






你好,AI爱好者们!👋 欢迎来到我们关于在ComfyUI中使用FLUX的介绍指南。FLUX是由Black Forest Labs开发的前沿模型。🌟 在本教程中,我们将深入探讨ComfyUI FLUX的基本知识,展示这个强大模型如何增强你的创作过程,并帮助你突破AI生成艺术的边界。🚀
我们将涵盖:
- 1. FLUX简介
- 2. FLUX的不同版本
- 3. FLUX硬件要求
- 3.1. FLUX.1 [Pro] 硬件要求
- 3.2. FLUX.1 [Dev] 硬件要求
- 3.3. FLUX.1 [Schnell] 硬件要求
- 4. 如何在ComfyUI中安装FLUX
- 4.1. 安装或更新ComfyUI
- 4.2. 下载ComfyUI FLUX文本编码器和CLIP模型
- 4.3. 下载FLUX.1 VAE模型
- 4.4. 下载FLUX.1 UNET模型
- 5. ComfyUI FLUX工作流 | 下载,在线访问和指南
- 5.1. ComfyUI工作流:FLUX Txt2Img
- 5.2. ComfyUI工作流:FLUX Img2Img
- 5.3. ComfyUI工作流:FLUX LoRA
- 5.4. ComfyUI工作流:FLUX ControlNet
- 5.5. ComfyUI工作流:FLUX修复
- 5.6. ComfyUI工作流:FLUX NF4和Upscale
- 5.7. ComfyUI工作流:FLUX IPAdapter
- 5.8. ComfyUI工作流:Flux LoRA训练器
- 5.9. ComfyUI工作流:Flux潜变量Upscale
1. FLUX简介#
FLUX.1是Black Forest Labs开发的前沿AI模型,它正在改变我们从文本描述中创建图像的方式。凭借其无与伦比的能力,FLUX.1能够生成与输入提示紧密匹配的令人惊叹的详细和复杂图像,使其从竞争中脱颖而出。FLUX.1成功的秘密在于其独特的混合架构,结合了不同类型的变压器块,并由惊人的120亿参数提供支持。这使得FLUX.1能够生成视觉上引人注目的图像,并以惊人的精确度准确地表示文本描述。
FLUX.1最令人兴奋的方面之一是它在生成各种风格的图像方面的多功能性,从写实到艺术风格。FLUX.1甚至具有将文本无缝集成到生成图像中的显著能力,这是许多其他模型难以实现的壮举。此外,FLUX.1以其出色的提示遵从性而闻名,无论是简单还是复杂的描述,都能轻松处理。这使得FLUX.1经常与其他知名模型如Stable Diffusion和Midjourney进行比较,FLUX.1通常因其用户友好性和顶级结果而成为首选。
FLUX.1的令人印象深刻的能力使其成为广泛应用的宝贵工具,从创建令人惊叹的视觉内容和激发创新设计到促进科学可视化。FLUX.1从文本描述中生成高度详细和准确的图像的能力为创意专业人士,研究人员和爱好者开辟了无限可能的世界。随着AI生成图像领域的不断发展,FLUX.1处于前沿,树立了质量,多样性和易用性的新的标准。
Black Forest Labs是开发革命性FLUX.1的先锋AI公司,由AI行业知名人物Robin Rombach创立,他曾是Stability AI的核心成员。如果你渴望了解更多关于Black Forest Labs及其与FLUX.1的革命性工作,请务必访问他们的官方网站:https://blackforestlabs.ai/。

2. FLUX的不同版本#
FLUX.1有三个不同的版本,每个版本都旨在满足特定用户的需求:
- FLUX.1 [pro]:这是顶级版本,提供最佳质量和性能,非常适合专业用途和高端项目。
- FLUX.1 [dev]:为非商业用途优化,该版本保持高质量输出,同时更高效,非常适合开发人员和爱好者。
- FLUX.1 [schnell]:这是关于速度和轻量化的版本,非常适合本地开发和个人项目。它也是开源的,并在Apache 2.0许可证下提供,因此对各种用户都很容易访问。
| 名称 | HuggingFace仓库 | 许可证 | md5sum |
FLUX.1 [pro] |
仅在我们的API中提供。 | ||
FLUX.1 [dev] |
https://huggingface.co/black-forest-labs/FLUX.1-dev | FLUX.1-dev 非商业许可证 | a6bd8c16dfc23db6aee2f63a2eba78c0 |
FLUX.1 [schnell] |
