Omost | 增强图像创建
Omost利用大型语言模型将编码转化为详细的图像组成。通过使用结构化画布和复杂的提示工程,Omost确保了精确和高效的图像生成ComfyUI Omost 工作流程
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
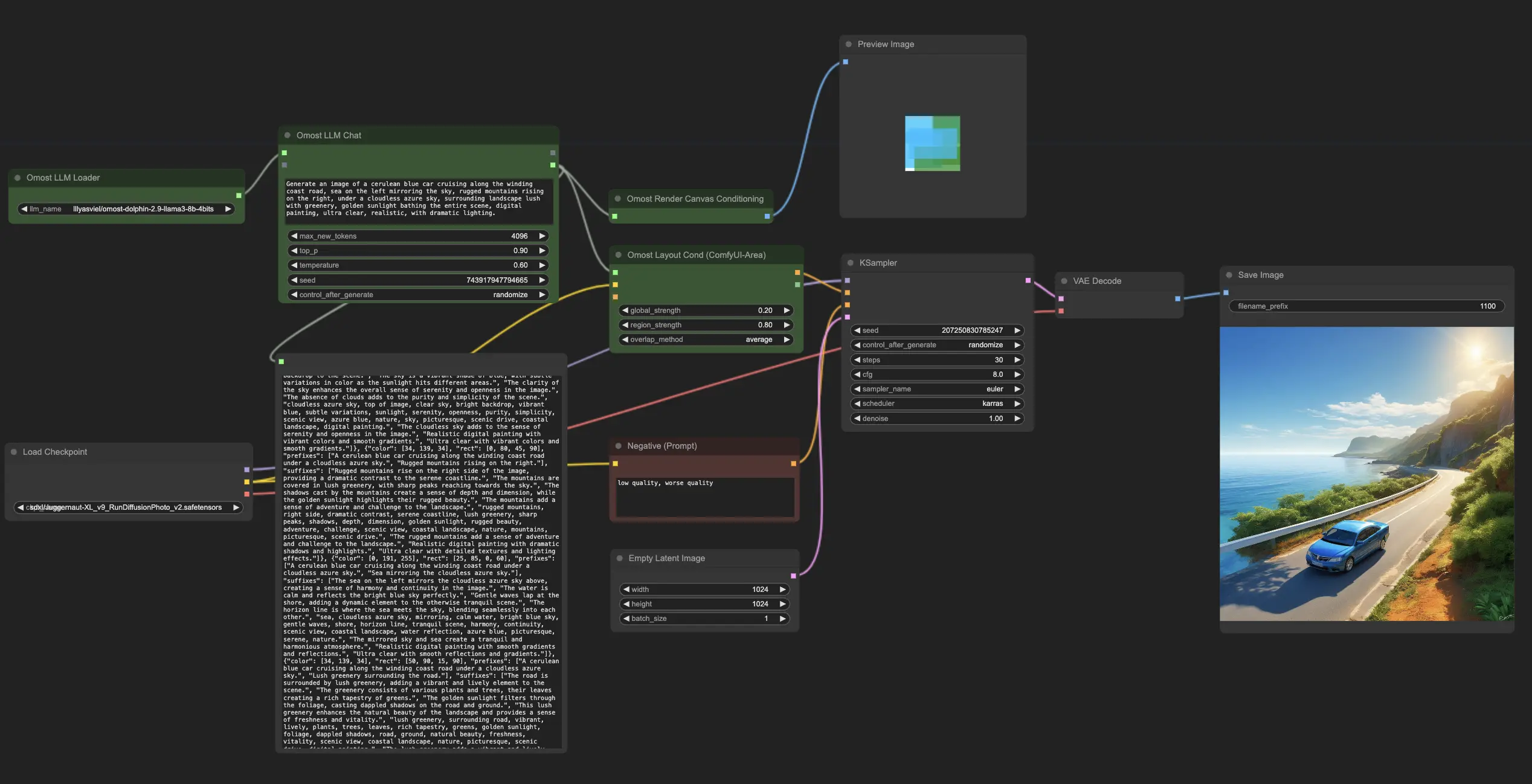
ComfyUI Omost 示例

ComfyUI Omost 描述
1. 什么是Omost?
