IPAdapter V1 FaceID Plus | Последовательные персонажи
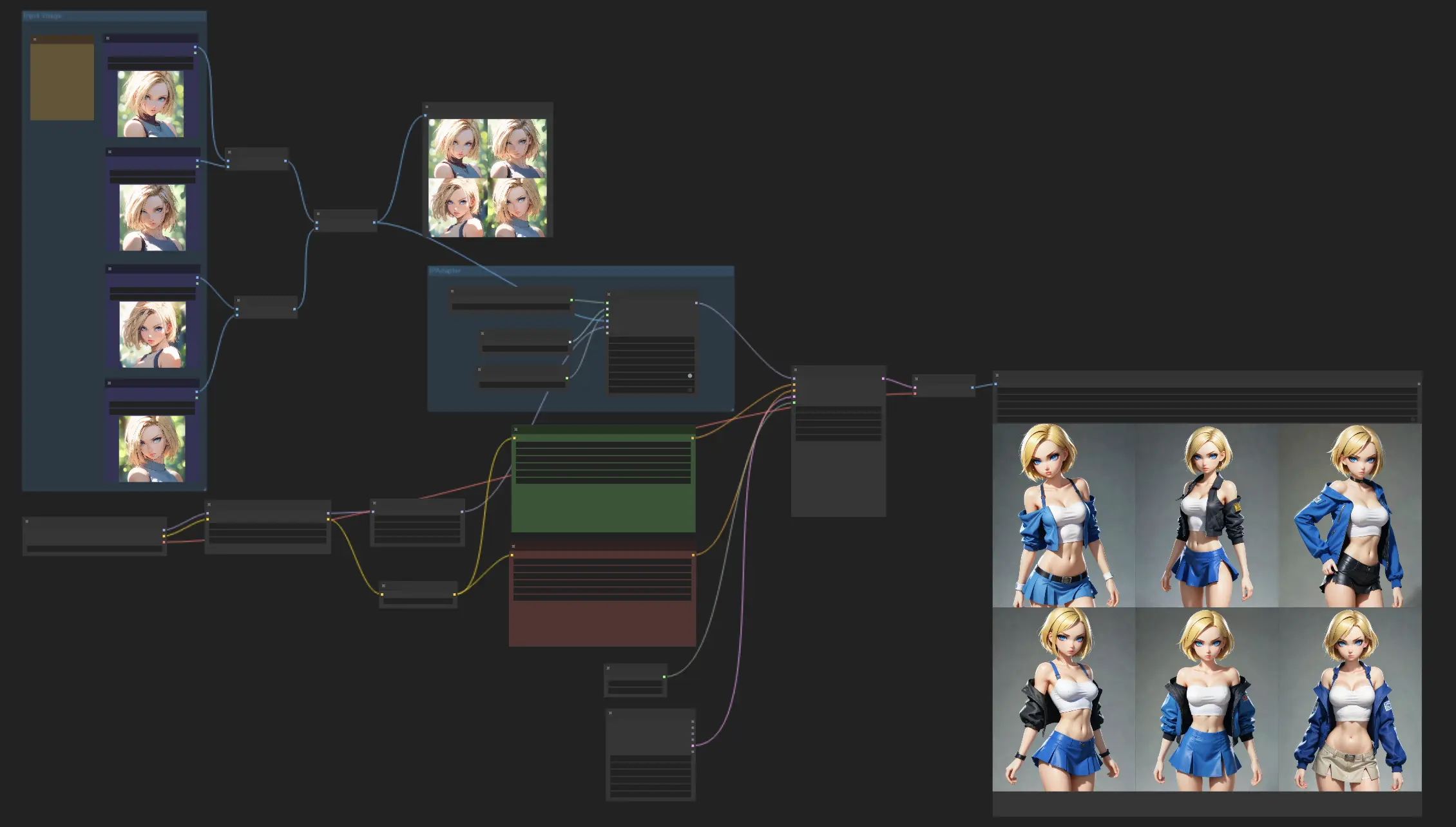
Раскройте полный потенциал ваших дизайнов персонажей с моделью IPAdapter Face Plus V2. Этот рабочий процесс позволяет создателям поддерживать последовательные черты персонажей в различных стилях. Не стесняйтесь использовать разные контрольные точки или модели LoRA для изучения различных стилей.ComfyUI Consistent Characters Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI Consistent Characters Примеры

ComfyUI Consistent Characters Описание
1. Последовательный рабочий процесс создания персонажей
Этот рабочий процесс посвящен созданию персонажей с последовательным внешним видом, используя модель IPAdapter Face Plus V2. Просто начните с загрузки некоторых референсных изображений, а затем позвольте модели Face Plus V2 творить чудеса, создавая серию изображений с одинаковыми чертами лица. Не стесняйтесь экспериментировать с различными контрольными точками или моделями LoRA, чтобы исследовать различные стили, сохраняя при этом внешний вид вашего персонажа последовательным.
