Stable Diffusion 3.5
Stable Diffusion 3.5 (SD3.5) — это новая модель с открытым исходным кодом, которая генерирует разнообразные, высококачественные изображения из текстовых подсказок. SD3.5 отлично справляется с созданием различных стилей и соблюдением подсказок. Несмотря на некоторые ограничения в анатомии и разрешении, SD3.5 является мощным инструментом для визуального творчества. Исследуйте SD3.5 в ComfyUI, чтобы легко создавать потрясающие визуализации.ComfyUI Stable Diffusion 3.5 Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI Stable Diffusion 3.5 Примеры




ComfyUI Stable Diffusion 3.5 Описание
Stability AI представила , многомодальную генеративную модель с открытым исходным кодом, включающую несколько вариантов, таких как Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo и Stable Diffusion 3.5 (SD3.5) Medium. Эти модели высоко настраиваемы и могут работать на потребительском оборудовании. Модели SD3.5 Large и Large Turbo доступны сразу, а версия Medium будет выпущена 29 октября 2024 года.
1. Как работает Stable Diffusion 3.5 (SD3.5)
На техническом уровне Stable Diffusion 3.5 (SD3.5) принимает текстовую подсказку в качестве входных данных, кодирует её в латентное пространство с использованием текстовых кодировщиков на основе трансформеров, а затем декодирует это латентное представление в выходное изображение с помощью декодера на основе диффузии. Текстовые кодировщики трансформеров, такие как модель CLIP (Contrastive Language-Image Pre-training), отображают входную подсказку в семантически значимое сжатое представление в латентном пространстве. Этот латентный код затем итеративно очищается декодером диффузии на протяжении нескольких шагов для генерации окончательного изображения. Процесс диффузии включает постепенное удаление шума из изначально шумного латентного представления, обусловленного текстовым встраиванием, до тех пор, пока не появится чистое изображение.
Различные размеры моделей в Stable Diffusion 3.5 (SD3.5) (Large, Medium) относятся к количеству обучаемых параметров — 8 миллиардов для модели Large и 2,5 миллиарда для Medium. Большее количество параметров обычно позволяет модели захватывать больше знаний и нюансов из обучающих данных. Turbo модели являются дистиллированными версиями, которые жертвуют некоторым качеством ради гораздо более высокой скорости вывода. Дистилляция включает обучение меньшей "студенческой" модели для имитации выходных данных большей "учительской" модели, стремясь сохранить большую часть возможностей в более эффективной архитектуре.
2. Преимущества моделей Stable Diffusion 3.5 (SD3.5)
2.1. Настраиваемость
Модели Stable Diffusion 3.5 (SD3.5) разработаны для легкой настройки и доработки для конкретных приложений. В блоки трансформеров была интегрирована нормализация Query-Key, чтобы стабилизировать обучение и упростить дальнейшую разработку. Эта техника нормализует оценки внимания в слоях трансформера, что может сделать модель более устойчивой и проще адаптировать к новым наборам данных через переносное обучение.
2.2. Разнообразие выходных данных
Stable Diffusion 3.5 (SD3.5) стремится генерировать изображения, представляющие мировое разнообразие без необходимости в обширных подсказках. Он может изображать людей с различными оттенками кожи, особенностями и эстетикой. Это, вероятно, обусловлено тем, что модель обучена на большом и разнообразном наборе изображений из интернета.
2.3. Широкий диапазон стилей
Модели Stable Diffusion 3.5 (SD3.5) способны генерировать изображения в широком разнообразии стилей, включая 3D-рендеры, фотореализм, картины, линейное искусство, аниме и другие. Эта универсальность делает их подходящими для многих случаев использования. Разнообразие стилей возникает благодаря способности модели диффузии захватывать множество различных визуальных паттернов и эстетик в своем латентном пространстве.
2.4. Сильное соответствие подсказкам
Особенно для модели Stable Diffusion 3.5 (SD3.5) Large, SD3.5 хорошо справляется с генерацией изображений, которые соответствуют семантическому значению входных текстовых подсказок. Она занимает высокие позиции по сравнению с другими моделями по метрикам соответствия подсказкам. Эта способность точно переводить текст в изображения обеспечивается возможностями понимания языка текстовым кодировщиком трансформеров.
3. Ограничения и недостатки моделей Stable Diffusion 3.5 (SD3.5)
3.1. Трудности с анатомией и взаимодействием объектов
Как и большинство моделей "текст-изображение", Stable Diffusion 3.5 (SD3.5) все еще испытывает трудности с рендерингом реалистичной человеческой анатомии, особенно рук, ног и лиц в сложных позах. Взаимодействия между объектами и руками часто искажены. Это, вероятно, связано с трудностью изучения всех нюансов 3D-пространственных отношений и физики только из 2D-изображений.
3.2. Ограниченное разрешение
Модель Stable Diffusion 3.5 (SD3.5) Large идеальна для изображений размером 1 мегапиксель (1024x1024), в то время как Medium достигает 2 мегапикселей. Генерация согласованных изображений с более высоким разрешением является сложной задачей для SD3.5. Это ограничение связано с вычислительными и памятьными ограничениями архитектуры диффузии.
3.3. Периодические сбои и галлюцинации
Из-за того, что модели Stable Diffusion 3.5 (SD3.5) позволяют широкое разнообразие выходных данных из одной и той же подсказки с различными случайными семенами, может возникнуть некоторая непредсказуемость. Подсказки, лишенные специфичности, могут привести к появлению глюков или неожиданных элементов. Это является свойством процесса выборки диффузии, который включает случайность.
