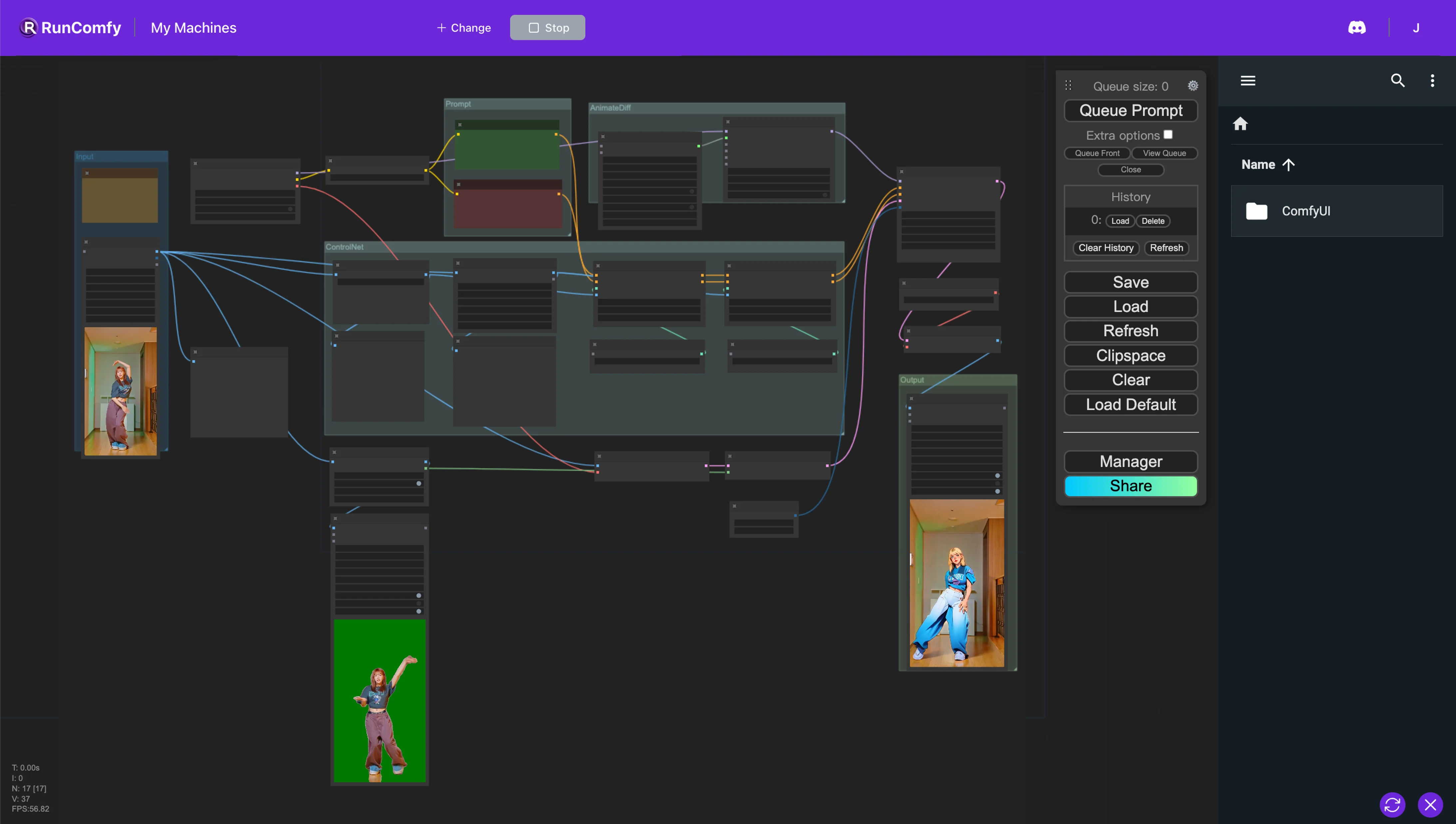
AnimateDiff + ControlNet + AutoMask | Estilo de Quadrinhos
Neste fluxo de trabalho ComfyUI, utilizamos nós personalizados como Animatediff, ControlNet (com Depth e OpenPose) e Auto Mask para reestilizar vídeos perfeitamente. Esse processo transforma personagens realistas em anime enquanto preserva meticulosamente os planos de fundo originais.ComfyUI Vid2Vid Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Vid2Vid Exemplos
ComfyUI Vid2Vid Descrição
1. Fluxo de trabalho ComfyUI AnimateDiff, ControlNet e Auto Mask
Este fluxo de trabalho ComfyUI introduz uma abordagem poderosa para a reestilização de vídeos, especificamente destinada a transformar personagens em um estilo de anime, preservando os planos de fundo originais. Essa transformação é apoiada por vários componentes-chave, incluindo AnimateDiff, ControlNet e Auto Mask.
