
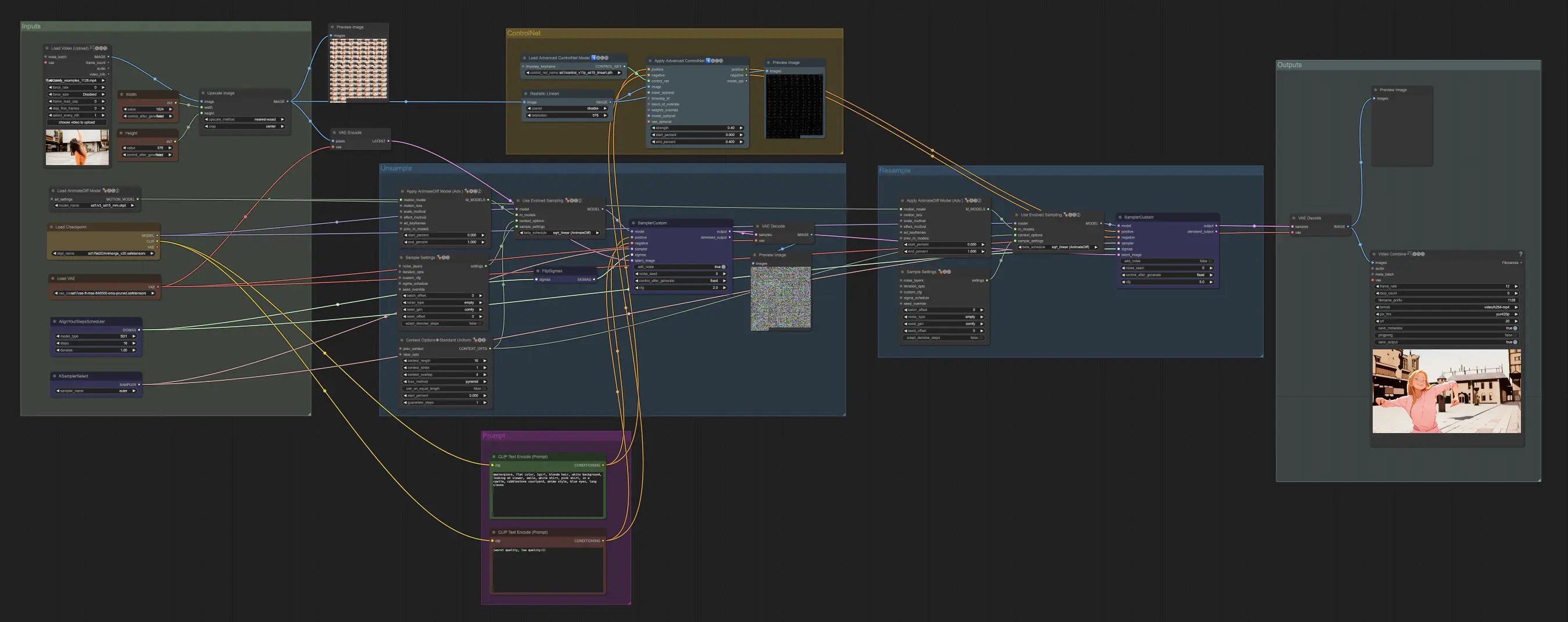
这份由Inner-Reflections撰写的Unsampling指南,对探索实现显著一致的视频风格迁移的Unsampling方法做出了巨大贡献。
1. 介绍:使用Unsampling控制潜在噪声#
潜在噪声是我们在Stable Diffusion中所做的一切的基础。回过头来思考我们能够实现的目标,真是令人惊叹。然而,总的来说,我们被迫使用随机数生成噪声。如果我们能够控制它呢?