3.4. Не дотягивает до абсолютной передовой
Согласно некоторым ранним тестам, в плане качества изображения и согласованности, Stable Diffusion 3.5 (SD3.5) в настоящее время не соответствует производительности самых современных моделей "текст-изображение", таких как Midjourney. И ранние сравнения между Stable Diffusion 3.5 (SD3.5) и FLUX.1 показывают, что каждая модель превосходит в разных областях. В то время как FLUX.1, кажется, имеет преимущество в создании фотореалистичных изображений, SD3.5 Large обладает большей способностью генерировать аниме-стиль без необходимости в дополнительной настройке или модификациях.
4. Stable Diffusion 3.5 в ComfyUI
В RunComfy мы упростили вам начало использования моделей Stable Diffusion 3.5 (SD3.5), предварительно загрузив их для вашего удобства. Вы можете сразу приступить к запуску выводов, используя примерный рабочий процесс
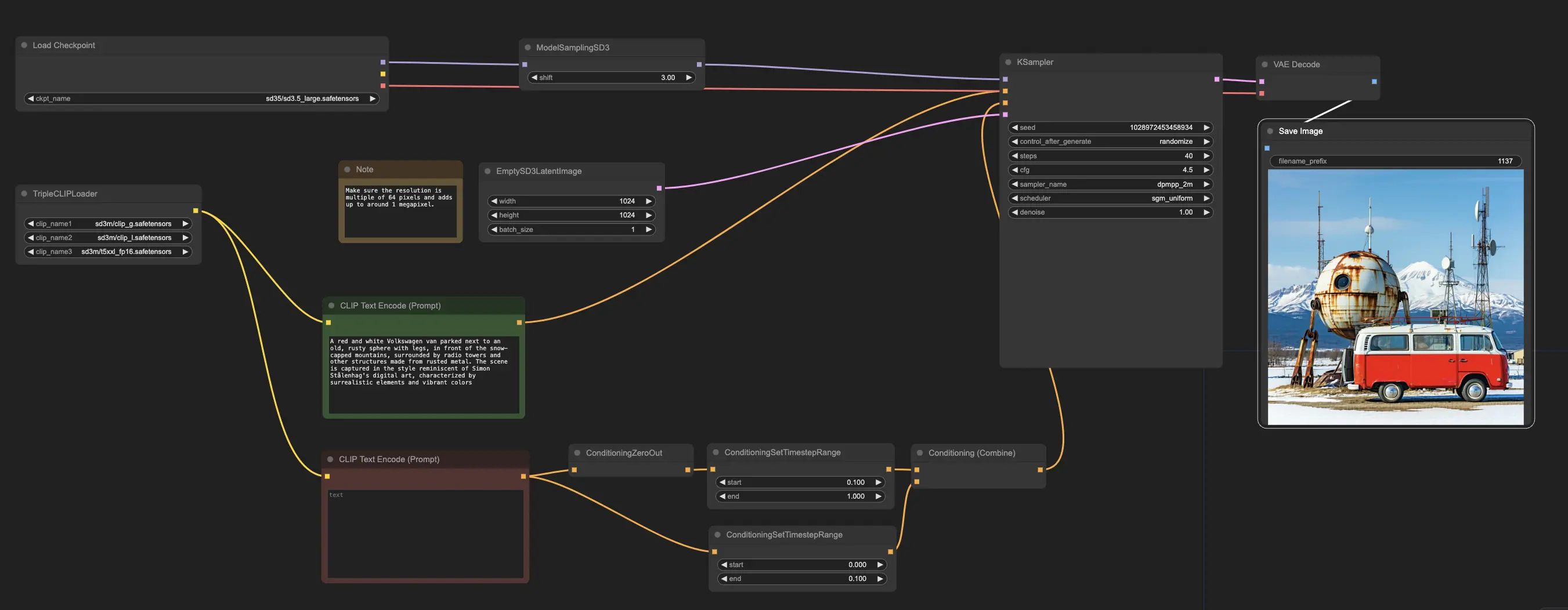
Примерный рабочий процесс начинается с узла CheckpointLoaderSimple, который загружает предобученную модель Stable Diffusion 3.5 Large. А для помощи в переводе ваших текстовых подсказок в формат, который модель может понять, используется узел TripleCLIPLoader для загрузки соответствующих кодировщиков. Эти кодировщики играют ключевую роль в направлении процесса генерации изображений на основе предоставленного вами текста.
Затем узел EmptySD3LatentImage создает пустой холст с указанными размерами, обычно 1024x1024 пикселя, который служит отправной точкой для модели для генерации изображения. Узлы CLIPTextEncode обрабатывают предоставленные вами текстовые подсказки, используя загруженные кодировщики для создания набора инструкций, которые модель должна следовать.
Прежде чем эти инструкции будут отправлены модели, они проходят дальнейшую доработку через узлы ConditioningCombine, ConditioningZeroOut и ConditioningSetTimestepRange. Эти узлы удаляют влияние любых негативных подсказок, указывают, когда подсказки должны применяться в процессе генерации, и объединяют инструкции в единый, согласованный набор.
Наконец, вы можете настроить процесс генерации изображений с помощью узла ModelSamplingSD3, который позволяет вам регулировать различные параметры, такие как режим выборки, количество шагов и масштаб вывода модели. В конце концов, узел KSampler дает вам контроль над количеством шагов, силой влияния инструкций (CFG scale) и конкретным алгоритмом, используемым для генерации, позволяя достичь желаемых результатов.


