LayerDiffuse | Texto para Imagem Transparente
O modelo LayerDiffuse introduz uma nova abordagem para a manipulação de imagens, permitindo a criação direta de imagens transparentes. Dentro deste fluxo de trabalho ComfyUI LayerDiffuse, três sub-fluxos de trabalho especializados são integrados: criar imagens transparentes, gerar o fundo a partir do primeiro plano e o processo inverso de criar o primeiro plano com base no fundo existente.ComfyUI LayerDiffuse Fluxo de Trabalho

- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI LayerDiffuse Exemplos

ComfyUI LayerDiffuse Descrição
1. Visão Geral do Fluxo de Trabalho ComfyUI LayerDiffuse
O fluxo de trabalho ComfyUI LayerDiffuse integra três sub-fluxos de trabalho especializados: criar imagens transparentes, gerar o fundo a partir do primeiro plano e o processo inverso de gerar o primeiro plano com base no fundo existente. Cada um desses sub-fluxos de trabalho LayerDiffuse opera independentemente, fornecendo a flexibilidade de escolher e ativar a funcionalidade específica do LayerDiffuse que atende às suas necessidades criativas.
1.1. Criando Imagens Transparentes com LayerDiffuse:
Este fluxo de trabalho permite a criação direta de imagens transparentes, fornecendo a flexibilidade de gerar imagens com ou sem especificar a máscara do canal alfa.
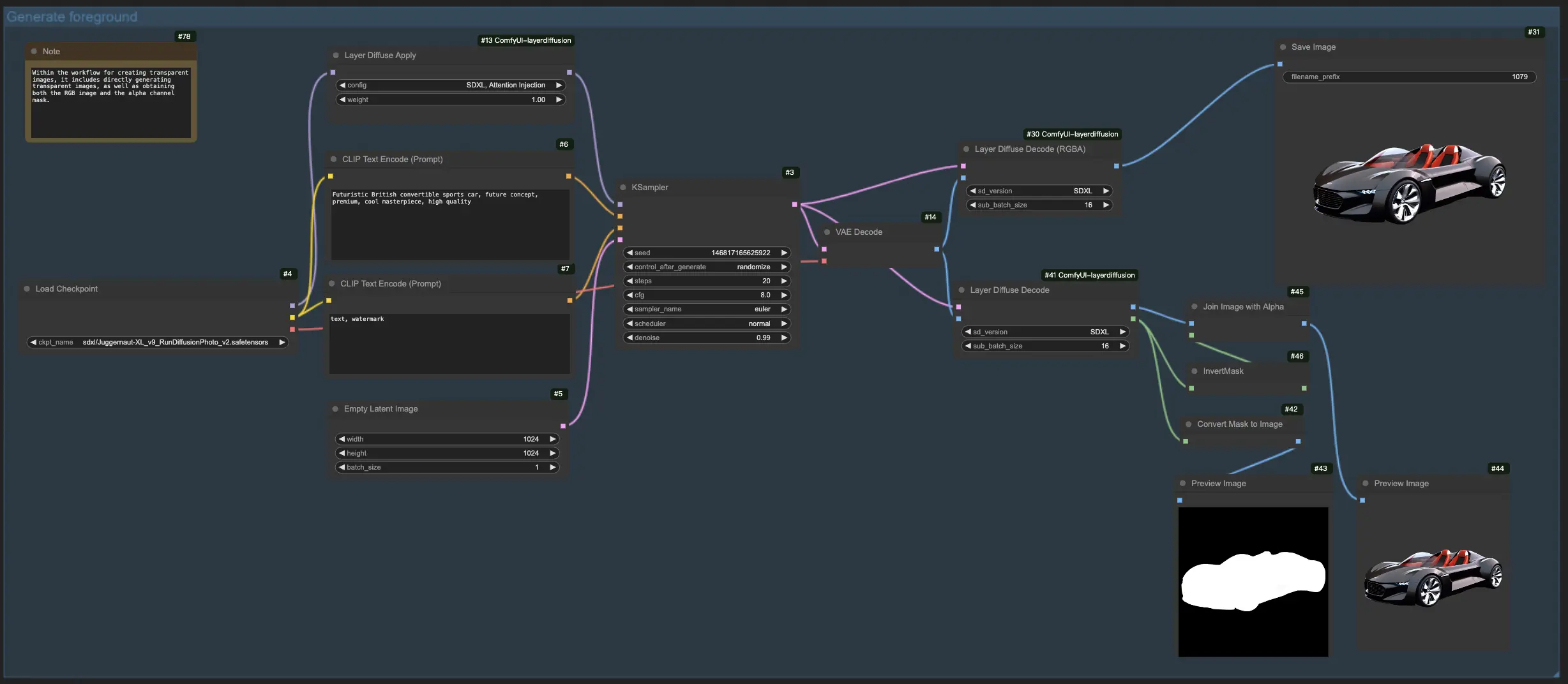
1.2. Gerando o Fundo a partir do Primeiro Plano com LayerDiffuse:
Para este fluxo de trabalho LayerDiffuse, comece carregando sua imagem de primeiro plano e criando um prompt descritivo. O LayerDiffuse então mescla esses elementos para produzir a imagem desejada. Ao elaborar seu prompt para o LayerDiffuse, é crucial detalhar a cena completa (por exemplo, "um carro estacionado na lateral da rua") em vez de apenas descrever o elemento de fundo (por exemplo, "a rua").
