


Desbloqueie o Poder do ComfyUI: Um Guia para Iniciantes com Prática Prática
Updated: 5/17/2024
Olá, companheiros artistas de IA! 👋 Bem-vindo ao nosso tutorial amigável para iniciantes sobre o ComfyUI, uma ferramenta incrivelmente poderosa e flexível para criar impressionantes obras de arte geradas por IA. 🎨 Neste guia, vamos orientá-lo através dos fundamentos do ComfyUI, explorar seus recursos e ajudá-lo a liberar seu potencial para levar sua arte de IA para o próximo nível. 🚀
Nós vamos cobrir:
1. O que é ComfyUI?
- 1.1. ComfyUI vs. AUTOMATIC1111
- 1.2. Por onde começar com ComfyUI?
- 1.3. Controles básicos
2. Fluxos de trabalho do ComfyUI: Texto para Imagem
- 2.1. Selecionando um Modelo
- 2.2. Inserindo o Prompt Positivo e o Prompt Negativo
- 2.3. Gerando uma Imagem
- 2.4. Explicação Técnica do ComfyUI
- 2.4.1 Nó Load Checkpoint
- 2.4.2. CLIP Text Encode
- 2.4.3. Empty Latent Image
- 2.4.4. VAE
- 2.4.5. KSampler
3. Fluxo de trabalho do ComfyUI: Imagem para Imagem
4. ComfyUI SDXL
5. ComfyUI Inpainting
6. ComfyUI Outpainting
7. ComfyUI Upscale
- 7.1. Upscale Pixel
- 7.1.1. Upscale Pixel por Algoritmo
- 7.1.2. Upscale Pixel por Modelo
- 7.2. Upscale Latent
- 7.3. Upscale Pixel vs. Upscale Latent
8. ComfyUI ControlNet
9. ComfyUI Manager
- 9.1. Como Instalar Nós Personalizados Ausentes
- 9.2. Como Atualizar Nós Personalizados
- 9.3. Como Carregar Nós Personalizados em seu Fluxo de Trabalho
10. ComfyUI Embeddings
- 10.1. Embedding com Autocompletar
- 10.2. Embedding Weight
11. ComfyUI LoRA
- 11.1. Fluxos de Trabalho LoRA Simples
- 11.2. LoRAs Múltiplos
12. Atalhos e Truques para ComfyUI
- 12.1. Copiar e Colar
- 12.2. Movendo Vários Nós
- 12.3. Ignorar um Nó
- 12.4. Minimizar um Nó
- 12.5. Gerar Imagem
- 12.6. Fluxo de Trabalho Embutido
- 12.7. Corrigir Seeds para Economizar Tempo
13. ComfyUI Online
1. O que é ComfyUI? 🤔
ComfyUI é como ter uma varinha mágica 🪄 para criar impressionantes obras de arte geradas por IA com facilidade. No seu cerne, ComfyUI é uma interface gráfica de usuário (GUI) baseada em nós construída em cima da Stable Diffusion, um modelo de aprendizado profundo de última geração que gera imagens a partir de descrições de texto. 🌟 Mas o que torna o ComfyUI realmente especial é como ele capacita artistas como você a liberar sua criatividade e dar vida às suas ideias mais selvagens.
Imagine uma tela digital onde você pode construir seus próprios fluxos de trabalho exclusivos de geração de imagens conectando diferentes nós, cada um representando uma função ou operação específica. 🧩 É como construir uma receita visual para suas obras-primas geradas por IA!
Quer gerar uma imagem do zero usando um prompt de texto? Existe um nó para isso! Precisa aplicar um sampler específico ou ajustar o nível de ruído? Basta adicionar os nós correspondentes e assistir a mágica acontecer. ✨
Mas aqui está a melhor parte: ComfyUI divide o fluxo de trabalho em elementos reorganizáveis, dando a você a liberdade de criar seus próprios fluxos de trabalho personalizados, adaptados à sua visão artística. 🖼️ É como ter um conjunto de ferramentas personalizado que se adapta ao seu processo criativo.
1.1. ComfyUI vs. AUTOMATIC1111 🆚
AUTOMATIC1111 é a GUI padrão para Stable Diffusion. Então, você deveria usar o ComfyUI em vez disso? Vamos comparar:
✅ Benefícios de usar o ComfyUI:
- Leve: Ele é executado de forma rápida e eficiente.
- Flexível: Altamente configurável para atender às suas necessidades.
- Transparente: O fluxo de dados é visível e fácil de entender.
- Fácil de compartilhar: Cada arquivo representa um fluxo de trabalho reproduzível.
- Bom para prototipagem: Crie protótipos com uma interface gráfica em vez de codificar.
❌ Desvantagens de usar o ComfyUI:
- Interface inconsistente: Cada fluxo de trabalho pode ter um layout de nó diferente.
- Muitos detalhes: Os usuários médios podem não precisar conhecer as conexões subjacentes.
1.2. Por onde começar com ComfyUI? 🏁
Acreditamos que a melhor maneira de aprender o ComfyUI é mergulhando em exemplos e experimentando-o em primeira mão. 🙌 É por isso que criamos este tutorial único que se destaca dos outros. Neste tutorial, você encontrará um guia detalhado, passo a passo, que você pode seguir.
Mas aqui está a melhor parte: 🌟 Integramos o ComfyUI diretamente a esta página da web! Você poderá interagir com exemplos do ComfyUI em tempo real à medida que avança pelo guia.🌟 Vamos mergulhar!
2. Fluxos de Trabalho do ComfyUI: Texto para Imagem 🖼️
Vamos começar com o caso mais simples: gerar uma imagem a partir de texto. Clique em Queue Prompt para executar o fluxo de trabalho. Após uma curta espera, você deve ver sua primeira imagem gerada! Para verificar sua fila, basta clicar em View Queue.
Aqui está um fluxo de trabalho padrão de texto para imagem para você experimentar:
Blocos de Construção Básicos 🕹️
O fluxo de trabalho do ComfyUI consiste em dois blocos de construção básicos: Nós e Arestas.
- Nós são os blocos retangulares, por exemplo, Load Checkpoint, Clip Text Encoder, etc. Cada nó executa um código específico e requer entradas, saídas e parâmetros.
- Arestas são os fios que conectam as saídas e entradas entre os nós.
Controles Básicos 🕹️
- Amplie e reduza usando a roda do mouse ou beliscando com dois dedos.
- Arraste e segure o ponto de entrada ou saída para criar conexões entre os nós.
- Mova-se pelo espaço de trabalho segurando e arrastando com o botão esquerdo do mouse.
Vamos mergulhar nos detalhes deste fluxo de trabalho.
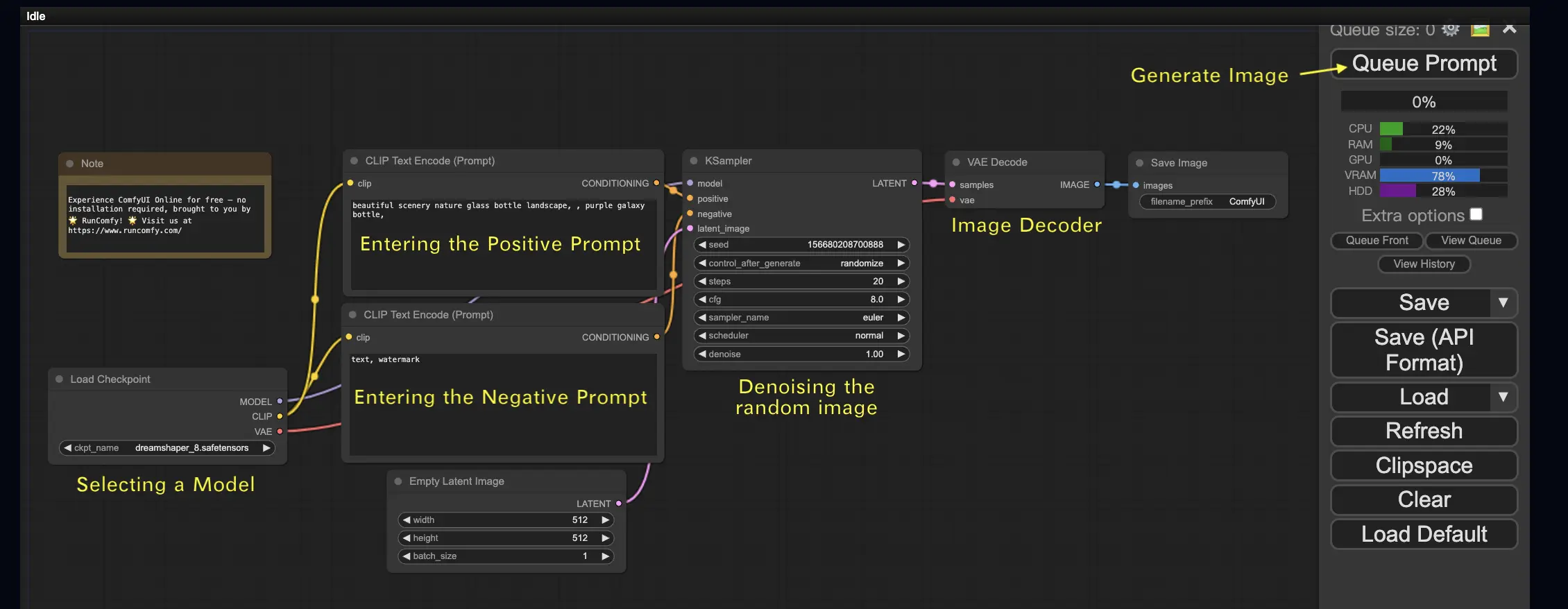
2.1. Selecionando um Modelo 🗃️
Primeiro, selecione um modelo Stable Diffusion Checkpoint no nó Load Checkpoint. Clique no nome do modelo para ver os modelos disponíveis. Se clicar no nome do modelo não fizer nada, você pode precisar fazer upload de um modelo personalizado.
