






こんにちは、AI愛好家の皆さん! 👋 ComfyUI内でFLUXを使用するための入門ガイドへようこそ。FLUXはBlack Forest Labsによって開発された最先端のモデルです。🌟 このチュートリアルでは、ComfyUI FLUXの基本を掘り下げ、この強力なモデルが創造プロセスをどのように強化し、AI生成アートの境界を押し広げるのに役立つかを紹介します。🚀
カバーする内容は次のとおりです:
1. FLUXの紹介
2. FLUXの異なるバージョン
3. FLUXのハードウェア要件
- 3.1. FLUX.1 [Pro]のハードウェア要件
- 3.2. FLUX.1 [Dev]のハードウェア要件
- 3.3. FLUX.1 [Schnell]のハードウェア要件
4. ComfyUIへのFLUXのインストール方法
- 4.1. ComfyUIのインストールまたは更新
- 4.2. ComfyUI FLUXテキストエンコーダーとCLIPモデルのダウンロード
- 4.3. FLUX.1 VAEモデルのダウンロード
- 4.4. FLUX.1 UNETモデルのダウンロード
5. ComfyUI FLUXワークフロー | ダウンロード、オンラインアクセス、およびガイド
- 5.1. ComfyUIワークフロー: FLUX Txt2Img
- 5.2. ComfyUIワークフロー: FLUX Img2Img
- 5.3. ComfyUIワークフロー: FLUX LoRA
- 5.4. ComfyUIワークフロー: FLUX ControlNet
- 5.5. ComfyUIワークフロー: FLUX Inpainting
- 5.6. ComfyUIワークフロー: FLUX NF4 & アップスケール
- 5.7. ComfyUIワークフロー: FLUX IPAdapter
- 5.8. ComfyUIワークフロー: Flux LoRA Trainer
- 5.9. ComfyUIワークフロー: Flux Latent Upscale
1. FLUXの紹介
Black Forest Labsによる最先端のAIモデル、FLUX.1は、テキスト記述から画像を生成する方法を変革しています。入力プロンプトに密接に一致する驚くほど詳細で複雑な画像を生成する比類のない能力を持つFLUX.1は、競争相手から一線を画しています。FLUX.1の成功の秘密は、異なる種類のトランスフォーマーブロックを組み合わせたユニークなハイブリッドアーキテクチャにあり、12億パラメータの力を持っています。これにより、FLUX.1はテキスト記述を正確に表現する視覚的に魅力的な画像を生成することができます。
FLUX.1の最もエキサイティングな側面の1つは、さまざまなスタイルで画像を生成できることです。フォトリアリスティックからアーティスティックまで、FLUX.1は他の多くのモデルが達成に苦労するテキストを画像内にシームレスに組み込む能力も持っています。さらに、FLUX.1は優れたプロンプト遵守能力で知られており、簡単な説明から複雑な説明までを簡単に処理します。このため、FLUX.1はStable DiffusionやMidjourneyなどの他の有名なモデルと頻繁に比較され、その使いやすさと一流の結果により、しばしば好まれる選択肢となっています。
FLUX.1の印象的な能力は、素晴らしい視覚コンテンツの作成や革新的なデザインのインスピレーションから科学的な可視化の促進まで、幅広いアプリケーションにとって貴重なツールとなっています。テキスト記述から詳細で正確な画像を生成するFLUX.1の能力は、クリエイティブなプロフェッショナル、研究者、および愛好家にとって無限の可能性を開きます。AI生成画像の分野が進化し続ける中、FLUX.1は品質、汎用性、使いやすさの新しい基準を設定し、最前線に立っています。
画期的なFLUX.1を開発した先駆的なAI企業であるBlack Forest Labsは、AI業界の著名な人物であり、以前はStability AIのコアメンバーとして活躍していたRobin Rombachによって設立されました。Black Forest LabsとFLUX.1に関する革新的な仕事について詳しく知りたい方は、公式ウェブサイトhttps://blackforestlabs.ai/をぜひご覧ください。

2. FLUXの異なるバージョン
FLUX.1は、特定のユーザーのニーズに合わせて設計された3つの異なるバージョンがあります:
- FLUX.1 [pro]: これは最高品質とパフォーマンスを提供するトップクラスのバージョンで、プロフェッショナルな使用や高エンドのプロジェクトに最適です。
- FLUX.1 [dev]: 非商用利用向けに最適化されており、高品質な出力を維持しながら効率的で、開発者や愛好家に最適です。
- FLUX.1 [schnell]: このバージョンはスピードと軽量さを重視しており、ローカル開発や個人プロジェクトに最適です。また、Apache 2.0ライセンスの下でオープンソースで提供されており、幅広いユーザーにアクセス可能です。
| Name | HuggingFace repo | License | md5sum |
FLUX.1 [pro] |
Only available in our API. | ||
FLUX.1 [dev] |
https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev Non-Commercial License | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] |
https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. FLUXのハードウェア要件
3.1. FLUX.1 [Pro]のハードウェア要件
- 推奨GPU: NVIDIA RTX 4090または同等の24GB以上のVRAMを持つGPU。モデルは複雑な操作を処理できる高性能GPUに最適化されています。
- RAM: 32GB以上のシステムメモリ。
- ディスクスペース: 約30GB。
- コンピュート要件: 高精度が必要です。メモリエラーを回避するためにFP16(半精度)を使用します。最高の結果を得るために、
fp16Clipモデルバリアントを使用することをお勧めします。 - その他の要件: 高速SSDを使用すると、読み込み時間と全体的なパフォーマンスが向上します。
3.2. FLUX.1 [Dev]のハードウェア要件
- 推奨GPU: NVIDIA RTX 3080/3090または同等の16GB以上のVRAMを持つGPU。このバージョンはProモデルに比べてハードウェア要求が少し緩やかですが、それでもかなりのGPUパワーが必要です。
- RAM: 16GB以上のシステムメモリ。
- ディスクスペース: 約25GB。
- コンピュート要件: Proと同様にFP16モデルを使用しますが、低精度計算に対する若干の許容があります。
fp16またはfp8ClipモデルをGPUの能力に応じて使用できます。 - その他の要件: 最適なパフォーマンスを得るために高速SSDを推奨します。
3.3. FLUX.1 [Schnell]のハードウェア要件
- 推奨GPU: NVIDIA RTX 3060/4060または同等の12GB VRAMを持つGPU。このバージョンは高速な推論と低いハードウェア要求に最適化されています。
- RAM: 8GB以上のシステムメモリ。
- ディスクスペース: 約15GB。
- コンピュート要件: このバージョンは要求が少なく、メモリ不足の場合には
fp8計算を許容します。速度に重点を置いており、超高品質よりも効率とスピードに焦点を当てています。 - その他の要件: SSDは役立ちますが、ProおよびDevバージョンほど重要ではありません。
4. ComfyUIへのFLUXのインストール方法
4.1. ComfyUIのインストールまたは更新
ComfyUI環境内でFLUX.1を効果的に使用するには、最新バージョンのComfyUIがインストールされていることが重要です。このバージョンはFLUX.1モデルに必要な機能と統合をサポートしています。
4.2. ComfyUI FLUXテキストエンコーダーとCLIPモデルのダウンロード
FLUX.1を使用したテキストから画像への生成を最適化し、正確にするためには、特定のテキストエンコーダーとCLIPモデルをダウンロードする必要があります。システムのハードウェアに応じて、次のモデルが必要です:
ダウンロードとインストールの手順:
clip_l.safetensorsモデルをダウンロードします。- システムのVRAMとRAMに応じて、`t
- Depending on your system's VRAM and RAM, download either
t5xxl_fp8_e4m3fn.safetensors(for lower VRAM) ort5xxl_fp16.safetensors(for higher VRAM and RAM). - Place the downloaded models in the
ComfyUI/models/clip/directory. Note: If you have previously used SD 3 Medium, you may already have these models.
