Fluxo de Trabalho/Tutorial do Face Detailer ComfyUI - Corrigindo Rostos em Qualquer Vídeo ou Animação
Updated: 5/17/2024
Olá! 🌟 Hoje vamos explorar a arte de substituir e corrigir rostos em imagens e vídeos com algo super legal: o Face Detailer ComfyUI. Pegue seus pincéis digitais e vamos ser artísticos!
Vamos abordar:
- O que é o Face Detailer no ComfyUI?
- After Detailer (ADetailer) para Automatic111 vs. Face Detailer para ComfyUI
- ComfyUI Impact Pack - Face Detailer
- Fluxo de trabalho do Face Detailer ComfyUI - Sem Necessidade de Instalação, Totalmente Grátis
- Adicionar o Nó Face Detailer
- Entrada para o Face Detailer
- Insira a imagem que deseja restaurar
- Escolha o Modelo, Clip, VAE e Insira um Prompt Positivo e um Negativo
- A diferença do Detector BBox e do Detector Segm (modelo Sam)
- Configurações do Face Detailer: Como Usar o Face Detailer no ComfyUI
- Face Detailer - Tamanho do Guia, Tamanho do Guia Para, Tamanho Máximo e Fator de Corte BBX
- Face Detailer - Suavização
- Face Detailer - Máscara de Ruído
- Face Detailer - Forçar Preenchimento
- Face Detailer - Tamanho de Queda
- Face Detailer - Recursos Relacionados ao BBox
- Face Detailer - Recursos Relacionados ao Segm/Sam
- Outras Melhorias
- Dois Refinamentos de Passe com Face Detailer (Pipe)
- Aumente a Resolução do Vídeo usando 4x-UltraSharp
- Execute o Fluxo de Trabalho do Face Detailer ComfyUI Gratuitamente
1. O que é o Face Detailer no ComfyUI?
1.1 After Detailer (ADetailer) para Automatic111 vs. Face Detailer para ComfyUI
Acredito que você possa estar familiarizado ou ter ouvido falar da extensão After Detailer (ADetailer) para Automatic111, usada para corrigir rostos. Uma função semelhante a esta extensão, conhecida como Face Detailer, existe no ComfyUI e faz parte do Impact Pack Node. Portanto, se você deseja usar o ADetailer no ComfyUI, deve optar pelo Face Detailer do Impact Pack no ComfyUI.
1.2 ComfyUI Impact Pack - Face Detailer
O ComfyUI Impact Pack serve como sua caixa de ferramentas digital para aprimoramento de imagens, semelhante a um canivete suíço para suas imagens. Ele está equipado com vários módulos, como Detector, Detailer, Upscaler, Pipe e outros. O destaque é o Face Detailer, que restaura facilmente rostos em imagens, vídeos e animações.
2. Fluxo de Trabalho do Face Detailer ComfyUI - Sem Necessidade de Instalação, Totalmente Grátis
Confira o vídeo acima, criado usando o Fluxo de Trabalho do Face Detailer ComfyUI. Agora, você pode experimentar o Face Detailer Workflow sem nenhuma instalação. Tudo está configurado para você em um ComfyUI baseado na nuvem, pré-carregado com o nó Impact Pack - Face Detailer e todos os modelos necessários para uma experiência perfeita. Você pode executar este Fluxo de Trabalho do Face Detailer agora ou continuar lendo este tutorial sobre como usá-lo e experimentá-lo mais tarde.
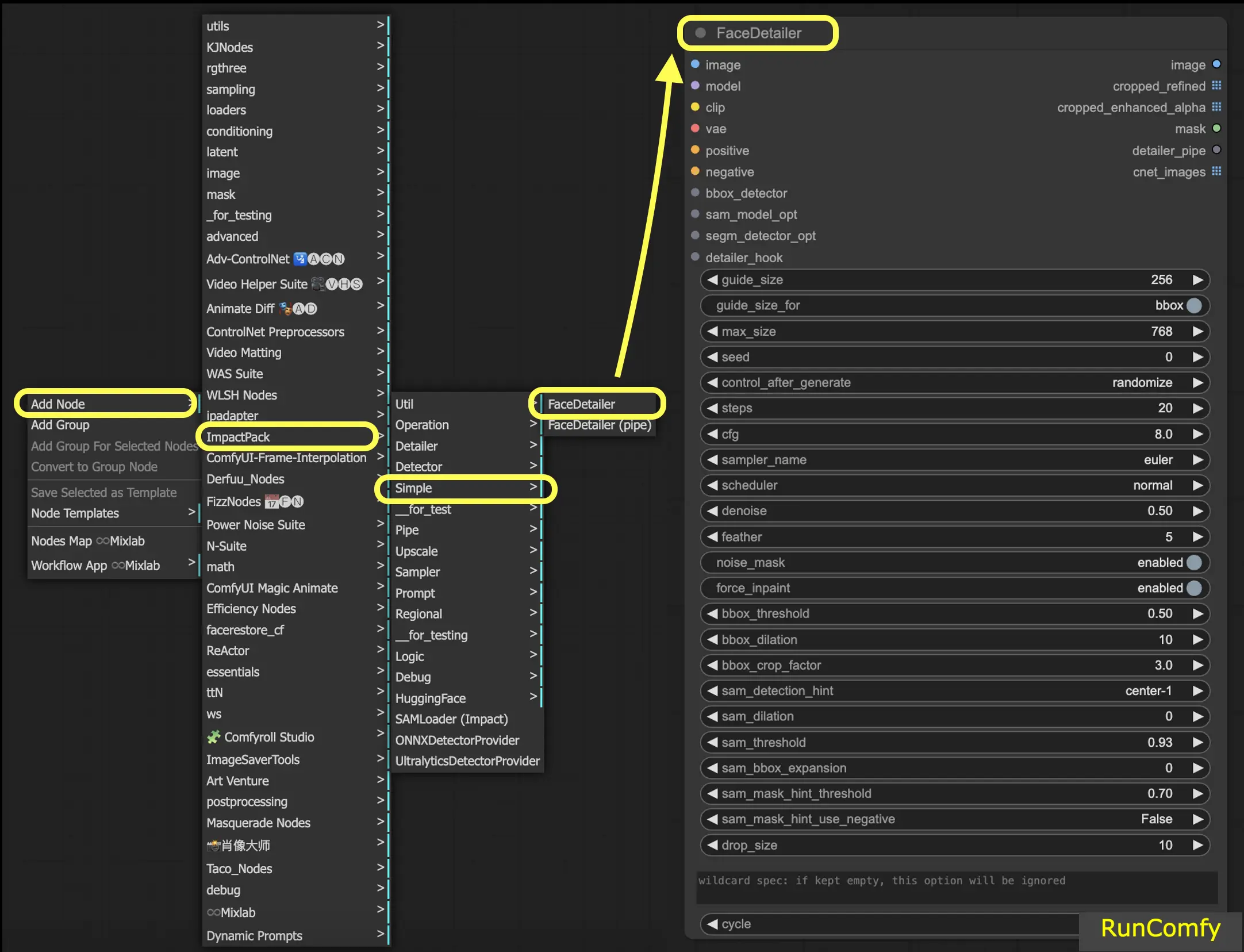
3. Adicionar o Nó Face Detailer
Vamos colocar a mão na massa com o Face Detailer ComfyUI. O nó Face Detailer pode parecer complexo à primeira vista, mas não se preocupe, vamos dividi-lo parte por parte. Ao entender cada entrada, saída e parâmetro, você estará dominando essa poderosa ferramenta rapidamente.
