AnimateDiff + IPAdapter V1 | Imagem para Vídeo
O IPAdapter é uma solução leve que aprimora modelos pré-treinados com recursos de prompt de imagem. Ao usar o AnimateDiff junto com o IPAdapter, você pode gerar facilmente animações mais controláveis a partir de imagens de referência.ComfyUI AnimateDiff IPAdapter Fluxo de Trabalho
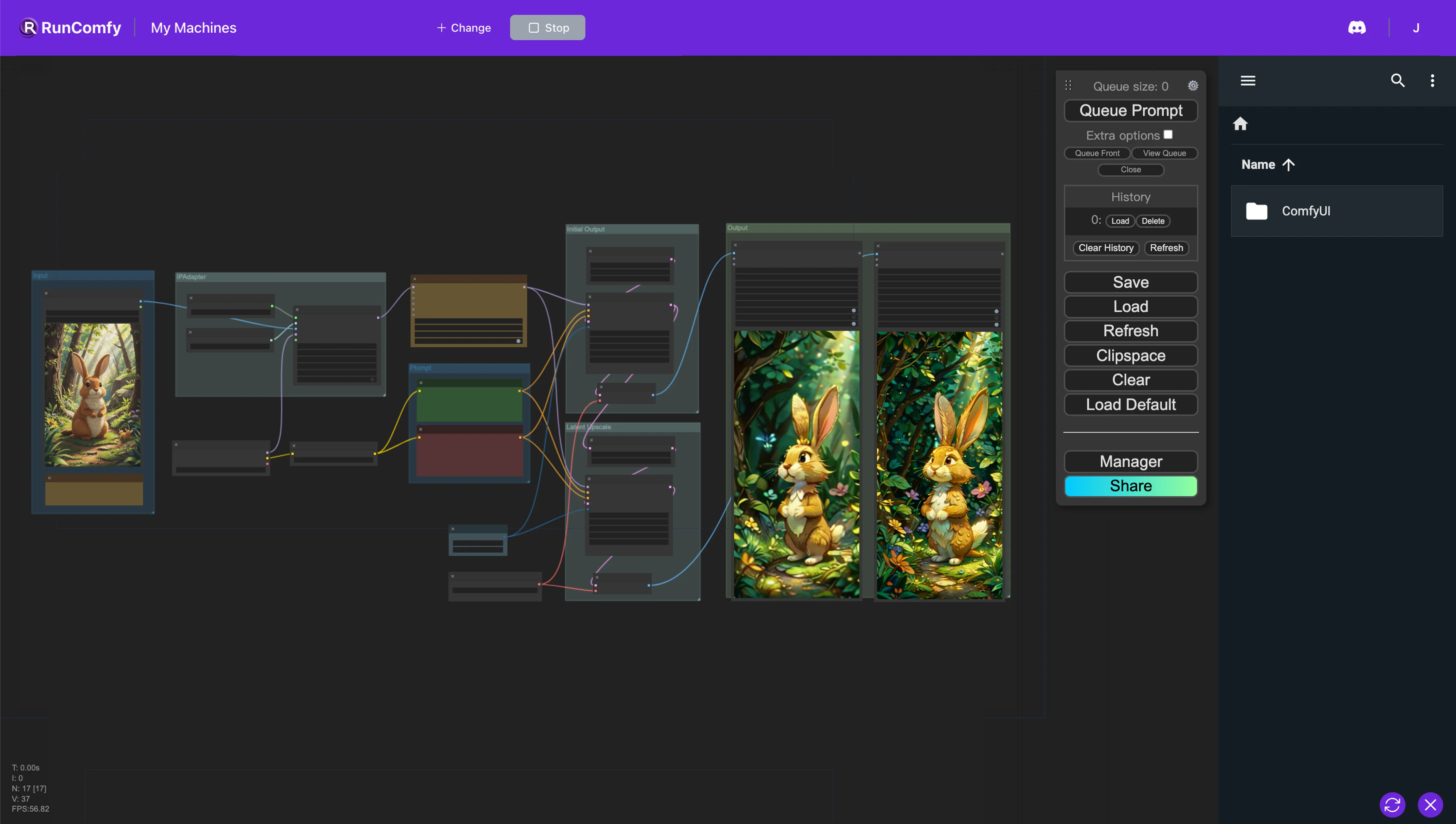
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI AnimateDiff IPAdapter Exemplos
ComfyUI AnimateDiff IPAdapter Descrição
1. Fluxo de Trabalho ComfyUI: AnimateDiff + IPAdapter | Imagem para Vídeo
Este fluxo de trabalho ComfyUI é projetado para criar animações a partir de imagens de referência usando AnimateDiff e IP-Adapter. O nó AnimateDiff integra opções de modelo e contexto para ajustar a dinâmica da animação. Por outro lado, o nó IP-Adapter facilita o uso de imagens como prompts de maneiras que podem imitar o estilo, composição ou características faciais da imagem de referência, aprimorando significativamente a personalização e qualidade das animações ou imagens geradas.
2. Visão Geral do AnimateDiff
Confira os detalhes sobre
3. Visão Geral do IP-Adapter
3.1. Introdução ao IP-Adapter
IP-Adapter significa "Image Prompt Adapter" (Adaptador de Prompt de Imagem), uma nova abordagem para aprimorar modelos de diffusion de texto para imagem com a capacidade de usar prompts de imagem em tarefas de geração de imagem. O IP-Adapter visa abordar as deficiências dos prompts de texto que geralmente exigem uma engenharia de prompt complexa para gerar as imagens desejadas. A introdução de prompts de imagem, junto com o texto, permite uma maneira mais intuitiva e eficaz de orientar o processo de síntese de imagem.