4.3. FLUX.1 VAEモデルのダウンロード
Variational Autoencoder (VAE)モデルは、FLUX.1の画像生成品質を向上させるために重要です。以下のVAEモデルがダウンロード可能です:
| File Name | Size | Link |
ae.safetensors |
335 MB | ダウンロード(新しいタブで開く) |
ダウンロードとインストールの手順:
ae.safetensorsモデルファイルをダウンロードします。- ダウンロードしたファイルを
ComfyUI/models/vaeディレクトリに配置します。 - 簡単に識別できるように、ファイル名を
flux_ae.safetensorsに変更することをお勧めします。
4.4. FLUX.1 UNETモデルのダウンロード
UNETモデルは、FLUX.1の画像合成のバックボーンです。システムの仕様に応じて、異なるバリアントを選択できます:
ダウンロードとインストールの手順:
- システムのメモリ構成に基づいて適切なUNETモデルをダウンロードします。
- ダウンロードしたモデルファイルを
ComfyUI/models/unet/ディレクトリに配置します。
5. ComfyUI FLUXワークフロー | ダウンロード、オンラインアクセス、およびガイド
ComfyUI FLUXワークフローを継続的に更新し、ComfyUI FLUXを使用して素晴らしい画像を生成するための最新かつ包括的なワークフローを提供します。
5.1. ComfyUIワークフロー: FLUX Txt2Img
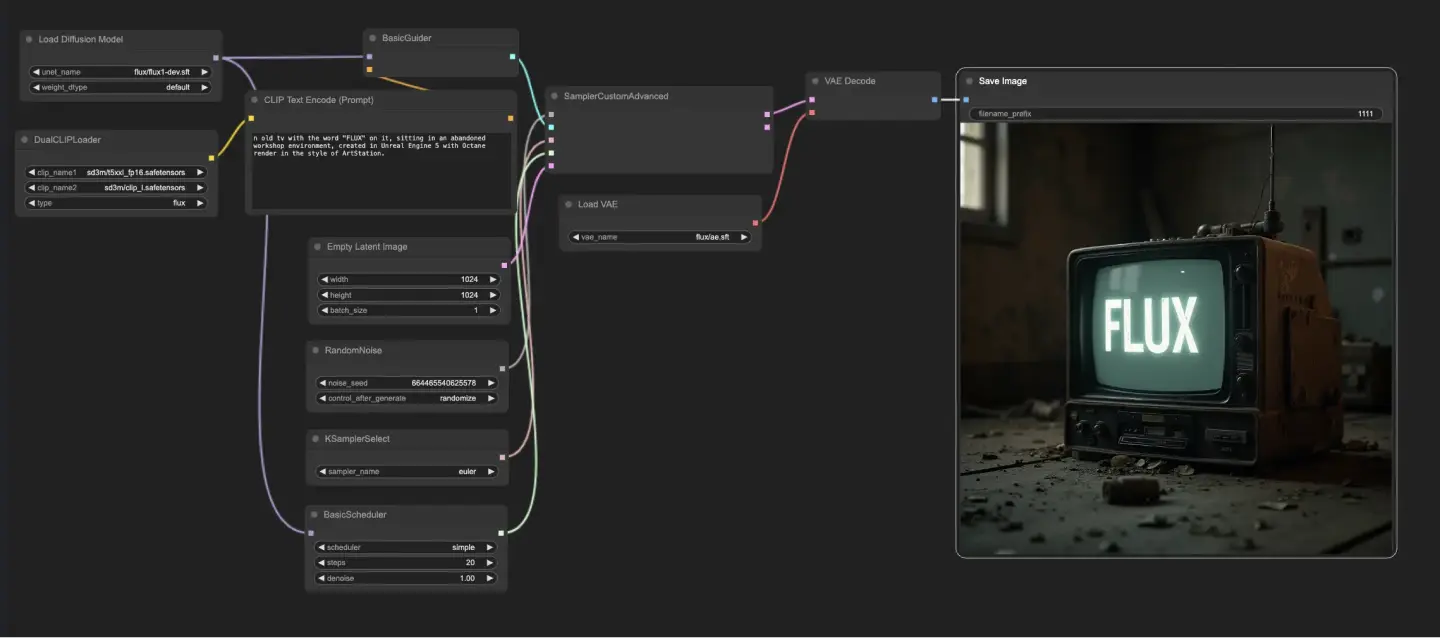
5.1.1. ComfyUI FLUX Txt2Img : <a href="https://cdn.runcomfy.net/tutorial_download/162/01.json" target="_blank">ダウンロード</a>
5.1.2. ComfyUI FLUX Txt2Img オンラインバージョン: ComfyUI FLUX Txt2Img
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX Txt2Imgの体験を簡単に楽しむことができます。
5.1.3. ComfyUI FLUX Txt2Imgの説明:
ComfyUI FLUX Txt2Imgワークフローは、FLUX UNET(UNETLoader)、FLUX CLIP(DualCLIPLoader)、およびFLUX VAE(VAELoader)を含む主要コンポーネントを読み込むことから始まります。これらは、ComfyUI FLUX画像生成プロセスの基盤を形成します。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: テキストエンコーディングのためのCLIPモデルを読み込みます。
- 埋め込みモデル1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 埋め込みモデル2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- グルーピング: CLIPモデルのグルーピング戦略はfluxです
- VAELoader: 潜在表現のデコードのためのVariational Autoencoder (VAE)モデルを読み込みます。
- VAEモデル: flux/ae.sft
テキストプロンプトは、CLIPTextEncodeを使用してエンコードされます。このノードは、テキストプロンプトを入力として受け取り、エンコードされたテキストコンディショニングを出力し、ComfyUI FLUXの生成中にガイドします。
ComfyUI FLUX生成プロセスを開始するために、EmptyLatentImageを使用して空の潜在表現が作成されます。これは、ComfyUI FLUXが基盤として構築する出発点です。
BasicGuiderは、ComfyUI FLUX生成プロセスをガイドする重要な役割を果たします。エンコードされたテキストコンディショニングとロードされたFLUX UNETを入力として受け取り、生成された出力が提供されたテキスト記述と一致するようにします。
KSamplerSelectは、ComfyUI FLUX生成のためのサンプリング方法を選択することができます。RandomNoiseは、ComfyUI FLUXの入力としてランダムノイズを生成します。BasicSchedulerは、生成プロセスの各ステップでのノイズレベル(シグマ)をスケジュールし、最終出力の詳細と明瞭さを制御します。
SamplerCustomAdvancedは、ComfyUI FLUX Txt2Imgワークフローのすべてのコンポーネントを統合します。ランダムノイズ、ガイダー、選択されたサンプラー、スケジュールされたシグマ、および空の潜在表現を入力として受け取り、テキストプロンプトを表す潜在表現を生成します。
最後に、VAEDecodeは、生成された潜在表現をロードされたFLUX VAEを使用して最終出力にデコードします。SaveImageは、生成された出力を指定された場所に保存し、ComfyUI FLUX Txt2Imgワークフローによって可能になった素晴らしい創造物を保存します。
5.2. ComfyUIワークフロー: FLUX Img2Img
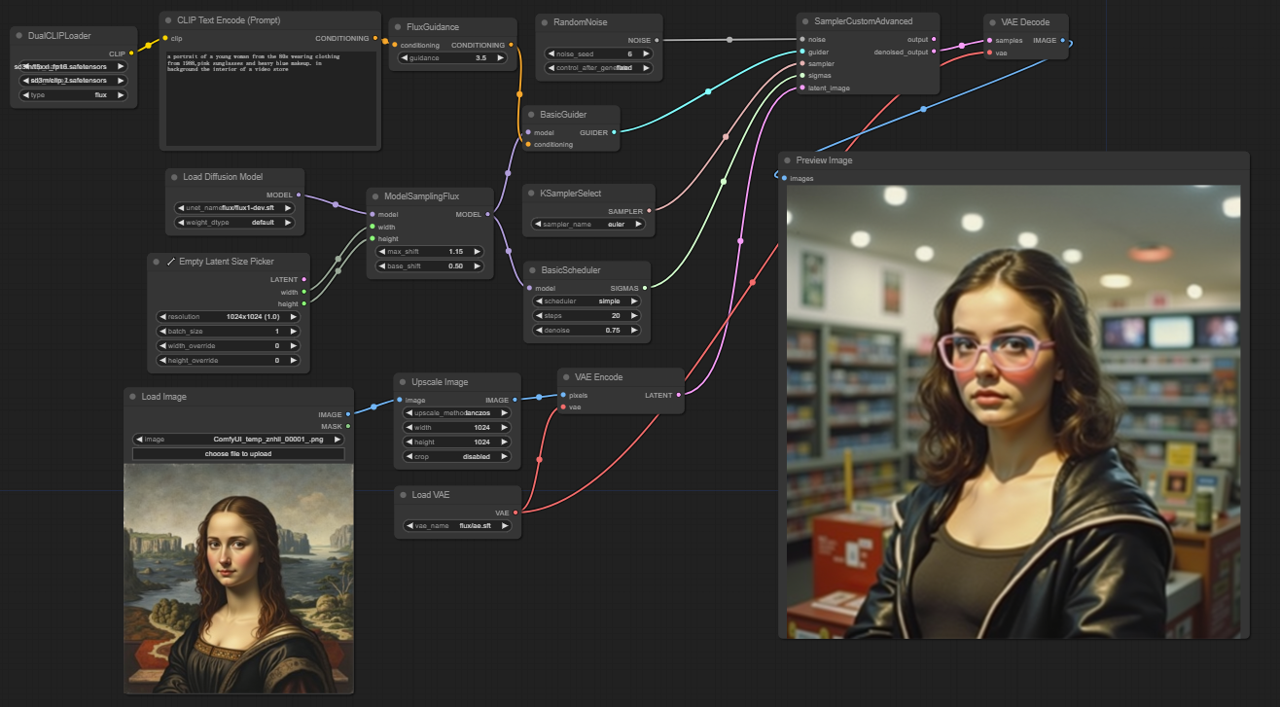