我不是第一个使用Unsampling的人。它已经存在很长时间,并且已经以多种不同的方式使用。然而,直到现在,我对结果并不满意。我花了几个月的时间寻找最佳设置,希望你们喜欢这份指南。
通过与AnimateDiff/Hotshot一起使用采样过程,我们可以找到代表原始视频的噪声,从而使任何形式的风格迁移变得更容易。特别是考虑到Hotshot的8帧上下文窗口,保持一致性尤为重要。
这个unsampling过程本质上将我们的输入视频转换为保持原始运动和构图的潜在噪声。然后,我们可以将这种代表性噪声作为扩散过程的起点,而不是随机噪声。这允许AI在保持时间一致性的同时应用目标风格。
本指南假设你已经安装了AnimateDiff和/或Hotshot。如果你还没有安装,可以在这里找到指南:
AnimateDiff: https://civitai.com/articles/2379
Hotshot XL指南: https://civitai.com/articles/2601/
资源链接 - 如果你想使用此工作流程在Civitai上发布视频。 https://civitai.com/models/544534
2. 该工作流程的系统要求#
建议使用带有至少12GB VRAM的NVIDIA显卡的Windows电脑。在RunComfy平台上,使用中等(16GB VRAM)或更高阶机器。这个过程不需要比标准的AnimateDiff或Hotshot工作流程更多的VRAM,但它几乎需要两倍的时间,因为它本质上运行两次扩散过程—一次用于上采样,一次用于重新采样目标风格。