2.2. Inserindo o Prompt Positivo e o Prompt Negativo 📝
Você verá dois nós chamados CLIP Text Encode (Prompt). O prompt superior está conectado à entrada positive do nó KSampler, enquanto o prompt inferior está conectado à entrada negative. Portanto, insira seu prompt positivo no superior e seu prompt negativo no inferior.
O nó CLIP Text Encode converte o prompt em tokens e os codifica em embeddings usando o codificador de texto.
💡 Dica: Use a sintaxe (keyword:weight) para controlar o peso de uma palavra-chave, por exemplo, (keyword:1.2) para aumentar seu efeito ou (keyword:0.8) para diminuí-lo.
2.3. Gerando uma Imagem 🎨
Clique em Queue Prompt para executar o fluxo de trabalho. Após uma curta espera, sua primeira imagem será gerada!
2.4. Explicação Técnica do ComfyUI 🤓
O poder do ComfyUI está em sua configurabilidade. Entender o que cada nó faz permite ajustá-los às suas necessidades. Mas antes de mergulhar nos detalhes, vamos dar uma olhada no processo da Stable Diffusion para entender melhor como o ComfyUI funciona.
O processo da Stable Diffusion pode ser resumido em três etapas principais:
- Codificação de Texto: O prompt de entrada do usuário é compilado em vetores de recursos de palavras individuais por um componente chamado Text Encoder. Esta etapa converte o texto em um formato que o modelo pode entender e trabalhar.
- Transformação do Espaço Latente: Os vetores de recursos do Text Encoder e uma imagem de ruído aleatório são transformados em um espaço latente. Neste espaço, a imagem aleatória passa por um processo de remoção de ruído com base nos vetores de recursos, resultando em um produto intermediário. Esta é a etapa onde a mágica acontece, pois o modelo aprende a associar os recursos de texto com representações visuais.
- Decodificação de Imagem: Finalmente, o produto intermediário do espaço latente é decodificado pelo Image Decoder, convertendo-o em uma imagem real que podemos ver e apreciar.
Agora que temos uma compreensão de alto nível do processo da Stable Diffusion, vamos mergulhar nos componentes e nós principais do ComfyUI que tornam esse processo possível.
2.4.1 Nó Load Checkpoint 🗃️
O nó Load Checkpoint no ComfyUI é crucial para selecionar um modelo Stable Diffusion. Um modelo Stable Diffusion consiste em três componentes principais: MODEL, CLIP e VAE. Vamos explorar cada componente e sua relação com os nós correspondentes no ComfyUI.
- MODEL: O componente MODEL é o modelo preditor de ruído que opera no espaço latente. Ele é responsável pelo processo central de gerar imagens a partir da representação latente. No ComfyUI, a saída MODEL do nó Load Checkpoint se conecta ao nó KSampler, onde ocorre o processo reverso de difusão. O nó KSampler usa o MODEL para remover o ruído da representação latente iterativamente, refinando gradualmente a imagem até que ela corresponda ao prompt desejado.
- CLIP: CLIP (Contrastive Language-Image Pre-training) é um modelo de linguagem que pré-processa os prompts positivos e negativos fornecidos pelo usuário. Ele converte os prompts de texto em um formato que o MODEL pode entender e usar para orientar o processo de geração de imagem. No ComfyUI, a saída CLIP do nó Load Checkpoint se conecta ao nó CLIP Text Encode. O nó CLIP Text Encode pega os prompts fornecidos pelo usuário e os alimenta no modelo de linguagem CLIP, transformando cada palavra em embeddings. Esses embeddings capturam o significado semântico das palavras e permitem que o MODEL gere imagens alinhadas com os prompts fornecidos.
- VAE: VAE (Variational AutoEncoder) é responsável por converter a imagem entre o espaço de pixels e o espaço latente. Ele consiste em um codificador que compacta a imagem em uma representação latente de dimensão inferior e um decodificador que reconstrói a imagem a partir da representação latente. No processo de texto para imagem, o VAE é usado apenas na etapa final para converter a imagem gerada do espaço latente de volta para o espaço de pixels. O nó VAE Decode no ComfyUI pega a saída do nó KSampler (que opera no espaço latente) e usa a parte do decodificador do VAE para transformar a representação latente na imagem final no espaço de pixels.
É importante observar que o VAE é um componente separado do modelo de linguagem CLIP. Enquanto o CLIP se concentra no processamento de prompts de texto, o VAE lida com a conversão entre os espaços de pixels e latente.
2.4.2. CLIP Text Encode 📝
O nó CLIP Text Encode no ComfyUI é responsável por pegar os prompts fornecidos pelo usuário e alimentá-los no modelo de linguagem CLIP. CLIP é um poderoso modelo de linguagem que entende o significado semântico das palavras e pode associá-las a conceitos visuais. Quando um prompt é inserido no nó CLIP Text Encode, ele passa por um processo de transformação onde cada palavra é convertida em embeddings. Esses embeddings são vetores de alta dimensão que capturam as informações semânticas das palavras. Ao transformar os prompts em embeddings, o CLIP permite que o MODEL gere imagens que refletem com precisão o significado e a intenção dos prompts fornecidos.
2.4.3. Empty Latent Image 🌌
No processo de texto para imagem, a geração começa com uma imagem aleatória no espaço latente. Essa imagem aleatória serve como o estado inicial com o qual o MODEL trabalha. O tamanho da imagem latente é proporcional ao tamanho real da imagem no espaço de pixels. No ComfyUI, você pode ajustar a altura e a largura da imagem latente para controlar o tamanho da imagem gerada. Além disso, você pode definir o tamanho do lote para determinar o número de imagens geradas em cada execução.
Os tamanhos ideais para imagens latentes dependem do modelo Stable Diffusion específico que está sendo usado. Para modelos SD v1.5, os tamanhos recomendados são 512x512 ou 768x768, enquanto para modelos SDXL, o tamanho ideal é 1024x1024. O ComfyUI fornece uma variedade de proporções de aspecto comuns para escolher, como 1:1 (quadrado), 3:2 (paisagem), 2:3 (retrato), 4:3 (paisagem), 3:4 (retrato), 16:9 (widescreen) e 9:16 (vertical). É importante observar que a largura e a altura da imagem latente devem ser divisíveis por 8 para garantir a compatibilidade com a arquitetura do modelo.
2.4.4. VAE 🔍
O VAE (Variational AutoEncoder) é um componente crucial no modelo Stable Diffusion que lida com a conversão de imagens entre o espaço de pixels e o espaço latente. Ele consiste em duas partes principais: um Image Encoder e um Image Decoder.
O Image Encoder pega uma imagem no espaço de pixels e a compacta em uma representação latente de dimensão inferior. Esse processo de compressão reduz significativamente o tamanho dos dados, permitindo um processamento e armazenamento mais eficientes. Por exemplo, uma imagem de tamanho 512x512 pixels pode ser compactada em uma representação latente de tamanho 64x64.
Por outro lado, o Image Decoder, também conhecido como VAE Decoder, é responsável por reconstruir a imagem a partir da representação latente de volta para o espaço de pixels. Ele pega a representação latente compactada e a expande para gerar a imagem final.
Usar um VAE oferece várias vantagens:
- Eficiência: Ao comprimir a imagem em um espaço latente de dimensão inferior, o VAE permite uma geração mais rápida e tempos de treinamento mais curtos. O tamanho reduzido dos dados permite um processamento e uso de memória mais eficientes.
- Manipulação do espaço latente: O espaço latente fornece uma representação mais compacta e significativa da imagem. Isso permite um controle e edição mais precisos dos detalhes e estilo da imagem. Ao manipular a representação latente, torna-se possível modificar aspectos específicos da imagem gerada.