https://huggingface.co/black-forest-labs/FLUX.1-schnell | apache-2.0 | a9e1e277b9b16add186f38e3f5a34044 |
3. FLUX硬件要求#
3.1. FLUX.1 [Pro] 硬件要求#
- 推荐GPU:NVIDIA RTX 4090或同等配置,具有24 GB或更多VRAM。该模型针对高端GPU进行了优化,以处理其复杂的操作。
- 内存:32 GB或更多系统内存。
- 磁盘空间:大约30 GB。
- 计算要求:需要高精度;使用FP16(半精度)以避免内存不足错误。为了获得最佳效果,建议使用
fp16Clip模型变体以获得最大质量。 - 其他要求:推荐使用快速SSD以加快加载时间和整体性能。
3.2. FLUX.1 [Dev] 硬件要求#
- 推荐GPU:NVIDIA RTX 3080/3090或同等配置,至少具有16 GB VRAM。与Pro模型相比,该版本对硬件要求稍微宽松,但仍需要相当的GPU功率。
- 内存:16 GB或更多系统内存。
- 磁盘空间:大约25 GB。
- 计算要求:与Pro类似,使用FP16模型,但对较低精度计算有轻微容忍度。可以根据GPU能力使用
fp16或fp8Clip模型。 - 其他要求:推荐使用快速SSD以获得最佳性能。
3.3. FLUX.1 [Schnell] 硬件要求#
- 推荐GPU:NVIDIA RTX 3060/4060或同等配置,具有12 GB VRAM。该版本针对更快的推理和较低的硬件要求进行了优化。
- 内存:8 GB或更多系统内存。
- 磁盘空间:大约15 GB。
- 计算要求:该版本要求较低,允许使用
fp8计算以避免内存不足。设计为快速高效,重点在于速度而非超高质量。 - 其他要求:SSD有用但不像Pro和Dev版本那样关键。
4. 如何在ComfyUI中安装FLUX#
4.1. 安装或更新ComfyUI#
要在ComfyUI环境中有效使用FLUX.1,关键是确保安装最新版本的ComfyUI。该版本支持FLUX.1模型所需的必要功能和集成。
4.2. 下载ComfyUI FLUX文本编码器和CLIP模型#
为了使用FLUX.1实现最佳性能和准确的文本到图像生成,你需要下载特定的文本编码器和CLIP模型。根据你的系统硬件,以下模型是必需的:
下载和安装步骤:
- 下载
clip_l.safetensors模型。 - 根据你的系统VRAM和RAM,下载
t5xxl_fp8_e4m3fn.safetensors(用于较低VRAM)或t5xxl_fp16.safetensors(用于较高VRAM和RAM)。 - 将下载的模型放置在
ComfyUI/models/clip/目录中。注意:如果你以前使用过SD 3 Medium,你可能已经有这些模型。
4.3. 下载FLUX.1 VAE模型#
变分自编码器(VAE)模型对于提高FLUX.1的图像生成质量至关重要。以下VAE模型可供下载:
| 文件名 | 大小 | 链接 |
ae.safetensors |
335 MB | 下载(在新标签中打开) |
下载和安装步骤:
- 下载
ae.safetensors模型文件。 - 将下载的文件放置在
ComfyUI/models/vae目录中。 - 为了便于识别,建议将文件重命名为
flux_ae.safetensors。
4.4. 下载FLUX.1 UNET模型#
UNET模型是FLUX.1中图像合成的骨干。根据系统规格,可以选择不同的变体:
下载和安装步骤:
- 根据系统的内存配置下载适当的UNET模型。
- 将下载的模型文件放置在
ComfyUI/models/unet/目录中。
5. ComfyUI FLUX工作流 | 下载,在线访问和指南#
我们将不断更新ComfyUI FLUX工作流,为你提供最新和最全面的工作流,以使用ComfyUI FLUX生成令人惊叹的图像。
5.1. ComfyUI工作流:FLUX Txt2Img#
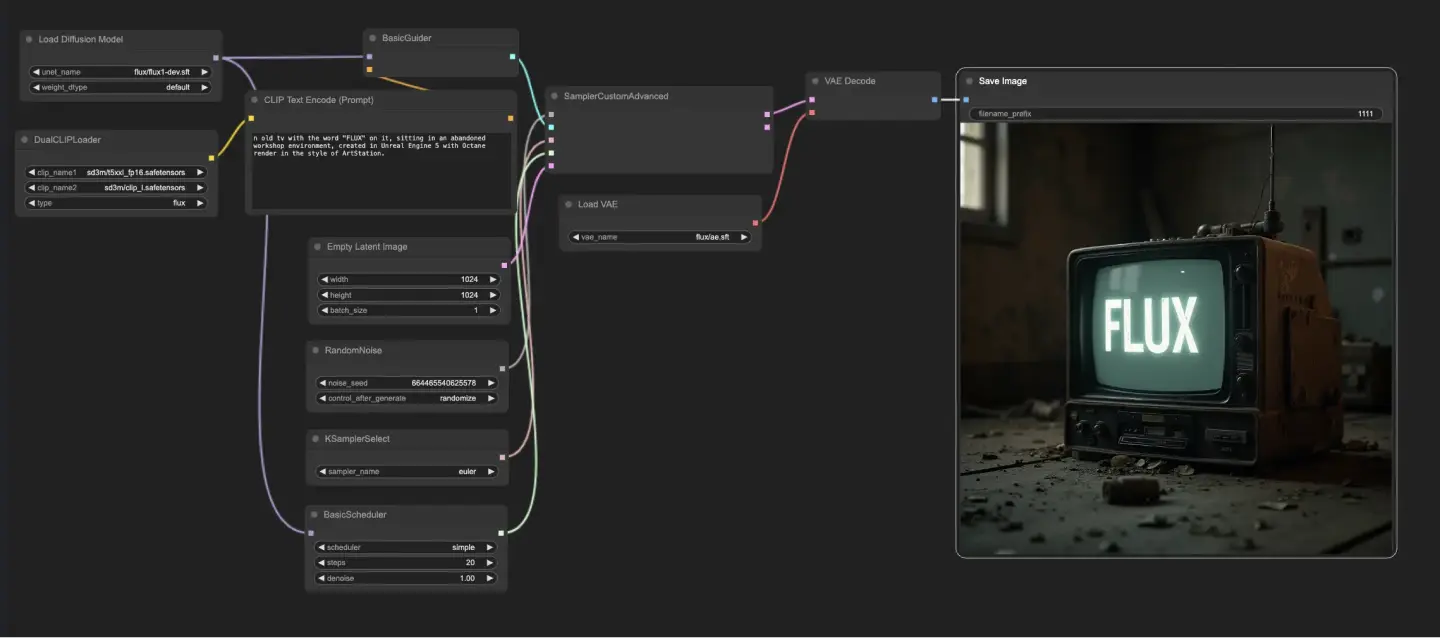
5.1.1. ComfyUI FLUX Txt2Img : <a href="https://cdn.runcomfy.net/tutorial_download/162/01.json" target="_blank">下载</a>#
5.1.2. ComfyUI FLUX Txt2Img在线版本:ComfyUI FLUX Txt2Img#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX Txt2Img体验。