AnimateDiff é projetado para técnicas de animação diferencial, permitindo a manutenção de um contexto consistente nas animações. Esse componente se concentra em suavizar transições e aprimorar a fluidez do movimento em conteúdo de vídeo reestilizado.
ControlNet desempenha um papel crítico na replicação e manipulação precisa da pose humana. Ele aproveita a estimativa avançada de pose para capturar e controlar com precisão as nuances do movimento humano, facilitando a transformação de personagens em formas de anime, preservando suas poses originais.
Auto Mask está envolvido na segmentação automática, hábil em isolar personagens de seus planos de fundo. Essa tecnologia permite a reestilização seletiva de elementos de vídeo, garantindo que as transformações de personagens sejam executadas sem alterar o ambiente circundante, mantendo a integridade dos planos de fundo originais.
Este fluxo de trabalho ComfyUI realiza a conversão de conteúdo de vídeo padrão em animações estilizadas, com foco na eficiência e na qualidade da geração de personagens no estilo anime.
2. Visão geral do AnimateDiff
2.1. Introdução ao AnimateDiff
AnimateDiff surge como uma ferramenta de IA projetada para animar imagens estáticas e prompts de texto em vídeos dinâmicos, aproveitando modelos Stable Diffusion e um módulo de movimento especializado. Essa tecnologia automatiza o processo de animação prevendo transições perfeitas entre quadros, tornando-a acessível a usuários sem habilidades de codificação ou recursos computacionais por meio de uma plataforma online gratuita.
2.2. Principais recursos do AnimateDiff
2.2.1. Suporte abrangente a modelos: O AnimateDiff é compatível com várias versões, incluindo AnimateDiff v1, v2, v3 para Stable Diffusion V1.5 e AnimateDiff sdxl para Stable Diffusion SDXL. Ele permite o uso simultâneo de vários modelos de movimento, facilitando a criação de animações complexas e em camadas.
2.2.2. O tamanho do lote de contexto determina a duração da animação: O AnimateDiff permite a criação de animações de duração infinita por meio do ajuste do tamanho do lote de contexto. Esse recurso permite que os usuários personalizem a duração e a transição das animações de acordo com seus requisitos específicos, proporcionando um processo de animação altamente adaptável.
2.2.3. Comprimento do contexto para transições suaves: O objetivo do Comprimento de Contexto Uniforme no AnimateDiff é garantir transições perfeitas entre diferentes segmentos de uma animação. Ao ajustar o Comprimento de Contexto Uniforme, os usuários podem controlar a dinâmica de transição entre cenas—comprimentos mais longos para transições mais suaves e perfeitas, e comprimentos mais curtos para mudanças mais rápidas e pronunciadas.
2.2.4. Dinâmica de movimento: No AnimateDiff v2, LoRAs de movimento especializados estão disponíveis para adicionar movimentos de câmera cinematográficos às animações. Esse recurso introduz uma camada dinâmica às animações, aprimorando significativamente seu apelo visual.
2.2.5. Recursos avançados de suporte: O AnimateDiff é projetado para funcionar com uma variedade de ferramentas, incluindo ControlNet, SparseCtrl e IPAdapter, oferecendo vantagens significativas para os usuários que desejam expandir as possibilidades criativas de seus projetos.
3. Visão geral do ControlNet
3.1. Introdução ao ControlNet
O ControlNet introduz uma estrutura para aumentar os modelos de difusão de imagem com entradas condicionais, com o objetivo de refinar e orientar o processo de síntese de imagem. Ele consegue isso duplicando os blocos de rede neural dentro de um determinado modelo de difusão em dois conjuntos: um permanece "bloqueado" para preservar a funcionalidade original e o outro se torna "treinável", adaptando-se às condições específicas fornecidas. Essa estrutura dupla permite que os desenvolvedores incorporem uma variedade de entradas condicionais usando modelos como OpenPose, Tile, IP-Adapter, Canny, Depth, LineArt, MLSD, Normal Map, Scribbles, Segmentation, Shuffle e T2I Adapter, influenciando diretamente a saída gerada. Por meio desse mecanismo, o ControlNet oferece aos desenvolvedores uma ferramenta poderosa para controlar e manipular o processo de geração de imagem, aprimorando a flexibilidade do modelo de difusão e sua aplicabilidade a diversas tarefas criativas.