No entanto, também existem algumas desvantagens a serem consideradas:
- Perda de dados: Durante o processo de codificação e decodificação, alguns detalhes da imagem original podem ser perdidos. As etapas de compressão e reconstrução podem introduzir artefatos ou pequenas variações na imagem final em comparação com a original.
- Captura limitada dos dados originais: O espaço latente de dimensão inferior pode não ser capaz de capturar completamente todas as características e detalhes intrincados da imagem original. Algumas informações podem ser perdidas durante o processo de compressão, resultando em uma representação um pouco menos precisa dos dados originais.
Apesar dessas limitações, o VAE desempenha um papel vital no modelo Stable Diffusion, permitindo uma conversão eficiente entre o espaço de pixels e o espaço latente, facilitando uma geração mais rápida e um controle mais preciso sobre as imagens geradas.
2.4.5. KSampler ⚙️
O nó KSampler no ComfyUI é o coração do processo de geração de imagem na Stable Diffusion. Ele é responsável por remover o ruído da imagem aleatória no espaço latente para corresponder ao prompt fornecido pelo usuário. O KSampler emprega uma técnica chamada difusão reversa, onde ele refina iterativamente a representação latente removendo o ruído e adicionando detalhes significativos com base na orientação dos embeddings CLIP.
O nó KSampler oferece vários parâmetros que permitem aos usuários ajustar o processo de geração de imagem:
Seed: O valor da semente controla o ruído inicial e a composição da imagem final. Ao definir uma semente específica, os usuários podem obter resultados reproduzíveis e manter a consistência em várias gerações.
Control_after_generation: Este parâmetro determina como o valor da semente muda após cada geração. Ele pode ser definido para aleatorizar (gerar uma nova semente aleatória para cada execução), incrementar (aumentar o valor da semente em 1), decrementar (diminuir o valor da semente em 1) ou fixo (manter o valor da semente constante).
Step: O número de etapas de amostragem determina a intensidade do processo de refinamento. Valores mais altos resultam em menos artefatos e imagens mais detalhadas, mas também aumentam o tempo de geração.
Sampler_name: Este parâmetro permite que os usuários escolham o algoritmo de amostragem específico usado pelo KSampler. Algoritmos de amostragem diferentes podem produzir resultados ligeiramente diferentes e ter velocidades de geração variadas.
Scheduler: O agendador controla como o nível de ruído muda em cada etapa do processo de remoção de ruído. Ele determina a taxa na qual o ruído é removido da representação latente.
Denoise: O parâmetro de denoise define a quantidade de ruído inicial que deve ser apagada pelo processo de remoção de ruído. Um valor de 1 significa que todo o ruído será removido, resultando em uma imagem limpa e detalhada.
Ao ajustar esses parâmetros, você pode ajustar o processo de geração de imagem para obter os resultados desejados.
Agora, você está pronto para embarcar em sua jornada ComfyUI?
Na RunComfy, criamos a melhor experiência ComfyUI online só para você. Diga adeus a instalações complicadas! 🎉 Experimente o ComfyUI Online agora e libere seu potencial artístico como nunca antes! 🎉
3. Fluxo de Trabalho do ComfyUI: Imagem para Imagem 🖼️
O fluxo de trabalho Imagem para Imagem gera uma imagem com base em um prompt e uma imagem de entrada. Experimente você mesmo!
Para usar o fluxo de trabalho Imagem para Imagem:
- Selecione o modelo checkpoint.
- Faça upload da imagem como um prompt de imagem.
- Revise os prompts positivos e negativos.
- Opcionalmente, ajuste o denoise (força de remoção de ruído) no nó KSampler.
- Pressione Queue Prompt para iniciar a geração.
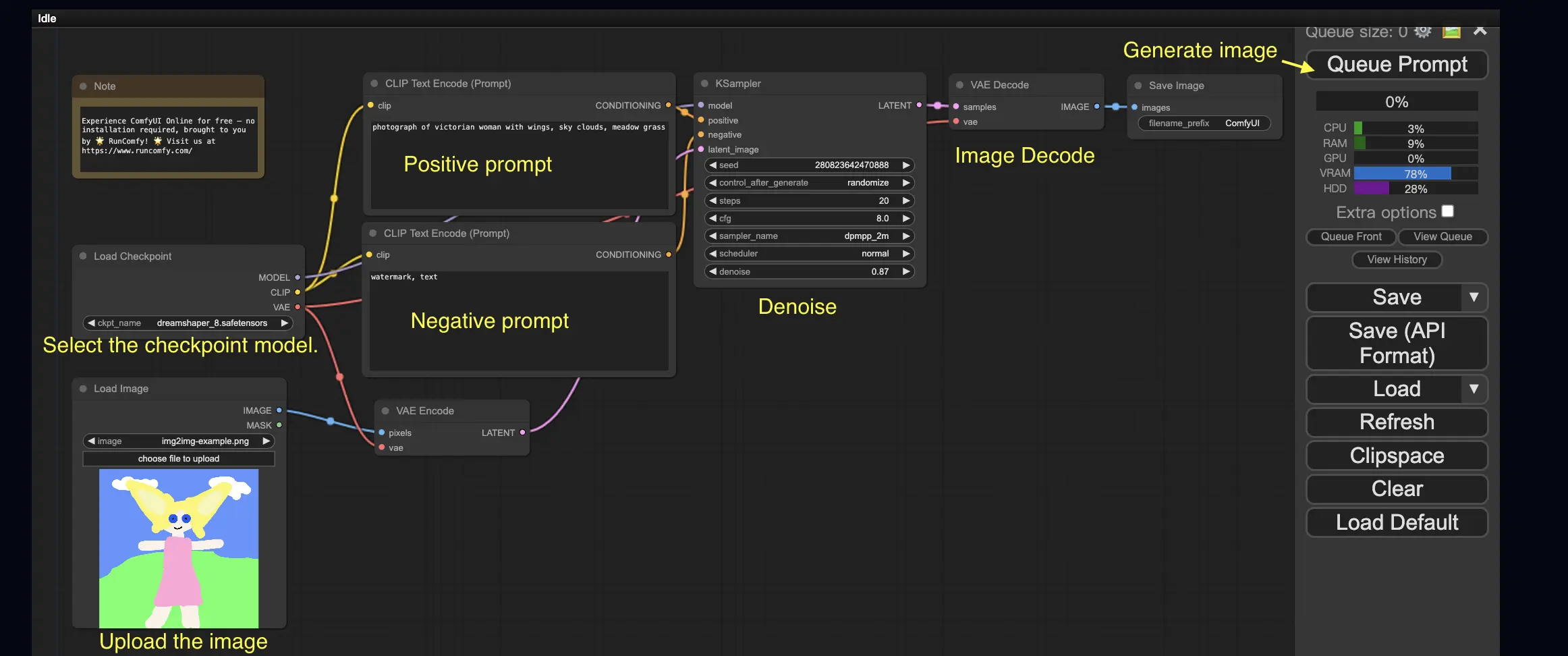
Para mais fluxos de trabalho ComfyUI premium, visite nossa 🌟Lista de Fluxos de Trabalho ComfyUI🌟
4. ComfyUI SDXL 🚀
Graças à sua configurabilidade extrema, o ComfyUI é uma das primeiras GUIs a suportar o modelo Stable Diffusion XL. Vamos experimentá-lo!
Para usar o fluxo de trabalho ComfyUI SDXL:
- Revise os prompts positivos e negativos.
- Pressione Queue Prompt para iniciar a geração.