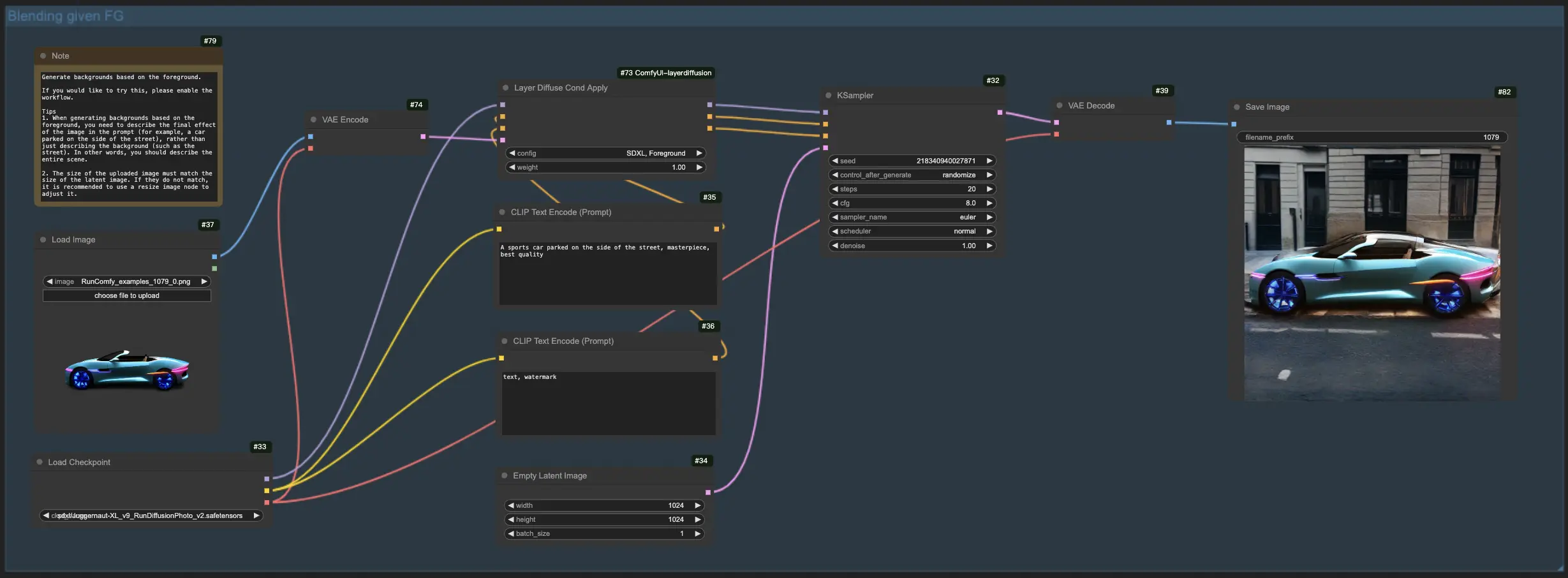
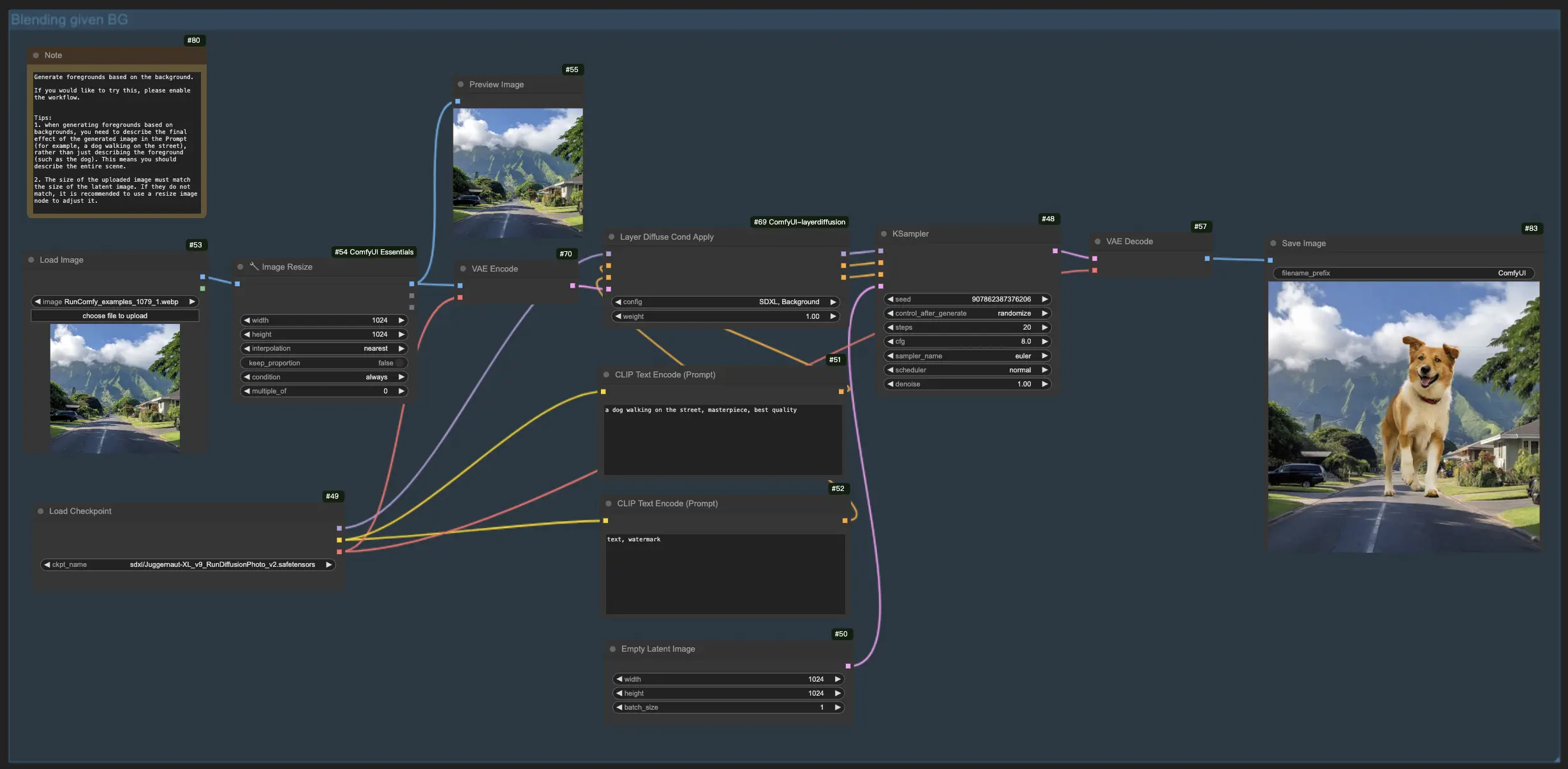
1.3. Gerando o Primeiro Plano com Base no Fundo:
Espelhando o fluxo de trabalho anterior, essa funcionalidade LayerDiffuse inverte o foco, visando mesclar elementos do primeiro plano com um fundo existente. Portanto, você precisa carregar a imagem de fundo e descrever a imagem final imaginada em seu prompt, enfatizando a cena completa (por exemplo, "um cachorro caminhando na rua") sobre elementos individuais (por exemplo, "o cachorro").
Para mais fluxos de trabalho LayerDiffuse, confira no
2. Eficácia do Fluxo de Trabalho LayerDiffuse
Embora o processo de criar imagens transparentes seja robusto e produza resultados de alta qualidade de forma confiável, os fluxos de trabalho para mesclar fundos e primeiro planos são mais experimentais. Eles podem nem sempre alcançar uma mistura perfeita, indicativo da natureza inovadora, mas em desenvolvimento, dessa tecnologia.
3. Introdução Técnica ao LayerDiffuse
O LayerDiffuse é uma abordagem inovadora projetada para permitir que modelos de difusão latente pré-treinados em larga escala gerem imagens com transparência. Essa técnica introduz o conceito de "transparência latente", que envolve a codificação da transparência do canal alfa diretamente no manifold latente de modelos existentes. Isso permite a criação de imagens transparentes ou múltiplas camadas transparentes sem alterar significativamente a distribuição latente original do modelo pré-treinado. O objetivo é manter a saída de alta qualidade desses modelos enquanto adiciona a capacidade de gerar imagens com transparência.
Para alcançar isso, o LayerDiffuse ajusta modelos de difusão latente pré-treinados, ajustando seu espaço latente para incluir a transparência como um offset latente. Esse processo envolve mudanças mínimas no modelo, preservando suas qualidades e desempenho originais. O treinamento do LayerDiffuse utiliza um conjunto de dados de 1 milhão de pares de camadas de imagem transparentes, coletados por meio de um esquema human-in-the-loop para garantir uma ampla variedade de efeitos de transparência.
O método mostrou-se adaptável a vários geradores de imagem de código aberto e pode ser integrado em diferentes sistemas de controle condicional. Essa versatilidade permite uma variedade de aplicações, como gerar imagens com transparência específica de primeiro plano/fundo, criar camadas com recursos de geração conjunta e controlar o conteúdo estrutural das camadas.






