IPAdapter V1 FaceID Plus | 一致的角色
使用 IPAdapter Face Plus V2 模型充分发挥你的角色设计潜力。该工作流程允许创作者在各种风格中保持一致的角色特征。你可以随意使用不同的 checkpoint 或 LoRA 模型来探索多种风格ComfyUI Consistent Characters 工作流程
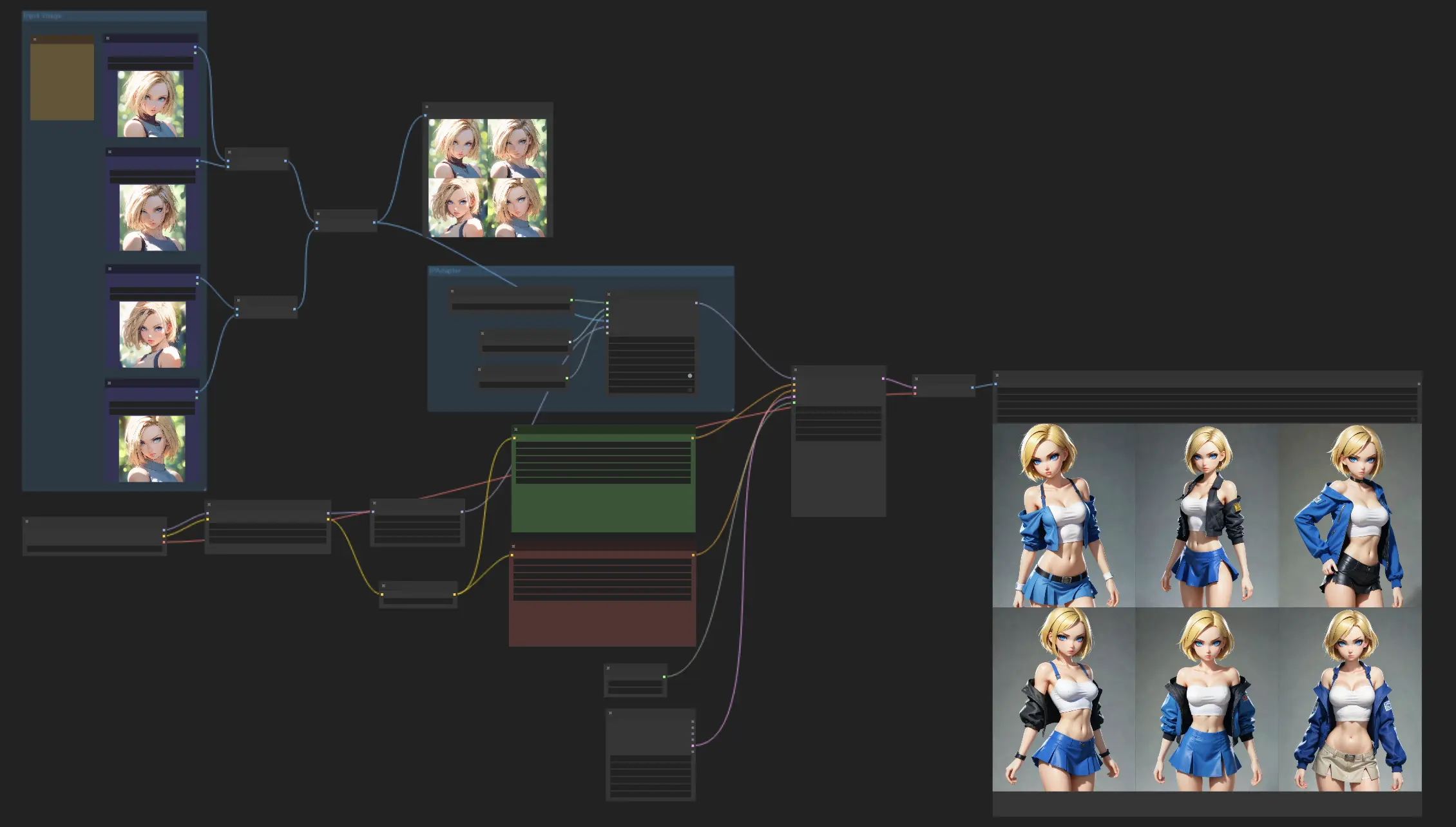
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Consistent Characters 示例

ComfyUI Consistent Characters 描述
1. 一致角色工作流程
这个工作流程主要是利用 IPAdapter Face Plus V2 模型创建外观一致的角色。首先上传一些参考图片,然后让 Face Plus V2 模型发挥它的魔力,创建一系列保持相同面部特征的图像。你可以随意混合使用不同的 checkpoint 或 LoRA 模型来探索各种风格,同时保持角色外观的一致性。
2. IPAdapter FaceID/FaceID Plus 概述
v1.5 FaceID
该模型是面部识别的基础版本,允许通过文本提示、control nets 和遮罩进行变体增强。它以其平均的条件强度而著称,适用于一般的面部条件任务。基础 FaceID 模型不使用 CLIP vision encoder,这意味着无需复杂的编码器配置即可实现更简单的设置。
v1.5 FaceID Plus
FaceID Plus 模型是一个更强大的变体,旨在实现更强的图像到图像的条件效果。它需要使用 ViT-H image encoder,表明其需要更高的处理能力来进行详细的面部建模。
v1.5 FaceID Plus v2