5.2.1. ComfyUI FLUX Img2Img: <a href="https://cdn.runcomfy.net/tutorial_download/162/02.json" target="_blank">ダウンロード</a>
5.2.2. ComfyUI FLUX Img2Img オンラインバージョン: ComfyUI FLUX Img2Img
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX Img2Imgの体験を簡単に楽しむことができます。
5.2.3. ComfyUI FLUX Img2Imgの説明:
ComfyUI FLUX Img2Imgワークフローは、テキストプロンプトと入力表現の両方に基づいて出力を生成するために、ComfyUI FLUXの力を活用します。最初に、CLIPモデル(DualCLIPLoader)、UNETモデル(UNETLoader)、およびVAEモデル(VAELoader)などの必要なコンポーネントを読み込みます。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: テキストエンコーディングのためのCLIPモデルを読み込みます。
- 埋め込みモデル1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 埋め込みモデル2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- グルーピング: CLIPモデルのグルーピング戦略はfluxです
- VAELoader: 潜在表現のデコードのためのVariational Autoencoder (VAE)モデルを読み込みます。
- VAEモデル: flux/ae.sft
入力表現は、LoadImageを使用して読み込まれ、ImageScaleで目的のサイズにスケーリングされ、ComfyUI FLUXとの互換性を確保します。
スケーリングされた入力表現は、VAEEncodeを使用してエンコードされ、潜在表現に変換されます。この潜在表現は、入力の本質的な特徴と詳細を捉え、ComfyUI FLUXが作業するための基盤を提供します。
desired modifications or enhancements to the input, is encoded using the CLIPTextEncode. The FluxGuidance then applies guidance to the conditioning based on the specified guidance scale, influencing the strength of the text prompt's influence on the final output.
The ModelSamplingFlux sets the sampling parameters for ComfyUI FLUX, including the timestep respacing, padding ratio, and output dimensions. These parameters control the granularity and resolution of the generated output.
The KSamplerSelect allows you to choose the sampling method for ComfyUI FLUX generation, while the BasicGuider guides the generation process based on the encoded text conditioning and the loaded FLUX UNET.
Random noise is generated using the RandomNoise, and the BasicScheduler schedules the noise levels (sigmas) for each step in the generation process. These components introduce controlled variations and fine-tune the details in the final output.
The SamplerCustomAdvanced brings together the random noise, guider, selected sampler, scheduled sigmas, and the latent representation of the input. Through an advanced sampling process, it generates a latent representation that incorporates the modifications specified by the text prompt while preserving the essential features of the input.
Finally, the VAEDecode decodes the denoised latent representation into the final output using the loaded FLUX VAE. The PreviewImage displays a preview of the generated output, showcasing the stunning results achieved by the ComfyUI FLUX Img2Img workflow.