Para localizar o Face Detailer no ComfyUI, basta ir para Adicionar Nó → Impact Pack → Simple → Face Detailer / Face Detailer (pipe).
Vamos começar com o "Face Detailer" e depois aprofundar no "Face Detailer Pipe".
- FaceDetailer - Detecta e melhora rostos facilmente.
- FaceDetailer (pipe) - Detecta e melhora rostos facilmente (para multipasse).
Neste tutorial, estamos explorando como consertar rostos ou substituir rostos em vídeos. O vídeo é gerado usando o AnimateDiff. Se você está ansioso para aprender mais sobre o AnimateDiff, temos um tutorial dedicado ao AnimateDiff!
Se você se sentir mais confortável trabalhando com imagens, basta trocar os nós relacionados ao vídeo pelos relacionados à imagem. O Face Detailer é versátil o suficiente para lidar tanto com vídeo quanto com imagem.
4. Entrada para o Face Detailer
4.1 Insira a imagem que deseja restaurar
Vamos começar com a entrada da imagem (botão superior esquerdo no Face Detailer), o que significa alimentar uma imagem ou vídeo no Face Detailer ComfyUI. É aqui que a transformação começa! Aqui, alimentamos o Face Detailer com o vídeo gerado pelo AnimateDiff.
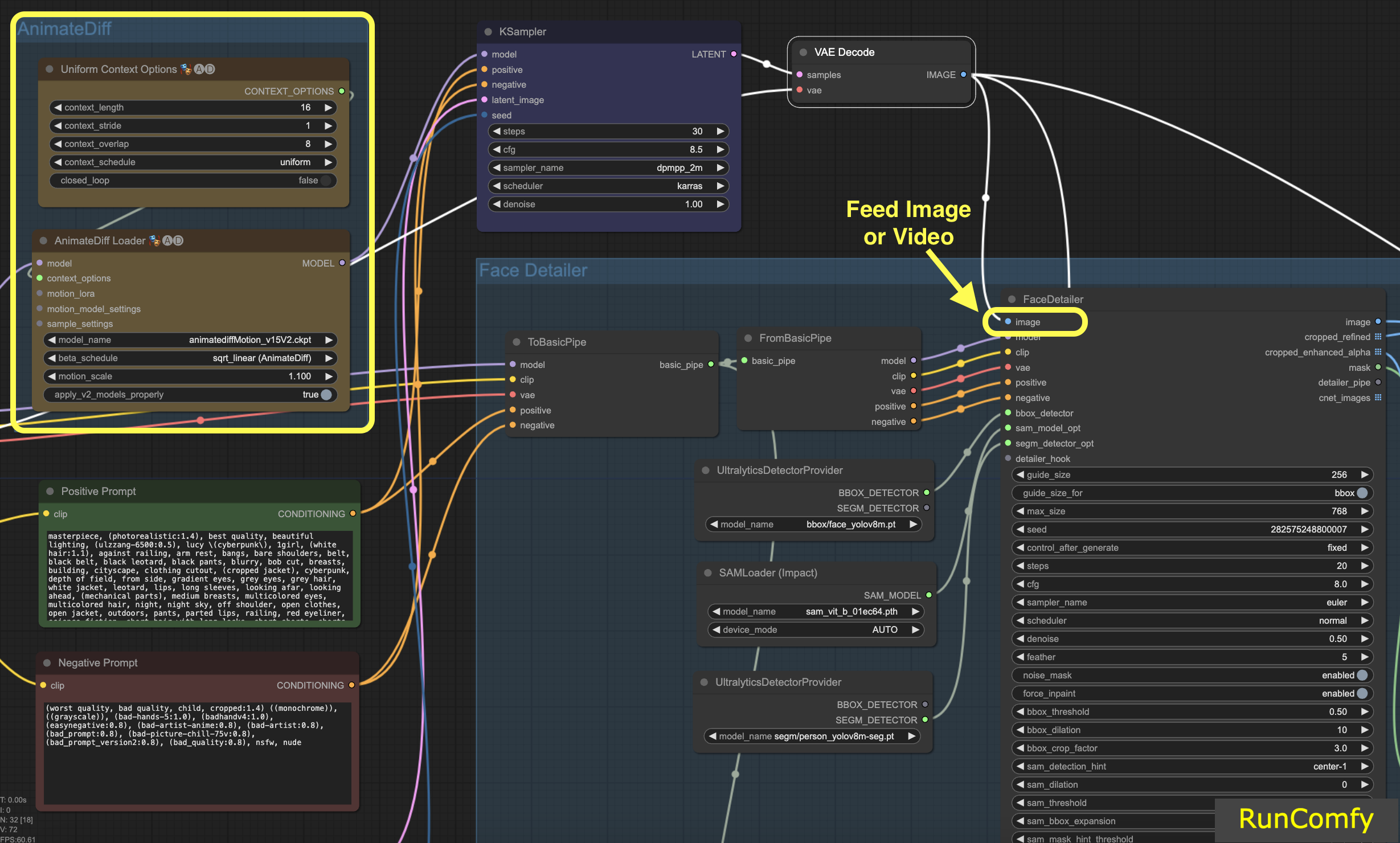
4.2 Escolha o Modelo, Clip, VAE e Insira um Prompt Positivo e um Negativo
Você provavelmente já está familiarizado com essas configurações. Vamos pular o básico e apenas observar que os prompts - positivos e negativos - desempenham um papel crucial aqui. Usaremos os mesmos prompts que geraram o vídeo. No entanto, você tem a flexibilidade de personalizar esses prompts, especialmente para o rosto que pretende substituir.
Aqui está uma informação interessante: usar os mesmos prompts da geração de imagens leva à restauração de rosto. Por outro lado, prompts diferentes significam que você está optando por uma substituição completa de rosto. É sua escolha!
Dica: Use "To Basic Pipe" e "From Basic Pipe"
Para simplificar o processo de conectar vários nós, utilize o sistema "Pipe". Comece com "To Basic Pipe", um combinador de entradas, para coletar várias entradas. Em seguida, use "From Basic Pipe" para descompactar essas entradas. Basta conectar esses dois pipes e você terá todas as entradas necessárias prontas para uma integração rápida e eficiente.