作为 FaceID Plus 的迭代版本,该模型引入了增强功能,以实现更详细的面部条件。与 FaceID Plus 类似,它也使用 ViT-H image encoder。该模型旨在提供更高质量的面部建模,满足更细微的要求。
v1.5 FaceID Portrait
该模型专为肖像而设计,不使用 CLIP vision encoder。它专注于在肖像设置中生成高质量的面部图像,可能为肖像图像生成提供专业化的方法。
SDXL FaceID
FaceID 的 SDXL 变体是为 SDXL 架构量身定制的,不采用 CLIP vision encoder。它代表了 SDXL 套件中的基础模型,专为可扩展的深度学习架构而设计,专注于面部识别任务。
SDXL FaceID Plus v2
这是 SDXL 架构的 FaceID 模型的更强版本,使用 ViT-H image encoder。它旨在为 SDXL 框架内的高质量图像生成任务提供增强的面部条件效果。
3. 如何使用 IPAdapter FaceID/FaceID Plus
3.1. 选择 FaceID/FaceID Plus 模型
选择你喜欢的 FaceID 或 FaceID Plus 模型开始制作图像。在设置中,你会找到调整权重和噪声的选项。这些调整对于微调生成图像的外观至关重要,让你能够实现精确的目标外观。
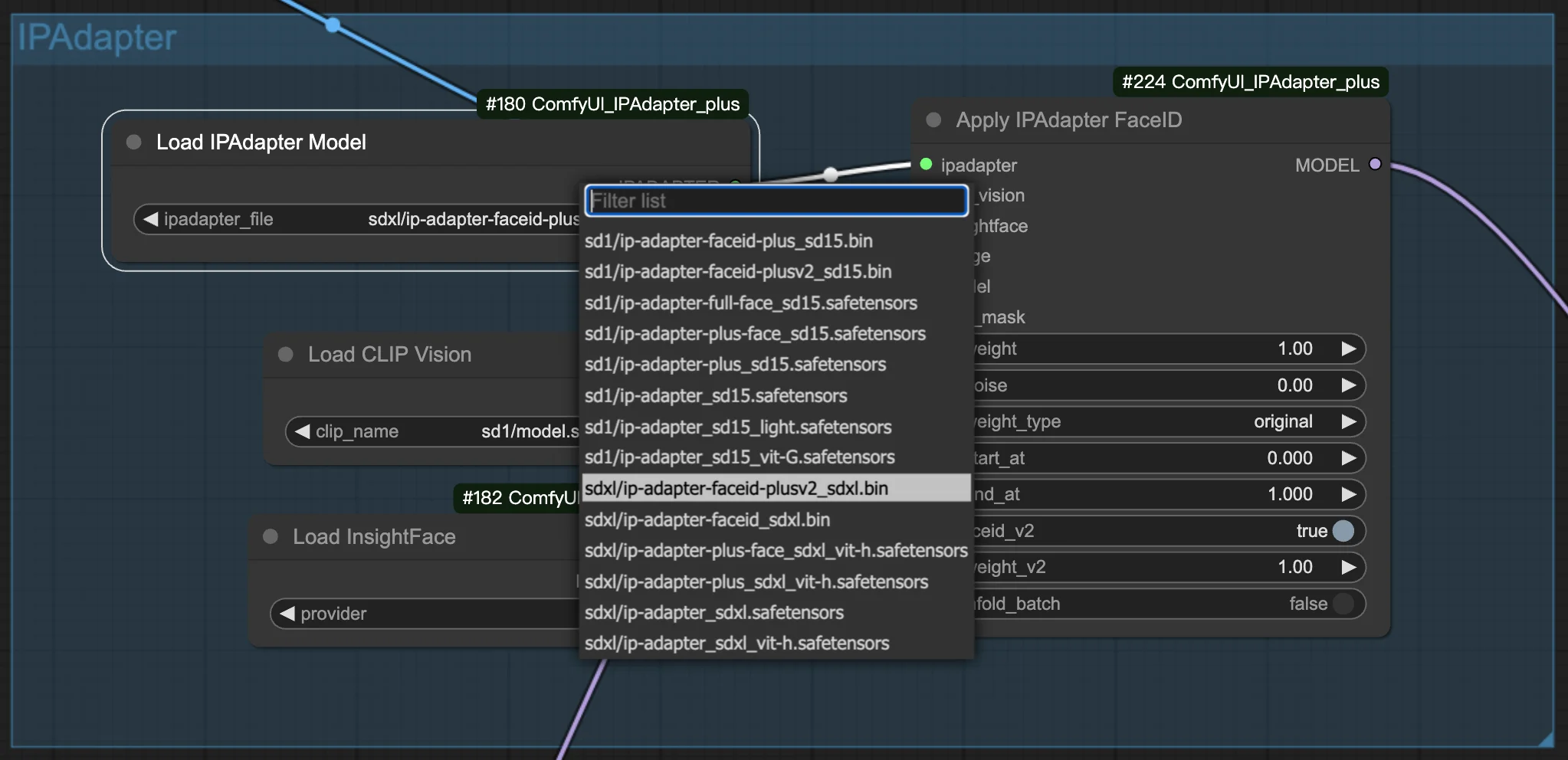
3.2. 准备参考图像
使用 IPAdapter FaceID 节点时,CLIP vision 模型会通过将参考图像调整大小并将其居中到 224x224 像素的尺寸来处理参考图像。这种自动调整聚焦于图像的中心,因此将图像的主要主题(如角色的脸)定位在中心非常重要。如果主题偏离中心,特别是在纵向或横向图像中,结果可能无法满足你的期望。 为了获得最佳效果,强烈建议使用主题居中的正方形图像。