5.3. ComfyUIワークフロー: FLUX LoRA
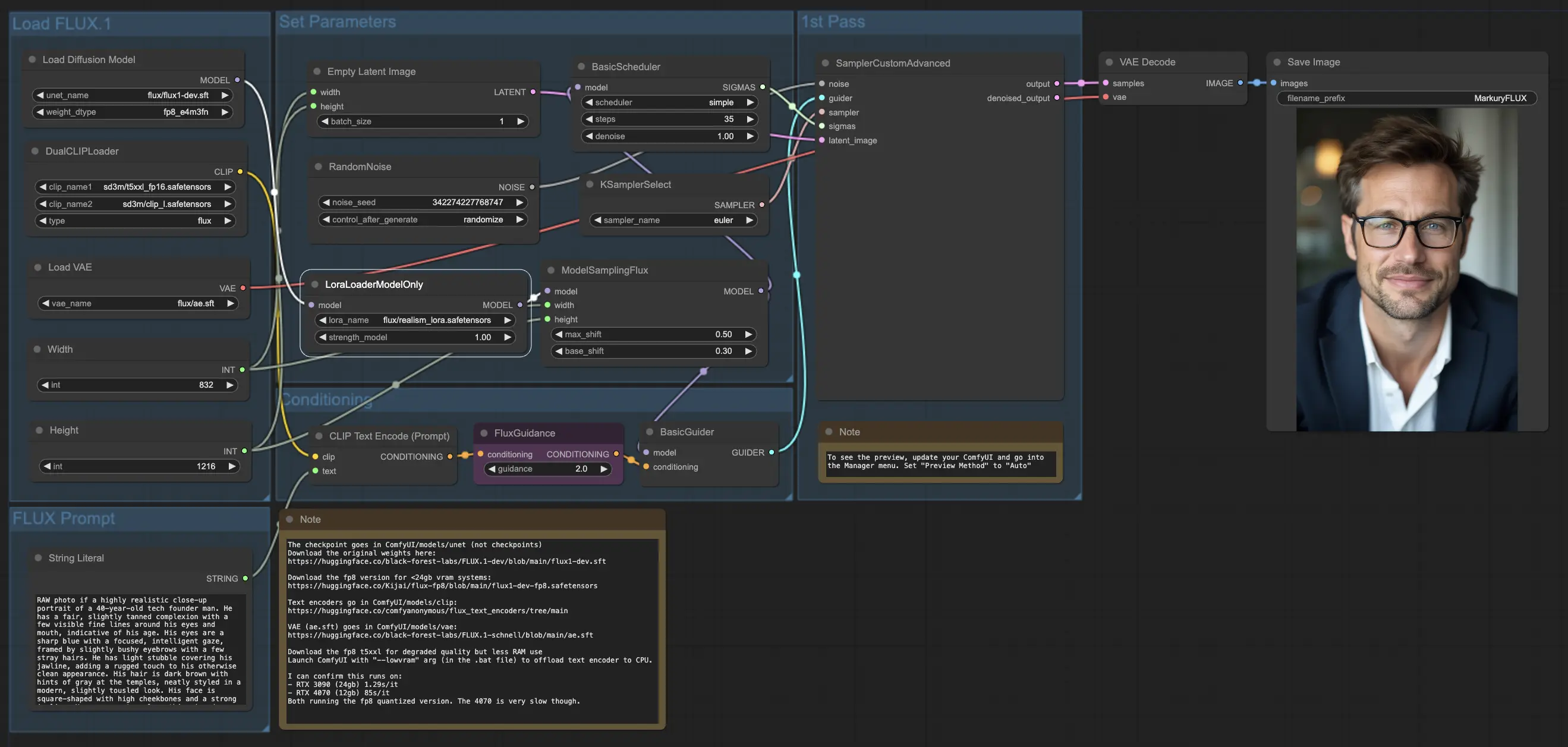
5.3.1. ComfyUI FLUX LoRA: <a href="https://cdn.runcomfy.net/tutorial_download/162/03.json" target="_blank">ダウンロード</a>
5.3.2. ComfyUI FLUX LoRA オンラインバージョン: ComfyUI FLUX LoRA
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX LoRAの体験を簡単に楽しむことができます。
5.3.3. ComfyUI FLUX LoRAの説明:
ComfyUI FLUX LoRAワークフローは、Low-Rank Adaptation (LoRA)の力を活用して、ComfyUI FLUXのパフォーマンスを向上させます。最初に、必要なコンポーネントをロードします。これには、UNETモデル(UNETLoader)、CLIPモデル(DualCLIPLoader)、VAEモデル(VAELoader)、およびLoRAモデル(LoraLoaderModelOnly)が含まれます。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: flux/flux1-dev.sft
- DualCLIPLoader: テキストエンコーディングのためのCLIPモデルを読み込みます。
- 埋め込みモデル1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 埋め込みモデル2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- グルーピング: CLIPモデルのグルーピング戦略はfluxです
- VAELoader: 潜在表現のデコードのためのVariational Autoencoder (VAE)モデルを読み込みます。
- VAEモデル: flux/ae.sft
- LoraLoaderModelOnly: UNETモデルを強化するためのLoRAモデル(Low-Rank Adaptation)を読み込みます。
- LoaderModel: flux/realism_lora.safetensors
テキストプロンプトは、String Literalを使用して指定されます。次に、CLIPTextEncodeを使用してテキストプロンプトをエンコードし、ComfyUI FLUX生成プロセスをガイドするエンコードされたテキストコンディショニングを生成します。
FluxGuidanceは、エンコードされたテキストコンディショニングにガイダンスを適用し、ComfyUI FLUXのテキストプロンプトへの遵守の強度と方向性に影響を与えます。
空の潜在表現は、EmptyLatentImageを使用して生成の出発点 として作成されます。生成された出力の幅と高さは、Int Literalを使用して指定され、最終結果の希望する寸法を確保します。
ModelSamplingFluxは、ComfyUI FLUXのサンプリングパラメータを設定し、パディング比率とタイムステップリスペーシングを含みます。これらのパラメータは、生成された出力の解像度と粒度を制御します。
KSamplerSelectは、ComfyUI FLUX生成のためのサンプリング方法を選択することができます。BasicGuiderは、エンコードされたテキストコンディショニングとロードされたFLUX UNETを基に生成プロセスをガイドします。
ランダムノイズは、RandomNoiseを使用して生成され、BasicSchedulerはComfyUI FLUX生成プロセスの各ステップでのノイズレベル(シグマ)をスケジュールします。これらのコンポーネントは、制御された変動を導入し、最終出力の詳細を微調整します。
SamplerCustomAdvancedは、ランダムノイズ、ガイダー、選択されたサンプラー、スケジュールされたシグマ、および空の潜在表現を統合します。高度なサンプリングプロセスを通じて、テキストプロンプトを表す潜在表現を生成し、FLUXとFLUX LoRAの力を活用します。
最後に、VAEDecodeは、生成された潜在表現をロードされたFLUX VAEを使用して最終出力にデコードします。SaveImageは、生成された出力を指定された場所に保存し、ComfyUI FLUX LoRAワークフローによって可能になった素晴らしい創造物を保存します。
5.4. ComfyUIワークフロー: FLUX ControlNet
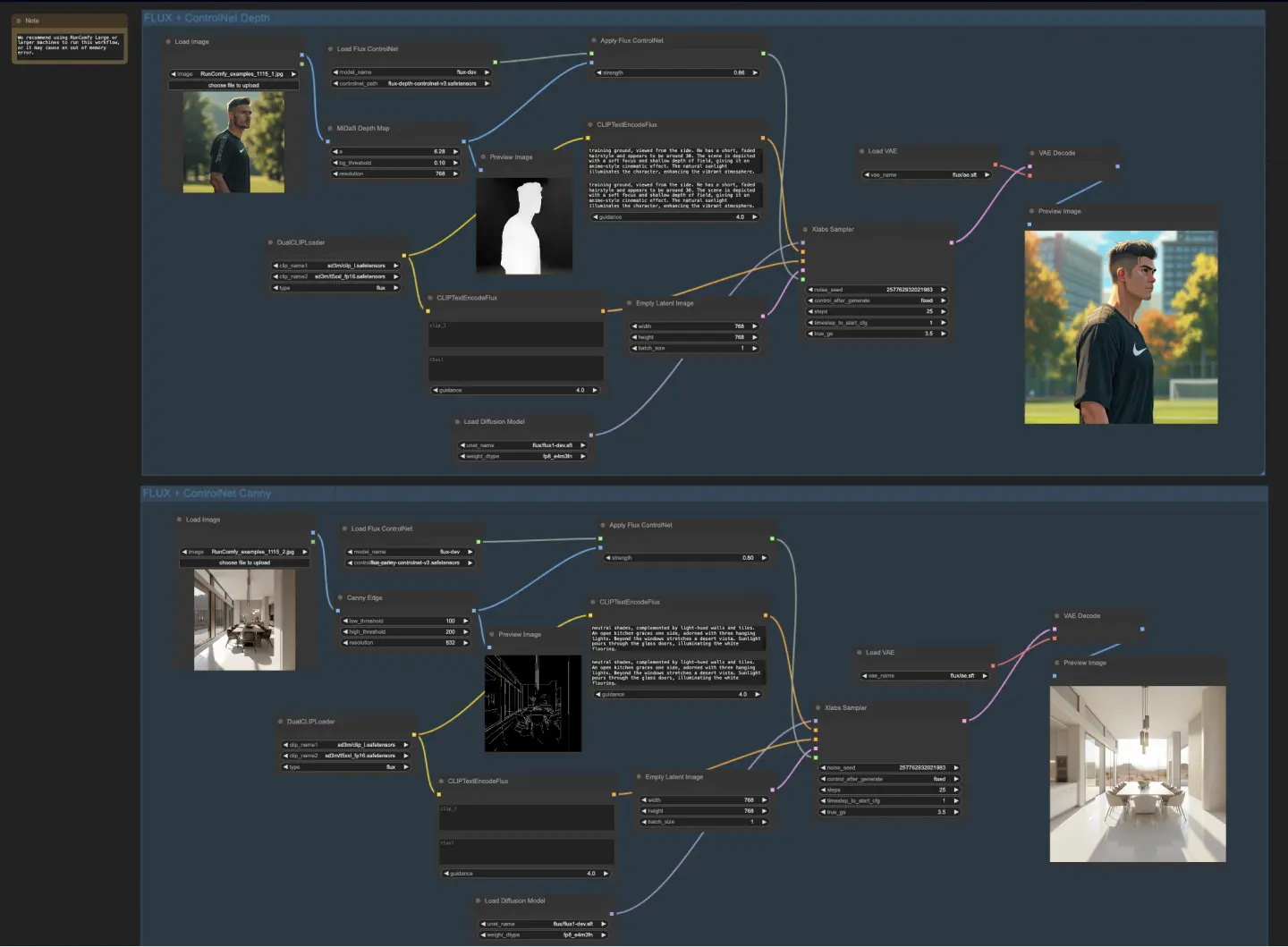
5.4.1. ComfyUI FLUX ControlNet: <a href="https://cdn.runcomfy.net/tutorial_download/162/04.json" target="_blank">ダウンロード</a>
5.4.2. ComfyUI FLUX ControlNet オンラインバージョン: ComfyUI FLUX ControlNet
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX ControlNetの体験を簡単に楽しむことができます。
5.4.3. ComfyUI FLUX ControlNetの説明:
ComfyUI FLUX ControlNetワークフローは、ControlNetとComfyUI FLUXの統合を示し、出力生成を強化します。ワークフローは、深度ベースのコンディショニングとCannyエッジベースのコンディショニングの2つの例を示します。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: flux/flux1-dev.sft
- DualCLIPLoader: テキストエンコーディングのためのCLIPモデルを読み込みます。
- 埋め込みモデル1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 埋め込みモデル2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- グルーピング: CLIPモデルのグルーピング戦略はfluxです
- VAELoader: 潜在表現のデコードのためのVariational Autoencoder (VAE)モデルを読み込みます。
- VAEモデル: flux/ae.sft
深度ベースのワークフローでは、入力表現はMiDaS-DepthMapPreprocessorを使用して前処理され、深度マップが生成されます。深度マップは、ロードされたFLUX ControlNetと共にApplyFluxControlNet (Depth)を通じて渡され、深度コンディショニングが行われます。生成されたFLUX ControlNetコンディションは、ロードされたFLUX UNET、エンコードされたテキストコンディショニング、ネガティブテキストコンディショニング、および空の潜在表現と共にXlabsSampler (Depth)に入力されます。XlabsSamplerは、これらの入力に基づいて潜在表現を生成し、VAEDecodeを使用して最終出力にデコードされます。
- MiDaS-DepthMapPreprocessor (Depth): MiDaSを使用して入力画像を深度推定のために前処理します。
- LoadFluxControlNet: ControlNetモデルを読み込みます。
- パス: flux-depth-controlnet.safetensors
同様に、Cannyエッジベースのワークフローでは、入力表現はCannyEdgePreprocessorを使用して前処理され、Cannyエッジが生成されます。Cannyエッジ表現は、ロードされたFLUX ControlNetと共にApplyFluxControlNet (Canny)を通じて渡され、Cannyエッジコンディショニングが行われます。生成されたFLUX ControlNetコンディションは、ロードされたFLUX UNET、エンコードされたテキストコンディショニング、ネガティブテキストコンディショニング、および空の潜在表現と共にXlabsSampler (Canny)に入力されます。XlabsSamplerは、これらの入力に基づいて潜在表現を生成し、VAEDecodeを使用して最終出力にデコードされます。
- CannyEdgePreprocessor (Canny): Cannyエッジ検出のために入力画像を前処理します。
- LoadFluxControlNet: ControlNetモデルを読み込みます。
- パス: flux-canny-controlnet.safetensors
ComfyUI FLUX ControlNetワークフローは、必要なコンポーネント(DualCLIPLoader、UNETLoader、VAELoader、LoadFluxControlNet)を読み込み、テキストプロンプトをエンコード(CLIPTextEncodeFlux)、空の潜在表現を作成(EmptyLatentImage)、生成されたおよび前処理された出力をプレビュー(PreviewImage)するノードを組み込んでいます。
FLUX ControlNetの力を活用することにより、ComfyUI FLUX ControlNetワークフローは、深度マップやCannyエッジなどの特定のコンディショニングに一致する出力の生成を可能にします。この追加の制御とガイダンスのレベルは、生成プロセスの柔軟性と精度を向上させ、ComfyUI FLUXを使用して素晴らしくコンテキストに関連する出力を作成することを可能にします。
5.5. ComfyUIワークフロー: FLUX Inpainting
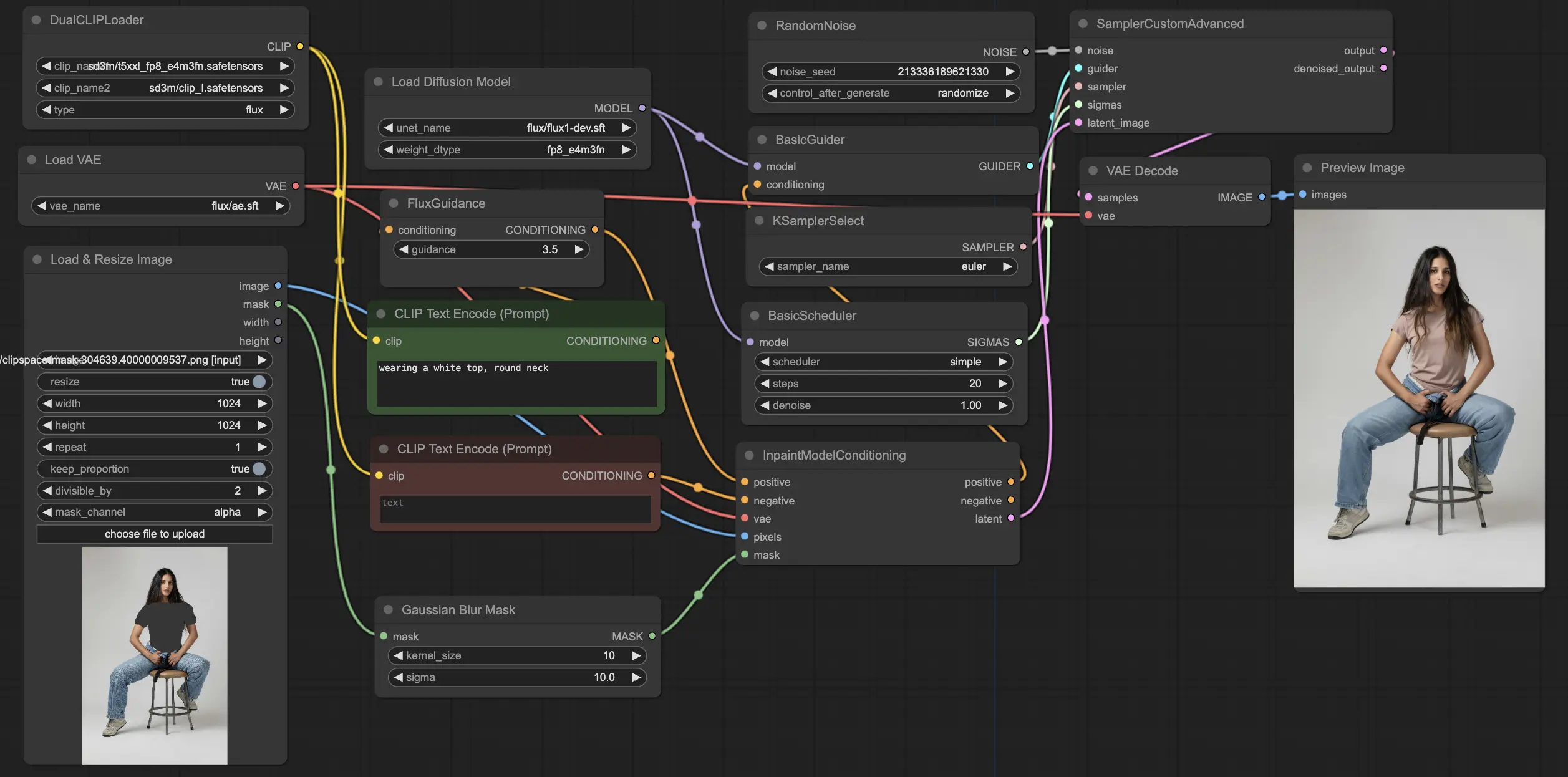
5.5.1. ComfyUI FLUX Inpainting: <a href="https://cdn.runcomfy.net/tutorial_download/162/05.json" target="_blank">ダウンロード</a>
5.5.2. ComfyUI FLUX Inpainting オンラインバージョン: ComfyUI FLUX Inpainting
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX Inpaintingの体験を簡単に楽しむことができます。
5.5.3. ComfyUI FLUX Inpaintingの説明:
ComfyUI FLUX Inpaintingワークフローは、周囲のコンテキストと提供されたテキストプロンプトに基づいて、出力の欠落またはマスクされた領域を埋めるインペインティングの能力を示します。ワークフローは、必要なコンポーネント(UNETモデル(UNETLoader)、VAEモデル(VAELoader)、およびCLIPモデル(DualCLIPLoader))を読み込むことから始まります。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: flux/flux1-schnell.sft; flux/flux1-dev.sft