5.1.3. ComfyUI FLUX Txt2Img解释:#
ComfyUI FLUX Txt2Img工作流首先加载基本组件,包括FLUX UNET(UNETLoader),FLUX CLIP(DualCLIPLoader)和FLUX VAE(VAELoader)。这些构成了ComfyUI FLUX图像生成过程的基础。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:加载用于文本编码的CLIP模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分组:CLIP模型的分组策略是flux
- VAELoader:加载用于解码潜在表示的变分自编码器(VAE)模型。
- VAE模型:flux/ae.sft
文本提示,它描述了所需的输出,使用CLIPTextEncode进行编码。该节点将文本提示作为输入,并输出编码的文本条件,这在生成过程中引导ComfyUI FLUX。
要启动ComfyUI FLUX生成过程,使用EmptyLatentImage创建一个空的潜在表示。这作为ComfyUI FLUX的起点。
BasicGuider在ComfyUI FLUX生成过程中起着关键作用。它将编码的文本条件和加载的FLUX UNET作为输入,确保生成的输出与提供的文本描述一致。
KSamplerSelect允许你选择ComfyUI FLUX生成的采样方法,而RandomNoise则生成随机噪声作为ComfyUI FLUX的输入。BasicScheduler为生成过程中的每一步调度噪声级别(sigmas),控制最终输出的细节和清晰度。
SamplerCustomAdvanced汇集了ComfyUI FLUX Txt2Img工作流的所有组件。它将随机噪声,指南,选择的采样器,调度的sigmas和空的潜在表示作为输入。通过高级采样过程,它生成一个表示文本提示的潜在表示。
最后,VAEDecode使用加载的FLUX VAE将生成的潜在表示解码为最终输出。SaveImage允许你将生成的输出保存到指定位置,保留由ComfyUI FLUX Txt2Img工作流生成的令人惊叹的创作。
5.2. ComfyUI工作流:FLUX Img2Img#
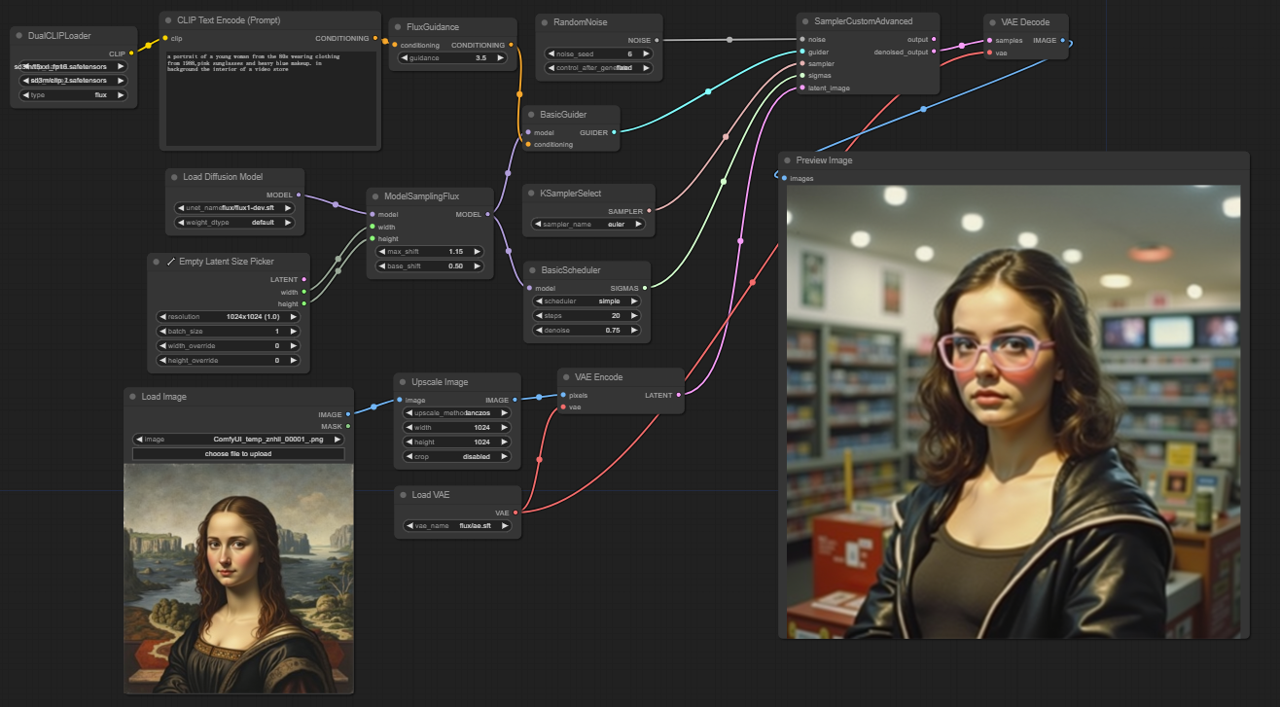
5.2.1. ComfyUI FLUX Img2Img: <a href="https://cdn.runcomfy.net/tutorial_download/162/02.json" target="_blank">下载</a>#
5.2.2. ComfyUI FLUX Img2Img在线版本:ComfyUI FLUX Img2Img#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX Img2Img体验。
5.2.3. ComfyUI FLUX Img2Img解释:#
ComfyUI FLUX Img2Img工作流基于ComfyUI FLUX的强大功能生成基于文本提示和输入表示的输出。它首先加载必要的组件,包括CLIP模型(DualCLIPLoader),UNET模型(UNETLoader)和VAE模型(VAELoader)。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:加载用于文本编码的CLIP模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分组:CLIP模型的分组策略是flux
- VAELoader:加载用于解码潜在表示的变分自编码器(VAE)模型。
- VAE模型:flux/ae.sft
输入表示,作为ComfyUI FLUX Img2Img过程的起点,使用LoadImage加载。ImageScale然后将输入表示缩放到所需大小,确保与ComfyUI FLUX兼容。
缩放后的输入表示通过VAEEncode进行编码,将其转换为潜在表示。该潜在表示捕获了输入的基本特征和细节,为ComfyUI FLUX提供了基础。
描述所需修改或增强的文本提示使用CLIPTextEncode进行编码。FluxGuidance然后根据指定的指导规模应用指导,影响文本提示对最终输出的影响强度。