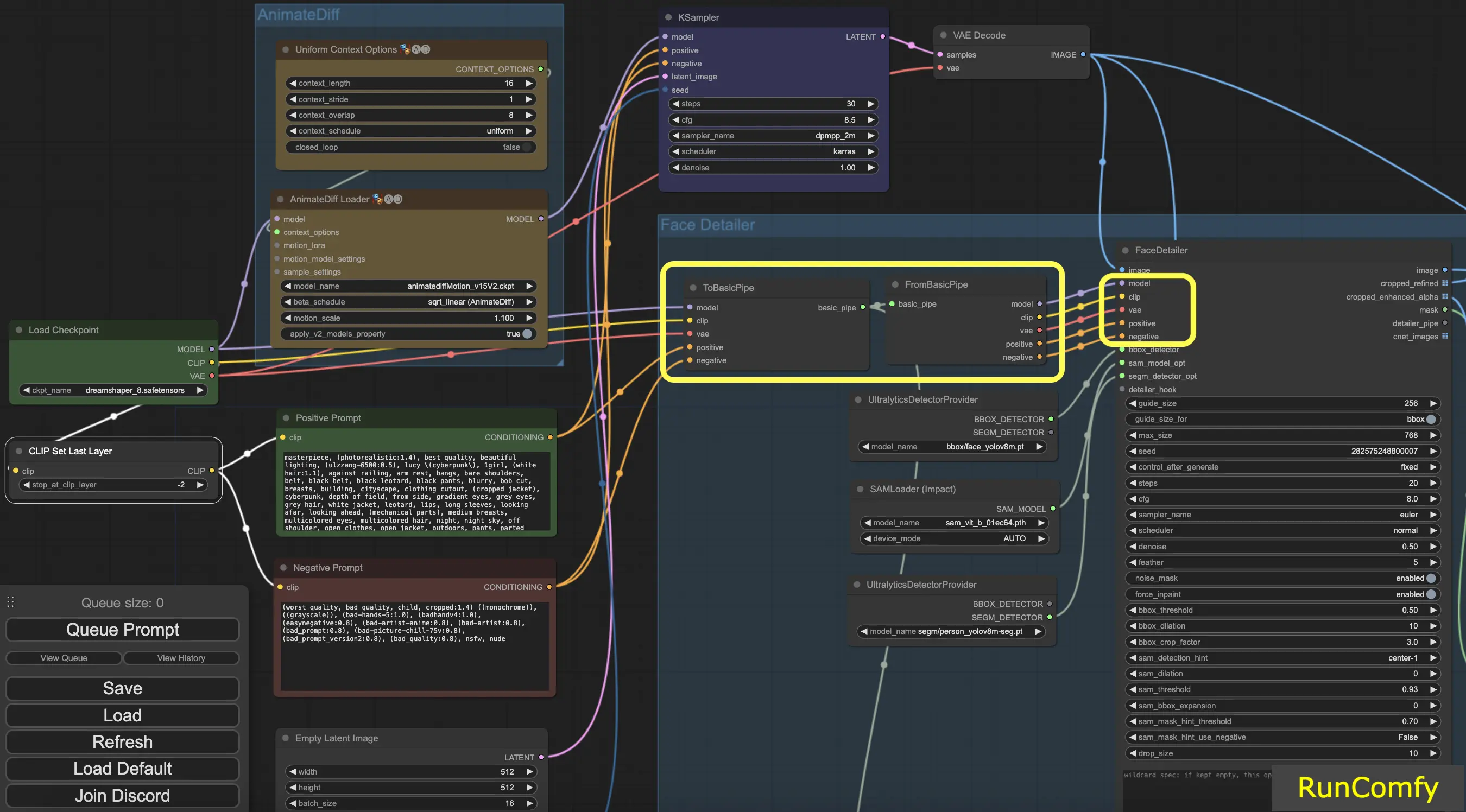
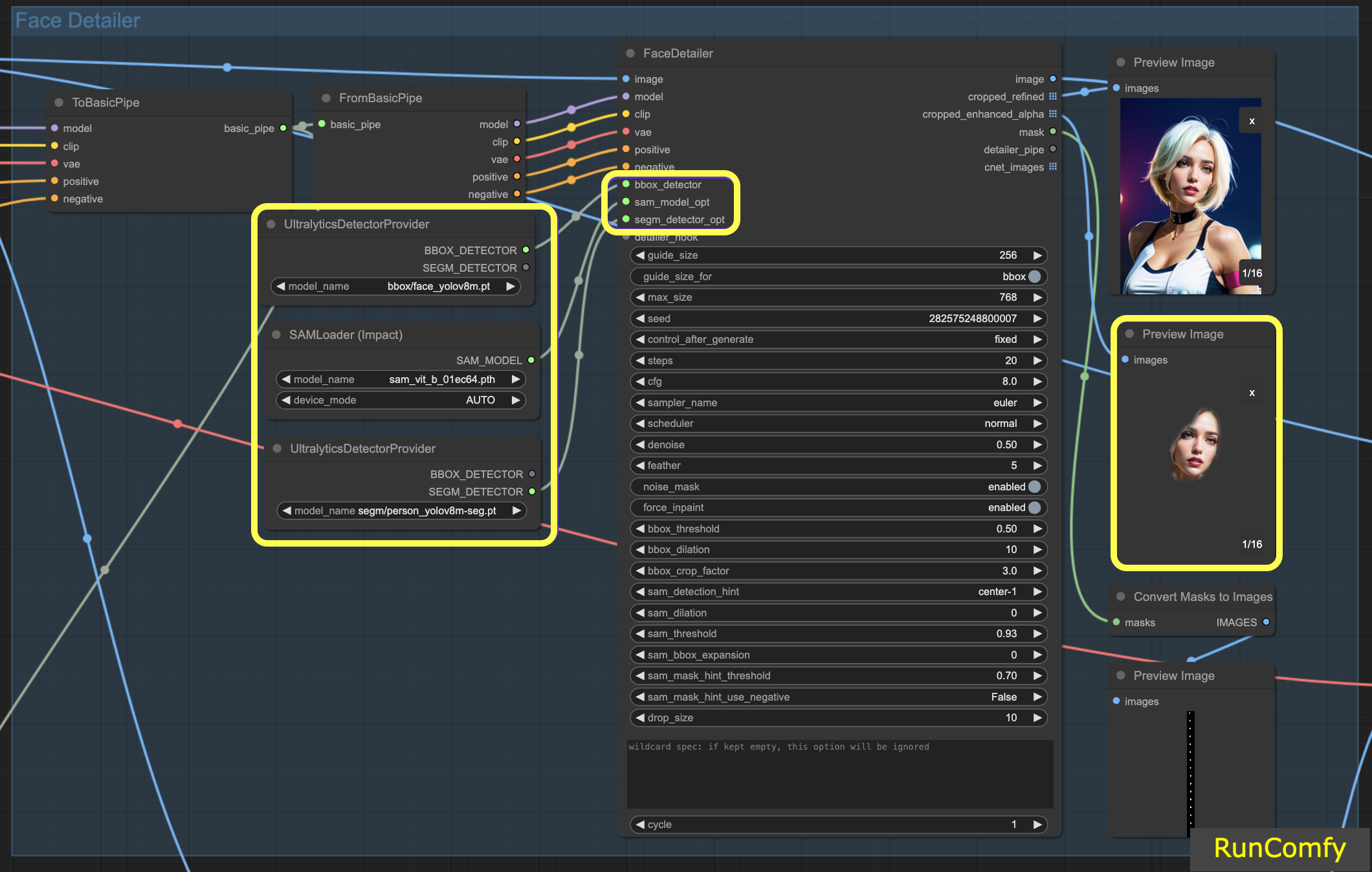
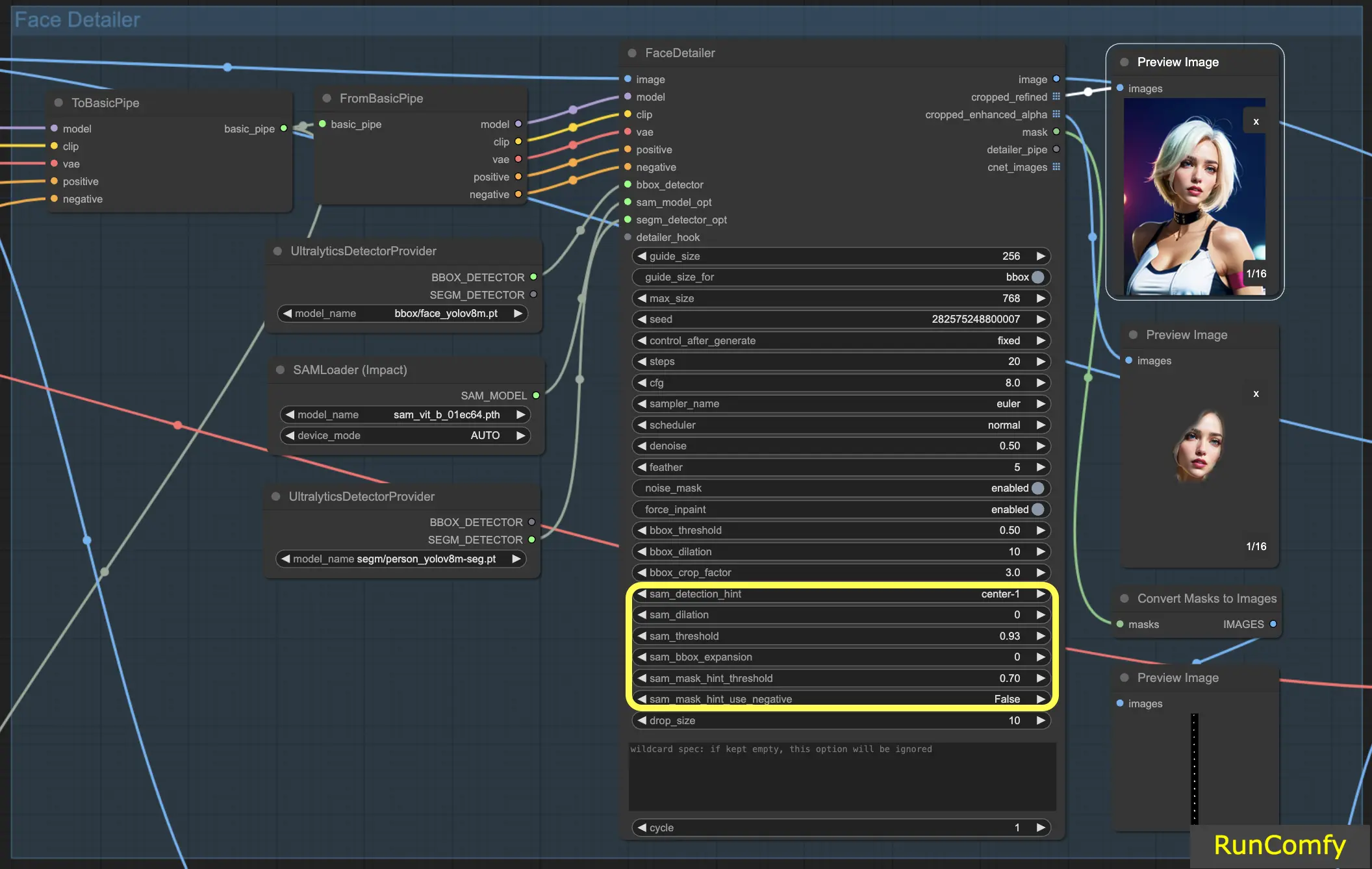
4.3 A diferença do Detector BBox e do Detector Segm (modelo Sam)
Os modelos BBox se especializam em identificar elementos usando caixas delimitadoras, enquanto os modelos Segm/person utilizam máscaras para detecção.
Em ambos os casos, seja o Detector BBox ou o Detector Segm, empregamos o nó "Ultral Litic Detector Provider". No entanto, é importante observar que, para o Detector BBox, usamos especificamente os modelos