5. ComfyUI Inpainting 🎨
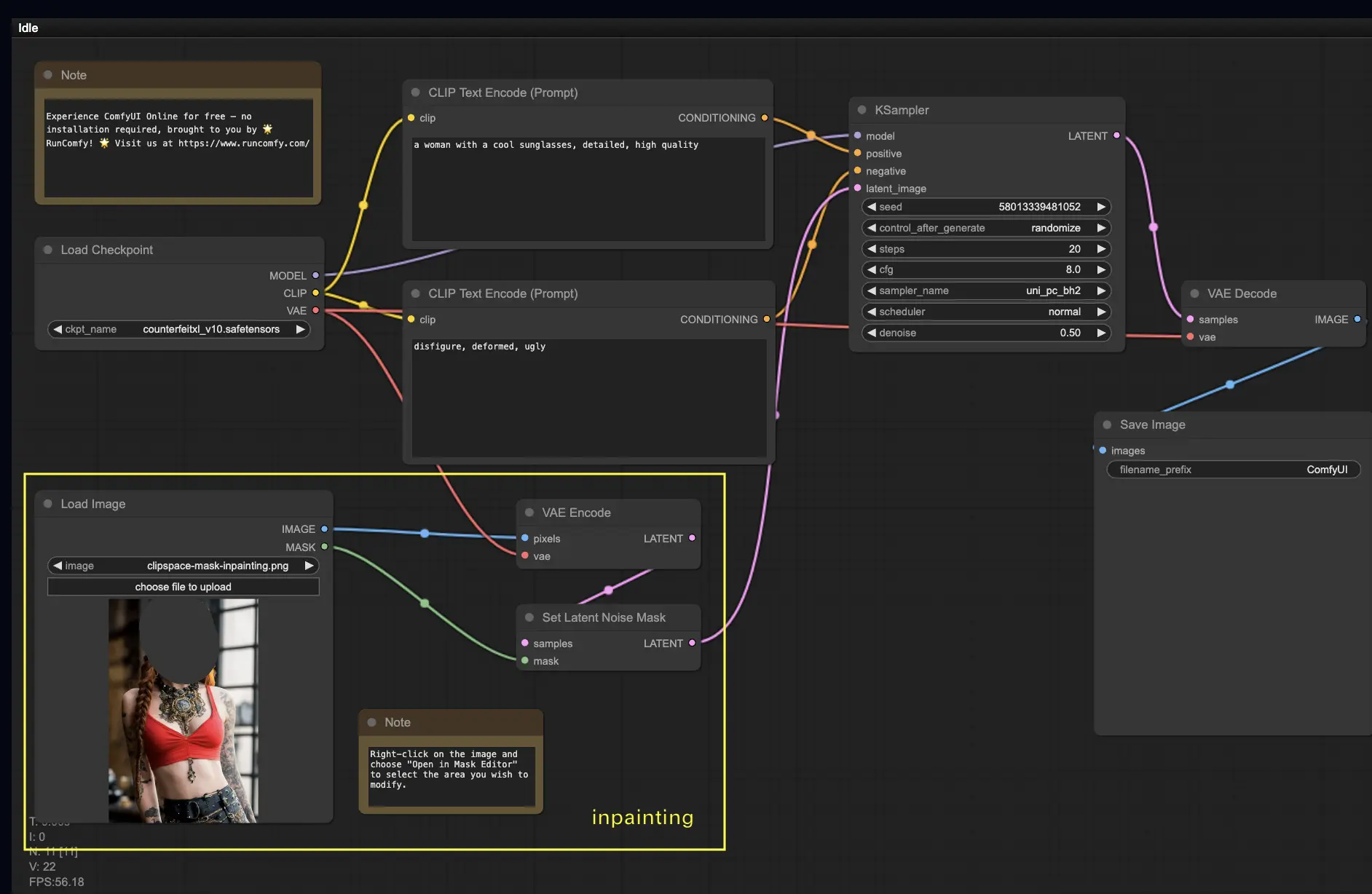
Vamos mergulhar em algo mais complexo: inpainting! Quando você tem uma ótima imagem, mas deseja modificar partes específicas, inpainting é o melhor método. Experimente aqui!
Para usar o fluxo de trabalho de inpainting:
- Faça upload de uma imagem que você deseja fazer inpainting.
- Clique com o botão direito na imagem e selecione "Open in MaskEditor". Mascare a área a ser regenerada e clique em "Save to node".
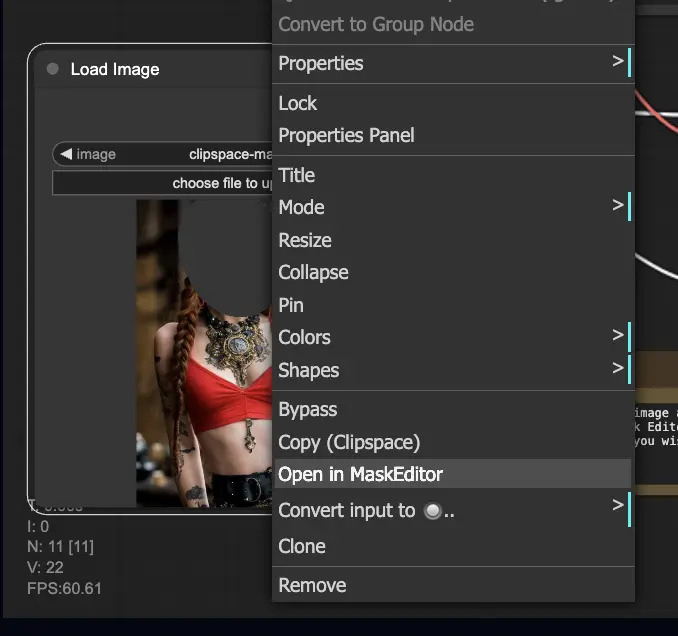
- Selecione um modelo Checkpoint:
- Este fluxo de trabalho funciona apenas com um modelo Stable Diffusion padrão, não um modelo Inpainting.
- Se você deseja utilizar um modelo de inpainting, troque os nós "VAE Encode" e "Set Noise Latent Mask" para o nó "VAE Encode (Inpaint)", que é projetado especificamente para modelos de inpainting.
- Personalize o processo de inpainting:
- No nó CLIP Text Encode (Prompt), você pode inserir informações adicionais para orientar o inpainting. Por exemplo, você pode especificar o estilo, tema ou elementos que deseja incluir na área de inpainting.
- Defina a força original de denoise (denoising strength), por exemplo, 0.6.
- Pressione Queue Prompt para realizar o inpainting.
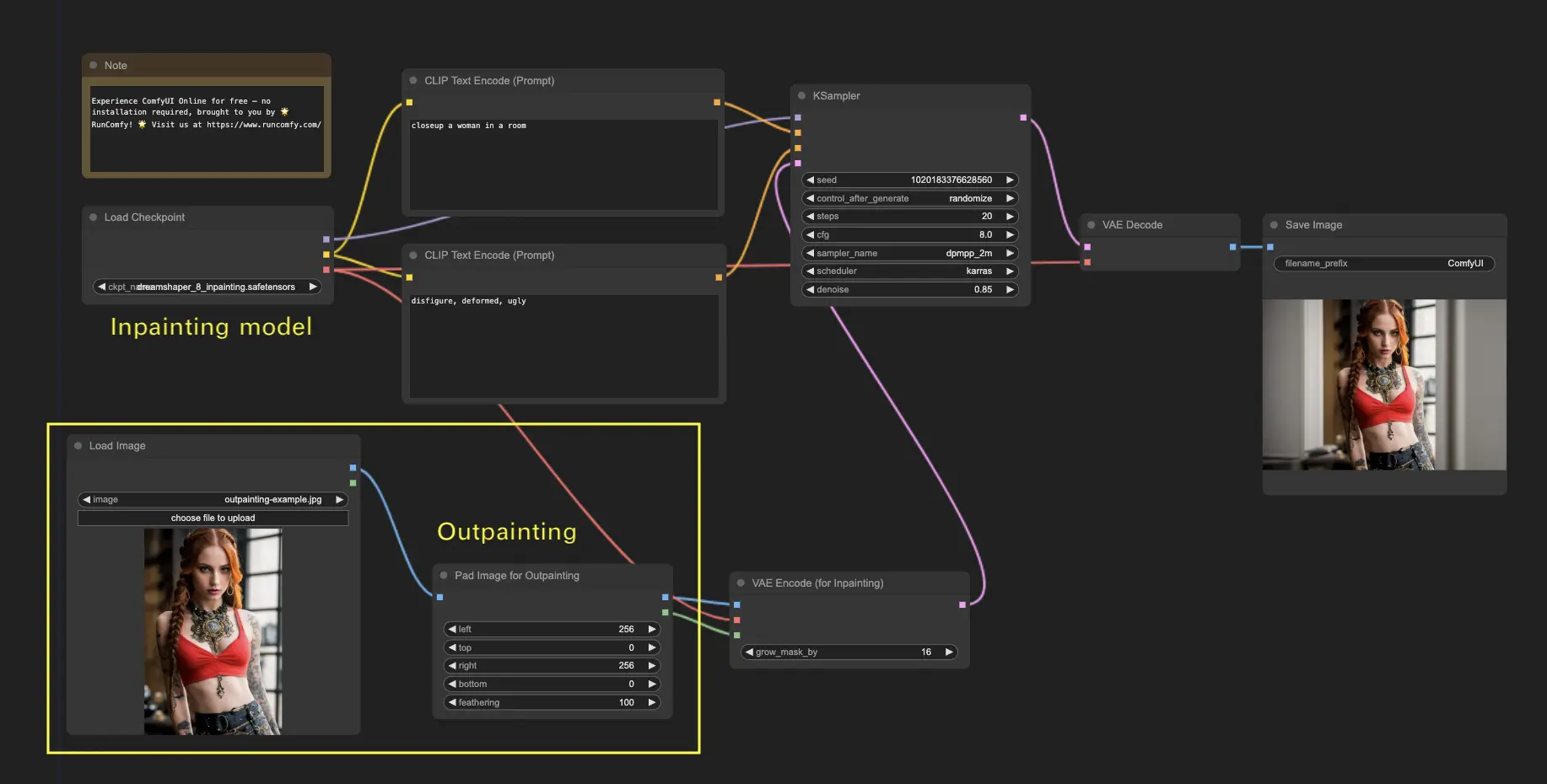
6. ComfyUI Outpainting 🖌️
Outpainting é outra técnica emocionante que permite expandir suas imagens além de seus limites originais. 🌆 É como ter uma tela infinita para trabalhar!