2. Обзор IPAdapter FaceID/FaceID Plus
v1.5 FaceID
Эта модель является базовой версией для распознавания лиц, позволяя вариации, дополненные текстовыми подсказками, сетями управления и масками. Она известна своей средней силой кондиционирования, что делает её подходящей для общих задач кондиционирования лица. Базовая модель FaceID не использует CLIP vision encoder, что означает более простую настройку без необходимости в сложных конфигурациях кодировщика.
v1.5 FaceID Plus
Модель FaceID Plus является более мощным вариантом, разработанным для более сильных эффектов кондиционирования изображения. Она требует использования ViT-H image encoder, что указывает на необходимость более высоких вычислительных мощностей для детального моделирования лица.
v1.5 FaceID Plus v2
Итерация модели FaceID Plus, эта модель вводит улучшения для ещё более детального кондиционирования лица. Как и FaceID Plus, она использует ViT-H image encoder. Эта модель направлена на обеспечение повышенного качества моделирования лица, удовлетворяя более тонкие требования.
v1.5 FaceID Portrait
Разработана специально для портретов, эта модель не использует CLIP vision encoder. Она сосредоточена на создании высококачественных изображений лиц в портретных настройках, что потенциально предлагает специализированный подход к генерации портретных изображений.
SDXL FaceID
Вариант FaceID SDXL предназначен для использования с архитектурой SDXL, не используя CLIP vision encoder. Он представляет собой базовую модель в наборе SDXL, разработанную для масштабируемых архитектур глубокого обучения, ориентированных на задачи распознавания лиц.
SDXL FaceID Plus v2
Это более мощная версия модели FaceID для архитектуры SDXL, использующая ViT-H image encoder. Она разработана для обеспечения улучшенных эффектов кондиционирования лица в рамках SDXL, ориентирована на задачи генерации высококачественных изображений.
3. Как использовать IPAdapter FaceID/FaceID Plus
3.1. Выбор модели FaceID/FaceID Plus
Выберите предпочитаемую модель FaceID или FaceID Plus, чтобы начать создание ваших изображений. В настройках вы найдёте опции для регулировки как весов, так и шума. Эти настройки являются ключевыми для точной настройки внешнего вида ваших сгенерированных изображений, позволяя вам достичь желаемого результата.
