Animatediff V2 & V3 | 文本转视频
AnimateDiff 提供了一种令人兴奋的方式来将文本转换为动画 GIF 或视频。在此 ComfyUI 工作流程中,您可以尝试 AnimateDiff V3、AnimateDiff SDXL 和 AnimateDiff V2,并探索 Latent Upscale 的领域以获得高分辨率结果。ComfyUI AnimateDiff 工作流程
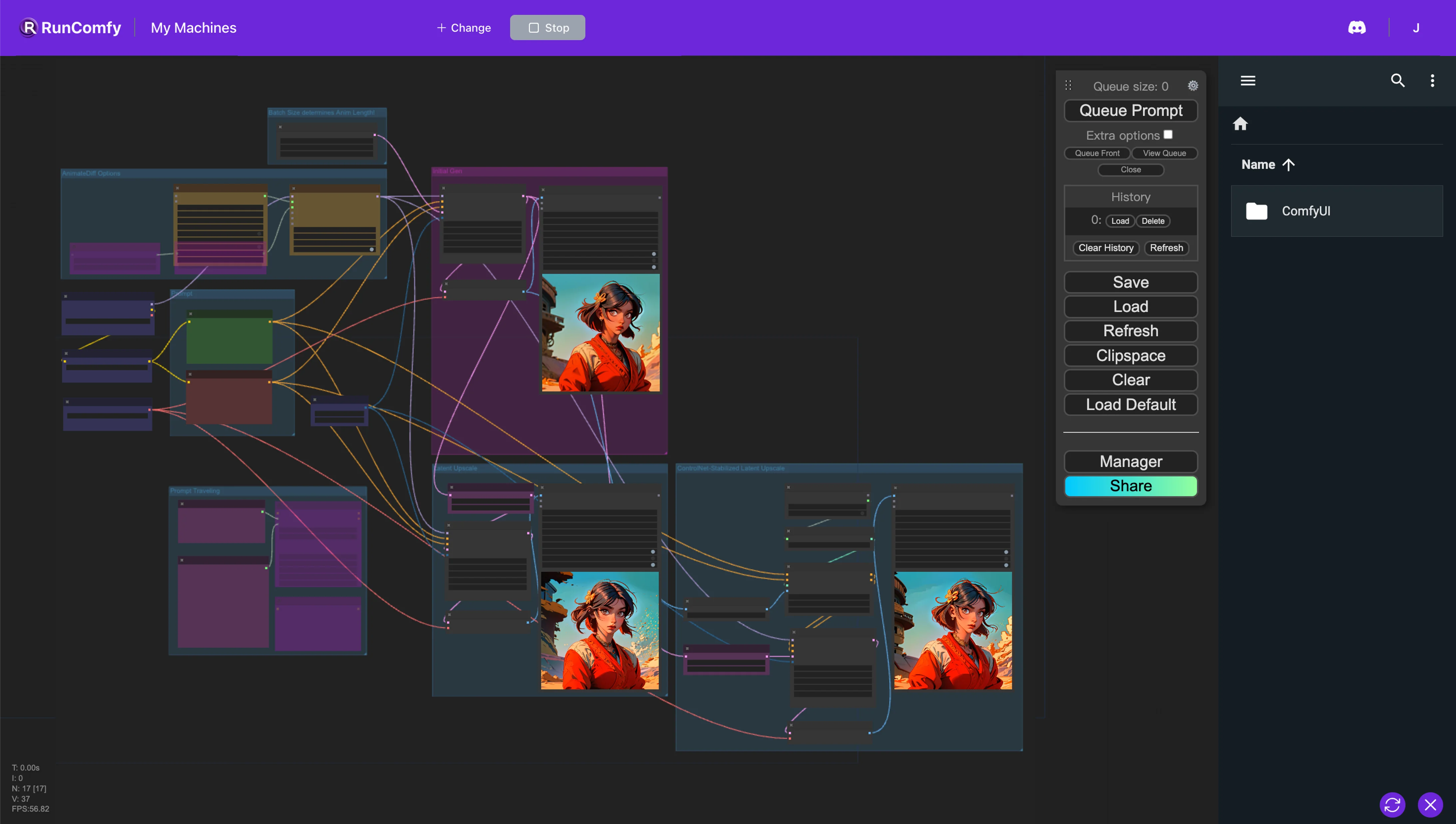
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI AnimateDiff 示例
ComfyUI AnimateDiff 描述
1. ComfyUI AnimateDiff 工作流程
这个 ComfyUI AnimateDiff 工作流程旨在让用户深入探索 AnimateDiff V3、AnimateDiff SDXL 和 AnimateDiff V2 版本中 AnimateDiff 的复杂功能。它有助于探索各种动画,结合不同的动作和风格。在使用 AnimateDiff 创建动画后,采用两种方法使用 Latent Upscale 实现高分辨率结果。第一种方法是在 ComfyUI 中利用传统的潜在上采样,调整去噪强度和上采样因子等参数。第二种方法是 Control Net Assisted Latent Upscale,通过集成线稿预处理器和适当的控制网络模型,在保持原始艺术精髓的同时显著改善艺术品。
2. AnimateDiff 概述
2.1. AnimateDiff 简介
AnimateDiff 是一个开创性的框架,旨在为文本到图像模型(如 Stable Diffusion)生成的图像注入生命。该工具允许用户无缝地将运动集成到静态图像中,将其转换为个性化的动画视觉效果。该框架建立在通过在视频剪辑上训练运动建模模块来增强现有文本到图像模型的前提之下,以捕捉真实的运动动态。这个过程消除了对模型特定调整的需求,为动画个性化图像提供了通用解决方案。
2.2. AnimateDiff 的不同版本
2.2.1. AnimateDiff V3:通过新技术革新动作
AnimateDiff V3 引入了一个突破性的运动模块,封装了动画技术的最新进展。这一演变的核心在于 Domain Adapter LoRA 模块,这是一种通过在静态视频帧上训练来准备运动模块的机制。这种设置使 AnimateDiff 能够巧妙地应对运动的复杂性,确保动画既细腻又灵活。与其前身不同,V3 并未在所有方面都超越 V2,但引入了多样化的运动能力,丰富了用户的创作工具包。
2.2.2. AnimateDiff SDXL:高分辨率视频动画
对于高清视觉效果的爱好者来说,AnimateDiff SDXL 提供了一个诱人的选择。这个 Beta 版本支持创建高分辨率视频(1024x1024 分辨率,16 帧),适应各种宽高比,可以选择是否使用个性化模型。尽管处于 Beta 阶段,SDXL 有望提升动画内容的质量,预计不久将推出更精细的版本。
2.2.3. AnimateDiff V2:经典运动和相机移动控制
AnimateDiff V2 是基础版本,通过增强分辨率和批量训练显著提高了样本质量。它引入了 MotionLoRA,可以控制八种基本相机移动,包括放大/缩小、向左/向右平移、向上/向下倾斜以及顺时针/逆时针滚动。这个版本非常适合希望在动画中加入动态相机移动的用户,为创建引人入胜的视觉叙事提供了一套强大的工具。