Para usar o fluxo de trabalho ComfyUI Outpainting:
- Comece com uma imagem que deseja expandir.
- Use o nó Pad Image for Outpainting no seu fluxo de trabalho.
- Configure as configurações de outpainting:
- left, top, right, bottom: Especifique o número de pixels a serem expandidos em cada direção.
- feathering: Ajuste a suavidade da transição entre a imagem original e a área de outpainting. Valores mais altos criam uma mistura mais gradual, mas podem introduzir um efeito de borrão.
- Personalize o processo de outpainting:
- No nó CLIP Text Encode (Prompt), você pode inserir informações adicionais para orientar o outpainting. Por exemplo, você pode especificar o estilo, tema ou elementos que deseja incluir na área expandida.
- Experimente com prompts diferentes para obter os resultados desejados.
- Ajuste o nó VAE Encode (for Inpainting):
- Ajuste o parâmetro grow_mask_by para controlar o tamanho da máscara de outpainting. Um valor maior que 10 é recomendado para resultados ideais.
- Pressione Queue Prompt para iniciar o processo de outpainting.
Para mais fluxos de trabalho premium de restauração/upscale, visite nossa 🌟Lista de Fluxos de Trabalho ComfyUI🌟
7. ComfyUI Upscale ⬆️
A seguir, vamos explorar o ComfyUI upscale. Apresentaremos três fluxos de trabalho fundamentais para ajudá-lo a fazer upscale com eficiência.
Existem dois métodos principais para fazer upscale:
- Upscale pixel: Faz upscale diretamente na imagem visível.
- Entrada: imagem, Saída: imagem ampliada
- Upscale latent: Faz upscale na imagem invisível do espaço latente.
- Entrada: latente, Saída: latente ampliado (requer decodificação para se tornar uma imagem visível)
7.1. Upscale Pixel 🖼️
Duas maneiras de alcançar isso:
- Usando algoritmos: Velocidade de geração mais rápida, mas resultados ligeiramente inferiores em comparação com modelos.
- Usando modelos: Melhores resultados, mas tempo de geração mais lento.
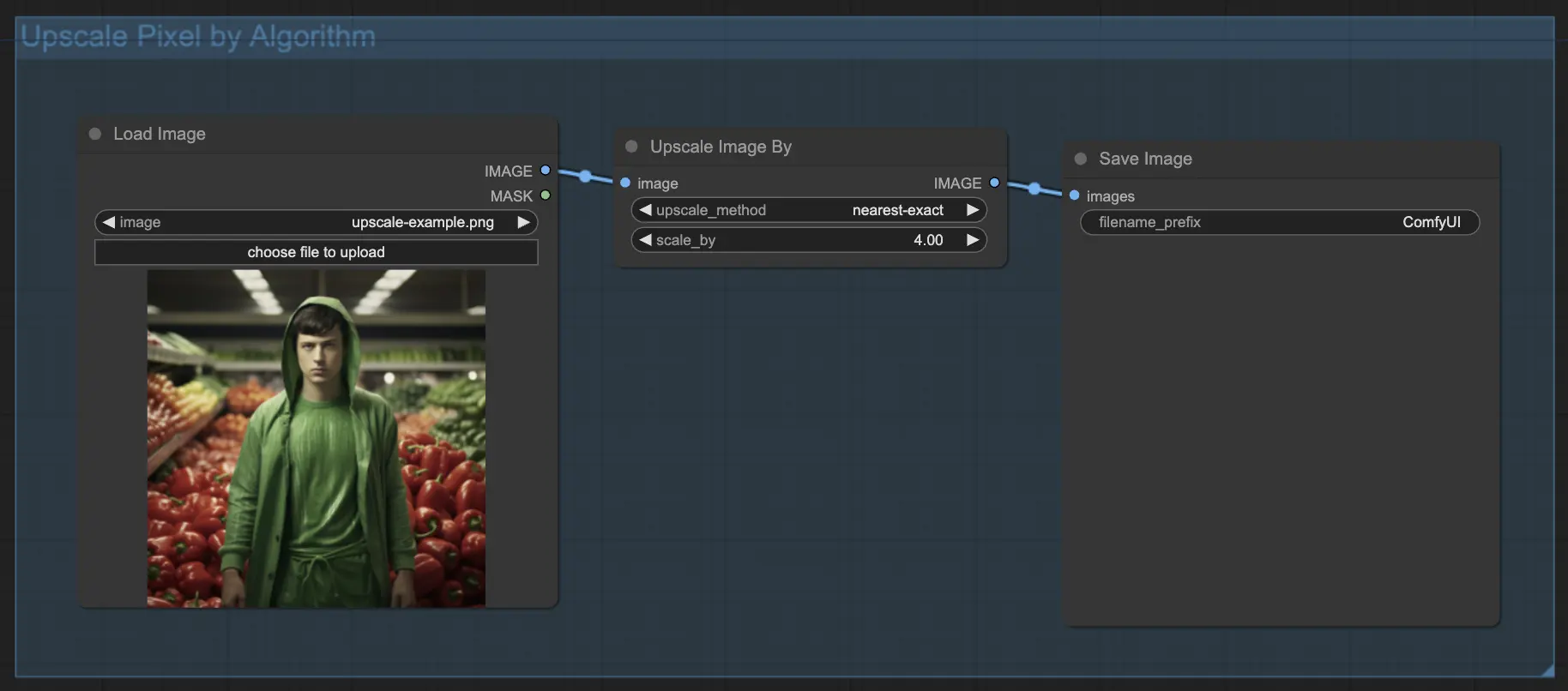
7.1.1. Upscale Pixel por Algoritmo 🧮
- Adicione o nó Upscale Image by.
- Parâmetro method: Escolha o algoritmo de upscale (bicubic, bilinear, nearest-exact).
- Parâmetro Scale: Especifique o fator de upscale (por exemplo, 2 para 2x).
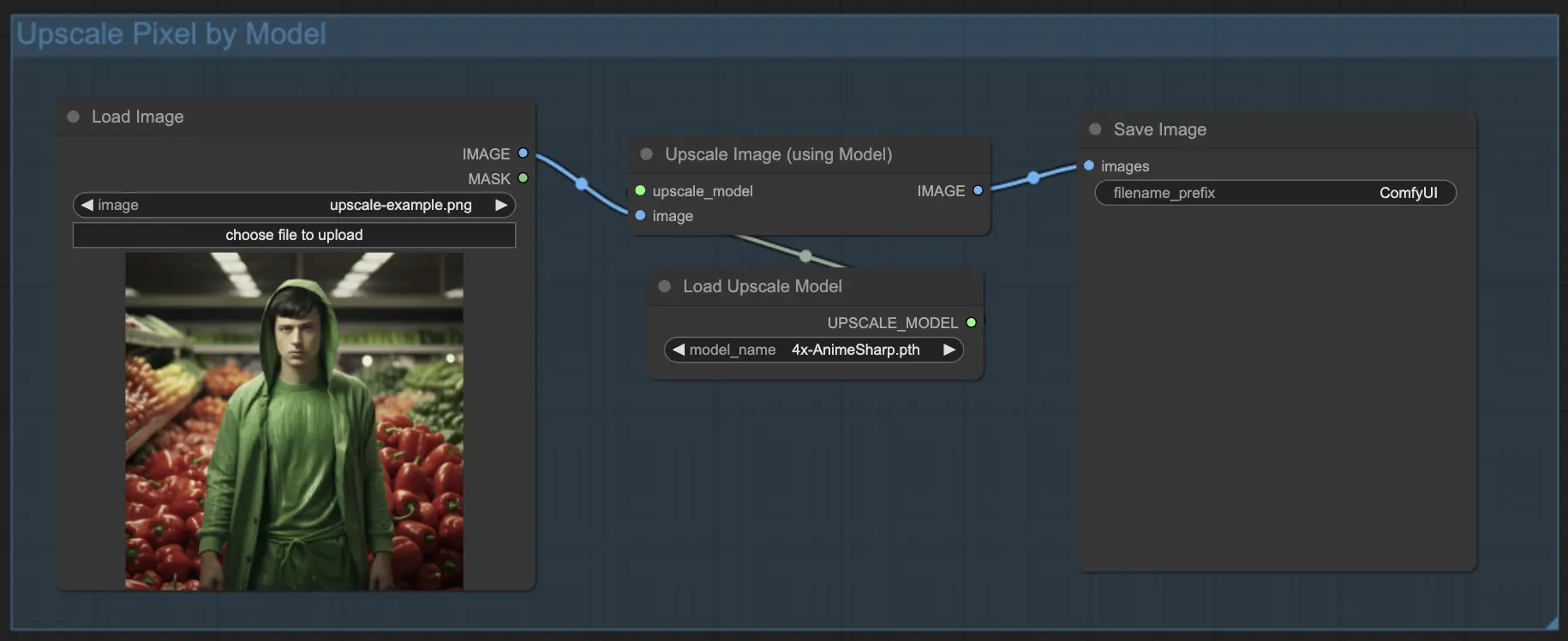
7.1.2. Upscale Pixel por Modelo 🤖
- Adicione o nó Upscale Image (using Model).