ModelSamplingFlux设置ComfyUI FLUX的采样参数,包括时间步重新采样,填充比率和输出维度。这些参数控制生成输出的粒度和分辨率。
KSamplerSelect允许你选择ComfyUI FLUX生成的采样方法,而BasicGuider根据编码的文本条件和加载的FLUX UNET指导生成过程。
使用RandomNoise生成随机噪声,BasicScheduler调度生成过程中的噪声级别(sigmas)。这些组件引入受控的变化,并微调最终输出的细节。
SamplerCustomAdvanced汇集了随机噪声,指南,选择的采样器,调度的sigmas和输入的潜在表示。通过高级采样过程,它生成一个潜在表示,结合了文本提示指定的修改,同时保留了输入的基本特征。
最后,VAEDecode使用加载的FLUX VAE将生成的潜在表示解码为最终输出。PreviewImage显示生成输出的预览,展示了由ComfyUI FLUX Img2Img工作流实现的令人惊叹的结果。
5.3. ComfyUI工作流:FLUX LoRA#
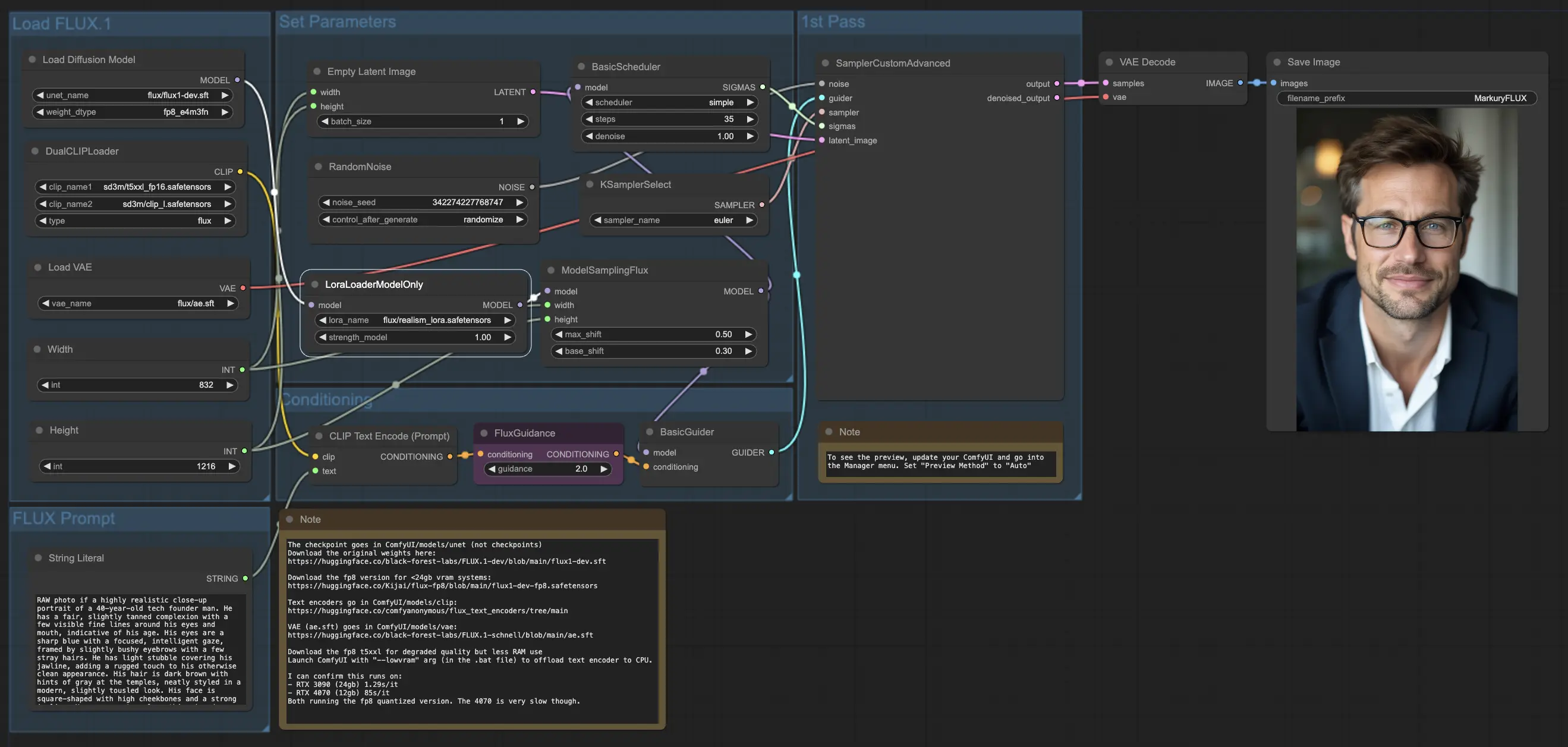
5.3.1. ComfyUI FLUX LoRA: <a href="https://cdn.runcomfy.net/tutorial_download/162/03.json" target="_blank">下载</a>#
5.3.2. ComfyUI FLUX LoRA在线版本:ComfyUI FLUX LoRA#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX LoRA体验。
5.3.3. ComfyUI FLUX LoRA解释:#
ComfyUI FLUX LoRA工作流利用低秩适应(LoRA)的强大功能来增强ComfyUI FLUX的性能。它首先加载必要的组件,包括UNET模型(UNETLoader),CLIP模型(DualCLIPLoader),VAE模型(VAELoader)和LoRA模型(LoraLoaderModelOnly)。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:flux/flux1-dev.sft
- DualCLIPLoader:加载用于文本编码的CLIP模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分组:CLIP模型的分组策略是flux
- VAELoader:加载用于解码潜在表示的变分自编码器(VAE)模型。
- VAE模型:flux/ae.sft
- LoraLoaderModelOnly:加载用于增强UNET模型的LoRA(低秩适应)模型。
- LoaderModel:flux/realism_lora.safetensors
描述所需输出的文本提示使用String Literal指定。CLIPTextEncode然后对文本提示进行编码,生成指导ComfyUI FLUX生成过程的编码文本条件。
FluxGuidance应用指导到编码的文本条件,影响ComfyUI FLUX对文本提示的遵从性和方向。
使用EmptyLatentImage创建一个空的潜在表示,作为生成的起点。使用Int Literal指定生成输出的宽度和高度,确保最终结果的所需尺寸。
ModelSamplingFlux设置ComfyUI FLUX的采样参数,包括填充比率和时间步重新采样。这些参数控制生成输出的分辨率和粒度。
KSamplerSelect允许你选择ComfyUI FLUX生成的采样方法,而BasicGuider根据编码的文本条件和加载的FLUX UNET(增强了FLUX LoRA)指导生成过程。
使用RandomNoise生成随机噪声,BasicScheduler调度生成过程中的噪声级别(sigmas)。这些组件引入受控的变化,并微调最终输出的细节。
SamplerCustomAdvanced汇集了随机噪声,指南,选择的采样器,调度的sigmas和空的潜在表示。通过高级采样过程,它生成一个代表文本提示的潜在表示,利用FLUX和FLUX LoRA增强的力量。
最后,VAEDecode使用加载的FLUX VAE将生成的潜在表示解码为最终输出。SaveImage允许你将生成的输出保存到指定位置,保留由ComfyUI FLUX LoRA工作流生成的令人惊叹的创作。
5.4. ComfyUI工作流:FLUX ControlNet#
