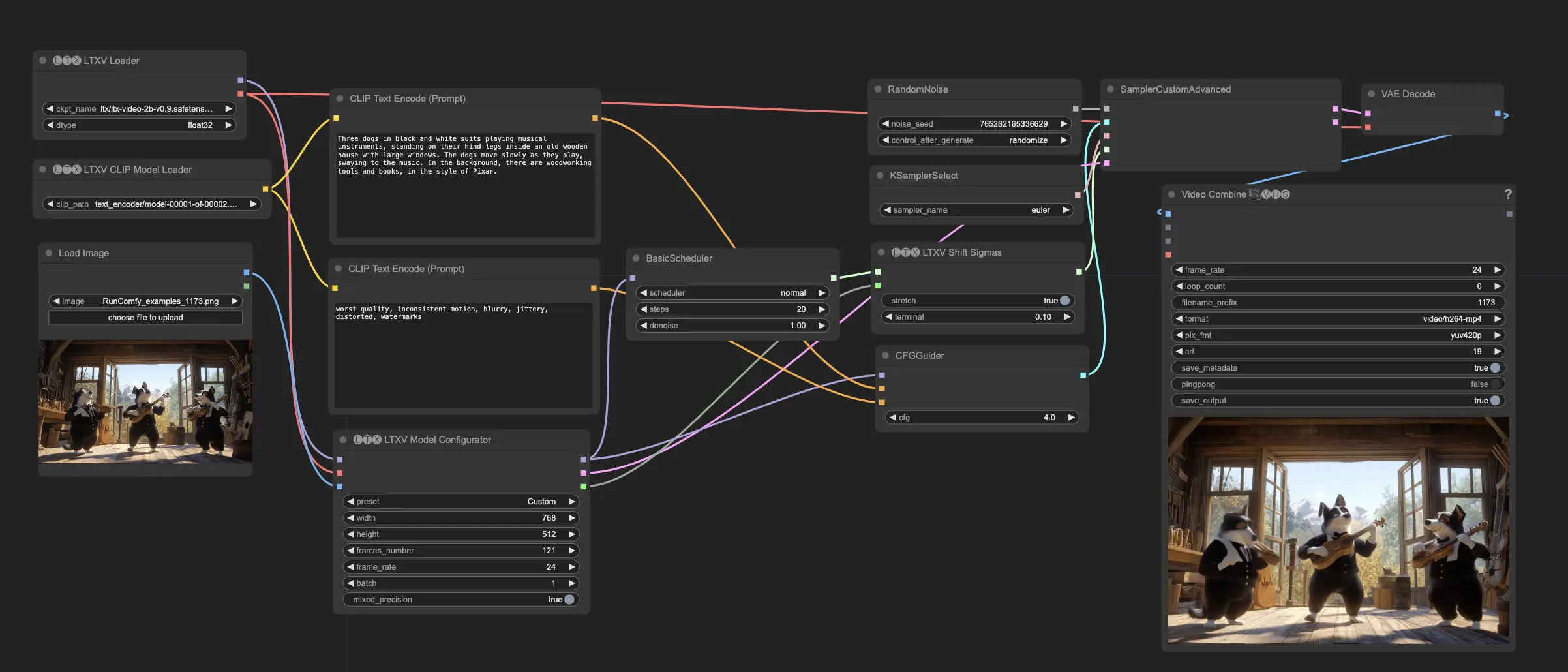
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI LTX Video 例
ComfyUI LTX Video 説明
LTX Videoは、Lightricksによって開発された拡散ベースのビデオ生成モデルです。テキストプロンプト(テキストからビデオ)または画像とテキストの組み合わせプロンプト(画像+テキストからビデオ)からビデオを生成することができます。LTX Videoは768x512の解像度で24 FPSのビデオを生成し、視聴するよりも速く生成されます。このモデルは多様なビデオを含む大規模なデータセットでトレーニングされ、高解像度でリアルで多様なビデオコンテンツを生成できます。
LTX Video ModelとComfyUI-LTXVideo NodesはLightricksによって開発されました。LTX Videoの創出における彼らの取り組みに全てのクレジットが与えられます。LTX VideoおよびLightricksのプロジェクトに関する詳細については、https://github.com/Lightricks/LTX-Video のGitHubリポジトリまたはhttps://www.lightricks.com/ltxv のWebサイトをご覧ください。
LTXモデルの技術
LTX Videoは、拡散ベースのアプローチを利用してビデオを生成します。拡散モデルは、ノイズの多い入力を複数のタイムステップにわたって徐々にノイズを除去して最終出力を生成します。LTX Videoの場合、モデルはノイズの多い潜在表現を入力として受け取り、それを反復的にノイズを除去してビデオフレームのシーケンスを生成します。このノイズ除去プロセスは、提供されたテキストまたは画像+テキストプロンプトによって導かれ、生成されるビデオのコンテンツとスタイルを制御します。
LTX Videoが採用する主な技術には次のものがあります:
- 拡散ベースのビデオ生成: 拡散モデルを活用することで、LTX Videoはリアルな動きとフレーム間の一貫性を持つ高品質なビデオを生成できます。
- テキストからビデオの合成: LTX Videoはテキスト記述のみに基づいてビデオを生成でき、自然言語プロンプトを使用してゼロからカスタムビデオを作成できます。
- 画像+テキストからビデオの合成: LTX Videoは、初期画像とテキストプロンプトを組み合わせてビデオを生成することもサポートしています。これにより、ユーザーはビデオの開始点を提供し、テキストを使用してそのコンテンツとスタイルを導くことができます。
ComfyUIでのLTX Videoワークフローの使用方法
- 入力の準備:
- デフォルトのワークフローは画像+テキストからビデオ生成です。初期画像と共にテキストプロンプトを提供します。画像は開始点として機能し、モデルはその画像と添付のテキストに基づいてビデオを生成します。このモデルは長く詳細なプロンプトを必要とします。プロンプトが短すぎると、品質が大きく低下します。
- モデルパラメータの設定:
- 生成されるコンテンツの解像度とフレーム数を設定します。解像度は32で割り切れるもので、フレーム数は8+1で割り切れる必要があります(例: 257フレーム)。LTXは720x1280ピクセル以下の解像度と257フレーム未満で最適に動作します。
- 拡散ステップ、ノイズスケジュール、ガイダンススケールなどの他のパラメータを要件に応じて調整します。これらのパラメータは生成される出力の品質と多様性を制御します。
- コンテンツの生成:
- 出力は指定された解像度とフレーム数を持ち、提供された入力プロンプトに合わせて生成されます。
LTXモデルの制限
- LTX Videoは事実情報を提供することを意図していませんし、できません。
- 統計モデルとして、LTX Videoはトレーニングデータに存在する既存の社会的バイアスを増幅する可能性があります。
- 生成されたビデオは、提供されたプロンプトと完全に一致しない場合があります。
- プロンプトのフォロー品質は、使用されるプロンプトスタイルに大きく依存します。
ライセンス
モデルを下で使用してください。