- Adicione o nó Load Upscale Model.
- Escolha um modelo adequado para o tipo de imagem (por exemplo, anime ou vida real).
- Selecione o fator de upscale (X2 ou X4).
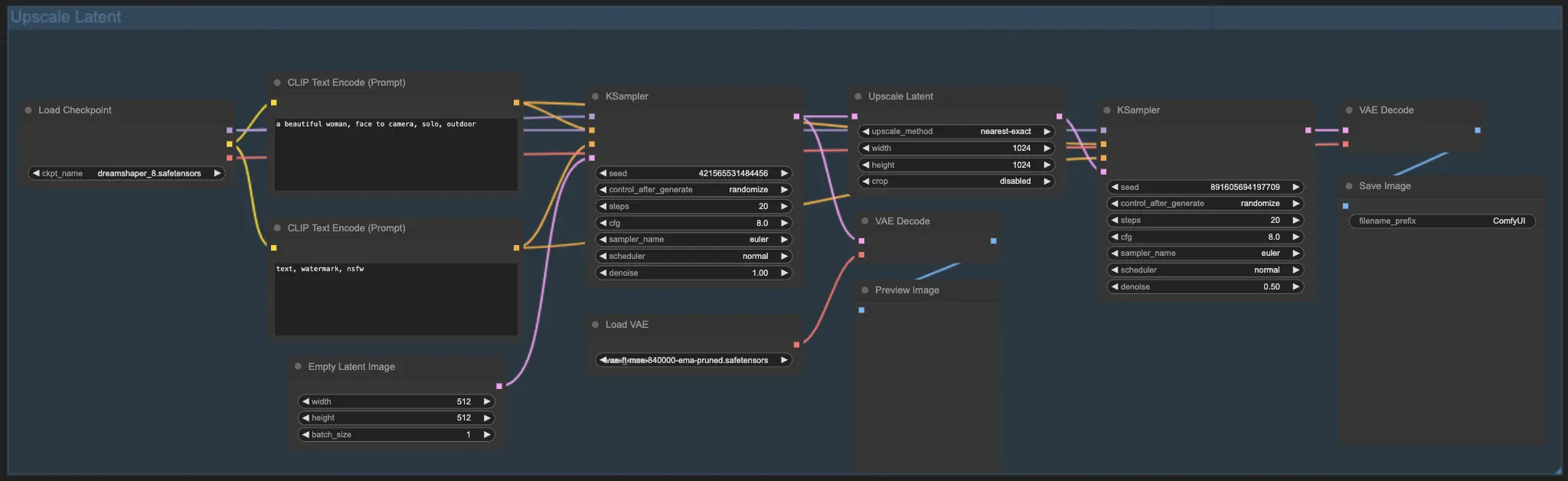
7.2. Upscale Latent ⚙️
Outro método de upscale é o Upscale Latent, também conhecido como Hi-res Latent Fix Upscale, que faz upscale diretamente no espaço latente.
7.3. Upscale Pixel vs. Upscale Latent 🆚
- Upscale Pixel: Apenas amplia a imagem sem adicionar novas informações. Geração mais rápida, mas pode ter um efeito de borrão e falta de detalhes.
- Upscale Latent: Além de ampliar, altera algumas informações da imagem original, enriquecendo detalhes. Pode desviar da imagem original e tem uma velocidade de geração mais lenta.
Para mais fluxos de trabalho premium de restauração/upscale, visite nossa 🌟Lista de Fluxos de Trabalho ComfyUI🌟
8. ComfyUI ControlNet 🎮
Prepare-se para levar sua arte de IA para o próximo nível com o ControlNet, uma tecnologia inovadora que revoluciona a geração de imagens!
ControlNet é como uma varinha mágica 🪄 que concede um controle sem precedentes sobre suas imagens geradas por IA. Ele trabalha em conjunto com modelos poderosos como a Stable Diffusion, aprimorando suas capacidades e permitindo que você oriente o processo de criação de imagens como nunca antes!
Imagine ser capaz de especificar as bordas, poses humanas, profundidade ou mesmo mapas de segmentação da imagem desejada. 🌠 Com o ControlNet, você pode fazer exatamente isso!
Se você está ansioso para mergulhar mais profundamente no mundo do ControlNet e liberar todo o seu potencial, nós o cobrimos. Confira nosso tutorial detalhado sobre como dominar o ControlNet no ComfyUI! 📚 Ele está repleto de guias passo a passo e exemplos inspiradores para ajudá-lo a se tornar um profissional em ControlNet. 🏆
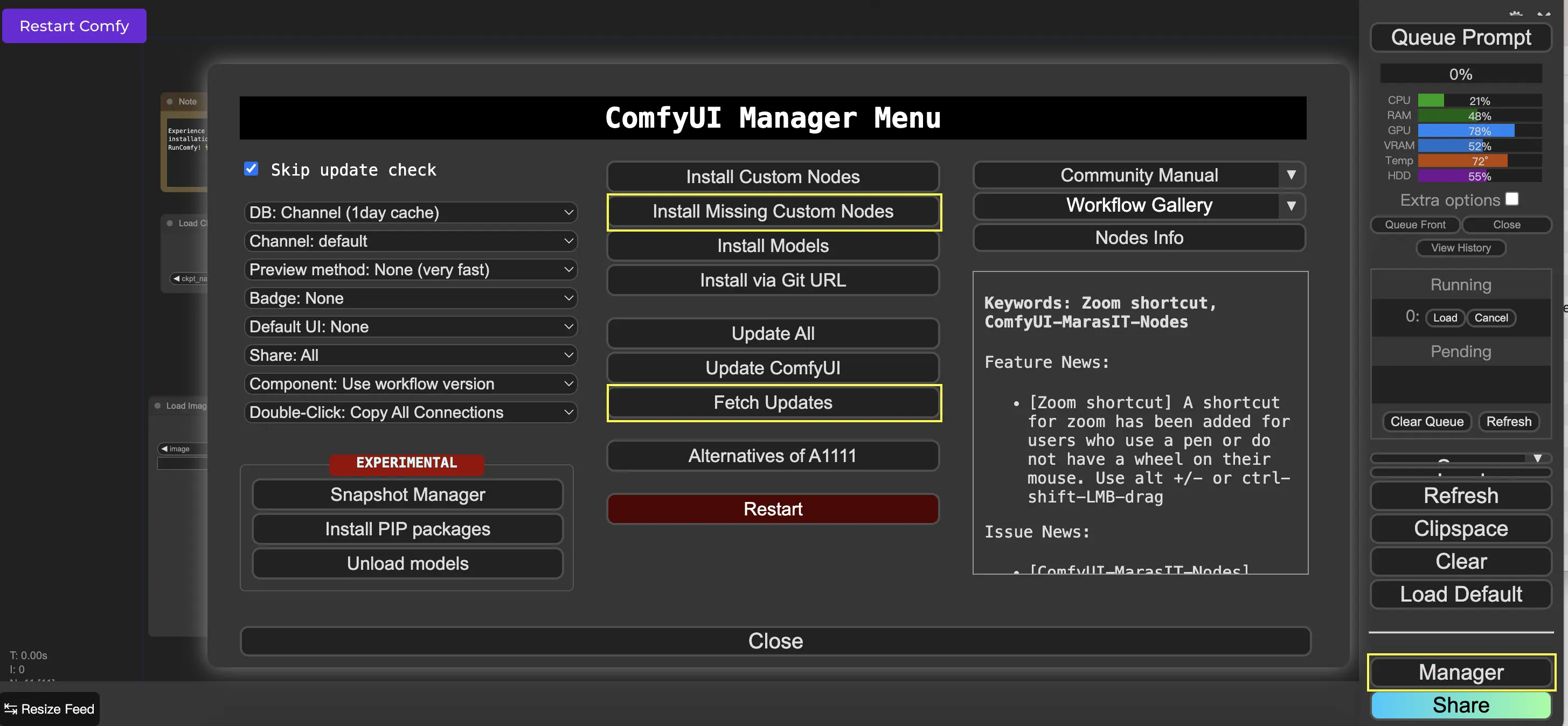
9. ComfyUI Manager 🛠️
ComfyUI Manager é um nó personalizado que permite instalar e atualizar outros nós personalizados através da interface do ComfyUI. Você encontrará o botão Manager no menu Queue Prompt.
9.1. Como Instalar Nós Personalizados Ausentes 📥
Se um fluxo de trabalho exigir nós personalizados que você não instalou, siga estas etapas:
- Clique em Manager no Menu.
- Clique em Install Missing Custom Nodes.
- Reinicie o ComfyUI completamente.
- Atualize o navegador.
9.2. Como Atualizar Nós Personalizados 🔄
- Clique em Manager no Menu.
- Clique em Fetch Updates (pode levar um tempo).
- Clique em Install Custom Nodes.
- Se uma atualização estiver disponível, um botão Update aparecerá ao lado do nó personalizado instalado.
- Clique em Update para atualizar o nó.
- Reinicie o ComfyUI.
- Atualize o navegador.
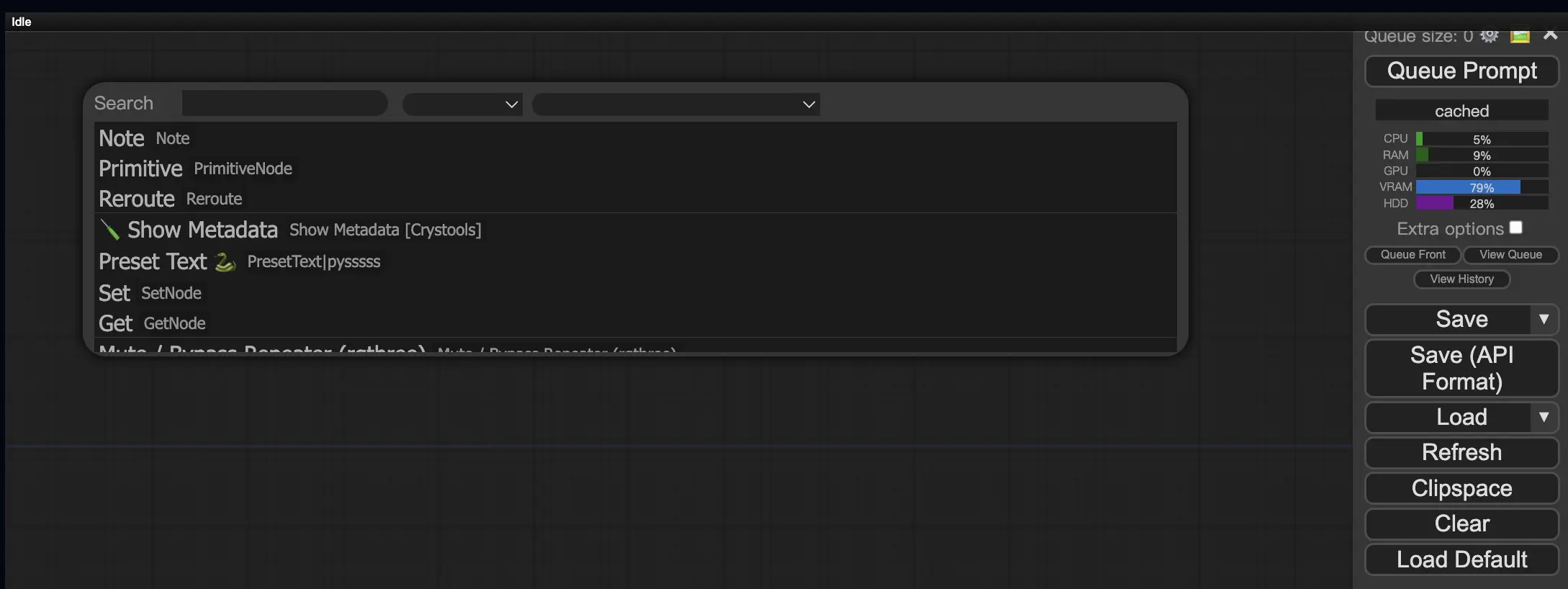
9.3. Como Carregar Nós Personalizados em seu Fluxo de Trabalho 🔍
Clique duas vezes em qualquer área vazia para abrir um menu de pesquisa de nós.
10. ComfyUI Embeddings 📝
Embeddings, também conhecidos como inversão textual, são um recurso poderoso no ComfyUI que permite injetar conceitos ou estilos personalizados em suas imagens geradas por IA. 💡 É como ensinar à IA uma nova palavra ou frase e associá-la a características visuais específicas.
Para usar embeddings no ComfyUI, basta digitar "embedding:" seguido pelo nome do seu embedding na caixa de prompt positivo ou negativo. Por exemplo:
embedding: BadDream
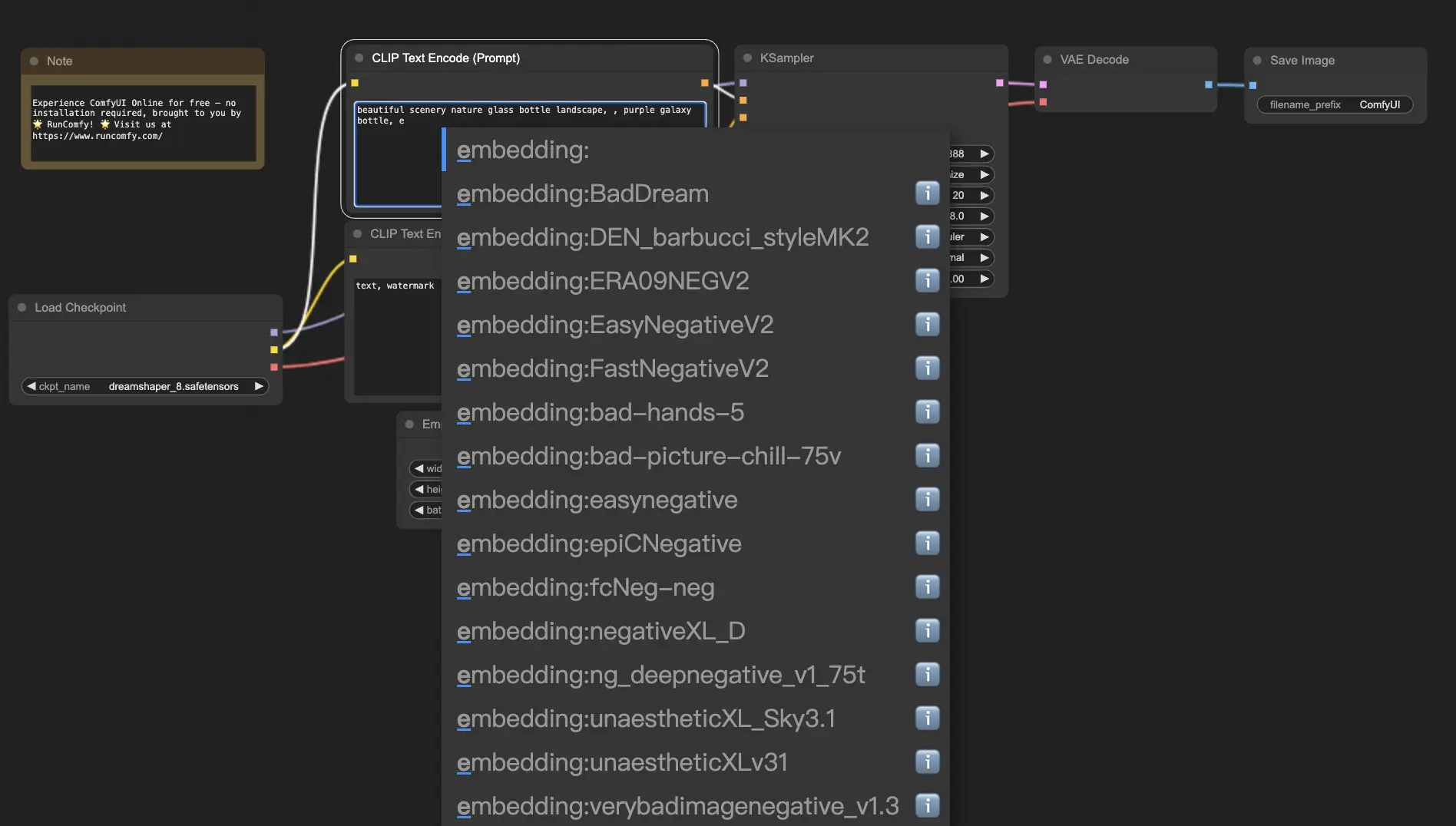
Quando você usar este prompt, o ComfyUI procurará por um arquivo de embedding chamado "BadDream" na pasta ComfyUI > models > embeddings. 📂 Se encontrar uma correspondência, ele aplicará as características visuais correspondentes à sua imagem gerada.
