LTX 视频 | 从图像+文本到视频
Lightricks 开发了 LTX 视频,这是一种使用基于扩散技术的视频生成模型。该模型可以根据文本提示或图像和文本提示的组合生成视频。LTX 视频以 768x512 的分辨率和 24 FPS 的帧率输出视频。LTX 模型经过多样化数据集的训练,以生成多样化的视频内容。探索 LTX 模型背后的技术,并在 ComfyUI 中使用它。ComfyUI LTX Video 工作流程
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
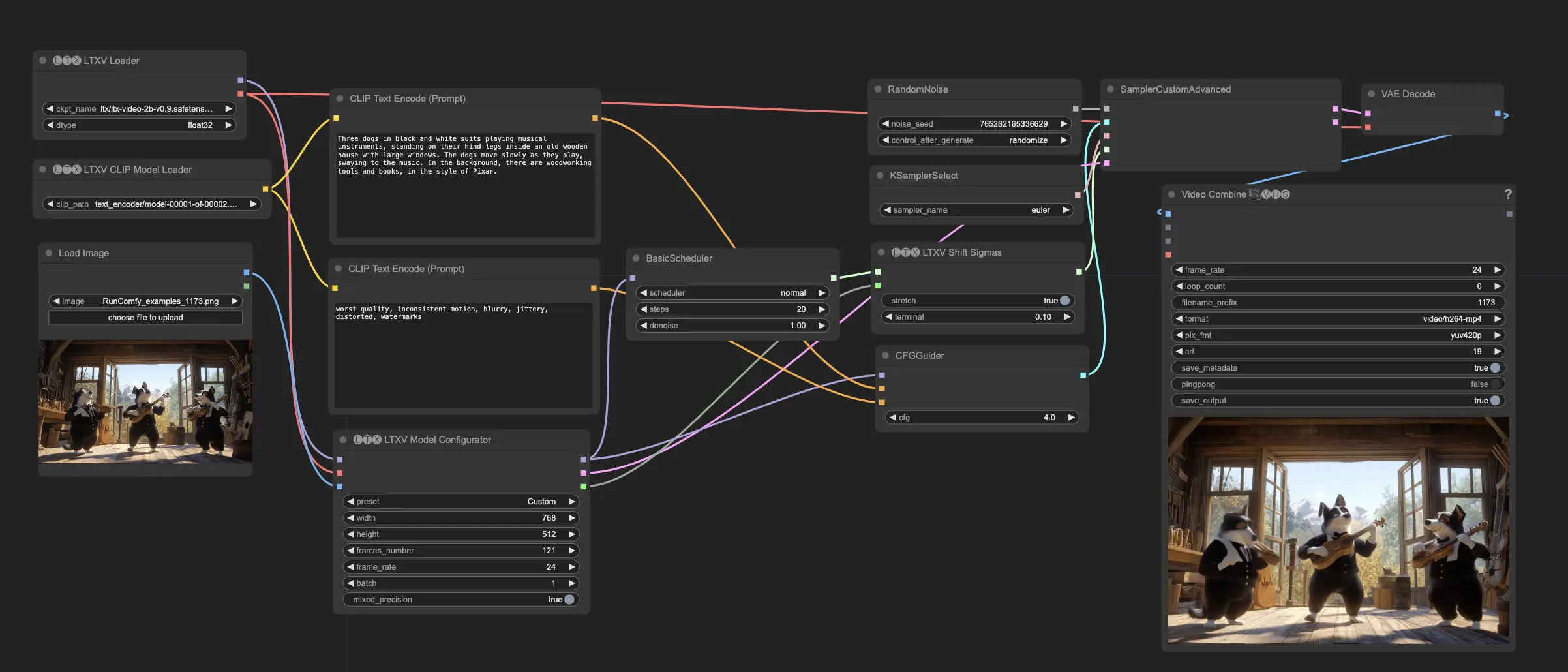
ComfyUI LTX Video 示例
ComfyUI LTX Video 描述
LTX 视频是由 Lightricks 开发的基于扩散的视频生成模型。它能够从文本提示(文本到视频)或图像和文本提示的组合(图像+文本到视频)生成视频。LTX 视频以 768x512 的分辨率生成每秒 24 帧(FPS)的视频,速度比观看速度更快。该模型在包含多样化视频的大规模数据集上进行了训练,使其能够在高分辨率下生成逼真且多样化的视频内容。
LTX 视频模型和 ComfyUI-LTXVideo 节点由 Lightricks 开发。所有功劳归功于他们在创建 LTX 视频方面的工作。有关 LTX 视频和 Lightricks 项目的更多信息,请访问他们的 GitHub 存储库:https://github.com/Lightricks/LTX-Video 或他们的网站:https://www.lightricks.com/ltxv。
LTX 模型背后的技术
LTX 视频利用基于扩散的方法生成视频。扩散模型通过在多个时间步长中逐步去噪一个噪声输入来生成最终输出。在 LTX 视频的情况下,模型将一个噪声潜在表示作为输入,并迭代去噪以生成一系列视频帧。去噪过程由提供的文本或图像+文本提示引导,这些提示控制生成视频的内容和风格。
LTX 视频采用的关键技术包括:
- 基于扩散的视频生成:通过利用扩散模型,LTX 视频可以生成具有真实运动和帧间一致性的视频。
- 文本到视频合成:LTX 视频可以仅根据文本描述生成视频,使用户能够使用自然语言提示从头创建自定义视频。
- 图像+文本到视频合成:LTX 视频还支持通过将初始图像与文本提示结合来生成视频。这允许用户为视频提供一个起点,并使用文本引导其内容和风格。
如何在 ComfyUI 中使用 LTX 视频工作流
- 准备输入:
- 默认工作流是图像+文本到视频生成。提供一个初始图像和一个文本提示。图像作为起点,模型将基于图像和伴随的文本生成视频。请注意,该模型需要长而描述性的提示;如果提示过短,质量会大幅下降。
- 配置模型参数:
- 设置所需的分辨率和生成内容的帧数。分辨率应为 32 的倍数,帧数应为 8 + 1 的倍数(例如,257 帧)。LTX 在分辨率低于 720x1280 像素和少于 257 帧时效果最佳。
- 根据您的要求调整其他参数,例如扩散步骤、噪声计划和指导尺度。这些参数控制生成输出的质量和多样性。
- 生成内容:
- 输出将具有指定的分辨率和帧数,并与提供的输入提示一致。
LTX 模型的局限性
- LTX 视频不旨在或无法提供事实信息。
- 作为统计模型,LTX 视频可能会放大训练数据中存在的现有社会偏见。
- 生成的视频可能无法完全匹配提供的提示。
- 提示跟随的质量很大程度上取决于使用的提示风格。
许可
请根据 使用该模型。