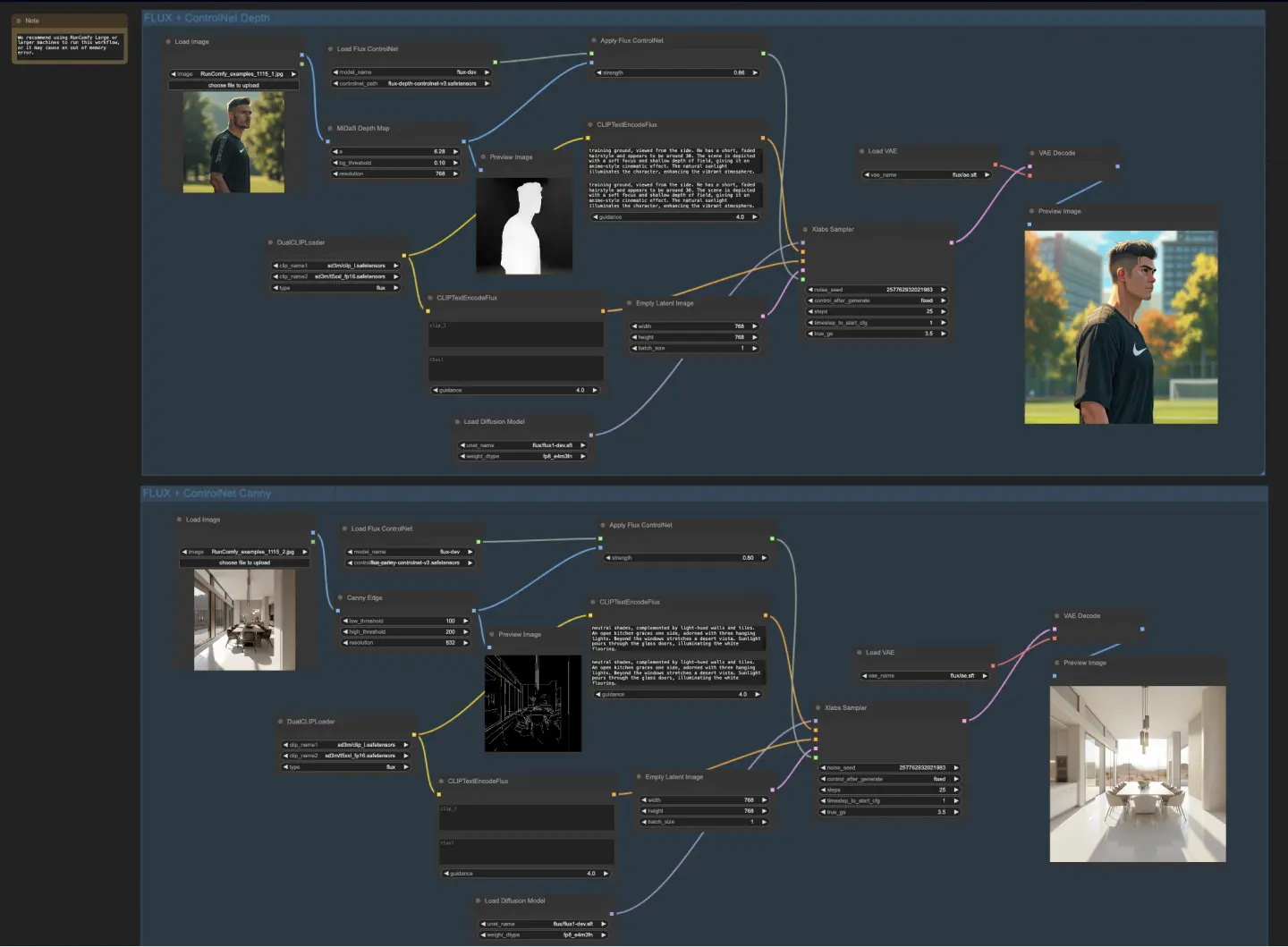
5.4.1. ComfyUI FLUX ControlNet: <a href="https://cdn.runcomfy.net/tutorial_download/162/04.json" target="_blank">下载</a>#
5.4.2. ComfyUI FLUX ControlNet在线版本:ComfyUI FLUX ControlNet#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX ControlNet体验。
5.4.3. ComfyUI FLUX ControlNet解释:#
ComfyUI FLUX ControlNet工作流展示了ControlNet与ComfyUI FLUX的集成,以增强输出生成。工作流展示了两个示例:基于深度的条件和基于Canny边缘的条件。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:flux/flux1-dev.sft
- DualCLIPLoader:加载用于文本编码的CLIP模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分组:CLIP模型的分组策略是flux
- VAELoader:加载用于解码潜在表示的变分自编码器(VAE)模型。
- VAE模型:flux/ae.sft
在基于深度的工作流中,输入表示通过MiDaS-DepthMapPreprocessor进行预处理,生成深度图。然后将深度图通过ApplyFluxControlNet(Depth)与加载的FLUX ControlNet进行深度条件处理。生成的FLUX ControlNet条件作为XlabsSampler(Depth)的输入,结合加载的FLUX UNET,编码的文本条件,负面文本条件和空的潜在表示。XlabsSampler根据这些输入生成潜在表示,然后通过VAEDecode解码为最终输出。
- MiDaS-DepthMapPreprocessor(Depth):使用MiDaS对输入图像进行深度估计预处理。
- LoadFluxControlNet:加载ControlNet模型。
- 路径:flux-depth-controlnet.safetensors
类似地,在基于Canny边缘的工作流中,输入表示通过CannyEdgePreprocessor进行预处理,生成Canny边缘表示。然后将Canny边缘表示通过ApplyFluxControlNet(Canny)与加载的FLUX ControlNet进行Canny边缘条件处理。生成的FLUX ControlNet条件作为XlabsSampler(Canny)的输入,结合加载的FLUX UNET,编码的文本条件,负面文本条件和空的潜在表示。XlabsSampler根据这些输入生成潜在表示,然后通过VAEDecode解码为最终输出。
- CannyEdgePreprocessor(Canny):对输入图像进行Canny边缘检测预处理。
- LoadFluxControlNet:加载ControlNet模型。
- 路径:flux-canny-controlnet.safetensors
ComfyUI FLUX ControlNet工作流包含用于加载必要组件(DualCLIPLoader,UNETLoader,VAELoader,LoadFluxControlNet),编码文本提示(CLIPTextEncodeFlux),创建空的潜在表示(EmptyLatentImage)和预览生成和预处理输出(PreviewImage)的节点。
通过利用FLUX ControlNet的强大功能,ComfyUI FLUX ControlNet工作流能够生成符合特定条件(如深度图或Canny边缘)的输出。这种额外的控制和指导增强了生成过程的灵活性和精确性,允许使用ComfyUI FLUX创建令人惊叹和符合背景的输出。
5.5. ComfyUI工作流:FLUX修复#
5.5.1. ComfyUI FLUX Inpainting: <a href="https://cdn.runcomfy.net/tutorial_download/162/05.json" target="_blank">下载</a>#
5.5.2. ComfyUI FLUX Inpainting在线版本:ComfyUI FLUX Inpainting#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX Inpainting体验。
5.5.3. ComfyUI FLUX Inpainting解释:#
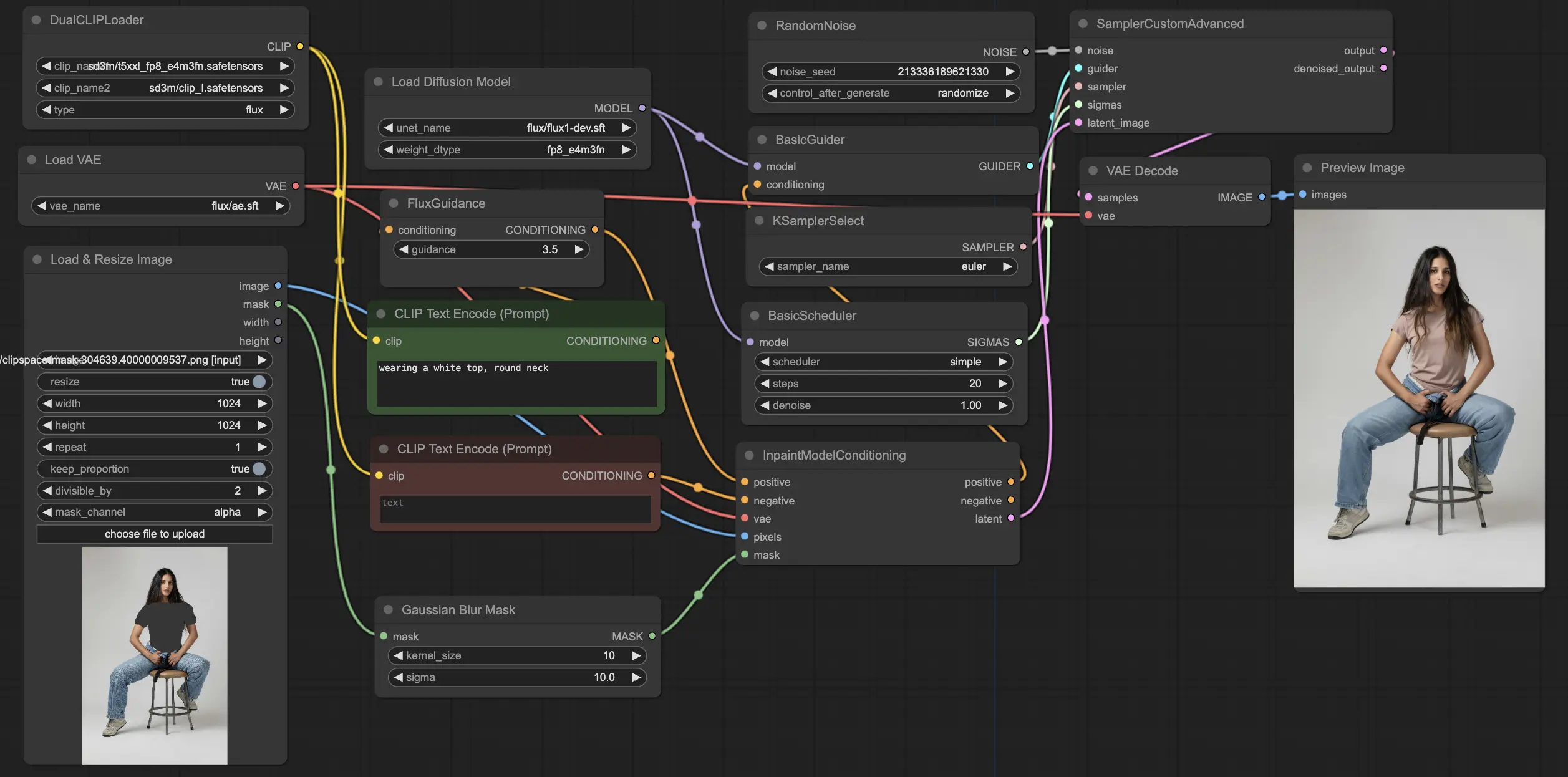
ComfyUI FLUX Inpainting工作流展示了ComfyUI FLUX执行修复的能力,即根据周围的上下文和提供的文本提示填充缺失或遮蔽的区域。工作流首先加载必要的组件,包括UNET模型(UNETLoader),VAE模型(VAELoader)和CLIP模型(DualCLIPLoader)。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:flux/flux1-schnell.sft;flux/flux1-dev.sft
- DualCLIPLoader:加载用于文本编码的CLIP模型。
- 嵌入模型1:sd3m/t5xxl_fp8_e4m3fn.safetensors;sd3m/t5xxl_fp16.safetensors
- 嵌入模型2:sd3m/clip_g.safetensors;sd3m/clip_l.safetensors
- 分组:CLIP模型的分组策略是flux
- VAELoader:加载用于解码潜在表示的变分自编码器(VAE)模型。
- VAE模型:flux/ae.sft
正面和负面的文本提示,描述了修复区域的所需内容和风格,使用CLIPTextEncodes进行编码。正面文本条件进一步通过FluxGuidance进行指导,以影响ComfyUI FLUX的修复过程。
使用LoadAndResizeImage加载和调整输入表示和遮罩的大小,确保与ComfyUI FLUX的要求兼容。ImpactGaussianBlurMask对遮罩应用高斯模糊,创建修复区域和原始表示之间的平滑过渡。
InpaintModelConditioning通过结合指导的正面文本条件,编码的负面文本条件,加载的FLUX VAE,加载和调整大小的输入表示和模糊遮罩来准备FLUX修复的条件。这些条件作为ComfyUI FLUX修复过程的基础。
使用RandomNoise生成随机噪声,KSamplerSelect选择采样方法。BasicScheduler调度ComfyUI FLUX修复过程中的噪声级别(sigmas),控制修复区域的细节和清晰度。
BasicGuider根据准备的条件和加载的FLUX UNET指导ComfyUI FLUX修复过程。SamplerCustomAdvanced执行高级采样过程,将生成的随机噪声,指南,选择的采样器,调度的sigmas和输入的潜在表示作为输入。它输出修复的潜在表示。
最后,VAEDecode使用加载的FLUX VAE将修复的潜在表示解码为最终输出,无缝融合修复区域和原始表示。PreviewImage显示最终输出,展示了FLUX的令人印象深刻的修复能力。
通过利用FLUX的强大功能和精心设计的修复工作流,FLUX Inpainting使得创建视觉一致和符合上下文的修复输出成为可能。无论是恢复缺失部分,移除不需要的对象,还是修改特定区域,ComfyUI FLUX修复工作流为编辑和操纵提供了强大的工具。
5.6. ComfyUI工作流:FLUX NF4#
5.6.1. ComfyUI FLUX NF4: <a href="https://cdn.runcomfy.net/tutorial_download/162/06.json" target="_blank">下载</a>#
5.6.2. ComfyUI FLUX NF4在线版本:ComfyUI FLUX NF4#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX NF4体验。
5.6.3. ComfyUI FLUX NF4解释:#
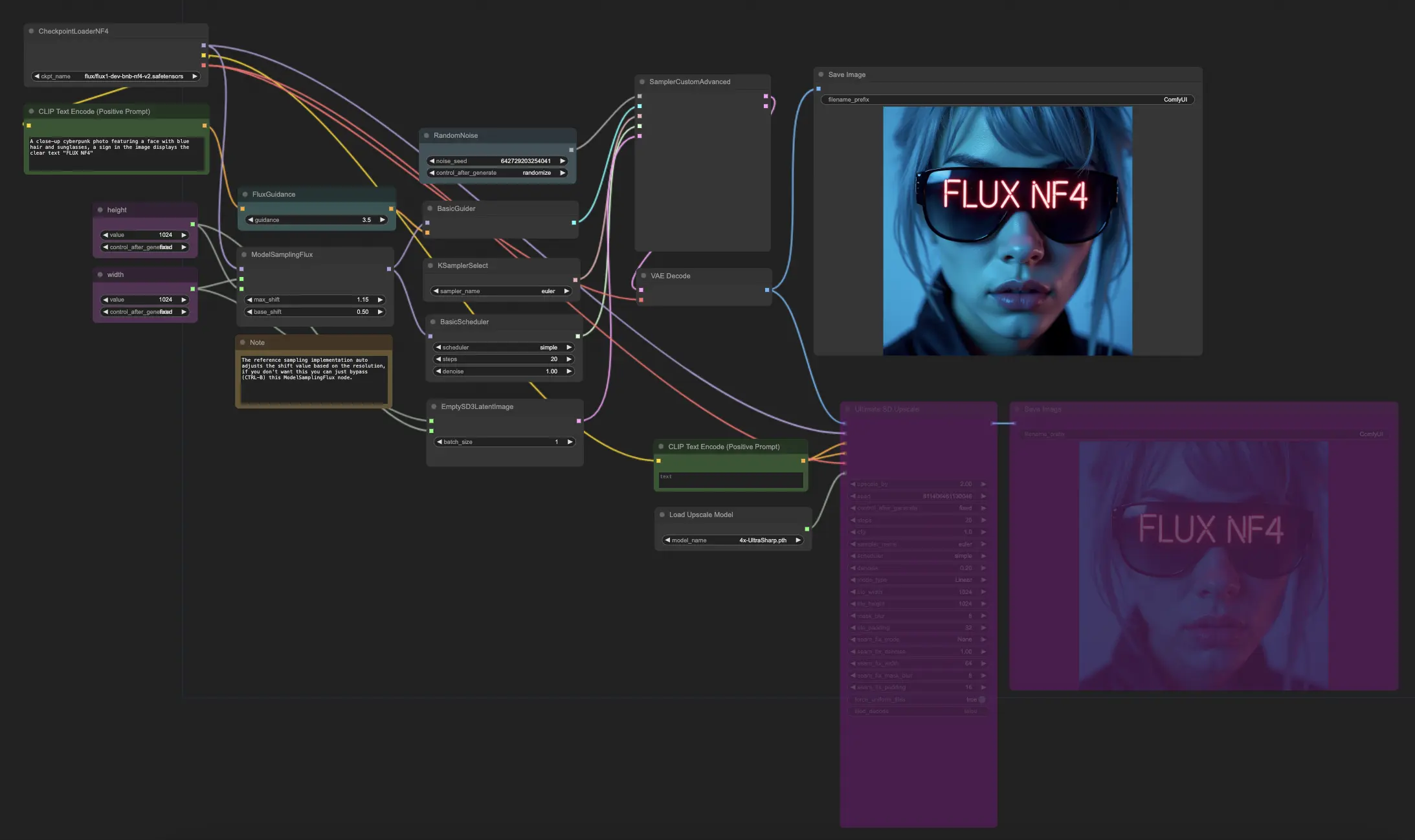
ComfyUI FLUX NF4工作流展示了ComfyUI FLUX与NF4(Normalizing Flow 4)架构的集成,以生成高质量的输出。工作流首先使用CheckpointLoaderNF4加载必要的组件,包括FLUX UNET,FLUX CLIP和FLUX VAE。
- UNETLoader:加载用于图像生成的UNET模型。
- 检查点:TBD