Embeddings são uma ótima maneira de personalizar sua arte de IA e obter estilos ou estéticas específicas. 🎨 Você pode criar seus próprios embeddings treinando-os em um conjunto de imagens que representam o conceito ou estilo desejado.
10.1. Embedding com Autocompletar 🔠
Lembrar os nomes exatos de seus embeddings pode ser um incômodo, especialmente se você tiver uma grande coleção. 😅 É aí que o nó personalizado ComfyUI-Custom-Scripts vem para o resgate!
Para habilitar o autocompletar de nomes de embedding:
- Abra o ComfyUI Manager clicando em "Manager" no menu superior.
- Vá para "Install Custom nodes" e procure por "ComfyUI-Custom-Scripts".
- Clique em "Install" para adicionar o nó personalizado à sua configuração do ComfyUI.
- Reinicie o ComfyUI para aplicar as alterações.
Uma vez que você tenha o nó ComfyUI-Custom-Scripts instalado, terá uma maneira mais amigável de usar embeddings. 😊 Basta começar a digitar "embedding:" em uma caixa de prompt e uma lista de embeddings disponíveis aparecerá. Você pode então selecionar o embedding desejado da lista, economizando tempo e esforço!
10.2. Embedding Weight ⚖️
Você sabia que pode controlar a força de seus embeddings? 💪 Como embeddings são essencialmente palavras-chave, você pode aplicar pesos a eles assim como faria com palavras-chave regulares em seus prompts.
Para ajustar o peso de um embedding, use a seguinte sintaxe:
(embedding: BadDream:1.2)
Neste exemplo, o peso do embedding "BadDream" é aumentado em 20%. Portanto, pesos mais altos (por exemplo, 1.2) tornarão o embedding mais proeminente, enquanto pesos mais baixos (por exemplo, 0.8) reduzirão sua influência. 🎚️ Isso lhe dá ainda mais controle sobre o resultado final!
11. ComfyUI LoRA 🧩
LoRA, abreviação de Low-rank Adaptation, é outro recurso emocionante no ComfyUI que permite modificar e ajustar seus modelos checkpoint. 🎨 É como adicionar um modelo pequeno e especializado em cima de seu modelo base para obter estilos específicos ou incorporar elementos personalizados.
Modelos LoRA são compactos e eficientes, tornando-os fáceis de usar e compartilhar. Eles são comumente usados para tarefas como modificar o estilo artístico de uma imagem ou injetar uma pessoa ou objeto específico no resultado gerado.
Quando você aplica um modelo LoRA a um modelo checkpoint, ele modifica os componentes MODEL e CLIP enquanto deixa o VAE (Variational Autoencoder) intocado. Isso significa que o LoRA se concentra em ajustar o conteúdo e o estilo da imagem sem alterar sua estrutura geral.
11.1. Como usar LoRA 🔧
Usar LoRA no ComfyUI é simples. Vamos dar uma olhada no método mais simples:
- Selecione um modelo checkpoint que serve como base para a geração de sua imagem.
- Escolha um modelo LoRA que deseja aplicar para modificar o estilo ou injetar elementos específicos.
- Revise os prompts positivos e negativos para orientar o processo de geração de imagem.
- Clique em "Queue Prompt" para começar a gerar a imagem com o LoRA aplicado. ▶
O ComfyUI combinará o modelo checkpoint e o modelo LoRA para criar uma imagem que reflita os prompts especificados e incorpore as modificações introduzidas pelo LoRA.
11.2. LoRAs Múltiplos 🧩🧩
Mas e se você quiser aplicar vários LoRAs a uma única imagem? Sem problemas! O ComfyUI permite que você use dois ou mais LoRAs no mesmo fluxo de trabalho de texto para imagem.
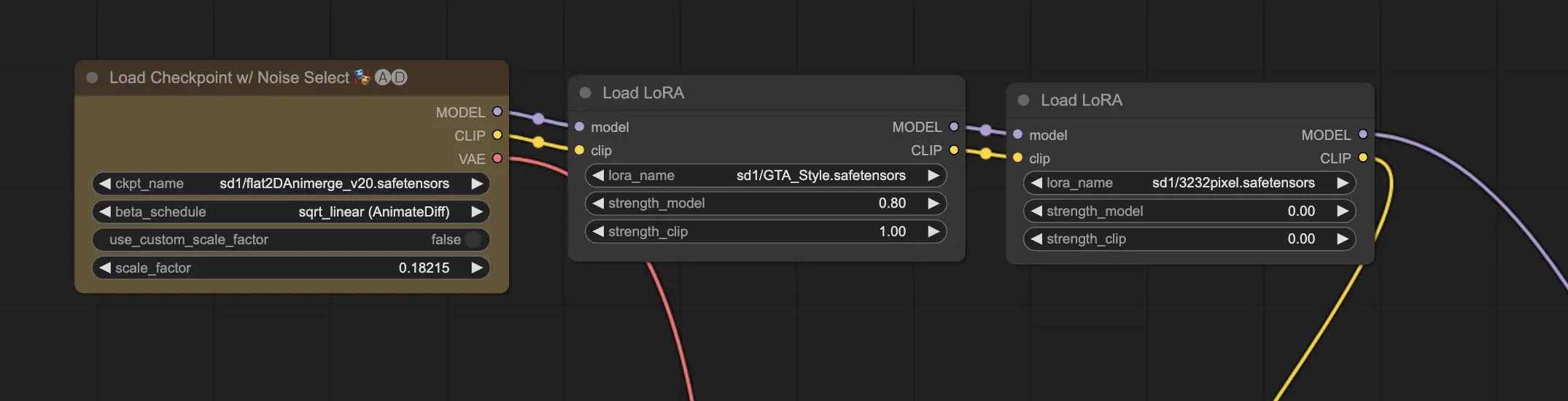
O processo é semelhante ao uso de um único LoRA, mas você precisará selecionar vários modelos LoRA em vez de apenas um. O ComfyUI aplicará os LoRAs sequencialmente, o que significa que cada LoRA se baseará nas modificações introduzidas pelo anterior.
Isso abre um mundo de possibilidades para combinar diferentes estilos, elementos e modificações em suas imagens geradas por IA. 🌍💡 Experimente com diferentes combinações de LoRA para obter resultados únicos e criativos!
12. Atalhos e Truques para ComfyUI ⌨️🖱️
12.1. Copiar e Colar 📋
- Selecione um nó e pressione Ctrl+C para copiar.
- Pressione Ctrl+V para colar.
- Pressione Ctrl+Shift+V para colar com as conexões de entrada intactas.
12.2. Movendo Vários Nós 🖱️
- Crie um grupo para mover um conjunto de nós juntos.
- Como alternativa, segure Ctrl e arraste para criar uma caixa para selecionar vários nós ou segure Ctrl para selecionar vários nós individualmente.
- Para mover os nós selecionados, segure Shift e mova o mouse.
12.3. Ignorar um Nó 🔇
- Desative temporariamente um nó silenciando-o. Selecione um nó e pressione Ctrl+M.
- Não há atalho de teclado para silenciar um grupo. Selecione Bypass Group Node no menu do botão direito ou silencie o primeiro nó do grupo para desativá-lo.
12.4. Minimizar um Nó 🔍
- Clique no ponto no canto superior esquerdo do nó para minimizá-lo.
12.5. Gerar Imagem ▶️
- Pressione Ctrl+Enter para colocar o fluxo de trabalho na fila e gerar imagens.
12.6. Fluxo de Trabalho Embutido 🖼️
- ComfyUI salva todo o fluxo de trabalho nos metadados do arquivo PNG que ele gera. Para carregar o fluxo de trabalho, arraste e solte a imagem no ComfyUI.
12.7. Corrigir Seeds para Economizar Tempo ⏰
- ComfyUI só executa novamente um nó se a entrada mudar. Ao trabalhar em uma longa cadeia de nós, economize tempo corrigindo o seed para evitar a regeneração de resultados anteriores.
13. ComfyUI Online 🚀
Parabéns por concluir este guia para iniciantes do ComfyUI! 🙌 Agora você está pronto para mergulhar no emocionante mundo da criação de arte com IA. Mas por que se incomodar com a instalação quando você pode começar a criar imediatamente? 🤔
Na RunComfy, simplificamos o uso do ComfyUI online sem qualquer configuração. Nosso serviço ComfyUI Online vem pré-carregado com mais de 200 nós e modelos populares, além de mais de 50 fluxos de trabalho deslumbrantes para inspirar suas criações.
🌟 Seja você um iniciante ou um artista de IA experiente, o RunComfy tem tudo que você precisa para dar vida às suas visões artísticas. 💡 Não espere mais – experimente o ComfyUI Online agora e experimente o poder da criação de arte com IA na ponta dos seus dedos! 🚀