bbox/face_yolov8m e bbox/hand_yolov8s. Por outro lado, o modelo segm/person_yolov8m-seg é utilizado exclusivamente para o Detector Segm.
O que se segue diz respeito unicamente ao Detector BBox. Portanto, você observará que a Visualização da imagem recortada e aprimorada aparece como uma caixa.
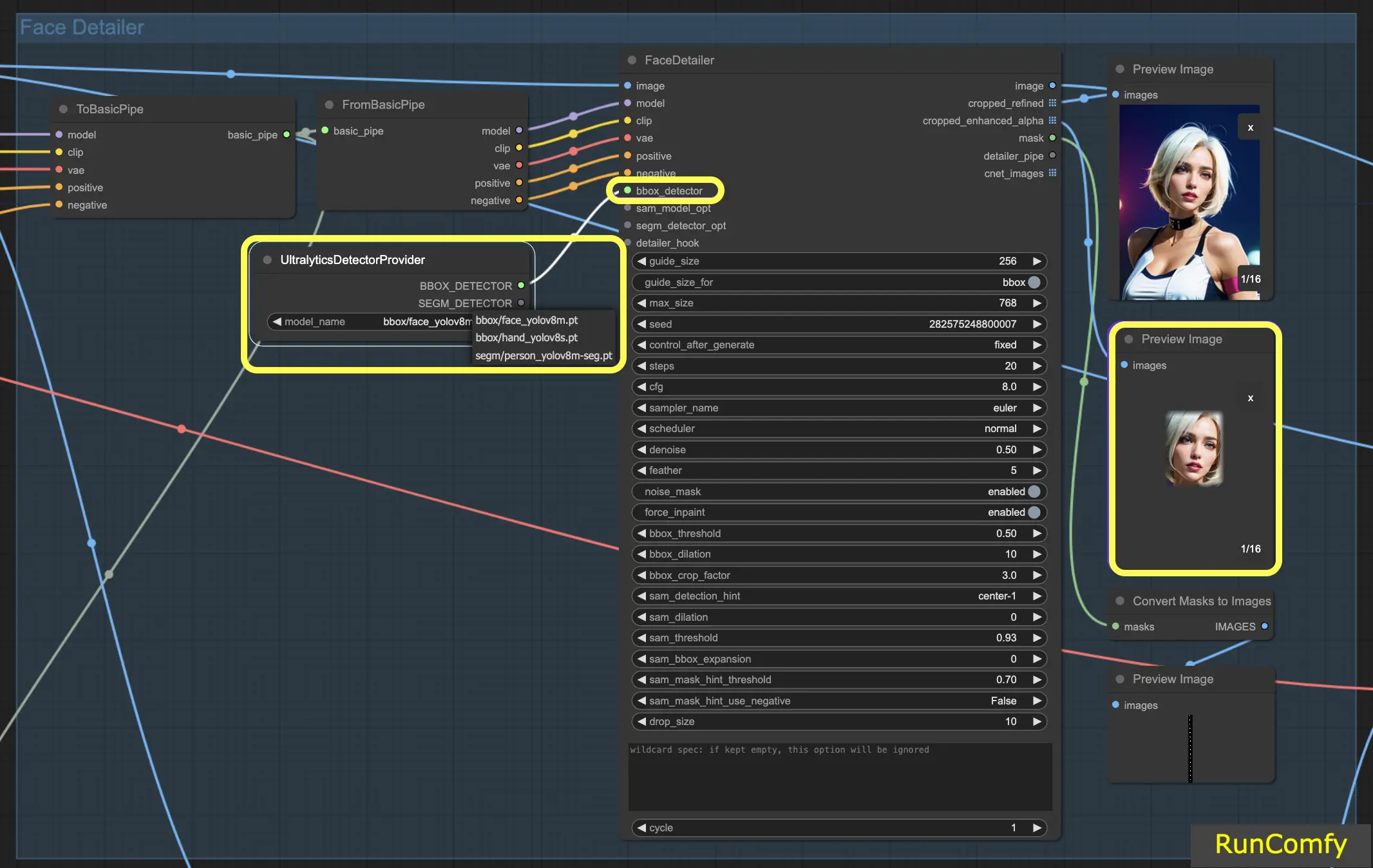
Subsequentemente, quando combinamos os recursos do Detector BBox e do Detector Segm, e integramos o modelo Sam, a Visualização da imagem recortada e aprimorada assume uma aparência semelhante a uma máscara.