PrimitiveNode(高度)和PrimitiveNode(宽度)节点指定生成输出的所需高度和宽度。ModelSamplingFlux节点基于加载的FLUX UNET和指定的高度和宽度设置ComfyUI FLUX的采样参数。
EmptySD3LatentImage节点创建一个空的潜在表示,作为生成的起点。BasicScheduler节点调度ComfyUI FLUX生成过程中的噪声级别(sigmas)。
RandomNoise节点生成ComfyUI FLUX生成过程的随机噪声。BasicGuider节点根据条件化的ComfyUI FLUX指导生成过程。
KSamplerSelect节点选择ComfyUI FLUX生成的采样方法。SamplerCustomAdvanced节点执行高级采样过程,将生成的随机噪声,指南,选择的采样器,调度的sigmas和空的潜在表示作为输入。它输出生成的潜在表示。
VAEDecode节点使用加载的FLUX VAE将生成的潜在表示解码为最终输出。SaveImage节点将生成的输出保存到指定位置。
对于放大,使用UltimateSDUpscale节点。它将生成的输出,加载的FLUX,正面和负面放大条件,加载的FLUX VAE和加载的FLUX放大作为输入。CLIPTextEncode(Upscale Positive Prompt)节点对用于放大的正面文本提示进行编码。UpscaleModelLoader节点加载FLUX放大。UltimateSDUpscale节点执行放大过程并输出放大的表示。最后,SaveImage(Upscaled)节点将放大的输出保存到指定位置。
通过利用ComfyUI FLUX和NF4架构的强大功能,ComfyUI FLUX NF4工作流能够生成具有增强保真度和真实感的高质量输出。ComfyUI FLUX与NF4架构的无缝集成提供了一个强大的工具,用于创建令人惊叹和引人入胜的输出。
5.7. ComfyUI工作流:FLUX IPAdapter#
5.7.1. ComfyUI FLUX IPAdapter: <a href="https://cdn.runcomfy.net/tutorial_download/162/07.json" target="_blank">下载</a>#
5.7.2. ComfyUI FLUX IPAdapter在线版本:ComfyUI FLUX IPAdapter#
在RunComfy平台,我们的在线版本预加载了所有必要的模式和节点。此外,我们提供高性能GPU机器,确保你可以轻松享受ComfyUI FLUX IPAdapter体验。
5.7.3. ComfyUI FLUX IPAdapter解释:#
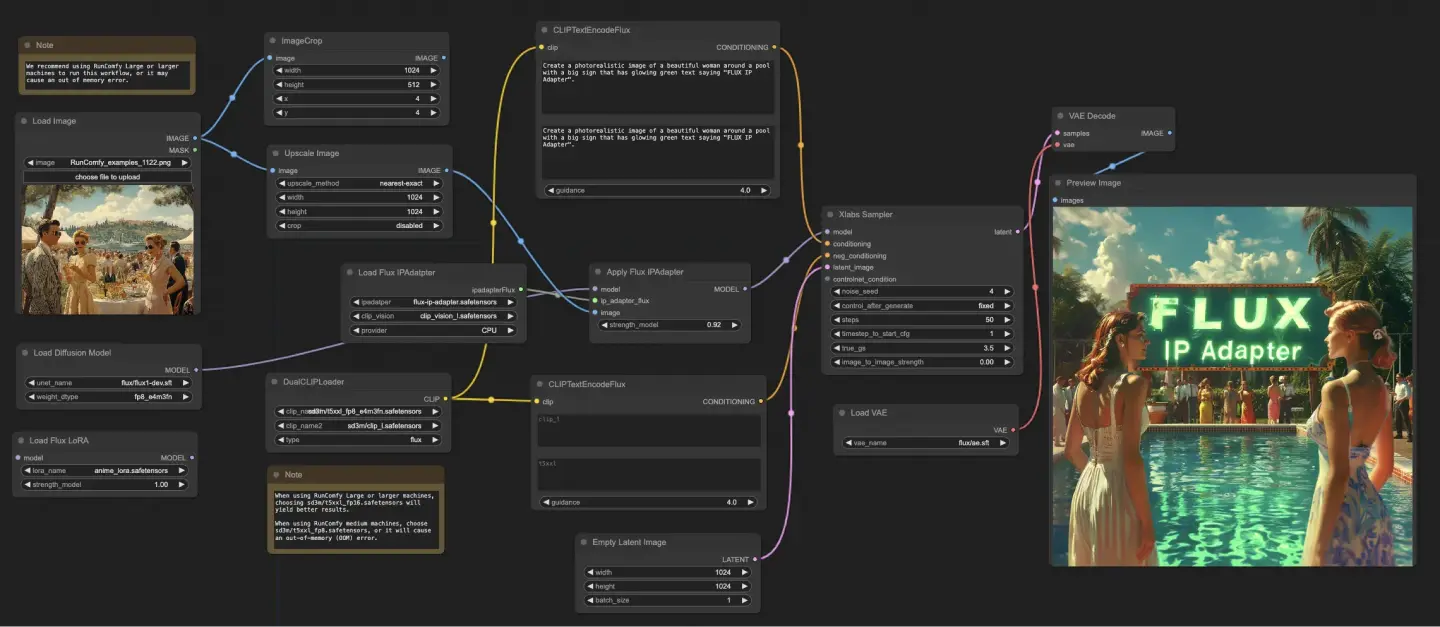
ComfyUI FLUX IPAdapter工作流首先加载必要的模型,包括UNET模型(UNETLoader),CLIP模型(DualCLIPLoader)和VAE模型(VAELoader)。
正面和负面的文本提示使用CLIPTextEncodeFlux进行编码。正面文本条件用于指导ComfyUI FLUX生成过程。
使用LoadImage加载输入图像。LoadFluxIPAdapter加载FLUX模型的IP-Adapter,然后应用于加载的UNET模型使用ApplyFluxIPAdapter。ImageScale将输入图像缩放到所需大小,然后应用IP-Adapter。
- LoadFluxIPAdapter:加载FLUX模型的IP-Adapter。
- IP Adapter模型:flux-ip-adapter.safetensors
- CLIP视觉编码器:clip_vision_l.safetensors
EmptyLatentImage创建一个空的潜在表示,作为ComfyUI FLUX生成的起点。
XlabsSampler执行采样过程,将FLUX UNET与应用的IP-Adapter,编码的正面和负面文本条件和空的潜在表示作为输入。它生成潜在表示。
VAEDecode使用加载的FLUX VAE将生成的潜在表示解码为最终输出。PreviewImage节点显示最终输出的预览。
ComfyUI FLUX IPAdapter工作流利用ComfyUI FLUX和IP-Adapter的强大功能生成符合提供的文本提示的高质量输出。通过将IP-Adapter应用于FLUX UNET,工作流能够生成捕捉文本条件指定的特征和风格的输出。
5.8. ComfyUI工作流:Flux LoRA训练器#