Omost,"Your image is almost there!"的缩写,是一个创新项目,将大型语言模型(LLM)的编码能力转换为图像生成,更准确地说,是图像合成能力。"Omost"这个名字有双重含义:它意味着每次使用Omost时,您的图像几乎完成,同时也表示"omni"(多模式)和"most"(最大化利用)。
Omost提供预训练的LLM模型,这些模型生成代码来使用Omost的虚拟画布代理合成图像视觉内容。然后,这个画布可以通过特定的图像生成器实现来创建最终图像。Omost旨在简化和增强图像生成过程,使其对AI艺术家来说既易于访问又高效。
2. Omost的工作原理
2.1. 画布和描述
Omost使用一个虚拟画布来描述和定位图像元素。画布分为9x9=81个位置,允许精确放置元素。这些位置进一步细化为边界框,为每个元素提供729个不同的可能位置。这种结构化的方法确保了元素的准确和一致放置。
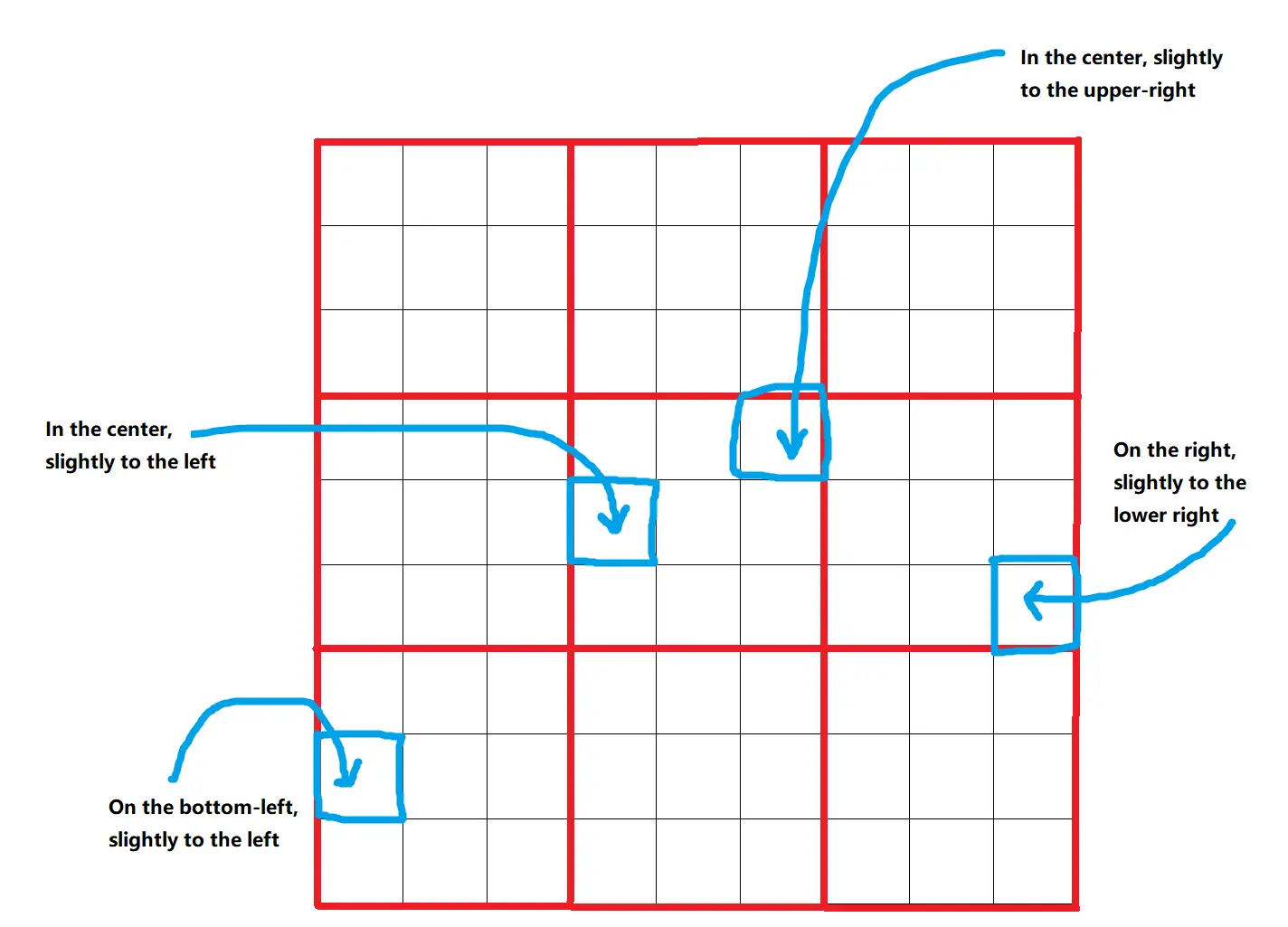
2.2. 深度和颜色
画布上的元素分配一个distance_to_viewer参数,这有助于将它们排序为从背景到前景的层次。这个参数作为相对深度指示器,确保较近的元素出现在较远元素的前面。此外,HTML_web_color_name参数提供初步渲染的粗略颜色表示,可以使用扩散模型进行细化。这种初始颜色有助于在微调之前可视化组成。

2.3. 提示工程
Omost使用子提示,这些是元素的简短独立描述,以生成详细和连贯的图像组成。每个子提示少于75个标记,并独立描述一个元素。这些子提示合并成完整的提示供LLM处理,确保生成的图像准确且语义丰富。这种方法确保文本编码高效并避免语义截断错误。
2.4. 区域提示器
Omost实现了高级注意力操控技术来处理区域提示,确保图像的每个部分根据给定描述准确生成。通过操控注意力分数,确保在遮罩区域内的激活受到鼓励,而外部的受到抑制。这种精确的注意力控制导致高质量的区域特定图像生成。
3. ComfyUI Omost节点的详细解释
3.1. Omost LLM加载节点
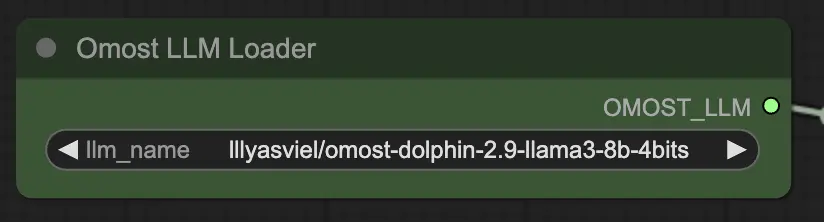
Omost LLM加载节点的输入参数
llm_name: 要加载的预训练LLM模型的名称。可用选项包括:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
此参数指定要加载的模型,每个模型提供不同的功能和优化。
Omost LLM加载节点的输出参数
OMOST_LLM: 加载的LLM模型。
此输出提供加载的LLM,准备生成图像描述和组成。
3.2. Omost LLM聊天节点