Diferentes Modelos do IP-Adapter
A suíte IP-Adapter inclui uma variedade de modelos, cada um adaptado para casos de uso específicos e níveis de complexidade de síntese de imagem. Aqui está uma visão geral dos diferentes modelos disponíveis:
3.1.1. Modelos v1.5
ip-adapter_sd15: O modelo padrão para a versão 1.5, que utiliza o poder do IP-Adapter para condicionamento de imagem para imagem e aumento de prompt de texto.ip-adapter_sd15_light: Uma versão mais leve do modelo padrão, otimizada para aplicações menos intensivas em recursos, ainda aproveitando a tecnologia IP-Adapter.ip-adapter-plus_sd15: Um modelo aprimorado que produz imagens mais alinhadas com a referência original, melhorando os detalhes mais finos.ip-adapter-plus-face_sd15: Semelhante ao IP-Adapter Plus, com foco na replicação mais precisa das características faciais nas imagens geradas.ip-adapter-full-face_sd15: Um modelo que enfatiza detalhes de rosto inteiro, provavelmente oferecendo um efeito de "troca de rosto" com alta fidelidade.ip-adapter_sd15_vit-G: Uma variante do modelo padrão usando o codificador de imagem Vision Transformer (ViT) BigG para extração de características de imagem mais detalhada.
3.1.2. Modelos SDXL
ip-adapter_sdxl: O modelo base para o SDXL, que é projetado para lidar com prompts de imagem maiores e mais complexos.ip-adapter_sdxl_vit-h: O modelo SDXL combinado com o codificador de imagem ViT H, equilibrando desempenho com eficiência computacional.ip-adapter-plus_sdxl_vit-h: Uma versão avançada do modelo SDXL com detalhes e qualidade aprimorados do prompt de imagem.ip-adapter-plus-face_sdxl_vit-h: Uma variante SDXL focada em detalhes do rosto, ideal para projetos onde a precisão facial é primordial.
3.1.3. Modelos FaceID
FaceID: Um modelo que usa InsightFace para extrair embeddings de Face ID, oferecendo uma abordagem única para geração de imagem relacionada ao rosto.FaceID Plus: Uma versão aprimorada do modelo FaceID, combinando InsightFace para características faciais e codificação de imagem CLIP para características faciais globais.FaceID Plus v2: Uma iteração no FaceID Plus com um ponto de verificação de modelo aprimorado e a capacidade de definir um peso no embedding de imagem CLIP.FaceID Portrait: Um modelo semelhante ao FaceID, mas projetado para aceitar várias imagens de rostos recortados para um condicionamento facial mais diversificado.
3.1.4. Modelos FaceID SDXL
FaceID SDXL: A versão SDXL do FaceID, mantendo o mesmo modelo InsightFace que a v1.5, mas dimensionado para aplicações SDXL.FaceID Plus v2 SDXL: Uma adaptação SDXL do FaceID Plus v2 para geração de imagem de alta definição com fidelidade aprimorada.
3.2. Principais Recursos do IP-Adapter
3.2.1. Integração de Prompt de Texto e Imagem: A capacidade exclusiva do IP-Adapter de usar prompts de texto e imagem permite a geração de imagem multimodal, fornecendo uma ferramenta versátil e poderosa para controlar as saídas do modelo de diffusion.
3.2.2. Mecanismo de Atenção Cruzada Desacoplado: O IP-Adapter emprega uma estratégia de atenção cruzada desacoplada que aprimora a eficiência do modelo no processamento de diversas modalidades, separando características de texto e imagem.
3.2.3. Modelo Leve: Apesar de sua funcionalidade abrangente, o IP-Adapter mantém uma contagem de parâmetros relativamente baixa (22M), oferecendo desempenho que rivaliza ou excede o de modelos de prompt de imagem ajustados.
3.2.4. Compatibilidade e Generalização: O IP-Adapter é projetado para ampla compatibilidade com ferramentas controláveis existentes e pode ser aplicado a modelos personalizados derivados do mesmo modelo base para maior generalização.
3.2.5. Controle de Estrutura: O IP-Adapter suporta controle detalhado de estrutura, permitindo que os criadores orientem o processo de geração de imagem com maior precisão.
3.2.6. Recursos de Imagem para Imagem e Inpainting: Com suporte para tradução de imagem para imagem e inpainting guiados por imagem, o IP-Adapter amplia o escopo de possíveis aplicações, permitindo usos criativos e práticos em uma variedade de tarefas de síntese de imagem.
3.2.7. Personalização com Diferentes Codificadores: O IP-Adapter permite o uso de vários codificadores, como OpenClip ViT H 14 e ViT BigG 14, para processar imagens de referência. Essa flexibilidade facilita o tratamento de diferentes resoluções e complexidades de imagem, tornando-o uma ferramenta versátil para criadores que buscam personalizar o processo de geração de imagem para necessidades específicas ou resultados desejados.
A incorporação da tecnologia IP-Adapter em projetos de geração de imagem não apenas simplifica a criação de imagens complexas e detalhadas, mas também aprimora significativamente a qualidade e fidelidade das imagens geradas aos prompts originais. Ao preencher a lacuna entre prompts de texto e imagem, o IP-Adapter fornece uma abordagem poderosa, intuitiva e eficiente para controlar as nuances da síntese de imagem, tornando-o uma ferramenta indispensável no arsenal de artistas digitais, designers e criadores que trabalham com o fluxo de trabalho ComfyUI ou qualquer outro contexto que exija geração de imagem personalizada de alta qualidade.