5.8.1. ComfyUI FLUX LoRA训练器: <a href="https://cdn.runcomfy.net/tutorial_download/162/08.json" target="_blank">下载</a>#
5.8.2. ComfyUI Flux LoRA训练器解释:#
ComfyUI FLUX LoRA训练器工作流由多个阶段组成,用于在ComfyUI中使用FLUX架构训练LoRA。
ComfyUI FLUX选择和配置: FluxTrainModelSelect节点用于选择训练组件,包括UNET,VAE,CLIP和CLIP文本编码器。 OptimizerConfig节点配置ComfyUI FLUX训练的优化器设置,如优化器类型,学习率和权重衰减。 TrainDatasetGeneralConfig和TrainDatasetAdd节点用于配置训练数据集,包括分辨率,增强设置和批次大小。
ComfyUI FLUX训练初始化: InitFluxLoRATraining节点使用选定的组件,数据集配置和优化器设置初始化LoRA训练过程。 FluxTrainValidationSettings节点配置训练的验证设置,如验证样本数量,分辨率和批次大小。
ComfyUI FLUX训练循环: FluxTrainLoop节点执行LoRA的训练循环,迭代指定步数。 在每个训练循环后,FluxTrainValidate节点使用验证设置验证训练的LoRA并生成验证输出。 PreviewImage节点显示验证结果的预览。 FluxTrainSave节点在指定间隔保存训练的LoRA。
ComfyUI FLUX损失可视化: VisualizeLoss节点可视化训练过程中损失的变化。 SaveImage节点保存损失图以供进一步分析。
ComfyUI FLUX验证输出处理: AddLabel和SomethingToString节点用于给验证输出添加标签,指示训练步骤。 ImageBatchMulti和ImageConcatFromBatch节点将验证输出组合和拼接为一个结果,以便于可视化。
ComfyUI FLUX训练结束: FluxTrainEnd节点完成LoRA的训练过程并保存训练的LoRA。 UploadToHuggingFace节点可用于将训练的LoRA上传到Hugging Face,以便与ComfyUI FLUX共享和进一步使用。
5.9. ComfyUI工作流:Flux Latent Upscaler#
5.9.1. ComfyUI Flux Latent Upscaler: <a href="https://cdn.runcomfy.net/tutorial_download/162/09.json" target="_blank">下载</a>#
5.9.2. ComfyUI Flux Latent Upscaler解释:#
ComfyUI Flux Latent Upscale工作流首先加载必要的组件,包括CLIP(DualCLIPLoader),UNET(UNETLoader)和VAE(VAELoader)。文本提示使用CLIPTextEncode节点进行编码,并使用FluxGuidance节点应用指导。
SDXLEmptyLatentSizePicker+节点指定空的潜在表示的大小,作为FLUX放大过程的起点。然后潜在表示通过一系列放大和裁剪步骤使用LatentUpscale和LatentCrop节点进行处理。
放大过程由编码的文本条件指导,并使用SamplerCustomAdvanced节点与选择的采样方法(KSamplerSelect)和调度的噪声级别(BasicScheduler)。ModelSamplingFlux节点设置采样参数。
然后使用SolidMask和FeatherMask节点生成的遮罩,将放大的潜在表示与原始潜在表示组合使用LatentCompositeMasked节点。使用InjectLatentNoise+节点将噪声注入放大的潜在表示。
最后,VAEDecode节点将放大的潜在表示解码为最终输出,并使用ImageSmartSharpen+节点应用智能锐化。PreviewImage节点显示由ComfyUI FLUX生成的最终输出的预览。
ComfyUI FLUX Latent Upscaler工作流还包括使用SimpleMath+,SimpleMathFloat+,SimpleMathInt+和SimpleMathPercent+节点进行的各种数学运算,以计算放大过程的尺寸比例和其他参数。