3. 节点解释和设置指南#
节点:Custom Sampler#
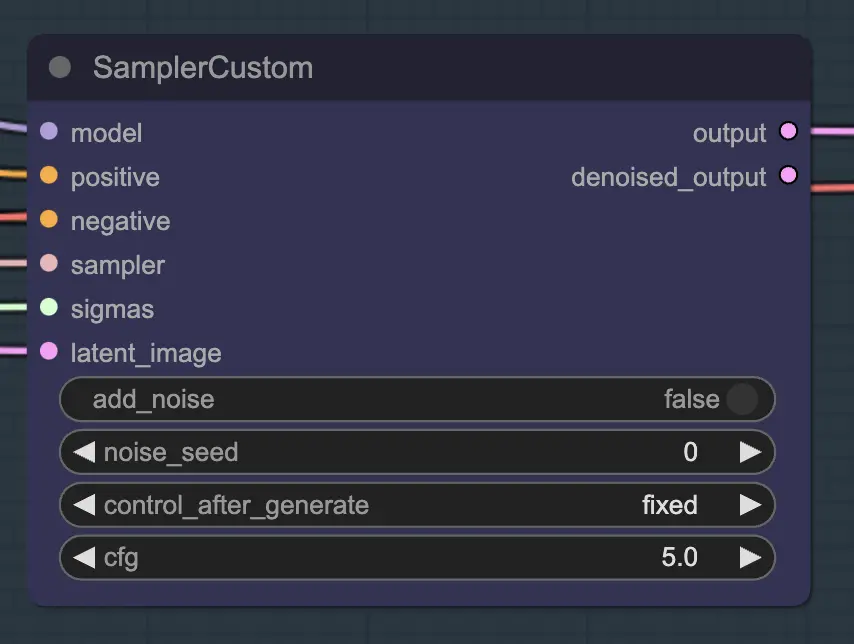
主要部分是使用Custom Sampler,它将你通常在常规KSampler中看到的所有设置分割成多个部分:
这是主要的KSampler节点 - 对于unsampling,添加噪声/种子没有任何效果(据我所知)。CFG很重要 - 总的来说,CFG越高,这一步视频看起来越接近你的原始视频。较高的CFG迫使unsampler更紧密地匹配输入。
节点:KSampler Select#
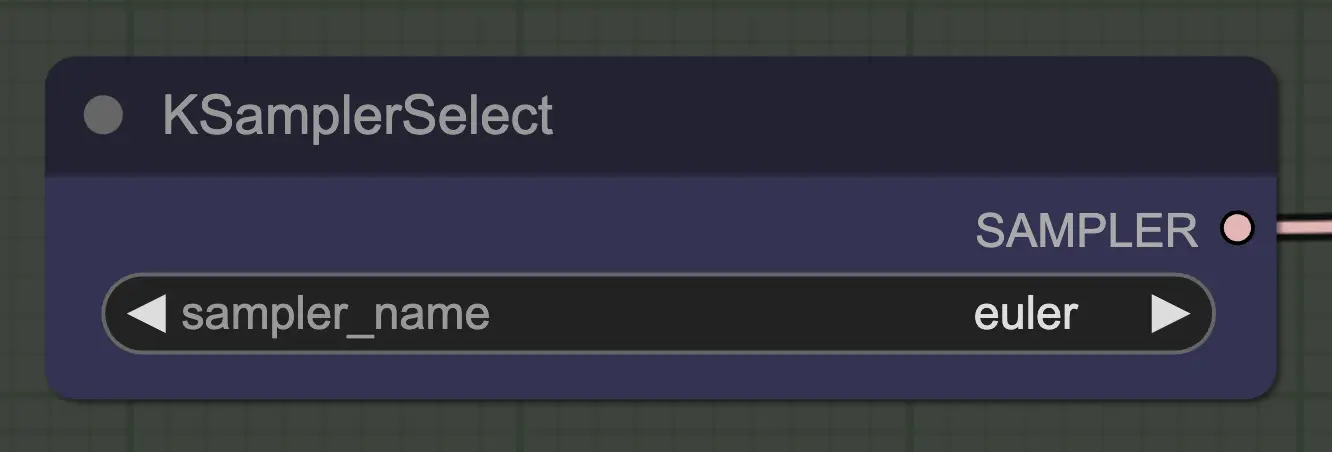
最重要的是使用一个收敛的采样器!这就是为什么我们使用euler而不是euler a,因为后者导致更多的随机性/不稳定性。 在每一步添加噪声的祖先采样器阻止unsampling干净地收敛。如果你想了解更多关于这方面的信息,我一直发现 this article 有用。reddit上的@spacepxl建议DPM++ 2M Karras可能是根据使用情况更准确的采样器。
节点:Align Your Step Scheduler#