- DualCLIPLoader: テキストエンコーディングのためのCLIPモデルを読み込みます。
- 埋め込みモデル1: sd3m/t5xxl_fp8_e4m3fn.safetensors; sd3m/t5xxl_fp16.safetensors
- 埋め込みモデル2: sd3m/clip_g.safetensors; sd3m/clip_l.safetensors
- グルーピング: CLIPモデルのグルーピング戦略はfluxです
- VAELoader: 潜在表現のデコードのためのVariational Autoencoder (VAE)モデルを読み込みます。
- VAEモデル: flux/ae.sft
ポジティブおよびネガティブテキストプロンプトは、希望するインペインティング領域の内容とスタイルを記述し、CLIPTextEncodesを使用してエンコードされます。ポジティブテキストコンディショニングは、ComfyUI FLUXインペインティングプロセスをガイドするためにさらにガイダンスされます。
入力表現とマスクは、LoadAndResizeImageを使用して読み込まれ、ComfyUI FLUXの要件に適合するようにリサイズされます。ImpactGaussianBlurMaskは、マスクにガウシアンブラーを適用し、インペインティング領域と元の表現との間のスムーズな移行を作成します。
InpaintModelConditioningは、ガイドされたポジティブテキストコンディショニング、エンコードされたネガティブテキストコンディショニング、ロードされたFLUX VAE、ロードおよびリサイズされた入力表現、ぼかされたマスクを組み合わせて、FLUXインペインティングのためのコンディショニングを準備します。このコンディショニングは、ComfyUI FLUXインペインティングプロセスの基盤として機能します。
ランダムノイズは、RandomNoiseを使用して生成され、サンプリング方法はKSamplerSelectを使用して選択されます。BasicSchedulerは、ComfyUI FLUXインペインティングプロセスのノイズレベル(シグマ)をスケジュールし、インペインティング領域の詳細と明瞭さを制御します。
BasicGuiderは、準備されたコンディショニングとロードされたFLUX UNETを基にComfyUI FLUXインペインティングプロセスをガイドします。SamplerCustomAdvancedは、高度なサンプリングプロセスを実行し、生成されたランダムノイズ、ガイダー、選択されたサンプラー、スケジュールされたシグマ、および入力の潜在表現を入力として受け取り、インペインティングされた潜在表現を出力します。
最後に、VAEDecodeは、インペインティングされた潜在表現をロードされたFLUX VAEを使用して最終出力にデコードします。PreviewImageは、FLUXの印象的なインペインティング能力を示す最終出力を表示します。
FLUXの力と慎重に設計されたインペインティングワークフローを活用することにより、FLUX Inpaintingは視覚的に一貫性があり、コンテキストに関連するインペインティング出力の作成を可能にします。欠落した部分の復元、不要なオブジェクトの除去、特定の領域の修正など、ComfyUI FLUXインペインティングワークフローは編集と操作のための強力なツールを提供します。
5.6. ComfyUIワークフロー: FLUX NF4
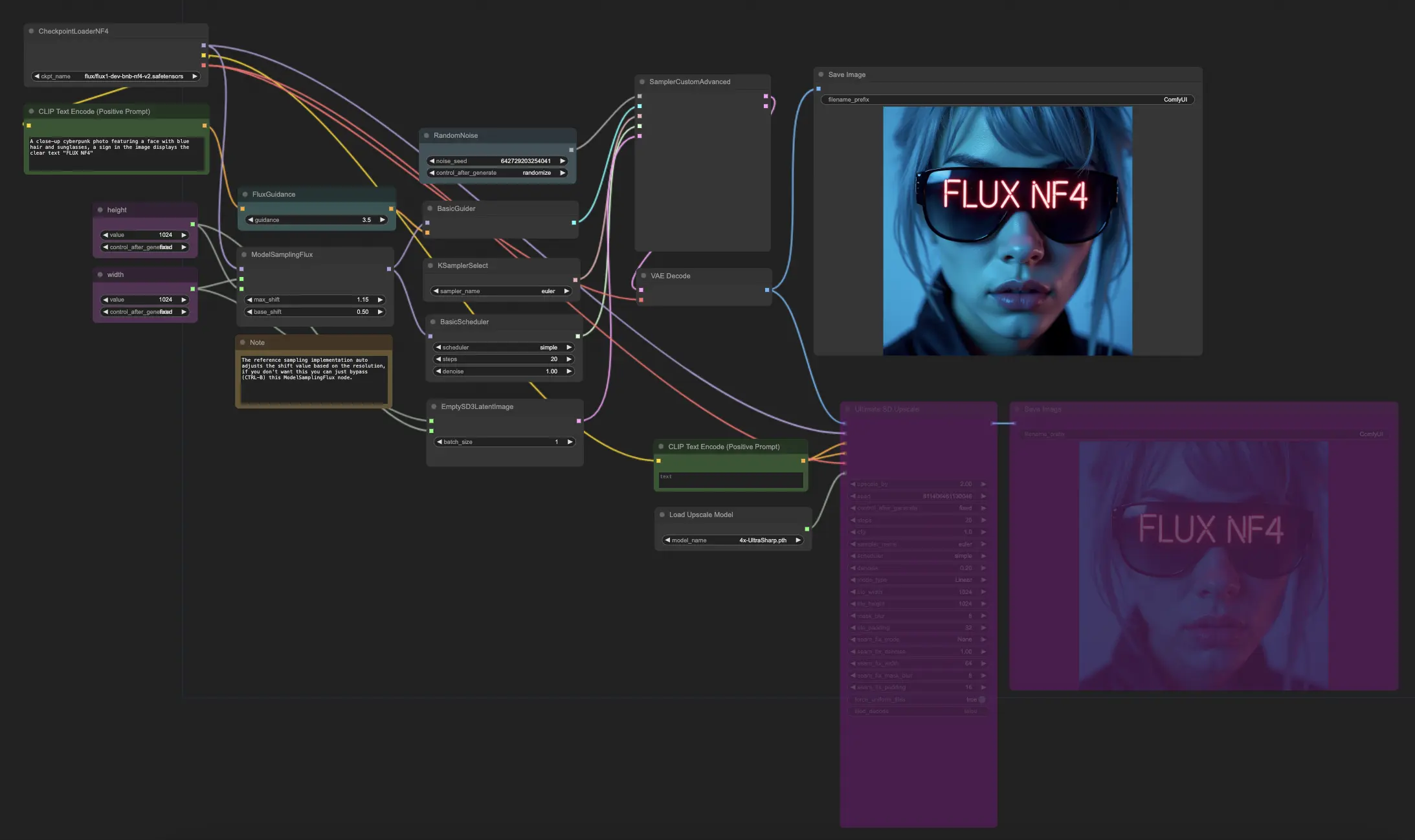
5.6.1. ComfyUI FLUX NF4: <a href="https://cdn.runcomfy.net/tutorial_download/162/06.json" target="_blank">ダウンロード</a>
5.6.2. ComfyUI FLUX NF4 オンラインバージョン: ComfyUI FLUX NF4
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX NF4の体験を簡単に楽しむことができます。
5.6.3. ComfyUI FLUX NF4の説明:
ComfyUI FLUX NF4ワークフローは、FLUX UNET、FLUX CLIP、FLUX VAEを含む必要なコンポーネントをCheckpointLoaderNF4を使用して読み込みます。
- UNETLoader: 画像生成のためのUNETモデルを読み込みます。
- チェックポイント: TBD
PrimitiveNode (height)およびPrimitiveNode (width)ノードは、生成された出力の希望する高さと幅を指定します。ModelSamplingFluxノードは、ロードされたFLUX UNETおよび指定された高さと幅に基づいてComfyUI FLUXのサンプリングパラメータを設定します。
EmptySD3LatentImageノードは、生成の出発点として空の潜在表現を作成します。BasicSchedulerノードは、ComfyUI FLUX生成プロセスのノイズレベル(シグマ)をスケジュールします。
RandomNoiseノードは、ComfyUI FLUX生成プロセスのためのランダムノイズを生成します。BasicGuiderノードは、コンディショニングされたComfyUI FLUXに基づいて生成プロセスをガイドします。
KSamplerSelectノードは、ComfyUI FLUX生成のためのサンプリング方法を選択します。SamplerCustomAdvancedノードは、高度なサンプリングプロセスを実行し、生成されたランダムノイズ、ガイダー、選択されたサンプラー、スケジュールされたシグマ、および空の潜在表現を入力として受け取り、生成された潜在表現を出力します。
VAEDecodeノードは、生成された潜在表現をロードされたFLUX VAEを使用して最終出力にデコードします。SaveImageノードは、生成された出力を指定された場所に保存します。
アップスケーリングには、UltimateSDUpscaleノードが使用されます。生成された出力、ロードされたFLUX、アップスケーリングのためのポジティブおよびネガティブコンディショニング、ロードされたFLUX VAE、およびロードされたFLUXアップスケーリングを入力として受け取ります。CLIPTextEncode (Upscale Positive Prompt)ノードは、アップスケーリングのためのポジティブテキストプロンプトをエンコードします。UpscaleModelLoaderノードは、FLUXアップスケーリングをロードします。UltimateSDUpscaleノードはアップスケーリングプロセスを実行し、アップスケールされた表現を出力します。最後に、SaveImage (Upscaled)ノードは、アップスケールされた出力を指定された場所に保存します。
ComfyUI FLUXとNF4アーキテクチャの力を活用することにより、ComfyUI FLUX NF4ワークフローは、強化された忠実度とリアリズムを持つ高品質の出力を生成します。ComfyUI FLUXとNF4アーキテクチャのシームレスな統合により、驚くべき魅力的な出力を作成するための強力なツールが提供されます。
5.7. ComfyUIワークフロー: FLUX IPAdapter
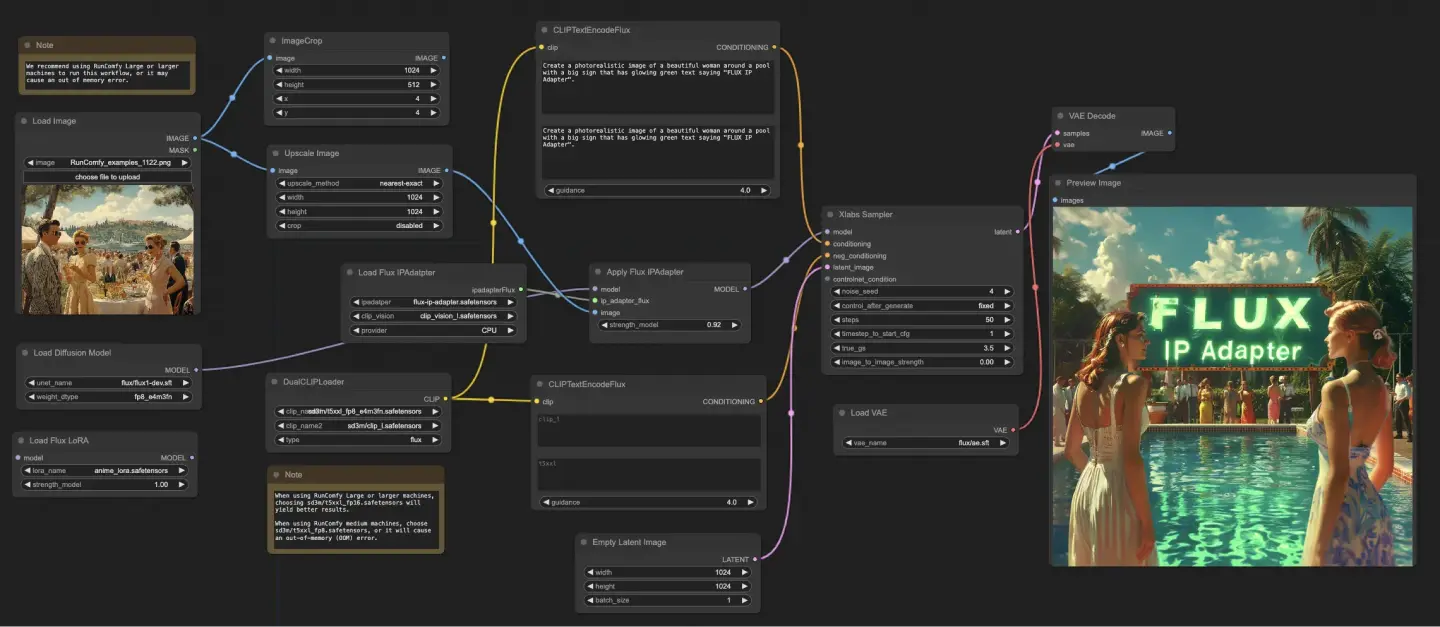
5.7.1. ComfyUI FLUX IPAdapter: <a href="https://cdn.runcomfy.net/tutorial_download/162/07.json" target="_blank">ダウンロード</a>
5.7.2. ComfyUI FLUX IPAdapter オンラインバージョン: [ComfyUI FLUX
IPAdapter](https://www.runcomfy.com/ja/comfyui-workflows/comfyui-flux-ipadapter)
RunComfyプラットフォームでは、オンラインバージョンが必要なモードとノードをすべて事前にロードします。さらに、高性能GPUマシンを提供しており、ComfyUI FLUX IPAdapterの体験を簡単に楽しむことができます。
5.7.3. ComfyUI FLUX IPAdapterの説明:
ComfyUI FLUX IPAdapterワークフローは、UNETモデル(UNETLoader)、CLIPモデル(DualCLIPLoader)、およびVAEモデル(VAELoader)などの必要なモデルを読み込むことから始まります。
ポジティブおよびネガティブテキストプロンプトは、CLIPTextEncodeFluxを使用してエンコードされます。ポジティブテキストコンディショニングは、ComfyUI FLUX生成プロセスをガイドするために使用されます。
入力画像は、LoadImageを使用して読み込まれます。LoadFluxIPAdapterは、FLUXモデルのためのIP-Adapterを読み込み、ApplyFluxIPAdapterを使用してロードされたUNETモデルに適用されます。ImageScaleは、IP-Adapterを適用する前に入力画像を希望のサイズにスケーリングします。
- LoadFluxIPAdapter: FLUXモデルのためのIP-Adapterを読み込みます。
- IP Adapter Model: flux-ip-adapter.safetensors
- CLIP Vision Encoder: clip_vision_l.safetensors
EmptyLatentImageは、ComfyUI FLUX生成の出発点として空の潜在表現を作成します。
XlabsSamplerは、FLUX UNETに適用されたIP-Adapter、エンコードされたポジティブおよびネガティブテキストコンディショニング、および空の潜在表現を入力として受け取り、サンプリングプロセスを実行します。これにより、潜在表現が生成されます。
VAEDecodeは、生成された潜在表現をロードされたFLUX VAEを使用して最終出力にデコードします。PreviewImageノードは、最終出力のプレビューを表示します。
ComfyUI FLUX IPAdapterワークフローは、ComfyUI FLUXの力とIP-Adapterを活用して、提供されたテキストプロンプトに一致する高品質の出力を生成します。IP-AdapterをFLUX UNETに適用することで、テキストコンディショニングで指定された特性とスタイルを捉えた出力の生成が可能になります。
5.8. ComfyUIワークフロー: Flux LoRA Trainer

5.8.1. ComfyUI FLUX LoRA Trainer: <a href="https://cdn.runcomfy.net/tutorial_download/162/08.json" target="_blank">ダウンロード</a>
5.8.2. ComfyUI Flux LoRA Trainerの説明:
ComfyUI FLUX LoRA Trainerワークフローは、ComfyUIでFLUXアーキテクチャを使用してLoRAをトレーニングするための複数のステージで構成されています。
ComfyUI FLUXの選択と構成: FluxTrainModelSelectノードは、UNET、VAE、CLIP、およびCLIPテキストエンコーダーを含むトレーニング用のコンポーネントを選択します。 OptimizerConfigノードは、ComfyUI FLUXトレーニングのためのオプティマイザ設定(オプティマイザタイプ、学習率、ウェイトデケイなど)を構成します。 TrainDatasetGeneralConfigおよびTrainDatasetAddノードは、解像度、オーグメンテーション設定、バッチサイズなどのトレーニングデータセットを構成します。
ComfyUI FLUXトレーニングの初期化: InitFluxLoRATrainingノードは、選択されたコンポーネント、データセット構成、およびオプティマイザ設定を使用してLoRAトレーニングプロセスを初期化します。 FluxTrainValidationSettingsノードは、検証サンプル数、解像度、バッチサイズなどのトレーニングの検証設定を構成します。
ComfyUI FLUXトレーニングループ: FluxTrainLoopノードは、指定されたステップ数でLoRAのトレーニングループを実行します。 各トレーニングループの後、FluxTrainValidateノードは検証設定を使用してトレーニングされたLoRAを検証し、検証出力を生成します。 PreviewImageノードは、検証結果のプレビューを表示します。 FluxTrainSaveノードは、指定された間隔でトレーニングされたLoRAを保存します。
ComfyUI FLUX損失の視覚化: VisualizeLossノードは、トレーニング全体の損失を視覚化します。 SaveImageノードは、さらなる分析のために損失プロットを保存します。
ComfyUI FLUX検証出力の処理: AddLabelおよびSomethingToStringノードは、トレーニングステップを示すラベルを検証出力に追加します。 ImageBatchMultiおよびImageConcatFromBatchノードは、検証出力を組み合わせて1つの結果にまとめ、視覚化を容易にします。
ComfyUI FLUXトレーニングの完了: FluxTrainEndノードは、LoRAトレーニングプロセスを完了し、トレーニングされたLoRAを保存します。 UploadToHuggingFaceノードは、トレーニングされたLoRAをHugging Faceにアップロードして、ComfyUI FLUXでの共有およびさらなる使用が可能です。
5.9. ComfyUIワークフロー: Flux Latent Upscaler
5.9.1. ComfyUI Flux Latent Upscaler: <a href="https://cdn.runcomfy.net/tutorial_download/162/09.json" target="_blank">ダウンロード</a>
5.9.2. ComfyUI Flux Latent Upscalerの説明:
ComfyUI Flux Latent Upscaleワークフローは、CLIP(DualCLIPLoader)、UNET(UNETLoader)、およびVAE(VAELoader)などの必要なコンポーネントを読み込むことから始まります。テキストプロンプトは、CLIPTextEncodeノードを使用してエンコードされ、FluxGuidanceノードを使用してガイダンスが適用されます。
SDXLEmptyLatentSizePicker+ノードは、FLUXのアップスケーリングプロセスの出発点として空の潜在表現のサイズを指定します。潜在表現は、LatentUpscaleおよびLatentCropノードを使用して一連のアップスケーリングおよびクロッピングステップを経て処理されます。
アップスケーリングプロセスは、エンコードされたテキストコンディショニングによってガイドされ、選択されたサンプリング方法(KSamplerSelect)およびスケジュールされたノイズレベル(BasicScheduler)を使用してSamplerCustomAdvancedノードを使用します。ModelSamplingFluxノードは、サンプリングパラメータを設定します。
アップスケールされた潜在表現は、SolidMaskおよびFeatherMaskノードによって生成されたマスクを使用して、LatentCompositeMaskedノードを使用して元の潜在表現と合成されます。ノイズは、InjectLatentNoise+ノードを使用してアップスケールされた潜在表現に注入されます。
最後に、VAEDecodeは、生成された潜在表現をロードされたFLUX VAEを使用して最終出力にデコードし、ImageSmartSharpen+ノードを使用してスマートシャープニングが適用されます。PreviewImageノードは、ComfyUI FLUXによって生成された最終出力のプレビューを表示します。
ComfyUI FLUX Latent Upscalerワークフローには、アップスケーリングプロセスの寸法、比率、およびその他のパラメータを計算するためのSimpleMath+、SimpleMathFloat+、SimpleMathInt+、およびSimpleMathPercent+ノードを使用したさまざまな数学的操作も含まれています。