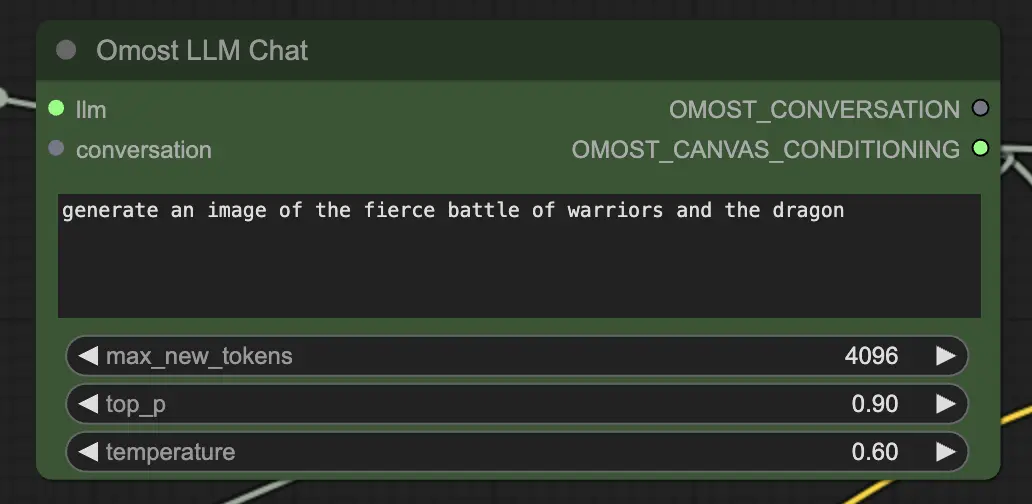
Omost LLM聊天节点的输入参数
llm: 由OmostLLMLoader加载的LLM模型。text: 生成图像的文本提示。这是描述您想生成的场景或元素的主要输入。max_new_tokens: 生成的新标记的最大数量。这控制生成文本的长度,较高的数字允许更详细的描述。top_p: 控制生成输出的多样性。接近1.0的值包括更多多样化的可能性,而较低的值则专注于最可能的结果。temperature: 控制生成输出的随机性。较高的值导致更随机的输出,而较低的值使输出更确定。conversation(可选): 先前的对话上下文。这允许模型从先前的互动中继续,保持上下文和连贯性。
Omost LLM聊天节点的输出参数
OMOST_CONVERSATION: 对话历史,包括新响应。这有助于跟踪对话并在多次互动中保持上下文。OMOST_CANVAS_CONDITIONING: 用于渲染的生成画布调节参数。这些参数定义元素在画布上的放置和描述方式。
3.3. Omost渲染画布调节节点
Omost渲染画布调节节点的输入参数
canvas_conds: 画布调节参数。这些参数包括元素在画布上的详细描述和位置。
Omost渲染画布调节节点的输出参数
IMAGE: 基于画布调节的渲染图像。此输出是描述场景的视觉表示,基于调节参数生成。
3.4. Omost布局调节节点
Omost布局调节节点的输入参数
canvas_conds: 画布调节参数。clip: 用于文本编码的CLIP模型。此模型将文本描述编码为可用于图像生成器的向量。global_strength: 全局调节的强度。这控制整体描述对图像的影响程度。region_strength: 区域调节的强度。这控制特定区域描述对其各自区域的影响程度。overlap_method: 处理重叠区域的方法(例如,overlay,average)。这定义了如何在图像中混合重叠区域。positive(可选): 额外的正面调节。这可以包括额外的提示或条件,以增强图像的特定方面。
Omost布局调节节点的输出参数
CONDITIONING: 图像生成的调节参数。这些参数指导图像生成过程,确保输出与描述场景匹配。MASK: 用于调节的遮罩。这有助于调试并将额外的条件应用于特定区域。
3.5. Omost加载画布调节节点
Omost加载画布调节节点的输入参数
json_str: 表示画布调节参数的JSON字符串。这允许从JSON文件加载预定义的条件。
Omost加载画布调节节点的输出参数
OMOST_CANVAS_CONDITIONING: 加载的画布调节参数。这些参数初始化画布,带有特定条件,准备生成图像。