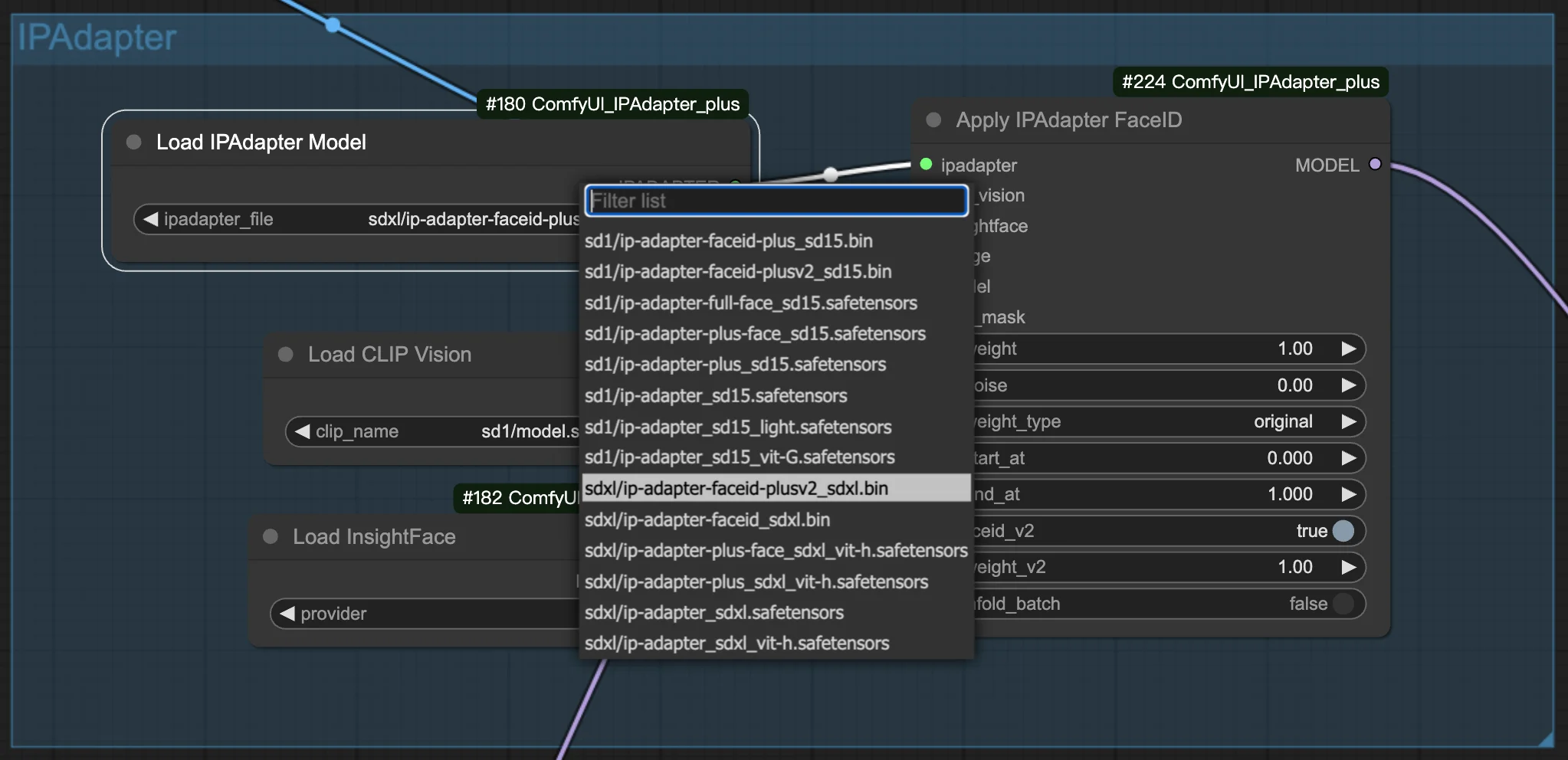
3.2. Подготовка референсного изображения
При использовании узлов IPAdapter FaceID, модель CLIP vision обрабатывает ваше референсное изображение, изменяя его размер и центрируя до размеров 224x224 пикселей. Эта автоматическая корректировка фокусируется на центре изображения, поэтому важно, чтобы основной объект вашего изображения, например, лицо персонажа, был расположен по центру. Если объект смещён от центра, особенно в портретных или ландшафтных изображениях, результаты могут не соответствовать вашим ожиданиям. Для достижения наилучших результатов настоятельно рекомендуется использовать квадратные изображения с централизованным объектом.