Pré-processadores e integração de modelos
3.1.1. Configuração de pré-processamento: Iniciar com ControlNet envolve a seleção de um pré-processador adequado. A ativação da opção de visualização é aconselhável para uma compreensão visual do impacto do pré-processamento. Após o pré-processamento, o fluxo de trabalho faz a transição para a utilização da imagem pré-processada para etapas de processamento posteriores.
3.1.2. Correspondência de modelos: Simplificando o processo de seleção de modelos, o ControlNet garante a compatibilidade alinhando os modelos com seus pré-processadores correspondentes com base em palavras-chave compartilhadas, facilitando um processo de integração perfeito.
3.2. Principais recursos do ControlNet
Exploração aprofundada dos modelos ControlNet
3.2.1. Suíte OpenPose: Projetada para detecção precisa de poses humanas, a suíte OpenPose abrange modelos para detectar poses corporais, expressões faciais e movimentos das mãos com excepcional precisão. Vários pré-processadores OpenPose são adaptados a requisitos de detecção específicos, desde análise básica de pose até captura detalhada de nuances faciais e das mãos.
3.2.2. Modelo Tile Resample: Aprimorando a resolução e os detalhes da imagem, o modelo Tile Resample é usado de maneira ideal ao lado de uma ferramenta de aumento de resolução, com o objetivo de enriquecer a qualidade da imagem sem comprometer a integridade visual.
3.2.3. Modelo IP-Adapter: Facilitando o uso inovador de imagens como prompts, o IP-Adapter integra elementos visuais de imagens de referência nas saídas geradas, mesclando recursos de difusão de texto para imagem para conteúdo visual enriquecido.
3.2.4. Detector de bordas Canny: Reverenciado por seus recursos de detecção de bordas, o modelo Canny enfatiza a essência estrutural das imagens, possibilitando reinterpretações visuais criativas enquanto mantém as composições principais.
3.2.5. Modelos de percepção de profundidade: Por meio de uma variedade de pré-processadores de profundidade, o ControlNet é especializado em derivar e aplicar informações de profundidade a partir de imagens, oferecendo uma perspectiva de profundidade em camadas nos visuais gerados.
3.2.6. Modelos LineArt: Converta imagens em desenhos de linha artísticos com os pré-processadores LineArt, atendendo a diversas preferências artísticas, desde anime até esboços realistas. O ControlNet acomoda um espectro de desejos estilísticos.
3.2.7. Processamento de rabiscos: Com pré-processadores como Scribble HED, Pidinet e xDoG, o ControlNet transforma imagens em arte única de rabiscos, oferecendo estilos variados para detecção de bordas e reinterpretação artística.
3.2.8. Técnicas de segmentação: Os recursos de segmentação do ControlNet classificam com precisão os elementos da imagem, permitindo a manipulação precisa com base na categorização de objetos, ideal para construções de cenas complexas.
3.2.9. Modelo Shuffle: Introduzindo um método para inovação de esquemas de cores, o modelo Shuffle randomiza imagens de entrada para gerar novos padrões de cores, alterando criativamente o original enquanto retém sua essência.
3.2.10. Inovações do T2I Adapter: Os modelos T2I Adapter, incluindo Color Grid e CLIP Vision Style, impulsionam o ControlNet para novos domínios criativos, misturando e adaptando cores e estilos para produzir saídas visualmente atraentes que respeitam o esquema de cores ou os atributos estilísticos do original.
3.2.11. MLSD (Detecção de Segmento de Linha Móvel): Especializado na detecção de linhas retas, o MLSD é inestimável para projetos focados em designs arquitetônicos e de interiores, priorizando clareza e precisão estrutural.
3.2.12. Processamento de Normal Map: Utilizando dados de orientação de superfície, os pré-processadores Normal Map replicam a estrutura 3D de imagens de referência, aprimorando o realismo do conteúdo gerado por meio de análise detalhada da superfície.