5. Configurações do Face Detailer: Como Usar o Face Detailer ComfyUI
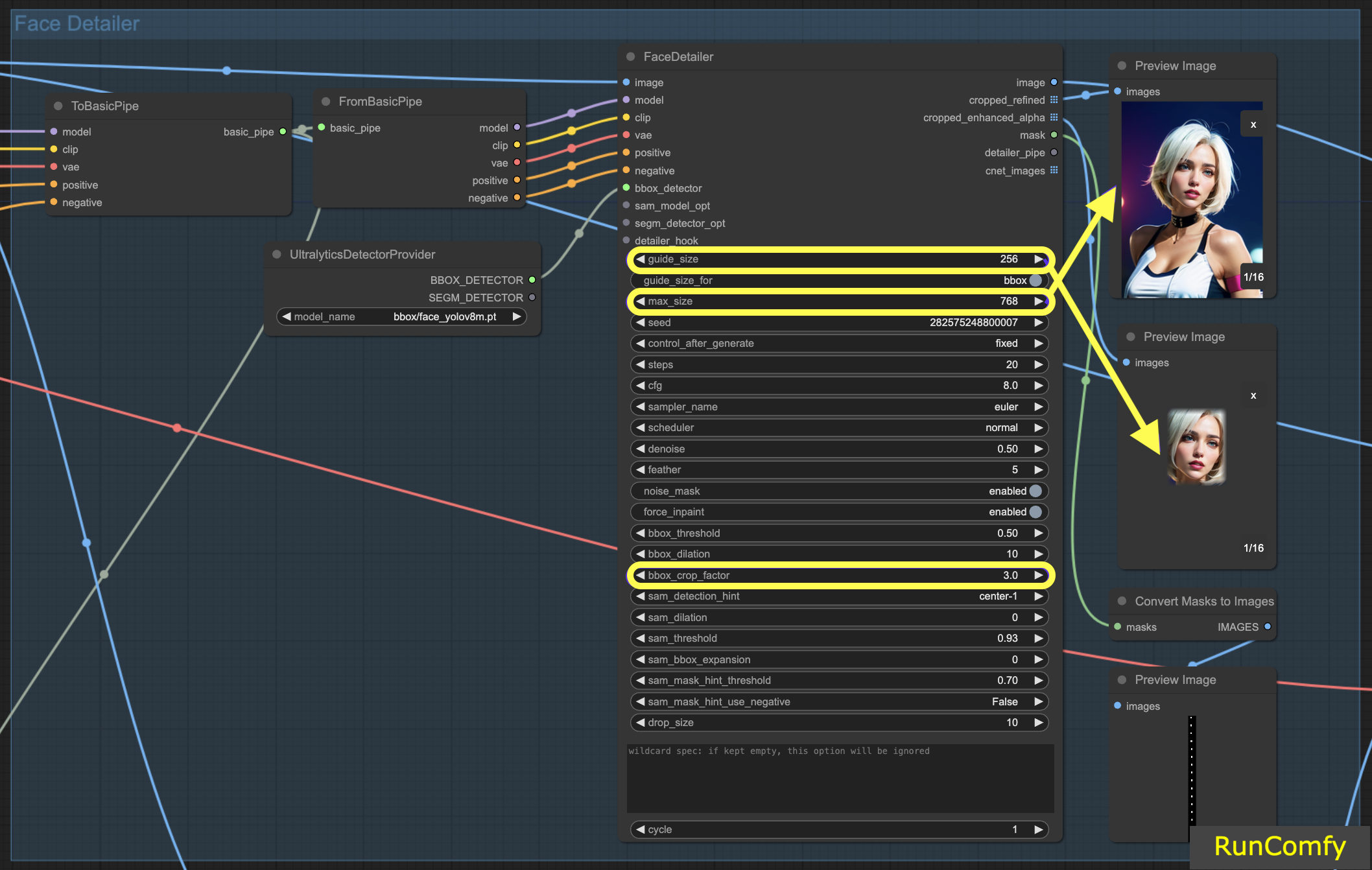
5.1 Face Detailer - Tamanho do Guia, Tamanho do Guia Para, Tamanho Máximo e Fator de Corte BBX
Tamanho do Guia: O tamanho do guia para BBX foca o detalhador de rosto da imagem na área de rosto da caixa delimitadora (conforme mostrado na visualização da imagem aprimorada recortada). Definido por padrão em 256, isso significa que se a área de rosto da caixa delimitadora for menor que 256 pixels, o sistema automaticamente a aumenta para um mínimo de 256 pixels.
Tamanho Máximo: O tamanho máximo estabelece o limite superior para o quão grande a área recortada pode ser (conforme mostrado na visualização da imagem refinada recortada). Esse limite é para evitar que a área se torne muito grande, o que poderia levar a outros problemas. O tamanho máximo padrão é de 768 pixels.
Mantendo um Intervalo Ideal: Ao definir esses parâmetros, mantemos o tamanho da imagem dentro de um intervalo de 256 a 768 pixels, ideal para o Checkpoint SD 1.5. No entanto, se você alternar para o modelo Checkpoint SDXL, conhecido por um melhor desempenho com imagens maiores, ajustar o tamanho do guia para 512 e o tamanho máximo para 1024 pode ser vantajoso. Esse ajuste vale a pena ser experimentado.
Tamanho do Guia para: Abaixo do tamanho do guia, há uma opção rotulada "tamanho do guia para bbox". Isso permite que você mude o foco para a região de corte, que é uma área maior do que a área de rosto da caixa delimitadora.
Fator de Corte BBX: O fator de corte BBX está atualmente definido em 3. Reduzir o fator de corte para 1.0 significa uma área de corte menor, igual à área do rosto. Quando definido em 3, indica que a área de corte é 3 vezes maior do que a área do rosto.
A essência do ajuste do fator de corte está em encontrar um equilíbrio entre fornecer foco adequado para o detalhador de rosto e permitir espaço suficiente para a mesclagem contextual. Defini-lo em 3 significa que a área de corte inclui um pouco mais do contexto ao redor, o que geralmente é benéfico. No entanto, você também deve levar em consideração o tamanho do rosto na imagem ao decidir sobre a configuração apropriada.
5.2 Face Detailer - Suavização
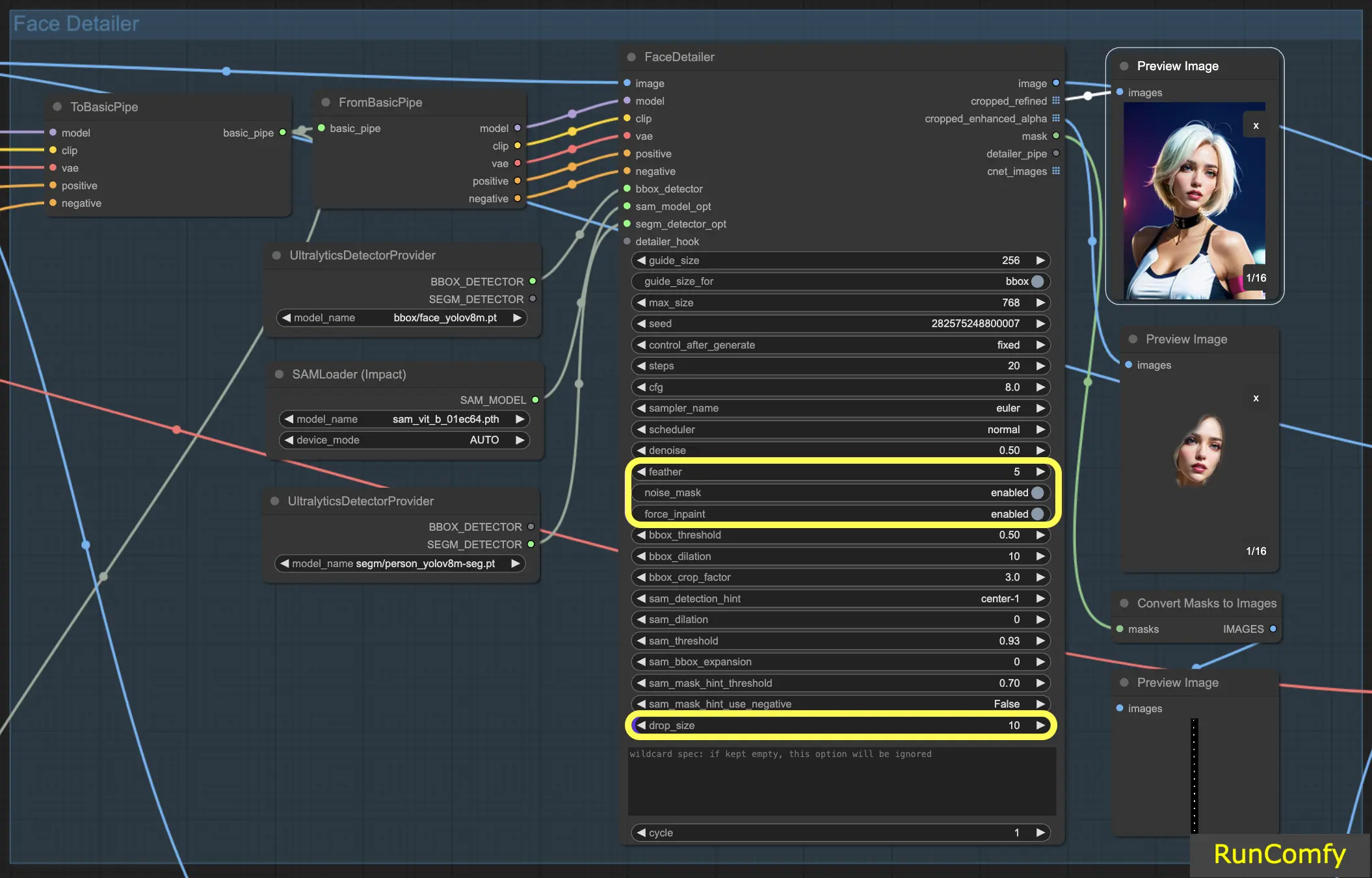
A configuração Suavização determina até que ponto as bordas da imagem ou as áreas preenchidas se mesclam perfeitamente com o restante da imagem. Normalmente, defino-a em cinco, o que funciona bem na maioria dos casos. No entanto, se você notar que o preenchimento em suas imagens tem bordas particularmente marcantes, pode considerar aumentar esse valor. Como não observamos bordas marcantes neste exemplo, não há necessidade imediata de ajustá-la.
5.3 Face Detailer - Máscara de Ruído
Ativar a Máscara de Ruído efetivamente direciona o modelo para focar suas operações de ruído e redução de ruído exclusivamente na área mascarada. Isso transforma a caixa delimitadora em uma máscara, que indica precisamente as áreas onde o ruído é aplicado e posteriormente refinado. Essa funcionalidade é especialmente importante ao trabalhar com detectores Segm e modelos Sam.
5.4 Face Detailer - Forçar Preenchimento
Forçar Preenchimento funciona como uma ferramenta especializada para aprimorar áreas específicas de uma imagem com detalhes adicionais. Muitas vezes, nos concentramos nos rostos nas imagens. Há momentos em que o sistema automático pode não adicionar detalhes suficientes a esses rostos, supondo erroneamente que eles já estão adequadamente detalhados. Esse é o cenário perfeito para utilizar o Forçar Preenchimento.
Em essência, Forçar Preenchimento é ideal para aumentar os detalhes em certas áreas da sua imagem, particularmente quando as configurações automáticas ficam aquém.
5.5 Face Detailer - Tamanho de Queda
Particularmente útil em cenários de substituição de vários rostos, a configuração de tamanho de queda instrui o modelo a ignorar máscaras menores que um tamanho especificado, como 10 pixels. Esse recurso é inestimável em cenas lotadas onde o foco está em rostos maiores.
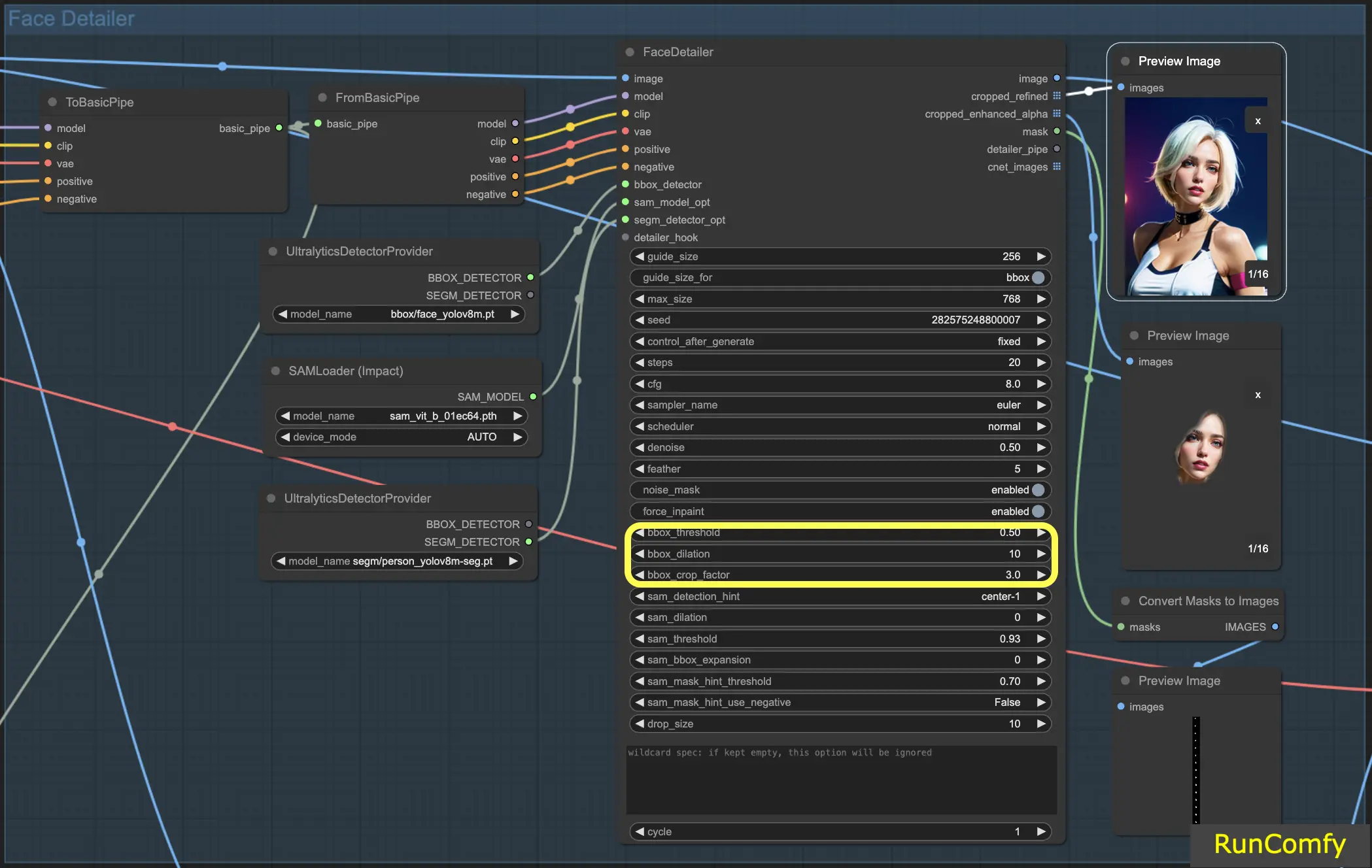
5.6 Face Detailer - Recursos Relacionados ao BBox
Limite BBox: O limite bbox é fundamental para ajustar o modelo de detecção de rosto. Optar por um número mais baixo significa um processo de detecção mais indulgente. O modelo avalia a imagem, atribuindo porcentagens de confiança a possíveis rostos. Alterar o limite modifica o nível de confiança necessário para o modelo reconhecer e substituir um rosto.
Considere uma imagem com máscaras no fundo e uma pessoa em primeiro plano. O modelo pode confundir as máscaras com rostos. Nesses casos, você pode aumentar o limite para garantir que ele reconheça e se concentre no rosto claramente definido, em vez das máscaras. Por outro lado, para substituir vários rostos em uma multidão, onde os rostos são menos distintos, diminuir o limite bbox pode ajudar a identificar esses rostos menos óbvios.
Dilatação BBox: A configuração de dilatação bbox permite expansão além da área de corte inicial, normalmente limitada ao rosto. Quando você aumenta a dilatação, mais áreas ao redor do rosto são incluídas no processo de substituição. No entanto, essas alterações são frequentemente sutis e podem exigir ajustes no fator de corte para resultados mais perceptíveis.
Fator de Corte BBX: Já mencionado em 4.1
5.7 Face Detailer - Recursos Relacionados ao Segm/Sam
Segm/Sam refina a caixa delimitadora convencional em uma máscara mais precisa, aprimorando a precisão da substituição do rosto. Essa precisão é particularmente útil em cenários em que a caixa delimitadora se sobrepõe ao cabelo e você prefere não alterar o cabelo. Ao usar o modelo Sam, você pode concentrar a substituição apenas no rosto.
Dica de Detecção Sam: A dica de detecção Sam é uma configuração crítica. Ela orienta o modelo sobre onde focar ao identificar rostos. Você tem várias opções, incluindo Centro, Horizontal (um ou dois rostos), Vertical (dois rostos) e arranjos para quatro rostos em formações retangulares ou de diamante.
Dilatação Sam: Semelhante à dilatação da caixa delimitadora, a configuração de dilatação Sam ajusta a área fora da máscara ou ponto focal que o modelo irá substituir. Aumentar essa dilatação re-expande a área da máscara de volta para uma forma de caixa.
Limite Sam: Definido em um alto 93%, o limite Sam funciona como sua contraparte da caixa delimitadora, mas exige um nível de confiança mais alto devido à precisão do modelo.
Expansão da Caixa Sam: Essa configuração ajusta a caixa delimitadora inicial, definindo ainda mais a área facial. Aumentar a expansão da caixa é benéfico quando a caixa delimitadora inicial é muito restritiva, permitindo que o modelo capture mais do rosto.
Limite de Dica de Máscara Sam: Trabalhando em conjunto com a dica de detecção Sam, essa configuração determina a agressividade do modelo em responder à dica. A configuração padrão é 0.7.
Com essas informações, você deve ter um entendimento muito mais profundo de como o detalhador de rosto funciona.
6. Outras Melhorias
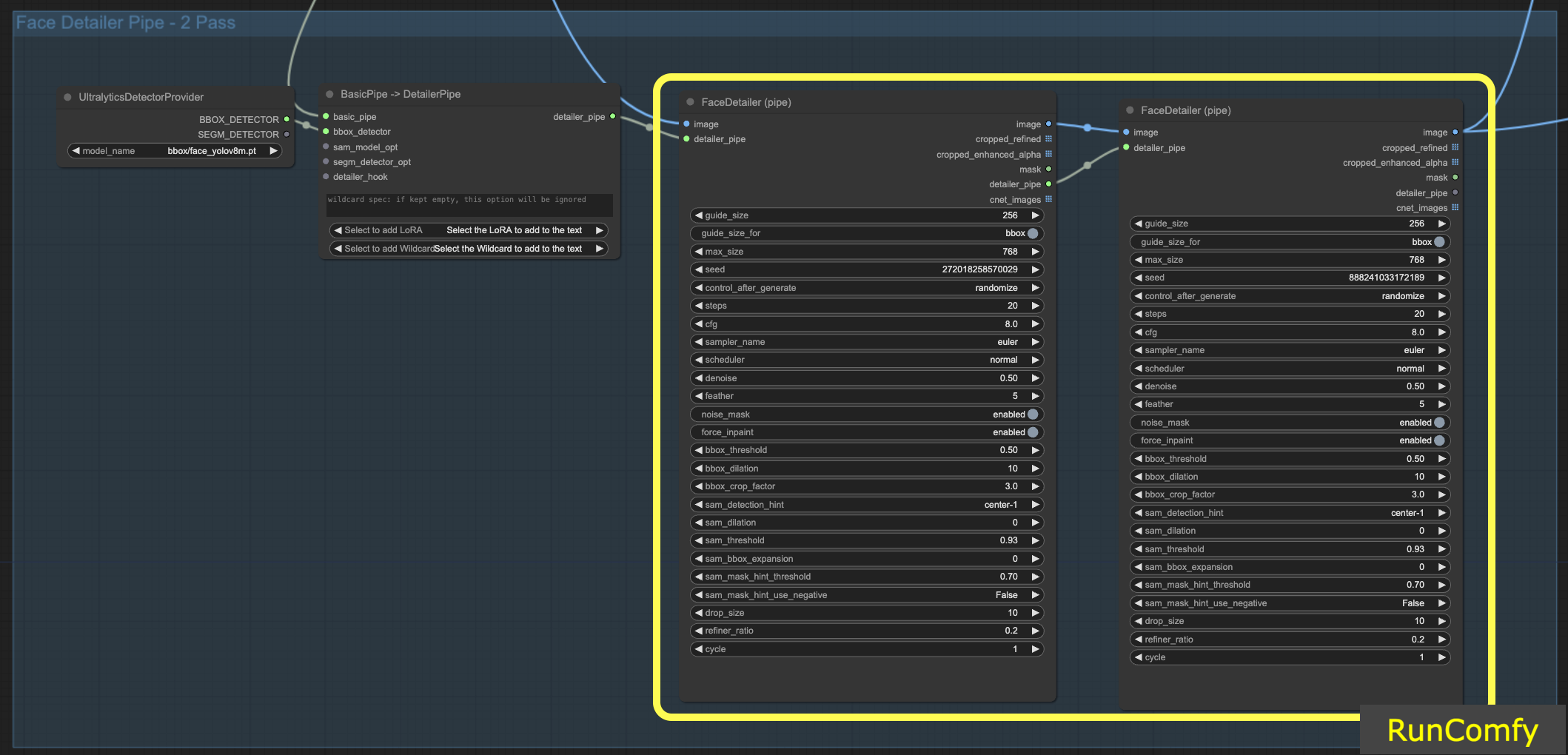
6.1 Refinamento de Dois Passes com Face Detailer(Pipe)
Integrar dois FaceDetailers para uma configuração de dois passes é viável; basta transferir o Face Detailer para o FaceDetailerPipe.
Em uma configuração de passe único (1pass), o foco está principalmente em restaurar um contorno básico. Isso requer o uso de uma resolução moderada com opções mínimas. No entanto, expandir a dilatação aqui pode ser vantajoso, pois não apenas cobre as características faciais, mas também se estende para as áreas ao redor. Essa técnica é particularmente benéfica quando a remodelagem se estende além da parte facial. Você pode experimentar conforme necessário.
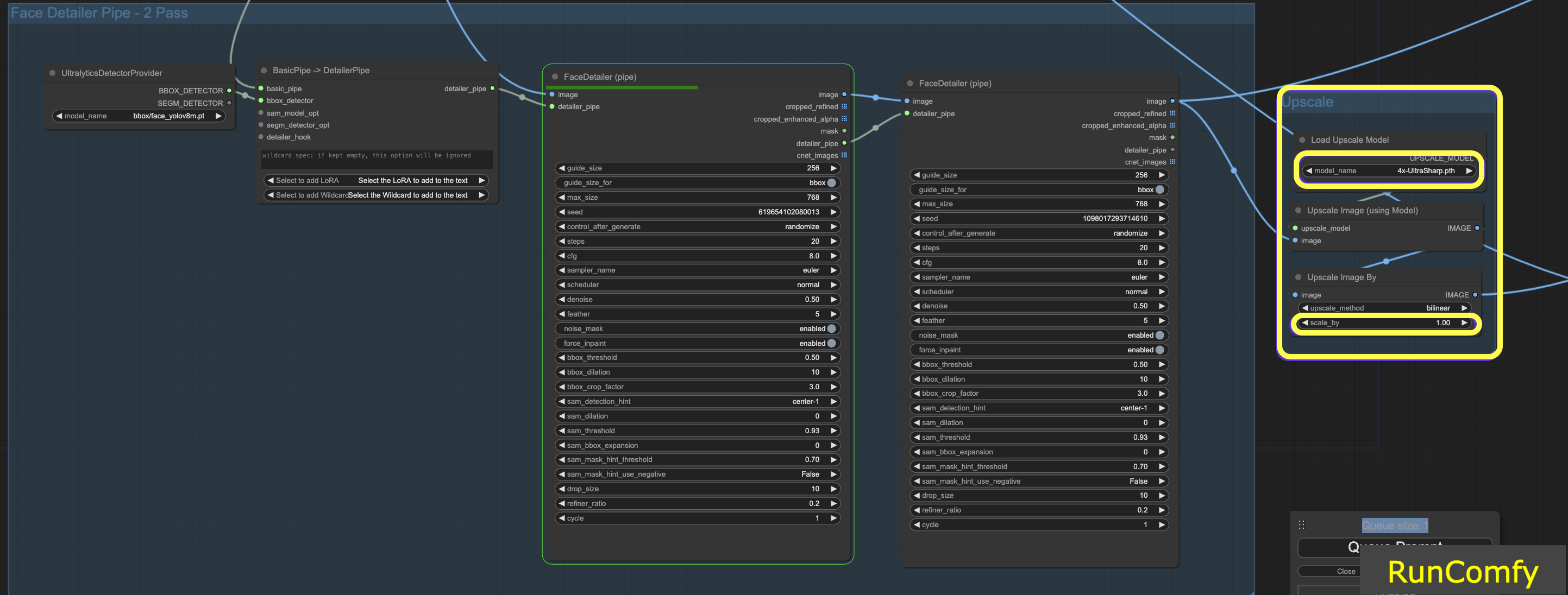
6.2 Aumentar a Resolução do Vídeo usando 4x-UltraSharp
Para obter resultados ainda melhores, podemos usar o nó ultra sharp para aumento de resolução. Ao redimensionar a imagem e selecionar o upscaler apropriado, você pode aprimorar significativamente a qualidade da imagem.
7. Execute o Fluxo de Trabalho do Face Detailer ComfyUI Gratuitamente
Aqui vamos nós! Com o Fluxo de Trabalho do Face Detailer ComfyUI, você agora pode corrigir rostos em qualquer vídeo e animação!
Ansioso para experimentar o Fluxo de Trabalho do Face Detailer ComfyUI que discutimos? Definitivamente considere usar o RunComfy, um ambiente em nuvem equipado com uma GPU poderosa. Ele está totalmente preparado e inclui tudo relacionado ao ComfyUI Impact Pack - Face Detailer, desde modelos até nós personalizados. Nenhuma configuração manual é necessária! É seu playground para liberar essa centelha criativa.
Autor: Editores RunComfy
Nossa equipe de editores trabalha com IA há mais de 15 anos, começando com PLN/Visão na era de RNN/CNN. Acumulamos uma tremenda quantidade de experiências em Arte/Animação/Chatbot de IA, como BERT/GAN/Transformer, etc. Fale conosco se precisar de ajuda com arte, animação e vídeo de IA.