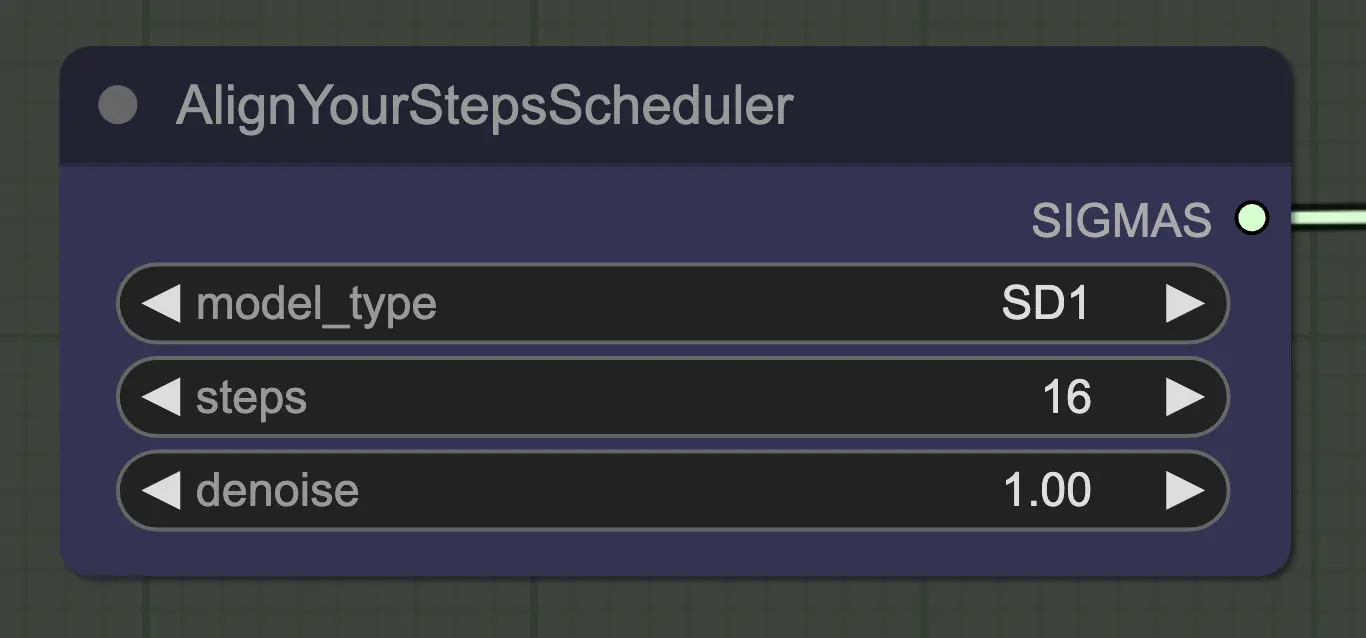
任何调度器在这里都可以正常工作 - Align Your Steps (AYS) 在16步时效果很好,所以我选择使用它以减少计算时间。更多的步骤会更完全地收敛,但收益递减。
节点:Flip Sigma#
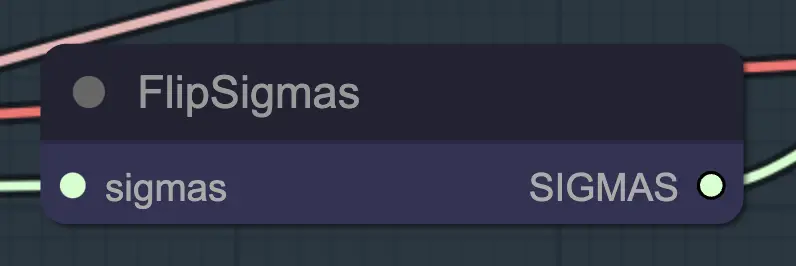
Flip Sigma是导致unsampling发生的神奇节点!通过翻转sigma时间表,我们逆转扩散过程,从干净的输入图像到代表性噪声。
节点:Prompt#
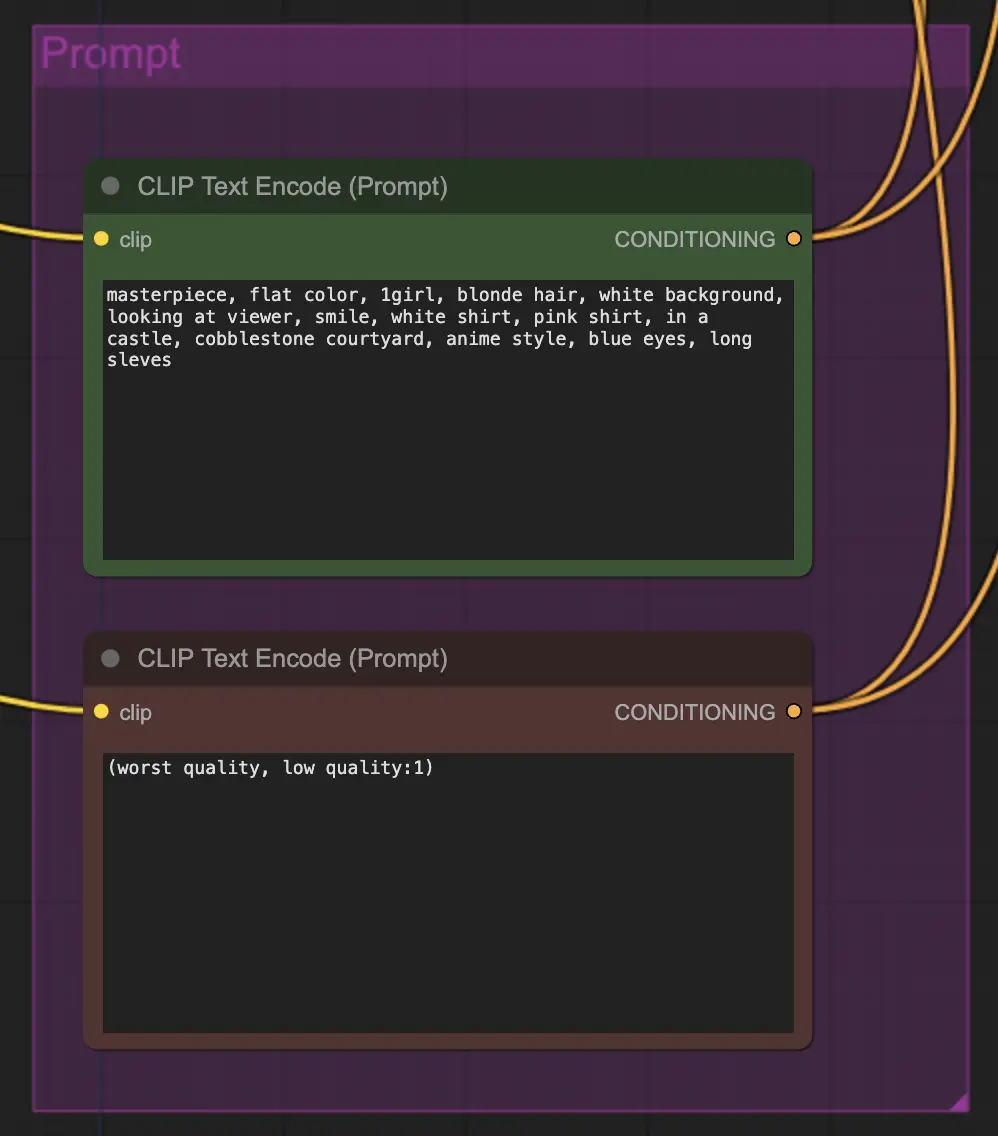
在这种方法中提示非常重要。一个好的提示可以显著提高视频的一致性,特别是当你想推动转换时。在这个例子中,我将相同的条件输入到unsampler和resampler中。通常效果很好 - 然而,没有什么可以阻止你在unsampler中放置空白条件 - 我发现这有助于改善风格迁移,尽管可能会稍微失去一致性。
节点:Resampling#
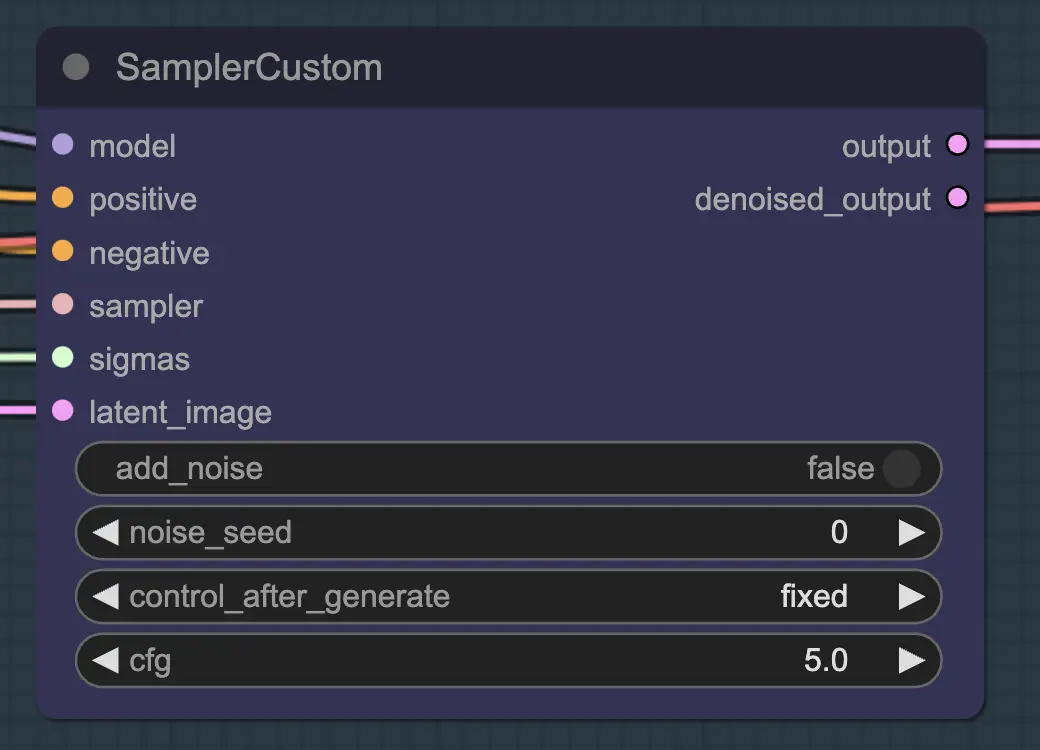
对于重新采样,重要的是关闭添加噪声 (尽管在AnimateDiff采样设置中有空噪声效果相同 - 我在我的工作流程中同时做了这两件事)。如果在重新采样期间添加噪声,你将得到一个不一致的,有噪声的结果,至少在默认设置下。否则,我建议从相对较低的CFG开始,结合弱ControlNet设置,因为这似乎在仍然允许提示影响风格的同时,给出了最一致的结果。
其他设置#
我其余的设置是个人偏好。我认为在仍然包括关键组件和设置的情况下,我已经尽可能简化了这个工作流程。
4. 工作流程信息#
默认工作流程使用SD1.5模型。然而,你可以通过简单地将检查点、VAE、AnimateDiff模型、ControlNet模型和步调度模型更改为SDXL来切换到SDXL。
5. 重要提示/问题#
- 闪烁 - 如果你查看我工作流程中由unsampling创建的解码和预览潜在变量,你会注意到一些明显的颜色异常。确切原因对我来说不清楚,通常它们不会影响最终结果。这些异常在SDXL中尤其明显。然而,它们有时会导致你的视频闪烁。主要原因似乎与ControlNets有关 - 因此减少它们的强度可以有所帮助。改变提示或稍微改变调度器也可以有所不同。我有时仍会遇到这个问题 - 如果你有解决方案,请告诉我!
- DPM++ 2M有时可以改善闪烁。
6. 从这里开始?#
这感觉像是一种全新的控制视频一致性的方法,所以有很多东西可以探索。如果你想要我的建议:
- 尝试结合/屏蔽来自多个源视频的噪声。
- 添加IPAdapter以实现一致的角色转换。
关于作者#
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI